


Please, report me about every grammar mistake, you see. Thank you.
Problem <>
Let's notice that 2n ≤ k ≤ 5n. If k < 3n author has to get 2 on some exams. There are 3n - k such exams and that's the answer). If 3n ≤ k author will pass all exams (answer is 0).
Problem <>
Let the pencil move by the line and put crosses through every (n + 1) point. Lets associate every point on the line with point on square perimeter. Namely, point x on the line will be associated with point on square perimeter that we will reach if we move pencil around square to x clockwise. Then lower left corner will be associated with all points 4np for every non-negative integer p. Crosses will be associated with points k(n + 1) for some non-negative k. Nearest point of overlap of two families of points will be in point LCM(n + 1, 4n). Then we will put 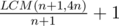 crosses.
crosses.
Problem "Cutting Figure"
Translation by fdoer
Main idea: using the fact that the answer cannot be greater than 2, check answer 1.
Let's proof that the answer is not greater than 2. Let area of the figure be greater than 3. Let's examine the leftmost of all topmost squares. There is no neighbors left or up to it. So, number of its neighbors is not more than 2. Thus, if we delete its neighbors, we shall disconnect the figure. If the area is equal to 3, we always can disconnect the figure by deletion of one square. It can be proofed by considering all two primary cases. If the area is not greater than 2, there is no way to disconnect the figure.
The algorithm: Check answer 1. We can simply brute-force the square to delete, and for each instance start dfs from any existing square. If during the dfs we visited not all of the remaining squares, we have found the square to delete. The answer is 1 if our bruteforce succeeded, and 2 otherwise.
That was necessary to consider the case when there is no answer.
The complexity of the described algorithm is O(n4). That was possible to search for articulation points and solve the problem in complexity O(n2), but in my opinion that required more time and effort.
Problem <>
Translation by fdoer
Main idea: bruteforce in complexity O(Fun) where Fu if fibonacci number at position u.
This problem had complex statements. We have an array a, and we can transform it in two ways. The goal was to maximize the sum of all its elements with given multipliers after exactly u operations.
A simple bruteforce of all combinations of operations with subsequent modeling leads to complexity O(2u * nu), what is not fast enough. That was possible to optimize it by modeling parallel to recursive bruteforce. Now we have complexity O(2un). Actually, the correct solution is not too far from this algorithm.
There is just one conjecture: every two successive xor operations change nothing, and we can move them to any place of the combination. Thus, it will be enough to bruteforce only combinations in which every pair of successive xor operations is at the end.
It could be done using recoursive bruteforce. We must change in previous solution two things. First, we must n't put xor after xor. Besides that, we should update answer if number u - l is even, where l is current level of recoursion (all remaining operations in the end separates to pairs of xors).
Let's calculate complexity of this algo. There are Fi sequences of length i without two consecutive xors. It's easy to proof, you can calculate some dp to see it. That's why, complexity of our algo is O(Fun).
Problem "Hamming distance"
Main idea: reduction to system of linear equations and solving it using Gauss algorithm.
Let's notice that order of columns in answer doesn't matter. That's why there is only one important thing — quantity of every type of column. There is only 24 = 16 different columns.
Let's represent Hamming distance between every pair of strings as sum of quantities of types of columns. It's possible because every column adds to every distance between pairs 0 or 1.
Now we have system of 6 linear equations with 16 variables. It's not good, let's decrease number of variables. First, some columns adds same values to every Hamming distance. For example strings "abbb" and "baaa". For every column q we can replace all letters "a" by letters "b" and all letters "b" by letters "a" and reach column that adds same values to every distance. We reduced number of variables to 8. We also can notice that columns "aaaa" and "bbbb" is useless and reduce number of variables to 7.
This system can be solved using Gauss algorithm. One variable steel be free. Let's fix it. It's value can't be more than maximum of h(si, sj) because column adds positive value to one or more Hamming distance. For every fixed value we should check if all variables take non-negative integer value and choose the best answer.
We can solve system of equations in integers because coefficients of equation is little.
Complexity of this solution if O(max(h(si, sj))). If we solve it in rational numbers complexity will change to 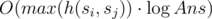 .
.
Problem "Two segments"
Main idea: inverse the permutation and solve simplified problem (see below), consider function "quantity of segments of permutation that form the given segment of natural series".
In order to solve this problem, we suggest solve another: <<we have a permutation pn, we have to calculate the count of segments such that their elements form one or two segments of natural series>>.
If we solve the inverse problem for some permutation qn such that 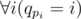 , we shall get the answer for the initial problem and initial permutation pi.
, we shall get the answer for the initial problem and initial permutation pi.
Straight-forward algo: let's bruteforce the segment of permutation and mark its elements in a boolean array. Check that in that array there is not more than two marked segments. This algo has complexity O(n3).
