


I invite you to participate in the rated Codeforces Round #499. Date and time of the round: Jul/26/2018 18:05 (Moscow time).
Those whose rating is not less than 1900 can participate in the round Div.1. Other can participate in the round Div.2.
Do not skip this contest, because the next Codeforces Round (Div.1, Div.2, or Div.3), which number begins with the digit '4', will be through the 3501 rounds!
This is the first competition I proposed. I hope that you will enjoy it.
The round will have 6 problems for each division (4 problems are common). The contest will last for 2 hours.
The main heroine of the competition is astronaut Natasha, Mars researcher. If you solve all problems, her flight will pass successfully.
Five problems of the contest are invented by me, Vladislav Zavodnik (VladProg), problems Div2.A and Div2.B are invented by Mike Mirzayanov (MikeMirzayanov), and problem Div1.F is invented by Ildar Gainullin (300iq) and Dmitry Sayutin (cdkrot).
Also thanks to:
Ildar Gainullin (300iq), Dmitry Sayutin (cdkrot), and Mike Mirzayanov (MikeMirzayanov) for help in preparing the problems;
Ivan Safonov (isaf27), Andrew Rayskiy (GreenGrape), Egor Gorbachev (peltorator), Grigory Reznikov (vintage_Vlad_Makeev), Costin-Andrei Oncescu (geniucos), Yuhao Du (jqdai0815), Ziqian Zhong (TLE), Andrey Khalyavin (halyavin), and Shuyi Yan (fateice) for testing the round;
Mike Mirzayanov (MikeMirzayanov) for Codeforces and Polygon platforms.
Scoring distribution will be announced later.
I wish you a high rating and I am looking forward to see you at the competition!
UPD1
Pay attention: count of problems at the round was changed. The round will have 6 problems for each division (4 problems are common).
The round will have one interactive problem for both divisions. Please, read the post about it here: Interactive Problems: Guide for Participants.
UPD2. Scoring distribution:
Div.2: 500, 1000, 1250, 1500, 2000, 2500
Div.1: 500, 750, 1000, 1500, 2250, 2750
UPD3. The contest is over. Congratulations to the winners!
Div.1:
Div.2:
UPD4. Editorial is published.







I wish high ratings for everyone.
I also wish, but, how it possible to have high ratings to everyone, as the top of the standing possibly have rating increment where the bottom have possibility of rating decrement. :P
it can happen, do your best.
Contest after a while and interestingly contest numbers are in binary (1010,1011) (; )).
And 1010 is 10 in binary :D (1011 is also 11 in binary, of course)
Unfortunately, Natasha’s flight won’t pass that successfully for me, she may fly to the Moon instead of Mars :P
I will be happy if I can get the plane to take off :P
After a wait of 10 days, coders are back to pavilion!! High ratings to everyone :)
In 2080: Codefoces Round #4000.
at least we still have two more "Educational Codeforces Round" 48 & 49 next two month maybe, which number begins with the digit '4' , and the next Round will be through only the 351 round
but surely we will enjoy this competition :)
I want to read this comment before round #4000. There will come a time when all of us will be old/dead, but the sport of cp will be one of the biggest.
I don't think that we are all will be so old. Suppose that CF holds a round once at every 3 days, it takes (4000-500)*3=10500 days or just 29 years. Due to the recent russian government's reform, we won't even reach the age of retirement.
Lol no, there are 60-70 cf rounds per year, not 1 per 3 days
Lol. isaf27 and peltorator.
Your nickname makes the situation better.
If one can solve all the problems, will he be hired by Elon Musk?
_kun_? Is It a mathforces?Probably it is anime.
A lot of days(8) for div3 participants wait for this contest.
Expectations are so high ratings.
Yes,it's 11 days for div.1 coders,wish more div.1 contests.
"The main heroine of the competition is astronaut Natasha, Mars researcher. If you solve all problems, her flight will pass successfully."
Is this just a cover up for the "tragic malfunction" of Natasha's mission? Remember, you heard it here first.
In chinese, '4' is ominous .
'4' means death in Chinese
so it's nirvana after this contest
To be specific, 四(sì, meaning 4) sounds like 死 (sǐ, meaning death) in Mandarin. If Mandarin word for death was actually "4" that would be pretty funny :)
Edit: Oh no I have 4 upvotes!
Say goodbye to codeforces round 4XX and say hello to codeforces round 5XX .
A new start for codeforces!(Shouldn't send us rating as celebrate?)
?detaR tI sI
"the next codeforces round(**Div.1, Div.2 or Div.3**) which begins with the digit 4..." What if codeforces round #4000 will be Div.4?
Almost every comment has upvotes, that's something new for Codeforces
That's because Wael.Al.Jamal didn't comment yet
"Do not skip this contest, because the next Codeforces Round (Div.1, Div.2, or Div.3), which number begins with the digit '4', will be through the 3501 round!"
Can anyone explain in simple terms what this means?
499 + 3501 = 4000
Listen to the lecture, please!
:O
i'm very excited for contest , i wish best for all
Me too, some of the great setters and testers are on board, hopes are high!
