


779A - Перераспределение учеников
Автор задачи: MikeMirzayanov
Для решения данной задачи воспользуемся массивом cnt[]. Проитерируемся по первому массиву с успеваемостями, и если очередная успеваемость равна x, увеличим cnt[x] на единицу. Аналогичным образом, проитерируемся по второму массиву, и если очередная успеваемость равна y, уменьшим cnt[y] на единицу.
Если после этого хотя бы один из элементов массива cnt нечетный, ответом будет - 1 (это означает, что учеников с такой успеваемостью нечетное количество и их никак не удастся разделить пополам). Если же все элементы массива четны, то ответом будет сумма абсолютных величин массива cnt, делённых пополам, причем итоговую сумму тоже нужно разделить пополам, так как каждый обмен при таком нахождении ответа будет посчитан дважды.
779B - Странное округление
Автор задачи: MikeMirzayanov
Для решения данной задачи нам нужно добиться того, чтобы в числе n в конце было k нулей, а перед ними хотя бы одна ненулевая цифра. Будем рассматривать число n как строку и пройдем по ней, начиная с конца (то есть с самого младшего разряда). Пусть cnt равно количеству цифр, которые мы уже рассмотрели. Если очередной символ строки не равен нулю, увеличим ответ на единицу. Если cnt стало равно k и мы рассмотрели не все цифры в строке n — выводим ответ.
В противном случае, нужно удалить из строки все символы, кроме одного, который равен нулю (если таковых несколько, то нужно оставить ровно один из них). Таковой символ обязательно найдется, так как гарантируется, что ответ существует.
779C - Нечестные продавцы
Авторы задачи: MikeMirzayanov и fcspartakm
Для решения данной задачи нужно отсортировать все товары по возрастанию величин ai - bi. Затем нужно проитерироваться по отсортированному массиву. Для очередного товара x, если мы еще не купили k товаров сейчас или после скидок товар x будет стоит не больше, чем сейчас, нужно купить его по цене ax, в противном случае, нужно купить товар x по цене bx.
778A - Игра на строке
Автор задачи: FireZi
В задаче нужно понять, в какой последний момент времени строка t будет такой, что из нее можно получить p вычеркиванием букв. Если в данный момент из строки t можно получить строку p вычеркиванием букв, то и в любой момент до этого это также можно было сделать. Поэтому решение — двоичный поиск по числу ходов, которые сделала Настя. Нужно для фиксированного момента времени m проверять, может ли p быть получена из t. Надо сделать m вычеркиваний Насти и проверить, что p подпоследовательность этой строки.
778B - Побитовая формула
Автор задачи: burakov28
Заметим, что задача по битам независима: изменение только значение i-го бита влияет только i-е биты других переменных. А сумма значений переменных больше, чем больше переменных имеют единицу на i-й позиции.
Будем решать задачу для i-го бита, то есть узнаем чему должен быть равен i-й бит загаданного числа. Для этого переберем оба значения и просимулируем программу, заданную во входном файле. Выберем то из двух значений, которое дает больше переменных, на которых стоит единица на i-й позиции. При равенстве выберем минимальное значение, то есть 0.
778C - Петрович --- полиглот
Авторы задачи: niyaznigmatul и YakutovDmitriy
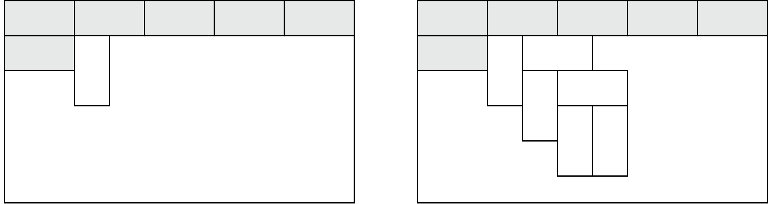
При удалении буквы с индексом p бор меняется так, что все ребра из вершины на глубине p склеиваются в одно, как это видно на картинке из пояснения к примеру. После того, как ребра склеиваются, из нескольких поддеревьев получается их объединение.
Заметим известный интересный факт: если для всех вершин дерева v, пробежаться по всем поддеревьям детей v, кроме самого большого, то это будет работать за 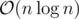 суммарно.
суммарно.
Пусть sx — размер поддерева с корнем в вершине x. Рассмотрим ребенка v с самым большим поддеревом — hv, то есть su ≤ shv для всех u — детей v. Если u — ребенок v, и поддерево с корнем в u не самое большое среди детей v, то 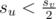 .
