


221A - Little Elephant and Function
In this problems you should notice that the answer for the problem is always of the following form: n, 1, 2, 3, ..., n-1. In such case array will be always sorted after the end of the algorithm.
221B - Little Elephant and Numbers
Here you just need to find all divisors of n. This can be done using standart algorithm with iterating from 1 to sqrt(n). After that you need to write some function that checks whether two numbers has same digits. This also can be done using simple loops.
220A - Little Elephant and Problem
There are multiple possible solutions for this problem. For example, the following. Find the last index x such that there exists some y (y < x) (minimal possible) that Ax < Ay. Then you just need to try two possibilities — either swap Ax and Ay, or don't change anything.
220B - Little Elephant and Array
This problem can be solve in simpler O(NsqrtN) solution, but I will describe O(NlogN) one.
We will solve this problem in offline. For each x (0 ≤ x < n) we should keep all the queries that end in x. Iterate that x from 0 to n - 1. Also we need to keep some array D such that for current x Dl + Dl + 1 + ... + Dx will be the answer for query [l;x]. To keep D correct, before the processing all queries that end in x, we need to update D. Let t be the current integer in A, i. e. Ax, and vector P be the list of indices of previous occurences of t (0-based numeration of vector). Then, if |P| ≥ t, you need to add 1 to DP[|P| - t], because this position is now the first (from right) that contains exactly t occurences of t. After that, if |P| > t, you need to subtract 2 from DP[|P| - t - 1], in order to close current interval and cancel previous. Finally, if |P| > t + 1, then you need additionally add 1 to DP[|P| - t - 2] to cancel previous close of the interval.
220C - Little Elephant and Shifts
Each of the shifts can be divided into two parts — the right (the one that starts from occurrence 1) and the left (the rest of the elements). If we could keep minimal distance for each part, the minimal of these numbers will be the answers for the corresponding shift. Lets solve the problems of the right part, the left will be almost the same.
Let we have some shift, for example 34567[12] and the permutation A is 4312765 and B is 2145673, then shifted B is 4567321. Let we keep two sets (S1 and S2). The first will keep all the distances from integers in current left part to the corresponding positions in A (for the example above, it is \texttt{2, 4}). When you come to the next shift, all integers in S1 should be decreased by 1 (that is because all distances are also decreased by 1). But now some integers in set may be negative, when any negative integer occures (it always will be -1) you need to delete it from S1 and put 1 to the S2. Also after shifting to the next shifts, all integers in S2 must be increase by 1. After that, for any shift, the answer will be minimum from the smallest numbers in S1 and S2.
It was very useful to use standart "set" in C++.
220D - Little Elephant and Triangle
Let iterate all possible points that, as we consider, must be the first point. Let it be (x;y). Let the second and the third points be (x1;y1) and (x2;y2). Then the doubled area is |(x1 - x)(y2 - y) - (x2 - x)(y1 - y)|. We need this number to be even and nonzero. For first we will find the number of groups of points that are even, after that just subtract the number of groups with area equal to zero.
For the first subproblem, we need to rewrite our formula. It is equal to |x(y1 - y2) + y(x2 - x1)|. Since we know x and y and we just need to check parity, we can try all possible 24 values of parity of x1, y1, x2 and y2 (let it be d0, d1, d2 and d3, respectively). And check whether they will form a 0 after multiplications and taking modulo 2. If it froms a 0, then add to the answer value cxd0cyd1cxd2cyd3, where cxd is equal to the number of integers between 0 and n, inclusve, that modulo 2 are equal d. cyd is the same but in range [0..m].
Now we need to subtract bad groups — the ones that has the area equal to zero. This means that they will either form a dot or a segment. If it is segment, we can just iterate dx = |x1 - x2| and dy = |y1 - y2| instead of all 4 coordinates. Then the number of such segments on the plane will be (n - dx + 1)(m - dy + 1). Also for counting the number of triples of points on the segment you need to find the number of integer coordinates on the segment. It is well-know problem, and the answer is gcd(dx, dy) + 1.
This gives us, with some simple optimizations, and O(nm) solution.
220E - Little Elephant and Inversions
In this problems you can use a method of two pointers. Also some RMQ are required. If you do not know about RMQ, please, read about it in the Internet before solving this problem.
