


NAIPC is happening again on March 2nd (start time). Information about the contest can be found on this page. Information about registering can be found on here. You can register in teams of up to 3. The deadline for registration is February 28th. This contest will be hosted on Kattis again.
A few hours later, it will be available as an open cup round as the Grand Prix of America (start time). Please participate in only one of them, and don't discuss problems here until after the open cup round has ended.
You can see some past years' problems here: 2018, 2017
UPD 1: Registration is ending soon.
UPD 2: Please don't discuss until after open cup is over.
UPD 3: You can find test data and solutions here: http://serjudging.vanb.org/?p=1349







Invitational / Open divisions start in 3 hours! Good luck to all participating.
I have a comment on NAIPC in general (Not related the problems) I don't know whether others have the same feelings with me. There are no well-documented NAIPC editorials officially or non-officially. Model Solutions (code) themselves might not be enough for people to understand the way to solve the problem. Would it be possible if editorials or just main idea of the solutions can be provided? This can make NAIPC a better experience for the participants.
I agree with this
Solution slides like what NCPC does would be nice.
How to solve D in 4 minutes?
How to solve D at all ? :D
I squeezed something what I believe is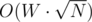
~1500 ms
The idea is to solve a problem in for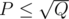 and then try to decrease P
and then try to decrease P
Knowing formula:
Sorry but I don't really get what this have to do with the problem.
You need to calculate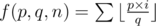 . From the formula you can obtain f(p, q, n) from
. From the formula you can obtain f(p, q, n) from 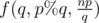 .
.
What is this book?
Number Theory Structures, Examples, and Problems
count_solve function here exactly does the job. I somehow had it in my TRD so it was very easy. I really hate this kind of problem which we are forced to write some uninteresting things to our TRD...
(Btw, the link is an article for NAIPC 2018. Notorious coincidence? :p)
It is truely notorious, given that it is just a subroutine of that problem.
How to solve A?
for each two distinct pair of points (a,b and b,a are different pairs), count the oriented square S of triangle received from these 2 points and any one fixed point, also count the number of points l between a and b; add to the answer S * C(l, k - 2) / C(n, k)
Isn't this number very small?
for l = n - 2 this number is k * (k - 1) / (n * (n - 1))
for l' = l - 1 this number is obtained from previous by multiplying (l - k + 2) and dividing by l
Thanks.
Are we the only one who had precision issue? After using long double it got ok. But I was wondering if there is better solution in terms of precision.
i got ok with double
We calculated logarithms of binomial coefficients instead of coefficients themselves, and it got OK.
I checked reference code which uses double. The difference is, I computed ncr using summation formula precomputed. While the reference computed nc(k-2) on fly. But I thought summation one would give less precision error. Am I wrong?
hi how to solve D,E and L
E: First precalc msk[i][j][k] , where msk[i][j][k] is the mask of rows R, such that either a[R][i] < a[R][j] < a[R][k] or a[R][i] > a[R][j] > a[R][k].
Now we need to fix the mask of rows (maskrow), then find out columns which are monotonic in that mask of rows. Let S to be set of that columns.
Let's do DP. Fix one column that belongs to S, let's say it is column. dp[i] is the number of masks of columns that are monotonic and the largest bit in that mask is i. Then we need to sum all dp[i].
Now how to count dp[i].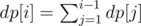 where (msk[column][j][i]&maskrow) = maskrow.
where (msk[column][j][i]&maskrow) = maskrow.
i can't understand anything.
how do we find S?why do you call columns "row"?I fixed it , thanks)
How did you count matrices like this one:
1 4
7 3
I needed one more dimension for place where we change way of monotonic order but it was O(n3·2n)
My solution works in O(n^3*2^n).
Thanks, I didn't think it will pass, so I didn't code it :)
Wasn't TL like 1 sec?
The goal was O(2nn2), but some optimized O(2nn3) passed unexpectedly.
EDIT: Looks like this was a change in timing between Kattis and Yandex systems. I don't know how the time limits were set for snarknews.
... and our O(2n n2) got TLE because of constants. Of course, we should have implemented it better (which we did after the contest), but in general as a problem setter I would argue it's not a good idea to try and distinguish algorithms when the factor is only 20.
Apparently, it's not. Yandex.Contest says it's 1 sec, however, I've just got an AC in 9.5 secs.
The .pdf said ten seconds.
Why should I trust pdf over the system? I mean displaying TL should be synchronized with the one that is actually set. We also asked about it at some point but there was no answer)
TLs in the system are random and that is often the case. Maybe snarknews can explain why
Yeah, that's exactly why we pruned our memory into 64MB and did extensive constant optimization :(
Our team has an O(2n * n2) solution:
For each pair of rows i < j, calculate c[i][j] as follows: its kth bit is on if and only if a[i][k] < a[j][k]. Build a graph where vertex i has an edge to vertex j with color c[i][j]. Now if we choose all the columns, then the number of monotonic rows is equal to the number of monochromatic paths in the graph. Similarly, if we choose a mask msk of columns, then the color of edge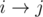 will be c[i][j] & msk. For each value of msk we can do this easily in O(n2).
will be c[i][j] & msk. For each value of msk we can do this easily in O(n2).