If you upvote this comment, you will get a positive rating change in the contest!
If you upvote my comment, you will get LGM after the contest.
I think if I upvote your comment then you will get positive contribution change.
But it doesn't cancel positive rating change!!!
up-and-down It worked ;)
You saved me, somehow I got + even though my C failed systests :)
Best of Luck Minna-san!
First of all thanks for letting us know there is an interactive problem, secondly can we know what problem it will be??? Div.2 C/D/E/F ???
Author:you're asking too much.:)
Its confirmed three legends (jqdai0815 , fateice , halyavin ) are not in this contest. Because they are the tester of this round.
When will we see announcement of Div.1+Div.2 combined round?
See the DARKSIDE of today's round here.
** ** *****?
***.
We need to postpone contes 5 min. and I might make it in time from work. Thanks
Since halyavin is a tester of this round. I think it will have very strong pretest.I hope halyavin will not fail me :')
Ouch.. so many hacks :D
lol
I think halyavin didn't test problem C.Many solutions failed system test.
It's really pitty there is no live disscussion after round with scott_wu and ecnerwala. Competition is more interesting for 30% to me.
Going to be my first official contest. Any tips, anyone?
Ask "Is it rated?" in the comments.
I am submitting my solution for Div2B and I am getting the wrong answer for pretest 4. It,s displaying that my answer is 2 whereas when checking on my personal IDE I am the getting the right answer that is 3. I have submitted the solution in different versions of c++ and every time I am getting a different answer for the exact same code. Why is so?
Possibly your problem works differently on your pc and codeforces due to undefined behaviour or some bug in your code.
You can try using the "Run" tab to run custom code with custom input on codeforces system.
You can also try using "diagnostics" compiler to detect such bugs
In problem E: their emperor decided to take tax from every tourist who visited the planet. Well,then theoretically Natasha does not have to give any money :I
lame joke :/
div 2 = div 3
Interactive problems don't like me :(
In D wha do i have to do with this: wrong output format Unexpected end of file — int32 expected?????
Your program was terminated before getting '0' answer from rocket.
Did someone forgot to a[i]%=k before taking the gcd in problem c? T_T
Does it matter? The answer should still be the same right?
not if you dont take gcd with k
Then it's a different mistake. For the only number k - 1 you must find gcd and don't have to do modulo.
Solution for question B??
Div2B was harder than A,C,D combined.
I made an array of food supply sizes (how much of each food), sorted them in decreasing order, and then greedily assigned people to food in the following way:
(used[i] represents how many currently assigned to food type i)
add 1 person to food type i as long as size[i]/(used[i]+1) is the maximum
you add n times, to find this maximum is O(n) so its n^2
but n^4 even passes so any polynomial solution should work
sorry I can't prove this, we will see by systests
https://pastebin.com/PBm7nExi
It was not hard
what if more than one person is assigned to one type of food?
For every food, I add to sum, the number of people that can be assigned to this food. So in the end, sum is equal to the maximum number of people I can feed.
OHHHH IT WAS ACTUALLY SO SIMPLE
QAQ
dude i feel stupid, thanks for the soluion though ^0^
EDIT:
I just realize function of answer space is monotonic.
This means b,c,d can all be solved with binary search. Damn
B and C are easier without
I would definitely agree B without, but I think C could be considered "easier" if you don't want to think about edge cases or math.
It is not hard. Let the answer be k. you have to find maximum k which satisfies: sum different food packet quantity/k is greater than equal to n Solution link
Binary search is faster Ans = 0 Left = 1 Right = max value from used vector
No, Div 2 B was just an easy binary search problem (other solutions are also there). But contrary to that you can say today's Div 2 D and E were of level of normal Div 2 C.
I made an array b[101], where b[i] contains the frequency of a[i]. Now iterating i from 100 to 1 check whether if the food will last for i days (if(sum of b[j]/i) is greater than n).
Thanks :)
what is the hack for Div1 B?
10000 1 10000
1
I was hacked because I forgot to take the index in the sequence modulo N in the binary search part. My guess is most other hacks were because of this too.
How to solve it ?
Print out '1' n times to get the sequence
then binary search
n = 30 log2(m = 1e9) = 29.somethings
should run in 30+30 = 60 iterations
but the sequence can "wrap around" is n is low but m is high, so you mod it or use a base-1 equivalent to modding
I did put the modulo and passed pretests, but then got a runtime error on test 24 and noticed I wrote mod M instead... :(
The following code didn't pass the pretests for A: https://ideone.com/jXjQQE
Why didn't it pass pretests even though it shows correct output on ideone?
Binary search round.
How to solve Div2E?
BFS
failed system tests :(
Take gcd of all numbers including k
let that number be x
print all multiples of x
take the gcd of all numbers and k, let it be a. The answer is k / a and numbers are 0a, 1a, 2a...(k - 1)a
Can you explain the logic behind this ?
Digit d can be good if there is a solution for equation a1 * x1 + a2 * x2 + ... + an * xn - k * x0 = d. It exists if d
dividesis divisible by the gcd of all numbers and k.Is there any proof for this ?
