


Sorry for my poor English :) This is the online version.
Problem D. k-Maximum Subsequence Sum
Brief Description Giving a number sequence {Ai}, in this sequence you need to implement the following two operations:
- 0 x v: Change Ax to v.
- 1 l r k: Query the k-MSS in [l, r].
Analysis
Consider the static problem, Apparently, we can use a dynamic programming to solve it.
- f0[i][j]: the j-MSS in [0, i].
- f1[i][j]: the quasi-j-MSS in [0, i], which the item {Ai} must be selected.
The state transition is enumerating whether the ith element is selected or not. That's easy for a clever guy such as you. So the brute-force method is doing a dynamic programming for each query. The operation Modify takes O(1) time, and Query takes O(nk) . It's too slow to get Accepted.
A simple optimization is using a data structure to speed up Query. The segment tree can be OK. In every node, we store such values in the interval represented by the node:
- the max sum if choosing j subsegments
- the max sum if choosing j subsegments with the first element chosen
- the max sum if choosing j subsegments with the last element chosen
- the max sum if choosing j subsegments with both first element and last element chosen
It's clear that if we know the values of two intervals A and B, we can infer the values of the interval which is concatenating A and B by just enumerating how many subsegments can be chosen in A and can be chosen in B. The time complexity of concatenating two intervals is O(k2). So both operations Modify and Query take 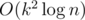 running time. The time limit is 5s in order to save Java's life. If you do some optimization, the solution can be Accepted. You can see liouzhou_101's solution for details.
running time. The time limit is 5s in order to save Java's life. If you do some optimization, the solution can be Accepted. You can see liouzhou_101's solution for details.
It seems hard to be optimized using such idea. Now we are going to use another totally different idea from max-flow problem. We construct a max-cost max-flow model to solve this problem. The source is S and the sink is T. There are other n + 1 vertices. A bi-directional edge between Vertex i and Vertex i + 1 has cost Ai and capacity 1. The unidirectional edge from S to Vertex i has cost 0 and capacity 1 and the unidirectional edge from Vertex i to T has cost 0 and capacity 1. It's obvious for correctness. We can use Successive shortest path algorithm to solve the flow problem. But it's as slow as the brute-force method, or even worse.
Considering how the flow problem is solved, that is, how Successive shortest path algorithm works. We find the longest path(**max-cost** instead of min-cost ) between S and T, and then augment. We can simplify the algorithm due to the special graph. The new algorithm is:
- find the subsegment with the maximum sum
- negate the elements in the subsegment
- repeat the two steps k times
- the answer is the sum of the sum of the subsegment you found each time.
So, the key point is doing these two operations quickly, where segment tree can possibly be used. To find the MSS you need to store
- the sum of an interval
- the maximum partial sum from left
- the maximum partial sum from right
- the MSS in the interval
To negate a subsegment, the minimum elements must be stored. To find the position of MSS, all the positions are supposed to be kept. The complexity of Modify is  , and the complexity of Query is
, and the complexity of Query is 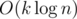 . It can pass all the test data easily but it has a really large constant. This is UESTC_Nocturne's solution and FattyPenguin's solution
. It can pass all the test data easily but it has a really large constant. This is UESTC_Nocturne's solution and FattyPenguin's solution
The idea is hard to come up with and is also hard to code. So let's applaud again for UESTC_Nocturne and FattyPenguin. Also thanks for the great optimization of liouzhou_101.







Is Contribution that important to you guys ? <_< ... This Contest's Editorial is published here :Editorial ... Why not just put it in an single post ...
Bcz I think it's more convenient to read online than download first...
I also agree combining this post into xiaodao's editorial...