D: As discussed above, you write
The latter sum can be computed in logarithmic time as noted in this comment, linking to a post from 2009. I guess most people had some version of that algorithm in their codebook.
L: Consider the complete bipartite graph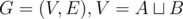 on 2·n vertices with an edge between
on 2·n vertices with an edge between 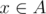 and
and 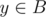 if x → y is an edge in the original graph. The train lines in a trip with minimal number of flights correspond to the edges a maximum matching in that graph. Hence the minimum number of flights is n - 1 minus the size of a maximum matching. If we use no flights, then the second line is empty. Otherwise we may fly to any unmatched vertex in A or fly from any unmatched vertex in B, so we should print all vertices that are not matched in some maximum matching.
if x → y is an edge in the original graph. The train lines in a trip with minimal number of flights correspond to the edges a maximum matching in that graph. Hence the minimum number of flights is n - 1 minus the size of a maximum matching. If we use no flights, then the second line is empty. Otherwise we may fly to any unmatched vertex in A or fly from any unmatched vertex in B, so we should print all vertices that are not matched in some maximum matching.
how to find a maximal matching here? constraints are up to 10^5
Use one of the following algorithms: Hopcroft Karp, Dinic maxflow or Push-relabel with lowest label & global relabeling. They all run in and are even faster in practice. (There is also some version of the basic algorithm that is fast in practice but O(|V||E|) in the worst case).
and are even faster in practice. (There is also some version of the basic algorithm that is fast in practice but O(|V||E|) in the worst case).
Hopcroft Karp algorithm runs in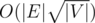
Can you please explain in details how to print the vertices? There are more vertices to the solution besides the vertices that are not matched on left or right in a particular maximum matching.
Sure, so we want to find all vertices v (let's say on the left side) for which there is a maximum matching in which v is not matched. To do this, find any maximum matching in . Then run another phase where you look for alternating paths starting from unmatched vertices on the left. (This takes linear time). The answer is all vertices of the left side that were visited during this phase. (Clearly all unmatched vertices are part of the solution, and if there is some alternating path v0 → w0 → v1 → w1 → ... → vk from an unmatched vertex v0 to a given vertex vk, then flipping the edges along that path gives us a maximum matching where vk is not matched. The converse can be proven similarly by looking at the union of the two matchings. (Similarly to how you prove that a matching is maximum if and only if there is no augmenting path.))
. Then run another phase where you look for alternating paths starting from unmatched vertices on the left. (This takes linear time). The answer is all vertices of the left side that were visited during this phase. (Clearly all unmatched vertices are part of the solution, and if there is some alternating path v0 → w0 → v1 → w1 → ... → vk from an unmatched vertex v0 to a given vertex vk, then flipping the edges along that path gives us a maximum matching where vk is not matched. The converse can be proven similarly by looking at the union of the two matchings. (Similarly to how you prove that a matching is maximum if and only if there is no augmenting path.))
May you share test #39 for C, please?
We have some precision issues and can't figure why, cause we use doubles only for last column in matrix.
Ok, after some investigation we figured out that if all test data generated with "%.10f" we have WA with error ~5*1e-4, but with "%.20f" our error around ~1e-8.
So this precision just lost when test data was printed.
Our solution: https://gist.github.com/yarrr-ru/9b3c262d0d94425281c1a8df050926be
You can replace double with __float128 and get same output, check that there's no overflow in int64_t (as we did).
Lewin
I hate this Gauss tasks with such large matrices. It's impossible to guarantee any precision there and it's just pain. This time we picked integers and failed :D Doubles works fine there.
Have you tried adding partial pivoting to your solution?
I don't fully understand how you're using integers, but your method seems to lead to numeric instability, particularly when the multiplier gets large.
If you change your code to select a row such that the multiplier is kept small, this accumulation of error is avoided. This version of your code passes: https://gist.github.com/godmar/0d15d489d6469e3d9f8e9d0c0a7cc305
PS: consider adding an additional query for '14 10' to random003.in. This is a known value, given as 69151.9484203626. However, your program (sans pivoting) outputs 69127.51092297458671964705.
And it prints "69151.94855679298052564263" if you provide correct test with %.20f print from python. How can we loose precision lesser with more accurate test?
And what you mean by "known value"? Every value from input is just interval cause of this roundness, you can't compare values like this.
What I'm trying to say in other words: you have some rounded values in your tests. For some solutions this roundness is ok, for our solution it's turns bad.
"partial pivoting" is not the case for our solution. We have integer gauss, we do not loose any precision in this operations at all. This is some technique for floats. We just do many operations with your incorrect inputed values and this error from input (not from floating-point arithmetic) summed to large value in answer. You can check __float128 there and get same result.
Why don't you try the code I posted and compare the answers?
Your numerical instability does not arise on the left-hand side in your coefficient matrix. It arises on the right-hand side with your doubles. It arises in random003.in particularly, because there you need large multipliers. Take a look at your code and print the value of 'multiplier' to understand that.