Firstly, map all the elements in the input array. After that all of them will be in range [0..n - 1]. We need to keep two RMQs, both of size n. Let the first RMQ be Q1 and the second Q2. Q1i will contain the number of numbers i in current left subarray. Q2i will contain the number of numbers i in the left subarray. Firstly, add all n number to the Q2. After that iterate some pointer r from n - 1 downto 1, by the way keeping point l (which, at the beggining, is equal to n - 1) Using RMQs, you can keep the number of inversions when you decrease r or l (using "sum on the range" operation). While the current number of inversions is more then k and l ≥ 0, decrease l. Then for each r the answer of correct l will be l + 1 (considering 0-based numeration).
This makes the algorithm working in O(NlogN) time with correct realisation.







I can't understand why doubled area is:|(x1 - x)(y2 - y) - (x2 - x)(y1 - y)|...can any one tell me why?
cross product?
Thank you...I am just on thinking about the meaning of this formula in classical geometry...a silly question...
In Div 1, Problem B, what is O(NsqrtN) solution?
For each two queries [l1, r1] and [l2, r2] we can easily change the first query to the second in no more than |l1 - l2| + |r1 - r2| operates.(adding or deleting the leftmost and rightmost elements and counting the number of times that each number appears)
Sort all the queries by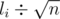 as primary sort key, and ri as secondary sort key. Now we can get a
as primary sort key, and ri as secondary sort key. Now we can get a 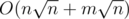 offline solution.
offline solution.
Why do you sort the queries by l/sqrt(n)
Split l into groups. We can ensure that
groups. We can ensure that 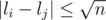 if i, j are belong to the same group.
if i, j are belong to the same group.
So we can calculate the complexity as follow:
a very underrated explanation thanks dude i was struggling with this problem
There is a much easier one. Just considering number x that occurs at least x times in sequence a. It's not hard to prove that there are at most 2*sqrt(N) numbers to be considered.
Can Anybody explain me , why are there at most 2*sqrt(N) of such numbers?. Thanks in advance.
(C[x] means the times that x occurs in sequence a) if C[x]>=sqrt(N), the number of this kind x is no more than sqrt(N). otherwise the number of elements in sequence a is greater than sqrt(N)*sqrt(N)=N if C[x]<sqrt(N), 1<=x<=C[x]<sqrt(N)
consider the best case of those numbers: 1,2,2,3,3,3,...,x,...(x-2 times)..,x so the amount of these are: x(x+1)/2 so x has to smaller than 2Rad(x)
GREAT
220E — we use RSQ, not RMQ
220B: why has the proposed solution nlogn complexity? I mean, if for each x I need to sum up D_l, D_l+1 etc to answer to the queries (that in worst case start from 0 and end to x for each x), isn't it N^2?
you can use segment tree to query 0 to x....
BIT is easier and faster to implement here.
In explanation of 220C, what does this mean " (for the example above, it is texttt{2, 4}) " ? Does it mean that left set has a minimum distance of 2 and right set a minimum of 4?
\texttt was a tag, now it's fixed.
[2, 4] is the set of distances in right part, i. e. distance from 1 in sifted B to 1 in A (it is equal to 4) and distance from 2 in shifted B to 1 in A (it is 2).
In problem A, for example, n = 3, if the init array is (3, 1, 2) (author's solution), isn't the sorted array is (3, 1, 2) -> (3, 2, 1) -> (2, 3, 1)? Did I mis-understand something?
PS: I know it's weird for a purple to stuck at Div2-A, but this one confused me a lot...
Edit: I got it, the sort happened after we enter function f[x-1], so it should be (3, 1, 2) -> (1, 3, 2) -> (1, 2, 3). I don't know what happened with my brain today...
220B — Little Elephant and Array, can anybody explain me how the update (add 1 to D[|p| — t], add -2 to D[|p| — t — 1], and add 1 to D[|p| — t — 2]) work?
I had a different approach
first of all count the numbers an remove numbers like x which occurred less than x times at all now you have at most O( sqrt(n) ) numbers.
for each of these store the indexes. for example store the indexes in which x occurred in vector[x].
now for each query(x,y) all you need to do is to binary search in each vector and find lower bound of x and upper bound of y( lets name them lbx and uby ) now we easily find out that x occurred ( uby-lbx ) times in [x...y]
it will solve the problem in O( N*sqrt(n) + Q*sqrt(n)* log( vector size ) )
can u give some advice , i write by mo's algorithm but it gives me tle http://codeforces.com/contest/220/submission/17425102
I think your algorithm runs in O(nsqrt(n)log(n) .It absolutely gets TLE. You can reduce log(n) to O(1) (remove or update operations) by just considering element which has value <= 1e5 . Cause every element greater than 1e5 can not contribute to the answer of a query . So you can use just a array instead of map
I have implemented the exact same logic but still getting a TLE.