Let's notice that during the changeover from [l, r] to [l, r + 1] the quantity of segments changes in some predictable way. Let s([a, b]) be quantity of segments that form segment [a, b] of permutation. There are three cases (see picture below):
- If the new element pr + 1 is between two marked elements (that is, both elements with values pr + 1 - 1 and pr + 1 + 1 belong to segment [l, r]), then s([l, r + 1]) = s([l, r]) - 1. The new element will <> the segments near it.
- If the new element pr + 1 has only one neighbor with value belonging to [l, r], then s([l, r + 1]) = s([l, r]). The new element will lengthen one of existing segments.
- If there are no marked elements near pr + 1 the new element forms a new segment, s([l, r + 1]) = s([l, r]) + 1.

The new element is red, elements that are marked to this moment are black.
Improved algo: Let's bruteforce position of the left border and for each instance move the right border from left to right. During each move we shall recount the actual quantity of segments forming the current segment of permutation (s([l, r])). Now we have a solution in complexity O(n2). It works fast enough even when n = 20000. Obviously, that is not enough to get AC.
Move on full solution. It is based on previous. Now we can calc s([l, r]) using s([l, r - 1]). Now we should look at way of changing s([l - 1, r]) as compared with s([l, r]). Let's move left border of segment from the right to left and support some data structure with s([l, i]) for every i satisfying l < i ≤ n and current l. This structure should answer queries "count numbers 1 and 2 in structure", that is count segments [l, i] that generates one or two segments in the original permutaton.
Let Δi be s([l - 1, i]) - s([l, i]). Δl will be equal to 1 because one element form one segment in permutation (notice that in final answer we must not consider 1-element segments, that's why we must subtract n from answer in the end of solution).
Δi determined by the number of neighbors of element l - 1 in the segment [l - 1, i]. Neighbors of l - 1 is elements pl - 1 + 1 and pl - 1 - 1 if they're exist.
- If l - 1 hasn't neighbors in this segment, Δi = 1, because l - 1 froms new 1-element segment.
- If l - 1 has one neighbor in this segment Δi = 0, because l - 1 join to existing segment of its neighbor.
- If l - 1 has two neighbors in this segment Δi = - 1, because l - 1 connect segments of its neighbors.
Number of neighbors in segment [l - 1, i] non-decreasing with increasing i. That's why Δi non-decreasing with increasing i. That means that there are only three segments of equivalence of Δi. We are interested only in neighbors of l - 1 which positions are right than l - 1. Let a is position of first neighbor, b is position of second neighbor, without loss of generality a < b. Then  ,
, 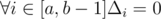 ,
, 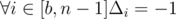 . (elements of permutation are numbered from 0). If a and b aren't exist, for all
. (elements of permutation are numbered from 0). If a and b aren't exist, for all 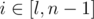 Δi = 1. If only b isn't exist for
Δi = 1. If only b isn't exist for 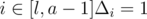 , for
, for 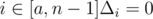 .
.
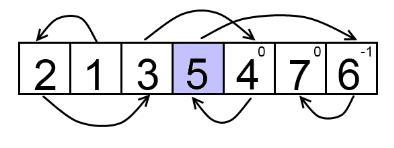
Look at example to clear your understanding. (Δi is in top right corners, l = 3, pl = 5)
Using this facts we can code data structure support following operations:
- Add +1 or -1 on segment
- Calc number of 1 and 2 in the structure.
Sum of answers of structure in every iteration (for every l) is answer to problem.
Let's notice that all numbers in structure will be positive. That's why elements 1 and 2 will be minimal of pre-minimal in the structure. Using this fact we can code segment tree, supports these operations.
Complexity of this solution is  .
.
We also can code sqrt-decomposition and obtain complexity 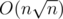 .
.
Problem <>
Translation by fdoer
Main idea: baby-step-giant-step.
In this problem we had some Fibonacci number modulo 1013 f, and we had to determine the position of its first occurence in Fibonacci sequence modulo 1013.
- Let a and b be two different coprime modula — divisors of 1013.
- Let F be the actual Fibonacci number such that
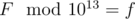 . Then
. Then 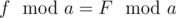 and
and 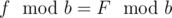 .
. - Find all occurences of number
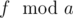 in Fibonacci sequence modulo a period.
in Fibonacci sequence modulo a period. - Find all occurences of number
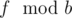 in Fibonacci sequence modulo b period.
in Fibonacci sequence modulo b period. - Let's fix a pair of such occurences. Let the occurence modulo a be in position i, and the occurence modulo b be in position j.
- Let t(m) be Fibonacci sequence modulo m period.
- From the Chinese Remainder Theorem, it follows that t(ab) = LCM(t(a), t(b)) (remember that a and b are coprime).