The input data is given with an absolute error of 1e-10 because it's printed with 10 decimals. Your unstable method amplifies the error and in the end you're off by more than the problem allows (1e-4 abs/rel is a quite generous bound.)
The fact that your incorrect implementation would pass if you changed the input generator doesn't mean it's not broken. It's not uncommon for numerically unstable implementations to be very sensitive to perturbations in the input — in fact, that's their definition.
Printing the input data with %.20f to work around your numeric instability is not a reasonable idea in my opinion. First of, 20 digits is excessive, and second, you only get about 16 digits (including before the decimal point) with IEEE double precision floats. And lastly, it's not necessary when numerically stable methods are used.
I will admit that it's ironic that by using integers for the coefficient matrix (lhs) you introduced numeric instability when you tried to avoid it. Nevertheless, pivoting is necessary in your case.
Care to elaborate why author solution is numerically stable (on all tests, not only yours)?
Because it reproduces the answers to within 1e-7 absolute.
What does it mean? Did you change the numbers in the input by values up to 1e-7 by absolute value and notice that the answer changed less than 1e-4 (which is required accuracy in the problem)? I agree that in this case stability takes place on your tests, but Alexey asked also about all possible tests. However, if you mean that your solution produces answer close to another author's solution (which can be unstable too), it obviously does not imply anything.
No, I'm comparing to the ground truth (that is, the values my Python script computes.)
The author solutions reproduce the ground truth for our tests to within 1e-7, even when faced with a 1e-10 error in the input. They do this, btw, without requiring any pivoting (we tested this before the contest because we didn't want this to become an issue for contestants.) In fact, that's why we chose the generous 1e-4 abs/rel bound.
Your solution, on the other hand, requires that the input error be much less than 1e-10 — perhaps as little as 1e-20, in order to reproduce the ground truth to within 1e-8 rel error.
In other words, because your solution amplifies error in the input, the input must be given with very high accuracy so that your error is still tolerable after your lack of pivoting amplifies it.
Also, when I said "partial pivoting" that is not the same as partial pivoting in the sense of choosing the row with the smallest absolute value. In my fix to your solution, I'm choosing the row that keeps the multiplier by which you're multiplying your doubles smallest, avoiding the exponential cascade of round-off error that results.
I think that using integer coefficients means you can drop pivoting only if the rhs is also integer, otherwise, you must take numerical stability into account and find a way of choosing your pivot to minimize it.
PS: you can change the makesomedata.py script to output the realprices for the random inputs to see the ground truth values.
PPS: I'm just talking about our tests. I haven't proven that the author solutions that use partially pivoting are numerically stable for all possible inputs (although my intuition is that this problem isn't particularly ill-conditioned unless you make it so by using large integer coefficients.)
BigDecimal solution in Java without any precision looses at all: https://gist.github.com/yarrr-ru/c88654abb47d85adb8ac0d2c2c476dd4
We're gaining errors only from input.
The problem is not that you're gaining errors. All numerical solution do that.
Your problem is that you are amplifying error. That's what numerical instability means. WikiPedia has a good definition:
An opposite phenomenon is instability. Typically, an algorithm involves an approximative method, and in some cases one could prove that the algorithm would approach the right solution in some limit (when using actual real numbers, not floating point numbers). Even in this case, there is no guarantee that it would converge to the correct solution, because the floating-point round-off or truncation errors can be magnified, instead of damped, causing the deviation from the exact solution to grow exponentially.
In other words, your solution stays on track only if it's near exactly on the right track when you start. If it's a little bit off at the beginning (such as when the input is printed with %.10f, you're off a lot at the end.)
Numerically stable solutions, on the other hand, do not magnify approximation errors in the input.
I am 95% percent sure it is possible find the test failing author solution.
Common, it's BigDecimal, we don't have any rounds/truncations.
Perhaps you could consult with a coach or mentor?
Perhaps you will not prepare ACM-like problems without any proof in future?
Here's a resource that explains why adding precision (via float128, or fixed point arithmetic as in BigDecimal) does not help with numerical instability.
Note that for this problem, it would be nearly impossible to give the input data exactly (unless we want to provide tens of digits in the input). So we had to round. We chose 1e-10.
Your position seems to be that because the input data had errors, your approach does not need to regard numerical stability.
I disagree. Your solution should not amplify the error in the input data. Think about real life. Would you accept a solution that produces answers that are off by as much as your solution just because the input data cannot be determined to a degree that avoids round-off? Suppose the input data came from a sensor that provides limited accuracy.
No — we design numerical algorithms such that they can tolerate larger errors in the input.
Think through your argument some more. Suppose you write a program that leads a Sojus spaceship to the ISS. Your input only provides 1e-10 accuracy due to sensor limitations.
You're using an algorithm that amplifies the inherent sensor error and whose output is off by 1e-1. Sojus misses the space station. Would you then blame the sensor and ask for 1e-20 accuracy in the sensor input?
Had you used a computation approach that paid more attention to floating point computation, you would have been off by only 1e-7 and not missed the space station.
Please share why you believe that different rules should apply to ACM ICPC problems than in real life?
You provided zero arguments why your solution is more stable. In real life you have plenty of time to design algorithms and you also can look at the data. This points make the real life research fully different from ICPC contests.