It is well-known criteria for solving linear diophantine equations
@Numb, Do you mean if d is divisible by the gcd (not divides)?
ah yes
UPD : Got it!
Can someone explain to me why this solution for E is wrong?
Green points are beginning and end of open interval, red are the points when it was closed. If there was a red point between the 2 green ones the information is INCORRECT so we are left with this case only, right?
https://imgur.com/a/rDUIgBo
(Please ignore my paint skills)
Edit: Realised I misunderstood the statement , oops.
is div1E just find the bounding box of guaranteed Open values, find the bounding box of guaranteed Closed values (extending this to infinity in the opposite direction as the open values) and then just testing each of the k points to see if they are guaranteed open/close?
Find bounding box of open points (ez)
Find bounding box for each of the k points with the open points (ez)
For each of the k points find the number of closed points in the point's associated bounding box (not ez, 100 lines of 3d sum queries)
If a point is already in the bounding box of the open points, then it is open for sure. If the bounding box for one of the k points contains a closed point, then that point has to be closed, otherwise it is unknown.
ohh okay its more complicated than i thought NVM sorry
edit: are 3d sum queries necessary? doesnt it suffice just to find bounding box of open points, bounding box of closed points (extended to infinity), and then check if each other point is within one of the bounding boxes?
I don't think that the bounding box of closed points is really a "box", it would be really hard to maintain that structure and check if a point is contained in the bounding shape of the closed points.
oh right nvm thanks!
E: I think "check if there exist a point in a 3D rectangular" appeared somewhere.
it definitely appeared in 2D version.
Every question is an integer such that 1 <= y <= m. NOOOOOOOOOO missed the <= m :(((
There are solutions without binary search on D2B,C :)
I personally am using *linear search on B
Yeb I solved C in O(n) time by calculating from the last place to first one.
By the way may I ask for B without BS?
No need for binary search in B. Linear search works well in time
Linear search is good enough for B (since the limit is so small) and C can be solved with math :) I would also argue a random solution might have a very small chance of passing for D...
I had no idea how to solve Div2E within TL, and I just wrote a random randomized solution and luckily it passed pretest..? And I don't even know why...?? 40811678
UPD: Failed System Test:)
your solution takes 997 ms out of 1000 ms
i'm sorry but your solution most probably will fail on system test
while(clock() < 0.99*CLOCKS_PER_SEC)This was a great contest, really enjoyed the problems! I made a dumb mistake on the interactive problem (div2D) unfortunately (forgot that upper limit is "m", not 1e9)...
In Div2D problem statement says : If your program's request is not a valid integer between - 231 and 231−1 (inclusive) without leading zeros, then you can get any verdict.
Does this mean that if I request numbers in this range i will get the correct response with respect to problem statement? I got WA1 7 times and wasted some time because of requesting -1 to find out when the rocket lies xD
If you request a -1, you will get -2. You can only request numbers from 1 to m.
Yeah, but for me this sentence was quite misleading...
for me to, but I quickly understood that I can request 1 (not -1) to find when it lies )
BinarySearc(h)es
What is the test case 14 in Div2F?
When you rush to solve div1 D in the last 20 min, speedcode it and are ready to submit it in the very last minute... then notice XOR was also part of the list of operations. feelsbadman
In Problem D, I couldn't accept the input using Python 2.
My simple solution:
The verdict: Idleness limit exceeded.
Any help is appreciated.
didn't flush after print
'print 1' prints '1'. I don't think we can flush this again.
print write to a buffer
stdout.flush() in Python; flushs the buffer to the stdout and clears the buffer
From the problem statement:
I think you are right. But I've never used the 'flush()' method. And that's I thought 'print' prints in real-time.
it will be better when solving next interactive problem. or you can read guide for interactive problem: https://codeforces.com/blog/entry/45307
Thanks a lot.
Did you flush your output?
It was mentioned a few times in the contest announcement and another few times in the problem statement.
My solution: https://codeforces.com/contest/1011/submission/40799411
Div 2D Bound was very nice.... log(base2)(10^9) = 29.89, very close to 30, which was required for the solution! [60 requests — 30 to know true/false]
I mistakenly thought initially that we have to print the answer in the end again (not exiting if answer is 0) so that becomes 61 queries :P
I have to be careful while reading the questions next time
I think we can slide the truth/lie test. It is certain that the x will be greater than or equal to current y. It will reduce the requests slightly.
Coding speed testing round.
Yeah i second that. Problems were rather simpler demanding faster implementation by User
http://codeforces.com/contest/1011/submission/40794998 what's wrong with this method?
Can someone elaborate how does this submission: 40792127 output exactly 60 numbers on hackcase:
It is clearly seen that participant runs non-interrupting cycle with n = 30 iterations, then another one non-interrupting cycle with 30 iterations and afterwards he outputs answer. Am I missing something?
"If the program reads 0, then the distance is correct and you must immediately terminate the program (for example, by calling exit(0)). If you ignore this, you can get any verdict, since your program will continue to read from the closed input stream."
