

Hey, hi, hello.
Codeforces Round 584 - Dasha Code Championship - Elimination Round (rated, open for everyone, Div. 1 + Div. 2) starts on Sep/14/2019 16:05 (Moscow time) and lasts 2h30m. The score drain will be adjusted for longer contest duration. It's a combined rated round with around eight problems. It is open and it is rated for everybody. Yes, it's rated. There are Dasha t-shirts for top 30 competitors (not counting later-to-be onsite finalists).
As an extra, this is an elimination round for those who live in/near SPb/Novosibirsk. More info about the championship is in the other blog. Thanks to Dasha.AI for making such an event for the community!
Problems are prepared by MikeMirzayanov, FieryPhoenix, dragonslayerintraining and Errichto. One of these setters also created Codeforces, thanks for that! And huge thanks to cdkrot for coordinating the round, to Merkurev, isaf27, KAN and me for testing, and finally to mareksom, Radewoosh and Marcin_smu for some small help.
I wish you more fun than bugs. Enjoy the contest!
PS. I recorded the process of preparing one problem with commentary, will publish it on Youtube after the contest. EDIT: https://www.youtube.com/watch?v=IaViSV0YBog
UPDATE, points: A 500, B 500, C 1250, D 1500, E 1000+1500, F 2500, G 1500+2250, H 4000. There are 8 problems and 2 of them are split into two versions. Good luck!
UPDATE, huge congratulations to winners!
I was the author of last two problems: Into Blocks (but thanks for cdkrot for preparing it!) and Walkways, hope you liked them.
UPDATE, editorial is out.







Rated?
This is something I've wanted to see for some time now, thanks for doing it!
how come your name is mango lassi?
how come your name is ankitsinha3005 ???
He's probably asking because lassi is a famous drink from India (which I personally enjoy a lot over caffeine loaded drinks) and he wants to know how Antti got to know about it. :)
On the other hand, ankitsinha3005 is a pretty easy name to deconstruct — with good probability, his name is Ankit Sinha and his birthdate is 30th May.
I think lassi isn't unknown outside India, just fairly obscure. Even I know what it is because I've seen it on random Asian takeaway menus here. So it's not unreasonable that someone from Finland would discover it.
Wow. It's great. We will get the recorded process of problem. Thanks, Errichto for your big-hearted sharing+teaching mind.
wish everyone high rating!
ratist :D
So the guy likes Petr's daughter :p
lol
Hope I get up early tomorrow for the contest!
BTW, I found “Small help” funny, it made me laugh.
wake up now..its about time
Don't get offended :)
"publish it on Youtube" reminds me of Codeforces Round #543.
Wish everyone high rating GL HF
1410 appearing in sample output O_o. Errichto I love you.
What's wrong with tourist today? He didn't perform well! And even a student from our school, aged $$$14$$$, has got a better rank than him!
It's not you who got a better rank than tourist, why R U so excited?
How to solve E2?
E1 was bitmask dp with complexity $$$O(3^n*m)$$$, I tried to improve it to $$$O(2^n*m+3^n*n)$$$ by only considering top 12 results for every bitmask, but somehow got TLE.
Wow, could you outline the idea? My solution is O(mn + n^n), unfortunately...
Oops, my solution is $$$O(4^n*n)$$$. The idea is: for a prefix of columns and bitmask of rows store the answer.
Did you also consider we have $$$t \leq 40$$$ as the number of test cases. I had a same idea but I didn't start implementing it. Considering the number of test cases, I assumed such an idea would have no chance to pass the system tests.
I passed pretests in E1 with $$$O(t * (n * m ^ 3 + m * n ^ 2 * 2 ^ n))$$$
code link
First realize you'll need at most N columns (with the N largest elements), then do a DP on all columns:
f(x,mask) = max sum you can do for rows in mask (it is a bitmask), starting from column X
Does it hold if some of the largest N is in the same column?
I meant this: sort columns by their largest number, and take the N biggest.
Okay, now it makes sense.
Could you prove it? Sorry for my dumb mind...
Yes, if you get these maximal columns, you're sure that you can rotate them in such a way that you get the maximal number of each column in its own row. Like:
2 1
1 4
So, if you took one more row, its maximal value would be less than the maximal values for each of those columns. So, with the above configuration, you can't use it to improve the configuration.
Got it, thank you.
I think I solved it in $$$O(2^n n^3)$$$, by taking only the $$$n$$$ columns with largest maximum, and during a bitmask dynamic programming, transferring grid by grid.
I have a solution in $$$O(3^n*n)$$$, what was your optimization to make the base $$$2$$$?