Do you think the problem became more interesting because of precision issues? You randomly picked the algorithm which is probably (no proof) more stable and many participants struggled to make the same pick as you (look at the success rate of this problem).
As far as I know Lewin who is much more experienced in creating problems for ACM contests offered to increase the input precision, but you refused to do so. Your persistence led to the emergence of a bad problem in the contest, congratulations.
And after this, instead of acceptance of the issue which was not intended, you are talking about stability which your approach supposedly has (with an argument <<worked on many tests, so it's correct>>).
Another point is that if not for additional constraints for given values (for example p > 1 instead of p > 0 for unknown prices), it would be easy to break all solutions based on Gauss elimination. So I think that these constraints were added for a reason: for example, author's solution didn't work without them. This leads us to 2 questions: what the way of realizing which constraints should be given for given variables was; and why these constraints at least "intuitively" are enough for the solution to work.
Reading this thread feels like err... I don't know why setter says "my test is weak" (aka, my unproven and possibly wrong solution works correctly/fast in my test) and think that's a cool thing. It's not, and here's an article by rng_58 which lists basic things that should be done by setters. This is a basic promise between the setters and solvers.
And I hate myself who even tried to attempt C at all.
You may be misunderstanding what I'm saying.
The integer-based solution doesn't fail because it produces different answers than the authors' solutions.
It fails because it produces different answers than the test data generator. Let's look at one data point in particular, line 62 in random003.ans.
You can find the random numbers used for this test case here: https://gist.github.com/godmar/c74b53b1d7177a359e6402030a9df356
The Python formula used to produce the output is:
modifier[cc]**(yy) * year0[cc] * inflationmultiplier[yy]For this, I claim that the exact answer (ground truth) is 38.6975051525. Given that I use one pow() operation and up to 10 multiplications, I believe that I have computed the ground truth with ~1e-10 precision, maybe plus/minus one order of magnitude.
You will note that I am not talking about author solutions here.
Talking about author solutions now: My solution (Java, doubles, partial pivoting), computes: 38.69750515287368. Another author solution computes 38.6975051525 (without partial pivoting).
The solution by Alexey et al computes: 38.71685948656378558133 When the proposed patch I have suggested to improve numerical stability is applied, it computes 38.69750469820102267704.
That's why I am suggesting that for this particular input, the integer-based solution computes an answer that is too far from the ground truth.
To give you more background: we tried hard to avoid these issues. We had a discussion about the limits/bounds. We tested without pivoting (the floating point solutions).
I truly did not anticipate the integer solution and the huge numerical instability they apparently introduce. We also didn't create the coefficient matrix structure that causes the problems for your approach by intent. You'll note the "seed(42)" here.
That said, had I anticipated it, my opinion would not have changed. There's no rule at ICPC to accept numerically unstable solutions. I think best practices that keep floating point error small should be used.
Do you disagree?
You wrote:
As far as I know lewin who is much more experienced in creating problems for ACM contests offered to increase the input precision, but you refused to do so. Your persistence led to the emergence of a bad problem in the contest, congratulations.
Your information is incorrect. lewin did not offer more digits in the input. He insisted on the error bounds being 1e-4 abs/rel, which is the decision we ultimately adopted.
People are interested in the proof of your solution, not arguing yarrr's solution to pass. If you have proof, then it's OK (still bad problem IMO). Otherwise, both solution should fail.
The discrepancy is not between my solution and the solution here, it's between the generated ground truth and the solution discussed here.
You can shift the topic to what I know about my solution, sure. I know, for instance, that it reproduces the ground truth for the tests we've chosen to within 1e-7 abs (roughly). Since we provided a generous bound of 1e-4 abs/rel (thanks to lewin's insistence), and since we had a solution that produces answers accurate to within 1e-7 (vs ground truth) we did not perform an in-depth analysis of the exact error behavior of my solution. Other than that it's several orders of magnitude better than the solution discussed, using the ground truth as a yard stick.
I'm a bit surprised at this discussion. I thought it was generally accepted that if you use floating point numbers (no matter whether double, float128, or higher) you have to be careful with numerical stability and avoid operations that lead to round-off error due to cancellation.
I think what surprises people is how much of a difference it can make (myself included.)
I believe, for most people, the topic had already shifted in at least this point.
You have two clear options.
You stated early that you don't want option 1, then you have to prove. That's what people were waiting for.
No, I'm not surprised. Most red people here are not surprised too IMO. I've seen a lot of terrible cases where floating point operation miserably fails on a well-constructed output. If a solution involves numerically unstable Gaussian Elimination + exp/log function then it's pretty easy to see that something can be highly messed up (Which is the reason that I hate myself who even attempted C).
If I understood right, you had not proved your solution, and it means the author solution is wrong. (I don't consider myself pedantic here at all. I seriously believe that your solution has real countercases.) Hopefully, I think it doesn't matter much to most people, so it'd be great if you could take this lesson to make better problems? I like NAIPC contests in general, and I'd be really happy to see it being better.
You randomly picked the algorithm which is probably (no proof) more stable
I wouldn't say that I picked partial pivoting randomly. It's an established algorithm whose numerical properties are well studied, going back to the work by Wilkinson in the 1960s.