That's probably why. I think the interactor determines that the program is correct before the 61st query is printed (so basically that query is ignored).
Solved Div.2 C — Fly on paper but too panicked to code it. Codeforces contests not good for my heart. Let me go and find some extra slow competitions :P
Marathon Round 2
problem E was easier than D
how to do?
take the gcd of all numbers and k, let it be a. The answer is k / a and numbers are 0a, 1a, 2a...(k - 1)a
I spent the whole contest on F, coded it in a file named A.cpp and submitted F.cpp in the last minute. Looks like it could have passed :/
after seeing problem D in div2, .........................................................????? what?
Seems Test Case 24 in Div2 Problem A is giving WA to many guys!!
Please, can someone explain me, or give me some resource for understanding why next thing in binary search gives TLE:
while(l < r - 0.0000001) DoSomthing();
If I used 1e-7 it gave me TLE, changed to 1e-6 and it passed.
God……I used 1e-8 :(
1) might depend on
doSomething()2) Maybe for big values of l and r the precision isn't good enough and the value (l + r) / 2 is equal to l and r for the computer. You should stop earlier for big answer (it's ok because of relative error).
I believe it's a second thing. Definately precision wasn't good and I got TLE...
Only surprise is that I was using the same binary search for 100 times and never got similar result :)
try long double ?
I got tles when using double . This makes me anxious and ruined the contest :(
At the end I have finished everything with loop and iteration 10000 times.
It ruined my contest too :(
Usually for binary searching on doubles, I just do something like:
for(int step = 0; step < 50; ++step) DoSomething();(One can, of course, adjust the 50 according to requirements/time limit etc)
I think its a floating-point precision thing, especially as numbers get larger and you can't store that many decimal places as 0.0000001
But you can fix the iterations by log2(1e9) = 30 (maybe 100 to be safe? I changed my 100 to 1000 LOL)
The tutorial solution to voltage keepsake did the same, probably because precision of floating-point is a common issue with binary searching on doubles
I used something more safe (in my opinion). I multiplied m by 1e9 and just used regular integer binary search with bounds [1, 1e18]. And then I divide the answer by 1e9 before outputing it. It passed the system tests: 40789915
That's way smarter solution than mine, thank you for sharing.
When you have the answer close to
1E9, the values like1E9and1E9 - 0.0000001can't be distinguished by thedoubledata type.Now, take some two values for
landrwhich are consecutive possibilities to be stored in a double. What will be their average,m = (l + r) * 0.5? It can turn into eitherlorr, no middle ground. After that, if the checking function picks the unlucky one of thel = mandr = m(50% probability), the loop goes forever.is the fix taking 1E9 + 1 as the r value initially?
No, that won't help at all. The comparison
while (l < r - 0.0000001)is the culprit.The best fix is to instead use
for (int step = 0; step < STEPS; step++)for binary search with floating point. WithSTEPSbeing obviously sufficient (200for example).I am not sure why this happened. Maybe some other mistake I committed since I took STEPS as 200 and it failed. But on resubmitting it after contest passed.
Failed Passed
The actual solution is at bottom (top is template only)
In your case, the answer is dependent on whether
if(check(mid))happens at least once. So yeah, your change helps, since otherwise, thechecknever actually runs for the exact upper bound.Another way to fix it is to use a single
ans = lo;after the loop: regardless of what happens inside the loop, after it finished, the boundsloandhiare both close enough to the real answer.Thanks for the help!
I always prefer
forloops when binary search in real numbers.You could've done
for (i=0;i<200;i++) binary_search()I guess this method works too for binary-search on doubles.
Did anybody else do a sorting for div2 b?
See the DARKSIDE of today's round here.
Solves A, B, C, D, E. Goes away for 50 minutes. Comes back. Sees: "solved: 2 out of 6". Deletes Codeforces account.
test your solutions
I tested them a little bit. I still don't know why they failed. Can somebody help me? 40790922 40796015
why you don't test negative fuel after landing
Because the landing doesn't take place if there's no fuel. Would that make a difference?
nvm the condition is in the for loop
for your D's solution, you should modulo nr by n
Thank you. I'm so stupid.
I'm so wondering, for your solution of C, you should read again Input area of this problem
For problem C, I made the same mistake. When you have a solution, which you know is enough, you output it with precision 8. This means, that your output can be smaller than the solution you got, because of precision, and that little change of fuel might won't be enough to land.
Thanks. This sucks :(
Talking about mistakes look at mine, in Div2C instead of writing,
cout<<setprecision(10)<<ans<<endl;
I wrote,
cout<<ans<<setprecision(10)<<endl;
This was the only difference between right and wrong answer.
Today in TCO round I made a bug, but after submitting I stress-tested, found a mistake, resubmitted and got AC. It's funny that the best advice I can give (for TC contests) was downvoted xd
It was downvoted because it's not applicable to this case and you wrote it as if the person in question didn't already follow it.