.
Пусть
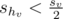 . Тогда
. Тогда 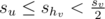 и следовательно .
и следовательно .А если же
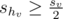 , то мы знаем, что su + shv < sv, и из этого следует, что
, то мы знаем, что su + shv < sv, и из этого следует, что 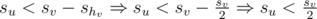 .
.
То есть, если мы рассмотрим вершину w и посмотрим, когда мы по ней пробегались. Пойдем вверх по дереву из вершины w, каждый раз когда мы ее перебирали, размер текущего поддерева хотя бы удваивался. Из этого следует, что каждую вершину мы перебирали не более 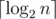 раз. Это доказывает оценку на все вершины суммарно.
раз. Это доказывает оценку на все вершины суммарно.
Решение:
1, Перебрать число p
2. Перебрать все вершины v на глубине p
3. Объединить все поддеревья пробежавшись по всем поддеревьям кроме самого большого.
Как объединить поддеревья? Метод первый. Найдем самое большое поддерево, оно уже построено. Попробуем к нему добавить какое-нибудь другое поддерево. Для этого обойдем маленькое поддерево, параллельно проходясь по большому и добавляя вершины, которых в большом нет. Тем самым мы объединим все поддеревья с корнями в детях вершины v и узнаем размер объединения. Далее, надо вернуть все на место. Для этого во время объединения запомним все ячейки памяти, которые изменились, и их старые значения. После объединения, можно в обратном порядке восстановить старые значения.
Можно ли сделать объединение без отката? Метод второй. Возьмем все поддеревья кроме самого большого. Построим их объединение в новой памяти. После чего, имея теперь два поддерева: самое большое и объединение всех кроме самого большого, можно найти размер объединения этих двух поддеревьев ничего не изменяя, просто пробежавшись по одному из них, параллельно изучив есть ли такие же вершины во втором. После чего ту новую память, куда мы положили объединение, можно будет переиспользовать.
778D - Перекладывание паркета
Автор задачи: pashka
Пусть ширина прямоугольника четная (если нет — повернем). Приведем обе конфигурации к такому виду, что все плитки лежат горизонтально. После этого, поскольку все ходы обратимы, нужно просто развернуть последовательность ходов для второй конфигурации.

Как получить конфигурацию в которой все плитки лежат горизонтально. Пойдем сверху вниз, слева направо, и будем выставлять все плитки в правильное положение. Пусть плитка стоит неправильно. Тогда попробуем повернуть ее в правильное положение. Если это не получается, потому что соседняя плитка ориентирована по-другому, перейдем рекурсивно к ней. Таким образом, получится "лесенка", которая не может идти дальше, чем на n плиток вниз. В конце этой лесенки будет две плитки, ориентированные одинаково. Производя операции снизу вверх, выставим верхнюю плитку в горизонтальное положение.
778E - Продажа чисел
Авторы задачи: niyaznigmatul и VArtem
Поскольку ответ на задачу считается независимо по каждому разряду во всех числах, будем использовать динамическое программирование. Обозначим dpk, C за максимальную возможную стоимость цифр, где k — количество рассмотренных младших разрядов, а C — множество чисел, в которых произошел перенос. Этой информации достаточно, чтобы выбрать, какую цифру поставить в текущем разряде A, и пересчитать переносы в следующий разряд и значение ДП.
Ключевой идеей является то, что возможных множеств чисел не 2n, а не более n + 1. Пусть мы рассмотрели k младших разрядов A и Bi. Рассмотрим все суффиксы чисел Bi длины k, отсортируем их по убыванию лексикографически. Из-за того, что ко всем этим суффиксам в результате добавится одно и то же число, свойство <<иметь перенос>> монотонно: если в числе Bx произойдет перенос, то перенос произойдет и во всех больших числах. Отсюда множество всех чисел, в которых будет перенос в текущем разряде, образует префикс длины m (0 ≤ m ≤ n) этого отсортированного списка. Таким образом, количество состояний ДП сократилось до O(n·|A|). Отсортировать все суффиксы чисел Bi можно с помощью цифровой сортировки за O(n·max |Bi|), приписывая каждый раз слева очередную цифру и пересчитывая порядок.
Осталось реализовать вычисление переходов в ДП за O(1). Для этого нужно поддерживать суммарную стоимость всех цифр в этом разряде, а также количество чисел с переносом в следующий разряд. При добавлении очередного числа с переносом эти величины несложно пересчитываются. После того, как все цифры в A обработаны, нужно обработать оставшиеся цифры в Bi (если такие есть) и взять наилучший ответ. Время работы: 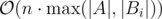 .