Let me try to understand what you're asking and you tell me if that is correct.
Before one can set a problem that requires Gaussian elimination, the problem setter is required to prove that the condition number of all possible coefficient matrices will not exceed an amount that would lead to a wrong answer relative to the required output precision?
Only then is the problem considered "solvable" and otherwise it is flawed? That is indeed a very high standard to have. I'd like to see the analysis for a comparable problem to learn from it.
(as a side note, I know people don't want to talk about yarrr's approach anymore, but such an analysis would not have helped him, since his approach actively makes the matrix worse conditioned.)
It's not (only) about problems about gaussian elimination, it's about all problems. Authors are supposed to provide a solution AND prove that it solves all the tests that are valid according to the statement and input format specification (or if there's random involved that it works with probability very close to 1)
Would you say that yarr's approach is incorrect beforehand? Although it works almost only with integers? Yep, you couldn't say that, and that's why you were just lucky to pick an approach that works on your tests. There are many problems where integer calculations help to avoid problems with precisions, we were unlucky to pick this approach, you were lucky not to think about it. Personally I don't believe that your solution is unbreakable on valid tests. But to fail it I need to spend much time with no definite benefits — the time which the problemsetter should have spent before the contest.
I was reading this entire thread, and I was quite confused as both sides made pretty good points and yet seemed in complete disagreement :)
I've played a bit with code and here are my findings, maybe they will help reconcile the differences.
First, if the input had no redundant information, then yarrr's solution, at least the BigDecimal version, would necessarily produce the correct output, since it would be computing exactly the same thing (some concrete linear combination of logs of inputs).
However, if the input does have redundant information, then there are multiple ways to express the correct output in terms of inputs. As a very extreme example, suppose we're given x=a, y=b, z=a+b and need to find a+2b. We could compute it as y+z, or as x+2*y, or as z*1e9-x*(1e9-1)-y*(1e9-2). If x+y=z then it doesn't matter as long as we avoid catastrophic cancellation (by using BigDecimal, for example). However, since x, y and z are given in a rounded form, it might happen that x+y differs from z by 1e-10. In that case z*1e9-x*(1e9-1)-y*(1e9-2) will produce a dramatically different result even in BigDecimal.
So a likely description of what happened in this problem is:
The solution found by yarrr's method is in some sense worse than the solution found by godmar's method: if you substitute it back into the system, then it will perfectly satisfy the equations which were not redundant, but the redundant ones will actually have significant errors, whereas godmar's solution will have very low errors for redundant equations as well.
Therefore, while I agree that in the ideal case godmar would have a proof of numeric stability and/or told that the input is generated randomly to sidestep the issue, so far I think that setting this problem based on intuition and experimentation was not a big mistake, and yarrr's issues were in large part self-inflicted indeed.
Thanks for your analysis. We were aware that the input information contained redundant + rounded information. We considered restricting the input to not have any, but we felt that with the 10 year limit it would have unduly restricted our choice of modifiers/inflation rates. We didn't want to craft a problem where the input is given with 100s or more decimal digits just so that it is mathematically consistent since we wanted to allow the use of language-provided built-in floating point types. We briefly considered, then discarded, giving the prices as fractions, for similar reasons.
I'll share something else: the judges initially considered this the easiest, "give-away" problem. How wrong we were.
There have been a lot of good comments in this thread on how the problem setting could be improved, but some CF readers may also be interested in how the contestants could have detected the problem during the contest.
I thought about this some, and here's what I came up with. The problem is of course catastrophic cancellation, which occurs when you subtract two nearly equal values (Petr explained it in his post.) But how can you detect it?
One approach would be to add a check to the code:
This way, contestants would have obtained a RTE instead of a WA when they were about to do an operation that is likely to induce the effect.
The problem with this approach, however, lies in the zeros in the rows below the rank of the coefficient matrix. These remaining values (which under exact arithmetic would be zero) are actually computed in a way that induces cancellation. It doesn't matter for this problem since we're not asking you to determine if the input data is consistent — you can assume it is.
Therefore, you have to refine the approach to abort only if you're performing this operation in a row that's at or above the matrix's rank. Since you don't know the rank of the matrix until you're done, you'll have to record these events in an array, and if cancellation occurred in a relevant row, abort() then.
This might have allowed you to detect the problem during the contest, and perhaps might be useful for other CF contestants facing similar issues in the future.
An open question to me is whether there's any way at all to make the integer-based approach work in a meaningful way. The fix I proposed in an earlier post would have allowed you to pass the judge test data, but it's incorrect. It can be broken with this test, for which your code currently outputs 'Inf'. (Correct answer is 69151.9484196742, your code with my patch computes 70349.72647564546787180007). Combining an integer coefficient matrix with a floating point right-hand side is quite an unusual idea and I'd be curious to see if there's any way to make it work.
We thought of choosing basis from the input equations (using Gauss elimintaion without right column) and then run the algo (with the second Gauss elimination) only on them as a way to remove redundancy. But at that point it's easier to switch to doubles instead.
