


(prologue) Some time ago this crossed my mind, but I only recalled it now and I think it could be worth a small blog post. This is nothing big and rarely useful but nevertheless, I found it interesting so hopefully you will too (don't expect to find this enriching).
It is widely known that the time complexity to compute the GCD (greatest common divisor) of two integers a, b, using the euclidean algorithm, is 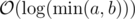 .
.
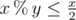 . This is due to:
. This is due to: respectively. Once one of them becomes 0 the algorithm terminates, so the algorithm terminates in at most
respectively. Once one of them becomes 0 the algorithm terminates, so the algorithm terminates in at most 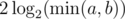 , which implies
, which implies This bound is nice and all, but we can provide a slightly tighter bound to the algorithm:
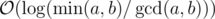
We show this bound by adding a few sentences to the above proof: once the smaller element becomes 0, we know that the larger element becomes the resulting gcd. Therefor we can first bound by 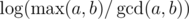 , and lastly notice that we can change the maximum to minimum, since after one step of the algorithm the current maximum is the previous minimum; min(a, b) = max(b, a % b) when a ≥ b.
, and lastly notice that we can change the maximum to minimum, since after one step of the algorithm the current maximum is the previous minimum; min(a, b) = max(b, a % b) when a ≥ b.
This bound is of course negligible... for a single gcd computation. It turns out to be somewhat useful when used multiple times in a row. I'll explain with an example "problem":
(1) Given an array A of n integers in range [1, M], compute their greatest common divisor.
The solution is of course, we start with the initial answer G = A0, and iterate over all the remaining elements, assigning to G the value  . The known time complexity analysis gives us the bound of
. The known time complexity analysis gives us the bound of 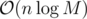 , for computing gcd n times over values of order M. The tighter analysis actually gives a bound that is asymptotically better:
, for computing gcd n times over values of order M. The tighter analysis actually gives a bound that is asymptotically better: 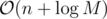 (for practical values of M, you can refer to this as
(for practical values of M, you can refer to this as  ). Why is that so? again, we can determine the time complexity more carefully:
). Why is that so? again, we can determine the time complexity more carefully:
The iteration over the array gives us the factor of n, while the remaining is recieved from gcd computations, which we analyze now; Let the value Gi be equal to G after the i-th iteration, that is:
- G0 = A0
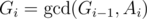
On the i-th iteration, the gcd computation starts with 2 values Gi - 1, Ai, and results with Gi, so the time complexity of it is 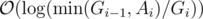 , which is worstcase
, which is worstcase 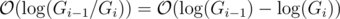 , so we will assume it's the latter.
, so we will assume it's the latter.
The total gcd iterations (differing by a constant factor) is:
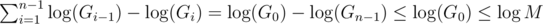
And generally speaking, this analysis sometimes allows us to show that the solution is quicker by a factor of 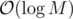 .
.
As a last note, we can use (1) to show more such improvements. For example, (2): suppose the problem of gcd queries for ranges, and point updates. Of course, we solve this by a segment tree. The known analysis gives us a bound of 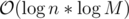 per query or update. We can use (1) to give
per query or update. We can use (1) to give 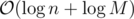 ; an update consists of a starting value, and repeatedly for
; an update consists of a starting value, and repeatedly for  steps we assign to it its gcd with some other value. Following (1), this takes the desired complexity. The same analysis is done for queries.
steps we assign to it its gcd with some other value. Following (1), this takes the desired complexity. The same analysis is done for queries.
If the constraints were n, q ≤ 5·105, Ai ≤ 1018, then this shows that instead of doing around 6·108 operations, we do around 4·107 operations (if we follow the big O notation and ignore the constant), which is close to the well known bitset optimization (factor of 1/32).
Thanks for reading :). As a question to the reader: What other tasks can utilize this, like (2) can?







That's very cool Noam, thanks for sharing :)
Nicely written!
Note that the bound you gave also follows (in a much easier way, in my opinion) from the observation that the computation of gcd(a*d,b*d) has the same number of steps as the computation of gcd(a,b).
In general what you wrote sounds nice and interesting, but I got a feeling that you are making things harder than they should be :)
Like misof already said, there is an easier way to see why the bound is true. I also don't think that the problem that you picked is the best way to make use of it (if we can make any use of it at all?..) In order to prove complexity there, to me it would be much more natural to observe that:
If we'll call operations which don't change GCD at all or don't change it much "bad" and operations which change GCD by decreasing it by half or more "good", you can say that there will be O(N) "bad" operations (O(1) for every element) and there can't be more than O(log(M)) "good" operations (because that's how many times you can divide something by 2, and you need O(1) operations for one division).
I would also use same approach for your other examples. I agree that it is quite similar to what you wrote, only using words instead of playing around with numbers to get amortized analysis (for me numbers and formulas are scary :) ), but I don't see how either of these two connects to x * gcd(A, B) = gcd(A * x, B * x) that you wrote about at the beginning.