There is no "best" advice. There are many types of generally good advice; some apply in some situations, some in other ones. In general, testing your solutions is useless if you misunderstand the problem, if there's a catch you haven't ever encountered and don't realise, if your solution is too slow on a specific (strongly non-random) type of tests, etc etc. Meta-advice like "analyse common mistakes you make and ways to avoid them" is better when followed, but that's also harder to do. Practice solving problems more, pick the right problems to practice on, put effort into focusing during contests (if only I could...), learn to read&understand statements faster, learn to do that more carefully, practice coding without bugs, use libraries for standard shit, practice typing faster, try different strategies that play to your strengths, get tools to automate things like testing, write your own e.g. generators, stresstesting on thousands of tests ties into this, there's so much that could be considered good advice... and you can still miss an obscure special case.
Problem C

but it seems you became handsome afterwards
So many red submissions in the standings page :(
Every normal CF round should be like this round. It is awesome!
shitty pretests.
very weak pretests, wow
That's what I call pretests.
May anyone give me a brief overview of test 63 in problem Div1C/Div2E? :<
Got how I failed my solution now.
Thank you, for being incredibly responsive as a setter! ;)
3 consecutive Binary Search problems for div2. I can't believe !
4 actually. If you consider D also. :)
Actually I was talking about B, C, D. What other problem did I miss ?
Can someone prove exact time complexity of my ac solution for div1C? I can prove that it works better than O(k*p(k)) where p(k) is number of primes less than k.
Link: http://codeforces.com/contest/1010/submission/40805461
It works in at most O(k * d(k)) where d(k) is the number of primes in the prime factorization of k because every time you run the inner loop, you end up being able to generate every number that's i * gcd(every number counted so far) and that gcd can change at most d(k) times.
Edit: Actually, it looks like it works in O(n + k)... since the worst possible input for that would be k = power of 2 and the inner loop would run O(1 + 2 + 4 + ... + k) = O(k)
Thank you :D
maybe there are some mistakes in problem c for example ans > 1e9,not put -1,but get accepted.
in problem C , I see the we should use a of the first plant first then for all remaining plants should use b first the a as landing will be before flying and the order is very important as the weight of fuel will update after each fly or land I mean some thing like this
but I found some solutions had got AC and they don't care about the order of flying and landing ,How ? thanks in advance ^_^ UPD: I got confused in reading that code ,there is no problem xDD
One of the best contests lately :) Problems were pretty cool and interesting. Thank you, VladProg and other people who helped to invent problems.
Is CF-Predictor broken? It is not working for me in this contest.
Exciting fact: contest was on CF platform, but Predictor's servers are down ;)
IDK why, but it happens too many times when we need it.
Why is including the constraint i.e. weight of fuel <= 1000000000 for Div2 C, giving WA for test case 76??
I think that my solution to F (upsolved) is interesting:
It turns out that we want to calculate for each i from [1, n] in how many ways can we cut off subtrees of tree so there will be i vertices left. Just doing fft in each vertex isn't enough (caterpillar is a countertest).
Let's use HLD. I have a recursive function (let's say DFS) which takes highest vertex from some path and asks for vector of results for this subtree. Sum of sizes of answers will amortize to O(n * log(n)). For each vertex on heavy path let's use DFS on every son from outside the path. In this problem tree was binary, but my solution works for any tree.
We have many vectors of results and we want to multiply them with fft. I'm using huffman codes on sizes of vectors, it's the best way probably. So for each vertex on path we have vector of results if the whole tree would consist only of this vertex and its sons except the one on this same heavy path. Now we could iterate over "which vertex on this path is cut off" and take product of every polynomial (vector of results) which is higher on path than this vertex. But it's quadratic of course. So we can do divide and conquer on this heavy path. Recursive function should return product of all polynomials in its interval and sum of prefix-products of polynomials. These two polynomials are enough to get the answer.
I'm sure that it's O(n * log3(n)), but it's probably O(n * log2(n)) also.
Here's a link to code: 40812966
Nice solution.
Here is what I did:
Store the generating function whose coefficients are number of connected subgraphs rooted at i of a given size, for a subtree, Ti implicitly as a tuple of (j, Fi(x), Gi(x)), meaning Ti(x) = Tj(x) * Fi(x) + Gi(x), where j is some node in i's subtree. Fi and Gi will have the same degree.
When merging two subtrees, first find the explicit form using fast multiplication for the smaller subtree, and then multiply with larger subtree's polynomial's implicit form.
Also, calculate Ti as an explicit polynomial whenever the degree of F exceeds some value k, else leave it in the implicit form.
Optimal value of k comes to be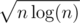 , giving an
, giving an 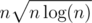 solution.
solution.
Here's the code 40812980
I wish I had submitted the code for the right problem during the contest though :(
Wow, I'm not much into generating functions but I'll for sure take a look into it. I guess that after parsing this comment for a few minutes I'll get it as brilliant :D
Nope, It's similar, just sqrt instead of d&c :/
Yeah, its quite similar. It has nothing fancy to do with generating functions. I just call polynomials as generating functions, when coefficients are of interest.