Challenged by some of the readers here, I went back to some textbooks to understand our intuition regarding this problem.
The sensitivity of a solution to a linear system in terms of its backward error can be expressed in terms of matrix norms. Here, we would use the infinity norm, which expresses the maximum absolute error, and which depends on the condition number of the matrix with respect to this norm. It can be computed by considering the maximum absolute row sum. (Take the absolute values of all coefficients in each row and add them.) In the problem as given, the maximum row sum is 20 (9 for the modifier, plus 9 ones for the inflation rates, plus 1 for the base year price, plus abs(-1) for the query). This makes the problem well-conditioned and explains why Gaussian with or without partial pivoting works so well and produces such a small absolute error (we had seen empirically 1e-7 on our test data and now we know why.) Note that the infinity norm expresses absolute error. This also appears to confirm our intuition that allowing 1e-4 relative error was a lenient choice; in fact, it was probably an unnecessarily generous choice. (By comparison, WF 2014/Pachinko, which involved Gaussian on an orthogonal matrix with 200,000 variables, asked for 1e-6 absolute tolerance.)
If you use integers for your basis/left-hand side, you are drastically increasing the matrix's infinity norm. I ran your code against random003.in — here, you are producing a matrix with an infinity norm of 362886 (those are the large multipliers I had alluded to in my first response), and with random003-permuted your algorithm produces a matrix with an infinity norm of 3155160. This appears to be consistent with the amplification of the relative error you have observed with your implementation.
What is the exact theorem you are talking about? Do you consider the norm of all matrices obtained in Gauss elimination algorithm for your algorithm as well? You explained why this norm is small at the beginning, but it is small at first in our algorithm as well. Of course you could just check all the norms you obtain when solving the tests, however, it wouldn't prove the correctness of the solution for any valid test.
The exact theorem is Theorem 22.2 in Trefethen & Bau For Gaussian with partial pivoting, it depends only on the initial norm and the maximum growth factor that can arise, along with a constant that's dependent on machine precision and for which the book says to budget roughly 3 decimal digits.
The only thing that could make pivoting unstable is a growth factor that grows exponentially large, which can happen in extreme cases (which are artificially constructed, it happens rarely even for random matrices). The book shows a worst case example which involves a lower-triangular matrix with -1.
My intuition, without proof, is that any matrices that can arise for this problem are not among them. Note that they have at most one -1 per row, and in different columns, and that the number of non-zero coefficients per row is less than 20 (most coefficients are zero). I wouldn't be surprised if this could be extended into a proof bounding the growth factor. (For our test data, btw, it's less than 20 and the infinity norm is continually decreasing.)
I'll include, anecdotally, a quote from the book: In fifty years of computing, no matrix problems that excite an explosive instability are known to have arisen under natural circumstances. You should read this chapter, perhaps this could put your concern regarding the stability of Gaussian with partial pivoting for all possible matrices that can arise for all tests for this problem to rest.
What may cause WA 6 in the problem I? My idea was to take letters greedily while
k>1and then take the alphabetically greatest suffix. It passed stress-tests and every smart test I could make.I uploaded a link to the tests, and you can find test 6 (if you order lexicographically).
Those tests are pretty big though. During testing, we could break most solutions with this manually constructed test, so it might be possible you can debug on one of these smaller examples.
Thanks!
If I remember correctly, we initially failed on test 6 because we handled the input
2 accacccbccaincorrectly (should becccccbcca).cis better, isn't it?My bad, fixed it, thanks!
How to solve M?
If x has a mix of numbers with MSB 0 and 1 then first and second half of p array must be disjoint, otherwise they must be same. Recursively solve subtasks in two halves of p array and multiply by 2 in the latter case.
I don't have any rigorous proof of my solution, but it worked:
Let's analyze, for example, p0 and p1. Can we obtain any information from this? If p0 ≠ p1, then numbers xp0 and xp1 differ in the least significant bit (xp0 has 1, and xp1 has 0), but all other bits of these numbers are the same (in the other case we would have p0 = p1). We may do this for all pairs (pi,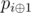 ).
).
Then let's analyze p0 and p2. If they are not equal, xp0 and xp2 differ in the second least significant bit (and we know which number has 0, and which has 1), but are equal in all higher bits. So, that's a pattern: if pi and are different, one of the corresponding values of x has 1 in j-th bit, the other has 0 (and we know which), and all higher bits are equal in these numbers.
are different, one of the corresponding values of x has 1 in j-th bit, the other has 0 (and we know which), and all higher bits are equal in these numbers.
Then we may create a graph for each bit. We have two types of facts: two numbers from x have equal values in some fixed bit, and some number may have fixed value in this bit. We may create n + 2 vertices, n of which represent xi, and two additional vertices represent 0 and 1. If some number has fixed bit equal to 0, connect it to 0-vertex (the same applies to 1); if some numbers have equal values in the fixed bit, connect their vertices. If 0 and 1 are in the same connected component — there is no answer; otherwise, we may "color" each component in one of two colours (except for components containing 0 and 1), so the answer for this graph is 2C - 2. Let's build such graph for every bit and multiply the answers we get from all graphs.