Can you please take a look at my code?
72203897
Thanks in advance.
Your code complexity is m*k*log(sz) where k = total numbers whose occurrence needs be checked(maximum = sqrt(n)) and sz = size of total occurrence of that particular number in array(it can be sqrt(n) don't know the maximum bound). log(sz) which adds larger constant is responsible for TLE.
thank you for sharing your approach
In case if anyone finds the explanation for Div2D/Div1B confusing, just Google "MO's algorithm". Can't believe this magic man...
Little Elephant and Array can be solved with hashing. Since n*(n+1)/2<=100000, therefore n<=450, which is the condition for tightest constraints i.e. n=10000 and all numbers 'a[i]' are distinct and appear 'a[i]' times.
Solution: http://codeforces.com/contest/220/submission/20777330
how for for problem D complexity can be achieved O(mn)
Witua is known to set beautiful problems and this contest was fantastic !
Here are my solutions to the Div 2 problems of this contest.
In Div 2, problem D captured my imagination. So, I wrote an editorial about it here that explains both the approaches.
I love your editorial. its very comprehensive
could someone explain 220C. Little Elephant and Shifts bit more
How to solve Div 1 B using sqrt decomposition rather than MO's algorithm??
My solution for div1C is a little different. I know this is an old problem but I found it really interesting.
Let's graph the problem. Let's assume each cyclic shift happens in 1 second. Plot time along the x axis and the absolute difference in positions in both arrays for each value along the y axis.
Observe that there can be only two possible values of the slopes of the lines in the entire graph — +1 and -1. The line for a particular value will have slope equal to +1 if the position of the value in that instant's cyclically shifted array b is <= its fixed position in array, otherwise its slope will be -1.
Moreover it's easy to notice that for a particular value, its slope value changes a maximum of 2 times in its graph.
So we can maintain two range minimum segment trees with lazy propagation range updates for slope value = +1 and -1, each of which store the minimum y-intercept value at each integer instant from x = 0 to n-1. Then for at any given x, the answer is $$$ min \ ( i \ + \ minimum \ y-intercept \ of \ slope \ = \ +1 \ at \ x \ \ = \ i \ ,-i \ + \ minimum \ y-intercept \ of \ slope \ = \ -1 \ at \ x \ = \ i \ ) $$$
Total complexity is O(nlogn)
My submission: 57004696
(I've shifted the entire graph by 1 unit to the right to avoid using a segment tree with 0-indexing in my submission)
"Q1i will contain the number of numbers i in current left subarray. Q2i will contain the number of numbers i in the left subarray." ?
right!
For those of you getting TLE in Square root decomposition try using a different comparator or try changing the Maps to array
You can check my submissions 80679872
I dont get it to implement the tutorials solution to 220B - Little Elephant and Array
Can somebody link a submission implementing it? I did not found one because there are so much sqrt solution or something else.
Hopefully this one is clear enough...
And just look for MO's algorithm using square root decomposition i just learnt it yesterday actually..
The main idea in sorting the query and taking most possible advantage of overlapping queries since we can do it offline.
I also found this comment useful.
Kinda late, but here you go, hope this helps.
90807410
Please explain the 3 major update operations in your solution too it is not clear to me from tutorial and also from the submission.
learn a lot after solving Little Elephant and Inversions using binary indexed tree and cool idea of two pointers and inclusion exclusion principle
I solved it in a rather ridiculous manner. I created a segment tree to store the merge sort results at each recursion level. Then first I calculated the number of inversions at each index, from 0 to that index in one array, from that index to n — 1 in another array. Lastly, I used two pointers method to find the total number of inversions. If the total inversions in the array originally was greater than k, and the array had at least three elements, forward pointer pointed at 0, backward pointer pointed at 3, at each iteration, if the sum of inversions count of forward array (0 to forward pointer), backward array (backward pointer to n), and the number of inversions for each element in forward array to backward array (stored in variable named ptionk) was added to check if inversion count is greater than k, if so, backward pointer was incremented, else forward pointer was incremented. Each incrementation, I added the number of inversions increased or decreased (due to removing an element from backward array or adding an element to forward array) to ptionk. Am I the only one who did it like this