Wow, I did exactly the same during the contest (but without a good value of k). However, even with the best value of k I still get TLE on test 18. I guess this is hard to squeeze in Java :)
Well, good optimized our solution is working in ~2s, so you are like 2x slower than author solution :)
Nobody cares about your solution radewoosh. India has jatin yadav, who could have solved it within contest and be the only one to do so but couldnt due to turnout of unfortunate events and so a big F YOU on your face.
Get a life
Yea, cause everybody cares about hates of some Specialist :/
Toxic people like you should not be allowed to be in this community. We are all here to learn, and it's awesome to see people sharing their solutions and ideas, enabling us to learn not one but multiple approaches to a single problem.
But there's always that one guy like you, who has to type some shit up and ruin the experience. You should realise you're in no position to talk shit about someone exponentially better than you or compare two people so out of your league.
The last time i saw something drop as hard as your rating, twin towers were nowhere to be seen lol.
Typical keyboard warrior. You know you could spend this time actually learning something.
As far as my rating goes, wait for today's changes :)
Bitch, you will still be blue. No need to be gung-ho about it. As far as my learning goes, i am much more learned than you bitch. So stop throwing stones at others when your own house is made of glass.
Lol kiddo you have no idea. It will hardly take me 4-5 contests to get to Div 1 if I start participating seriously.
And I don't remember the last time I saw a well-learnt person swearing just to prove he's smarter
Stop doing drugs noobie. I have not used a single swear word. Your username clearly suits your mental state.
" It will hardly take me 4-5 contests to get to Div 1 if I start participating seriously." ----Many specialists and borderline experts have said the same to me a thousand times. Stop with the excuses already.
Look brother, I have better things to do than to argue with you. I'm not giving excuses, as I never said that I want to be in Div 1. I said that just because you were questioning my ability for no apparent reason. And yes, what I said is true, it won't take me long to get to Div1 if I really wanted to, but I'm not going to bust my ass just to prove my point to idiots like you. If I do get the time, I will participate seriously, and maybe then we'll talk.
Haha, you seem so mentally,emotionally as well as sexually frustrated with your life. Learn to chill a little. Anyways, Good day "Mr intelligent and capable". You are so great that it might take you 1 contest to be yellow. You are great sir hats off.
You seem insecure and angry ushagal0000, I believe the comments such as "mentally, emotionally as well as sexually frustrated with your life" might reflect your current position, and if that is the case please do something about it and not just label others with your own securities. There is no need to be so mad on an online platform, so "Learn to chill a little."
And go to facebook if you enjoy this bullshit.
I have apologized...so all ya dickheads can stop with the downvotes
Why do you think downvotes exist?
I didn't even notice this and wrote my solution (similar to yours, splitting a path into two with similar sizes and processing them recursively instead of Huffman coding) for a general tree. Of course, the only difference is doing a convolution of many arrays.
It should be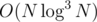 , logs don't tend to disappear in amortised complexity. However, I was thinking: is there a way to do convolution+something more efficiently by doing FFT first, then doing the something and then doing inverse FFT? After all, if an array with size 2n is padded with zeroes to size 2n + k, we only need to compute the first 2n elements of its FFT and each of the remaining 2k - 1 blocks of 2n elements is just the first block multiplied by some power of the primitive root. Then we could use
, logs don't tend to disappear in amortised complexity. However, I was thinking: is there a way to do convolution+something more efficiently by doing FFT first, then doing the something and then doing inverse FFT? After all, if an array with size 2n is padded with zeroes to size 2n + k, we only need to compute the first 2n elements of its FFT and each of the remaining 2k - 1 blocks of 2n elements is just the first block multiplied by some power of the primitive root. Then we could use 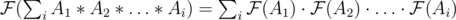 if that sum of element-wise products can be computed easily.
if that sum of element-wise products can be computed easily.
This round was one of my most epic failures ever.
In Div1A I combined two arrays into one array of size 2·n. But when checking if there are ones among them I checked values only to n, not to 2·n. It was unlucky that no one in my room noticed that — one could get +100 on hacking and I could have a chance to find this awful mistake...
But Div1B was even more epic. More than 7 year ago I chose standard realization for binary search working in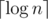 iterations. There is realization which needs
iterations. There is realization which needs 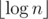 iterations, but for me it was harder to work with bound values (when coding l = mid + 1 or r = mid - 1 there is no knowledge in general about bounds, while when l = mid or r = mid, it looked easier for me to keep one of bounds always "bad" and the other "good"). I never thought about difference in one iteration... And this was just the case — I failed in test making 61 iterations instead of 60.
iterations, but for me it was harder to work with bound values (when coding l = mid + 1 or r = mid - 1 there is no knowledge in general about bounds, while when l = mid or r = mid, it looked easier for me to keep one of bounds always "bad" and the other "good"). I never thought about difference in one iteration... And this was just the case — I failed in test making 61 iterations instead of 60.
Nevertheless, thanks to authors for the contest! It taught me a lot of things :)
I think you problem with B is somewhere else: I have AC with l=m, r=m
Looks like the difference in our codes is that you used r = m + 1 and I used r = m. It means that in your case l < x, r > x, while in mine l < x, r ≥ x. So when the difference between l and r becomes 2 your code immediately finds answer (l + r) / 2 = r - 1, while mine requires to do one more iteration for checking r - 1 and r.