Create n·m unknown variables for all bits in all n numbers. For all 2m numbers consider m numbers which differ in only one bit. Let's say we have some numbers a and b which are equal except for i-th bit which is 0 in a and 1 in b. If p[a] = p[b], do nothing. Otherwise p[a] and p[b] have equal bits before i-th and differ in i-th bit. So we just have to unite variables for equal bits (we used DSU for this) and set i-th bit as 1 in p[a] and 0 in p[b] (not forgetting to check with our DSU whether it's possible). The final answer will be 2x where x is number of variables which were not set to 0 or 1.
H: It seems it's always optimal to start rotating before moving forward (or start both at the same time). How to prove this?
I guess when the angle of your viewpoint vector and the vector to your target is greater than PI / 2, then if moving forward you are increasing the distance and also increasing the angle to the target. Else you may move and rotate at the same time. I didn't solve this problem in the contest so it is just my 2 cent.
Problem E had TL of 10s in statement and 1s in system.
We assumed that system > statement and abandoned our 2nn2 solution. After waiting for 2+ hours for clarification we've sent "while(1)" and received TL of 10s. Didn't manage to code it in time after that.
How to solve B, C, F, K?
C: I have no idea why the following works out numerically, but it does:
After taking logarithms, the formula becomes
where some values of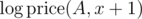 and
and 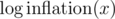 are given, so we're looking at a (possibly underdetermined) system of linear equations. We can use Gauss-Jordan elimination to find some solution to it. (This will then be the answer to a query, assuming the answer to the query is not
are given, so we're looking at a (possibly underdetermined) system of linear equations. We can use Gauss-Jordan elimination to find some solution to it. (This will then be the answer to a query, assuming the answer to the query is not
-1.)How do we determine if the value of some variable is uniquely determined? When the system is underdetermined, some columns will not have a pivot element and the corresponding variables are free. We could use free variables X1, X2, ... and compute the results as linear polynomials in them. (Then an answer is unique iff the polynomial is constant). This would give us an additional factor 100, so instead we solve the system a couple of times and set the free variables to some independent random values. If the some answer is unique, it will never change (up to floating-point errors), otherwise we hope that it changes a lot at between different trials. (In a finite field, this works due to Schwartz-Zippel, but I don't know any version of it for floating-point.)
Isn’t it a Gauss-Jordan on 1110 variables? Is it natural to believe that they work for 1 second? For me it was not, especially given that we are dealing with doubles (even long doubles, maybe).
After I downloaded model solution, there was a solution in “accepted” folder that simply runs in (yc)^3 time, although there was also asymptotically faster ones. I was confused over the intention of setter, whether they generously gave 1s to allow (yc)^3, or otherwise.
I forgot to say the following: We expand the formula to
so in the Gauss-Jordan elimination part, we only need the variables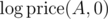 ,
, 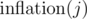 ,
, 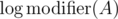 , so at most
, so at most 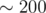 . (But we indeed have up to
. (But we indeed have up to 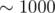 equations).
equations).
Recomputing the values of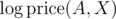 runs in quadratic time, so there
runs in quadratic time, so there 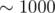 variables are fine
variables are fine
Thanks for pointing this out.
So indeed you had a faster algorithm, thanks for the info. That’s a cool trick btw.
F: For every node u, we compute the probability p(x, u) that the value of u is at most x and the subtree of x forms a heap. The answer is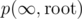 Turns out this is function is piece-wise polynomial in x (The endpoints of the pieces are the values of b). p can be computed in a single dfs by
Turns out this is function is piece-wise polynomial in x (The endpoints of the pieces are the values of b). p can be computed in a single dfs by
godmar yarrr ko_osaga Lewin riadwaw zeliboba
I think that another crucial issue with problem C is that it can be ill-defined. I mean that since the test data contains values with precision errors, the set of possible parameters satisfying all the given data is a set of intervals, not the set of just numbers. That's because each given number is not a number but actually an interval of numbers. Here comes the question: why for each unknown value which can be expressed as a linear combination of given values the resulting interval will have length less than 10 - 4, which is required precision? If the problem statement does not guarantee this, than it is possible to print the value from the correct interval and receive WA because the author's solution has chosen a value near the other end of the interval.
I'd appreciate if somebody at least answers this question. Of course it won't be enough to consider the problem ok without proof of the author's solution, but it will give a chance for the problem to exist in its current form.
If nobody can prove this, I think there are two options:
Accept that the problem can be ill-defined and make the OpenCup round unrated.
Increase the precision of generators to 15-20 digits to let all reasonable solutions pass and make a rejudge.
I think the second option is a bit better, because not so many teams attempted this problem.
Can't wait more for the comments of the organizers, especially the opinion Lewin.
I initially avoided chiming in since I didn't contribute very much to this specific problem, and I personally am not very comfortable with numerical instability issues, so the other judges are more knowledgeable about it. However, after talking about it in depth with the other judges, I feel that there is some misunderstandings going on and wanted to give some opinions.