- Then from fixed occurences of f in periods of sequences modulo a and b we can recover the position of occurence of f in period of sequence modulo ab. It could be done by solving the following Diophantine equation: i + t(a) * x = j + t(b) * y. We can solve it using a simple bruteforce of one of the roots.
- If the occurence in sequence modulo ab period ( we have just found it) is u, then every occurence f in Fibonacci sequence modulo 1013 period can be represented as t(ab) * k + u. Then let's bruteforce k and find all occurences in sequence modulo 1013 period. To determine Fibonacci number on position α + t(ab) from known Fibonacci number on position α, we need to multiply the vector (Fα, Fα + 1) and some matrix.
- Let's choose a = 59 and b = 213. Note that there is no number that occur Fibonacci sequence modulo a or b period more than 8 times. That means that total count of pairs will never be greater than 64. For each occurence we'll bruteforce not more than
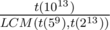 numbers. That was the author's solution.
numbers. That was the author's solution.
Also that was possible to use the fact that for any number the count of its occurences in period of sequence modulo 10p (for any natural p) is not big more efficiently. From occurences in sequence modulo 10i period we could get occurences in sequence modulo 10i + 1 period using the method we use to jump from modulus ab to modulus 1013.







I did it in O(n^2). I always do. It was a really nice problem, everyone got hacked :)
Is Problem “Hamming distance” perfectly designed?
I mean if the number of strings is not 4,such as 5,6,7 or bigger,the number of variables is much bigger than equation number.How can we solve it in this situation?
It's solvable, yes. We have system of linear equations and limitations (all values must be non-negative). In that case you can use simplex-mathod and Homori method. I can't tell you more because i'm not sure how it works. But it's so hard for me, and it's not beautiful in my opinion.
I think this solution still works but you have to set a new equation system, and it's going to be more than 7 variables. The rest of the algorithm should be the same.
But in this solution,we need to enumerate more than one free variables.
That was exactly my solution for xor but I got TLE...
Maybe, you didn't really cut off the branches which have two xors in a row in the recursive tree.
Your solution have right complexity, yes. But it's so slow because of using vector as parameter in recoursive function. Test 3 is not maximal test. Optimise your solution, remove vectors, long longs etc. And it will pass the tests.
ah thanks
I don't quite get this. How do you get rid of the u factor?
Edit : Ah nvm. I see it now :).
One variable steel be free. Let’s fix it. It’s value can’t be more than maximum of h(si, sj) because column adds positive value to one or more Hamming distance. For every fixed value we should check if all variables take non-negative integer value and choose the best answer.
what do you mean ???? which variable????
We have six linear equations with seven variables. Number of variables greater than number of equations. Because of this we have one free variable. In other words we can represent every variable except for free as f(x) where x is free variable.
For example there are one free variable in this system of linear equations:
x, y and z can be free because we can represent any two variables as f(a) where a is free variable. Is it clear?
Sorry for my English..
I mean how did you get the last restriction ?
The number of columns is fixed ?
Why it can’t be more than maximum of h(si, sj)?
I think your prove might be insufficient,because the column's contributions to hamming distances are not arbitrary,it have some pattern.
Look, every column except <> and <> (we don't use it) add 1 to some h(si, sj) because there are two different letters in every such column. For example, if we add column <> to the answer h(s0, s3) will increase by one (h(s1, s3) and h(s2, s3) will increase too). Therefore number of every type of columns doesn't exceed h(si, sj) if letter i differs with letter j in this column. We obtain that number of every type of columns doesn't exceed some h(si, sj). Then number of every column doesn't exceed maximum of h(si, sj).
about div1 Problem E, how to count t(10^13)?
In ques A of Div 1, let us say the grid/matrix : )
)
How can deleting 2 cells eventually disconnect the whole component? If corner of the grid is deleted, then also some column will certainly have a colored cell sharing a side, just beneath it. Am I doing it right?
We denote the row number from up to down as 1,2,..., and the column number from left to right as 1,2,.... If we delete (row=1,column=2)-th and (row=2,column=1)-th cells, the original graph will be disconnected, since the (row=1,column=1)-th cell has been isolated from the other part.
As a feasible solution, we could check the degree of each cell, and if some cell has degree-1, then the answer is 1 by deleting its unique neighbor; otherwise, we could find a cell with degree-2, and deleting its two neighbors gives answer 2. If can be proved that there exists at least one cell with degree-2.
Got it.Thanks!
it will fail on TC-7
You are right, and thank you for pointing out my mistake. Test 7 is a nice counter-example to my solution described above. I think the correct one is to run tarjan algorithm to find if there exists a cutting node. If yes, the answer is 1, and ohterwise it should be 2.
yes