.







somebody plzz tell how to do string game using binary search.i read tutorial but i didn't get it..
Let's consider the first test case, where you have this order of deleting characters:
Let's write down if we could obtain the target word after deleting characters order[0], order[1], ... order[i] of the original word (Note that we always delete characters in this order):
This sequence is monotonous and thus, we could do a binary search to find the maximum index, which brings "YES". :)
Hope that helps!
Help me plzzz,What's wrong with my code ? (time limit on test 10) String game 25102212
It's a bruteforce, not a binary search.
Where's the editorial for Div. 1 C and Div. 1 D?
The way I implemented C was pretty much brute force, but if you calculate the complexity it's N * 26 Log(N).
For each node U, you count how many duplicate nodes you'll have in its subtree if you remove it and its outgoing edges. We add this to the number of removals for level(U) + 1.
So you'll have a dfs(vector v), where all vertices in v are equivalent with respect to U (same prefix in the sub-trie). Since all are equivalent you add v.size()-1 to the number of duplicates. Now for every letter c, you make the vector of nodes that are children of a node in v through an edge labelled with letter c. Now do (at most) 26 dfs calls, one for each new vector. If the current size of the node vector is 1 or 0, you stop since there won't be any extra duplicates. The initial call is dfs(children of U).
Submission
Your solution is also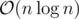 , because if the size of v is 26, then n is distributed in this 26 subtrees, so every time you call
, because if the size of v is 26, then n is distributed in this 26 subtrees, so every time you call
dfs3withv.size() == k, you use k nodes. You use only nodes, which are duplicate, that's why it's the same as if you only iterated over the small subtree.Can you elaborate on the the statement: "The complexity is N*26log(N)". That is the most vague part in your solution
778C: I dont know why you wrote about biggest child of vertex. I implemented your solution and then removed "lets merge all subtrees to the biggest subtree" rule — it became even faster (935ms 146Mb vs 732ms 124Mb)
So plain solution with rollbacks works.
No, your solution makes link to whole subtree, instead of copying it. That's why your merge function works in min(s1, s2) time, where s1 and s2 are the sizes of the subtrees, which is equivalent to iterating over "all vertices in all subtrees except the largest one".
Could you please explain why they are equivalent? It really puzzled me.
Because
dfsvisits vertex for the first time if it's in both subtrees, that are being merged. Every next time the vertex is visited, it appears again in a new subtree. It means vertex is visited k - 1 times, if it appeared in k subtrees. So, consider biggest subtree and for every vertex this - 1 from k - 1 means "we don't visit biggest subtree".Got it. Thanks a lot.
what is wrong with my appraoch for "778C — Peterson Polyglot"? normal dfs when i enter vertex i try to kill its children and count the children of the children which occur more than once + number of its children and update kill[depth] after that iterate over kill get the largest one x to be the solution (n-x)... can any one help me http://codeforces.com/contest/778/submission/25119082
I got the same problem. Try this test case 7 1 2 a 1 3 b 2 4 b 4 6 c 3 5 b 5 7 c
This should've been in pretests before the big test case # 3.
779B непонятно: входные данные 10203049 2 выходные данные 3 Там же 4 и 9 можно удалить, и получится, что число нацело делится.
Должно делиться на 10 во второй, то-есть на 100
Так 10203000 делится на 100 нацело.
Удалить это удалить, а не заменить на 00. Если бы удаление делалось заменой на нули, то не было бы возможности получить один 0, в примерах.
Can someone explain the time complexity of the binary search solution to the String Game problem?
I hope someone reply, especially the author Mr.niyaznigmatul :).
In problem 779C, what's about this approach?:
We firstly iterate over the
nnumbers and take all items which its cost now is less than or equal to its cost after week, because we need to buy at leastkitems now. So, we can buy more thankitems!Secondly, for the rest of the items, we do what the approach in the editorial do.
This is my submission which depends on my approach and gets WA.
Please, reply.
UPD: I was wrong when I think that my approach is deferent from the approach mentioned in the editorial. I used
setdata structure for sorting, ignoring that there may be equal entries. Now I fixed my code :). Sorry for disturbing you.Can u please help me in string game problem.
I am not getting how to apply binary search.
Please tell the approach and if possible please share your code with comments, that would me to understand in better way