It is true we can't prove that our judge solution will work on all possible input data. However, after some discussion, I don't believe this is a necessary requirement for a valid problem in a contest without challenge phase if we did do perturbation analysis on the input provided. There have been problems in ICPC where there is some guarantee if input is perturbed by X, then the output won't change by Y, and for those problems, it's not necessary to show the judge will work on all possible data (and is only necessary to show this guarantee for the input that is provided). In practice, a lot of floating point problems in ICPC have this guarantee, implicitly or explicitly. We didn't explicitly state this in the statement (though it is implicit when we said that input is not exact and only has at most 10 digits). Perturbation analysis on numerically proper Gaussian elimination with our data shows very little sensitivity to the input. We found that our solution is accurate up to 1e-7 absolute error with 1e-10 perturbation on the input. This means we could have added in the statement "changing the input by 1e-10 will not change the answer by 1e-7 on the given data". I think this is sufficient to give this problem. I don't think it's reasonable to demand a rigorous proof of precision when we did perturbation analysis on the input files.
Orthogonally, yarrr's solution seems to be incorrect because of numeric instability (as shown with the given data). Numerical stability is fundamental to linear algebra, and the given solution ignored this by not selecting pivots carefully. Their solution does have a lower accuracy for the same perturbation, so objectively it is more numerically imprecise. godmar has already mentioned some of this above, and I think it's valuable if you want to learn more about it.
Personally, I don't really like this style of question and dealing with these issues, and I feel that any implementation of the intended solution should pass. In hindsight, if I knew more about these issues, I would have pushed harder to for more generous precision requirements and possibly lower bounds. However, as is, I don't think this question is invalid, and the data is not incorrect. Sometimes numerical stability is a necessary evil that you need to consider when solving floating point problems. I feel the other judges did their due diligence to making this problem and data valid.
How can you guarantee this if the answer is always some interval, from which the author's solution picks some value? The fact that model solution outputs a value close to the "ground truth" does not imply that there is no other value satisfying all the conditions described in the statement and also farther than 10 - 4 from the "ground truth". Without this fact the problem is clearly ill-defined.
I believe this is the purpose of the perturbation analysis. Suppose all but one of the input values are exact, and that one "fuzzy" value is in some range of size 2e-10. Then varying the input by 1e-10 in either direction will give a lower/upper bound on what answers are valid to print (since these are linear equations).
Now this isn't exactly the case (multiple variables are varying, and interact in complicated ways), but this is the purpose of the perturbation analysis. They do something similar but with multiple variables at once. This gives a 1e-7 variance, meaning if your answer is outside 1e-7 it technically could not possibly be valid. So a 1e-4 epsilon is very generous.
This is my understanding, I'm not sure if this is exactly correct, but just to give you an idea of how it is proven.
The problem with this approach can be that author's solution skips the rows 0=b with b != 0. So they fix the order of rows in some sense, and if you process them in other direction, you could obtain different values because this b contributes to other variables. Why is the author's way of processing rows correct and other ways are not then?
Anyway, this approach just shows that author's output is stable to small perturbations. However it doesn't prove that the interval of possible answers will be short in this case!
lol what is the problem guys how can thsi thread still be hot i mean lol just prove the authors solution or build a countertest to it haha
I don’t think that’s a problem? It’s already known that the ground truth (some ground truth?) is consistent with the input, so it’s sufficient to show that an answer computed using some subset of the input is resistant to perturbations.
Agree, you are right if gauss elimination does not lose precision. However, the experiments of the setters couldn't cover all possible cases. The reliable approach would be to express the parameter values as linear combinations of input values and look at the sum of absolute values of these coefficients. If it is less than 1000 for all computed values, than the described stability takes place.
I don't think that round should be unrated. I believe that on current set of tests all valid solutions belongs to small enough neighborhood of "ground truth" solution, because looks like matrix eigenvalues shouldn't be too big. However authors should admit that they haven't proof of this fact and haven't proof of correctness of their solution on all possible inputs. Several ideas for authors what could be done better: 1) 100 variables for not integer gauss are bad, you should reduce number of variables to less or equal to 50; 2) In such problems if all maxtests are random you should write about it in statement, because experienced participant could reject writing simple solution for such problem keeping in mind that authors have precision anti-tests against simple gauss; 3) you should have proof that problem is well defined and your solution is correct at least on your tests (better on all valid tests, otherwise people will hate you). Also you should be ready to make contest unrated if somebody will find test against all known solutions, this is fair price for giving not proved problems. I believe that there is anti-test against author solution, but also I believe that more precise algorithms should pass them, so I don't want waste time on looking for it.
How to solve H? I got the part that "it's always optimal to turn for sometime at the beginning". And then we need to go like archimedean spiral (constant linear and angular velocity) until the direction from the point's current location is towards the destination. Then simply linear velocity. But how to find out how long do I need to spiral around? I checked the reference solutions but not sure how. May be some reduction makes the problem simpler (I see tangent to circle code, but not sure where the circle is coming from)?
The hovercraft rotates around its current position (it has thrusters). It doesn't rotate around the origin of the coordinate system (that wouldn't be consistent with the physical setup of the problem). Thus, it follows a circle, not an Archimedean spiral if it moves both forward and rotates at the same time. When it sees the target point along a tangent it is optimal to leave the circle and head straight for the target along the tangent.