Misunderstood you for the first time. Now it makes sense
It's not misunderstanding :) It's real cause of my problem. In most of binary search problems you don't have answer in a form < / = / > , it's usually like < / ≥ (or ≤ / > ). And in the second case it's usual way use binary search with one strictly bound and second non-strictly (like l < x, r ≥ x). While in a case < / = / > it's possible to use strictly bounds and do one iteration less. The same result could be obtained with mid ± 1 approach. But I just used standard way of binary search implementation without thinking about ± 1 extra iteration, and it was mistake.
BTW, I chose a way to write binary search without mid ± 1 when I learned C++ std::sort instead of standard C qsort. The first uses false / true for comparator while the second uses -1 / 0 / 1 :)
Do you have any proofs (links?) that mid ± 1 binsearch work with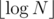 operations?
operations?
Looks like it's the same case as flygrounder's (see above).
Well, maybe it's not strictly proof, but if you use mid ± 1, after each iteration size of binary search segment becomes not more than ⌊ n / 2⌋, and it means that after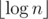 iterations it will be equal to 1. While without ± 1 it would become ⌈ n / 2⌉ which is
iterations it will be equal to 1. While without ± 1 it would become ⌈ n / 2⌉ which is 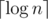
TL;DR: in the sense of actual problem, yes. But this does not actually depend on how you code binary search, it only depends on whether you are actually using all information that is given to you.
I'll try to clarify. There are two different things, actually, that influence how you write integer binary search (I suppose that you write binary search in classic "l-r" style instead of "binary lifting" style).
"Model" you choose (this is not standard terminology, I just will use this word for purposes of this comment). Model indicates what do numbers l and r from binary search actually mean. There are 4 possibilities: the number you are searching for lies in [l, r] range, in [l, r) range, in (l, r] range or in (l, r) range. In all of this models m can be choosen as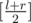 and terminating conditions for this models are r - l ≤ 0, r - l ≤ 1, r - l ≤ 1 and r - l ≤ 2 respectively.
and terminating conditions for this models are r - l ≤ 0, r - l ≤ 1, r - l ≤ 1 and r - l ≤ 2 respectively.
What type of information you can get by asking a query. Usually, when you use binary search to solve a problem, you are asking questions that can be answered "yes" or "no". In this problem, however, you are asking a question that has three answers: the number you are searching for is less than, equal to or bigger than your guess.
Now, you could, say, write the following C++ code in [l, r) model:
Notice that we lose some information here when
sign == '<'. Indeed, we know that X lies in range [m, r), but we know also that X is not equal to m (otherwisesign == '='). Binary search still does terminate, but in possibly bigger number of steps than it could. Writingl = m + 1instead ofl = mfixes the problem.Now suppose that we are searching for X in range [1, n]. We could write code that uses all the information given for all 4 possible models in the following ways:
Now, any of this codes indeed needs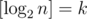 questions to figure out value of X for n = 2k + 1 - 1 (and not more than that for smaller n's). In this exact problem, you still need to ask this number in the end.
questions to figure out value of X for n = 2k + 1 - 1 (and not more than that for smaller n's). In this exact problem, you still need to ask this number in the end.
Quick summary: number of queries does not depend on model you choose, because this choice is purely estetical. However, it does depend on whether you use all information given to you or not.
Nice intuitive explanation. This article also explains how to choose the model nicely.
ceil(log2n) should have done fine, since log2109 ≈ 29.89.
Sorry, I counted only binary search iterations, without first n iterations and one extra iteration to print answer (if it wasn't already found).
I also failed on 61 iterations, it seems. I understand the intent behind 60 queries was to make only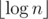 algorithms pass, but I would decide against such a strict constraint if I were a problemsetter, because you can't reasonably separate solutions that can make one more query occasionally. Here's why: [submission:http://codeforces.com/contest/1010/submission/40792452] [submission:http://codeforces.com/contest/1010/submission/40895948]
algorithms pass, but I would decide against such a strict constraint if I were a problemsetter, because you can't reasonably separate solutions that can make one more query occasionally. Here's why: [submission:http://codeforces.com/contest/1010/submission/40792452] [submission:http://codeforces.com/contest/1010/submission/40895948]
Note the difference is purely cosmetic — it has no bearing on how the algorithm works, since decreasing the range of million possibilities by 30 is useless in that sense. It can only slightly change the numbers in some queries. I really didn't expect the out of contest submission to pass, it was just a "lol what if I wrote this instead", and yet it got AC. That idea isn't even something esoteric, not asking for the same number over and over can be a natural way someone would implement this algorithm.
Good test data should be made in such a way that intended solutions almost certainly pass, solutions intended to fail almost certainly fail and anything in between is irrelevant. In this case, solutions that can use 61 queries seem to be intended to fail (otherwise, why use 60 and not e.g. 64), but I found one that passes purely by accident, which is... really bad. My reaction to this as the problemsetter would be "oh shit, this can't happen".
Top 4 in Div2 is just smurfs :(
Div2 C has an
O(n)solution as well.Let
where $A$ and B are the two lists given.
The answer is ans = x * (a - 1), where x is the initial weight of rocket.
Of course, the answer is 0 when any element in any of the two lists is 1.
Sadly none of Div1 participants suceeded in helping Natasha to reach Mars :(
Btw the problems are nice and tough especially the interactive, and for me the statement is a little bit hard to understand, maybe due to my English :(
Hello VladProg, I found something wrong with the checker on Fly's problem. I got accepted instead of wrong answer on that problem. Or you could check on my submission for that problem. I hope you could fix it, so it will not affect any future contest :)
Or you could check on my submission for that problem. I hope you could fix it, so it will not affect any future contest :)
relative error is still less than 10 - 6 so it is still correct
I don't think it is less than 10^-6
Relative error is (difference)/(answer) not just absolute difference
Oh i see, i didn't read that statement carefully. Thank for clarifying it.
In div2C can someone help me understand, why 40816252 works and 40815743 doesn't.
Due to precision issues, when mid is very close to the answer,
possible()might not return the expected value. Here the answer is exactly 10^9 but yourpossible()returned false so youprintf("-1\n")and got WA. And the first one just happened to work.I have a code 40800183 that checks first if 10^9 is ok. It returns false. Then, there is no sense to do binary search after that. But why it does return false ? Maybe it is not 100% correct to require 10^9 answer in this case ? Because it seems to be something not well-defined distinction between -1 and 10^9 if there is less than 10^-6 difference.
from test616.cpp's explanation if the answer is equal to the upper bound, it may fail due to precision issues. However this is not a very good explanation, but from 40807764 you can see if you increase the search space significantly greater than the max possible answer you will get correct answers even if the answer is 10^9. In my case the precision issue was probably caused due to many calculations in one single line and yours it's probably because of double/int (which shouldn't be a problem). But maybe someone more informed can help us.
Binary search contest
can someone explain me why this solution for D is giving wrong answer on pretest 1??
Link to solution : https://ideone.com/klzLiI
Sometimes you know the answer (hi — lo == 1), but didn't tell the system that answer (because you do nothing after while loop). It's just a brief note, got the same problem, I may be wrong.
you know you're a very anxious person when you can't do anything while wait the rating change
What's wrong with this code? Please take a look it is pretty short and clear : https://codeforces.com/contest/1010/submission/40818298
try while(a<b)
xDDDD Thanks.
I got an email about my submission (40806184) for problem 1011A coincides with submission (40800257) of user 641999. Actually both accounts are mine. You can verify it with email id and name on account. I accidentally submitted solution in account 641999. After realising mistake i submitted solution in account no_1999. All submissions after that are from account no_1999.
I think its not allowed to have multiple accounts.
Indeed you agree when registering for contest.
The top5 from div2 is wrong as 2 of them probably were caught cheating
Thank you. Fixed.
OP, consider updating Div2 winners?
Yes. Fixed.
A question about gcd in problem D.
Why would you always need to gcd K?
For example, if all n numbers followed this property x = (x mod k) then shouldn't it be unnecessary to consider k in your gcd (because it is no longer part of the equation)?
I submitted a code with something like
if (x != x%k) d = gcd(d, k);
and it gets wrong answer.
But when I just do d = gcd(d, k); it will work.
Why is that?
UPD:
Ok I got it thanks to Svlad_Cjelli (both smooth with algorithm and with the ladies) Basically if you consider factor x that exceeds K it will become x mod K, actually x mod k can be some factor you didn't consider before. Therefore, its not x % k = x where x, but all the time we mod k (because we can always add one item infinitely until it becomes greater or equal to k)
I approached Div2 Prob b in dynamic but i got TLE in TestCase 14 Since the n is so small, it should hold up to N^2 or even N^3 Why did i get TLE???
http://codeforces.com/contest/1011/submission/40802960
I'm assuming your analysis of complexity relies on the "fact" that (thanks to your memo table), you will enter every state at most once. However, that is not true.
One problem I see is that if
from >= m, thenfood[from]is 0, therefore yourforloop does one iteration. In that iteration,solve(people, from+1)is called, which then callssolve(people, from+2)and so on untilfromreaches 101. The problem is, all of thesesolvecalls return -1. Therefore, yourmemotable is unmodified and whensolveis called next time, the process is repeated all over again.Thanks !!
I changed the memo table to -2 and got AC
http://codeforces.com/contest/1011/submission/40877953
http://codeforces.com/contest/1011/problem/A Pressing the tutorial in Contest materials on these pages did not transition to the tutorial
I help you notice the writer VladProg :)
Thank you for your help
Thank you. Fixed.
I got a problem about Codeforces Round #499 (Div. 2) problem C
I submit this code last night and got a CE with message:
Can't compile file: Compiled file is not a valid executable. Probably, the source tried to use too large static array(s).
I never see this message before and really wonder why. So i submit it again today but judger return an AC with same code and same compiler.
Would anyone like to tell me why?
That's actually very interesting. The codes are identical. Seems like a problem with the judge. Maybe MikeMirzayanov could have a look?