Transfer grid by grid instead of column by column.
cell by cell*
And it's called broken profile, https://cp-algorithms.com/dynamic_programming/profile-dynamics.html
Same as E1, just notice that you only need to sort columns by their maxima and take the top min(N, M) (if the sorted order isn't unique, just pick one). Proof: let's assume $$$M > N$$$, assign a column to each row maximum in the final solution and look at the smallest of these columns (in the picked order) that's not among the top $$$N$$$. If there's just one row maximum in this column, you can replace it by a column from the top $$$N$$$, suitably shifted. If there's more than one, you've chosen less than $$$N$$$ columns, so you can just add a column from the top $$$N$$$ and move one row maximum to it. Both cases result in one more of the top $$$N$$$ columns being chosen, so if you repeat this as long as possible, you'll either end up with the top $$$N$$$ columns all containing row maxima or no other columns containing row maxima. However, the former also implies there are no other columns containing row maxima, since there are just $$$N$$$ of them.
Got it, thank you.
Give us more problems next time pls.
How are you sure that your solution to H is numerically stable?
While Errichto didn't answer you, try watching his video of preration of problem H.
https://www.youtube.com/watch?v=IaViSV0YBog
My solution involves division only at the beginning and at the end, the rest is obviously numerically stable:
Can you wrap that in a spoiler? :)
How is this numerically stable?
It doesn't matter how this comparison is resolved when t1 and t2 are close.
I can say the same about all the 14 codes I submit, but they do occasionally receive different verdicts, so I'm trying to understand why.
In short, there is no issue with catastrophic cancellation because incorrectly computing some sum as $$$S + e$$$ instead of $$$S$$$ gives us a new value $$$V - e$$$ instead of $$$V$$$ and the errors cancel out. And the formal proof of the whole thing should use absolute errors only but that's fine because we never get huge numbers.
60573091 this gets WA 19. You can press "Compare" and look at the changes from solution that gets WA 15. Really?
I'm not sure what you're talking about. My solution is different, it doesn't use any epsilon (well, only to check if something is 0 or greater than 0.1).
EDIT: I want to compute energy computed/saved for every walkway. I build a segment tree over that. Sort walkways by speed and in this order maximize energy used there without getting below $$$0$$$. I use a segment tree to get prefix sum and min prefix sum.
Does your solution use sets, comparisons of doubles, or something similar?
No, it doesn't.
poor:<
this problem is simillar to D https://codeforces.com/gym/102268/problem/F (code which got AC at D got AC at this problem)
Bessie the Cow has come to Codeforces :)
Very nice problemset! Thank you for the contest.
Could E1 have been solved entirely with implementation, or did it require dp?
It could. I found the 4 columns with the biggest max.value and bruteforced every possible combination of shifts.
how to solve B? all i can think is simulating the condition one by one
Yes, exactly.
Can you explain, how to simulate Problem B...?
We simply start with the initial configuration and run X trials. In my code, X = 50K, but I think that's overkill, some solutions use as little as 200, but better safe than sorry :) I haven't gotten around to a formal proof, though I'm sure there is one.
Anyway, on a single trial we go through all of the candles and check whether the i-th candle needs to be toggled. It boils down to the following equation:
current_time = a + bk
or
current_time — a = bk
or
current_time — a = 0 (mod b)
We check that condition for every candle, and, if it is true, toggle it. On every trial we update the maximum number of lighted candles. After the trials are over, we output the maximum.
Would it be correct to argue that, since $$$lcm(2,3,4,5) = 60$$$, every bulb will repeat after $$$60$$$ time steps. So you don't need to check times after $$$60+5$$$. But like you said, I didn't try a small amount to stay on the safe side.
Same, but lcm (2,4,6,8,10) = 120 and + 5 so I iterated from 0 to 125 exclusive and got accepted. Then tested for 0 to 124 to be sure and got wrong answer. You need twice those numbers because you are looking for a period, and full period is time on + time off, thus multiply by 2.
Yeah, I was also thinking that maybe we'll need twice of the lcm. Thanks for clarifying!
is D greedy ? I've tried to put the guests that has 2 types others have first but I think I'm missing something
I used DSU to solve D.
Create graph, for each connected component with x vertices you can satisfy x-1 guests.
Wow.
I basically did the same thing, but I made that observation only for cycles, so I had to do additional work for non-cycles.
That explains how there were solutions for D for several minutes :)
D is just M — (sum of sizes of connected component — number of connected components)... so yes, if you count any graph traversal to be greedy
[my bad]
At this point, no.
Can you help me see what's wrong with simply sorting given food preferences as pair ( also keeping minimum in pair as first ) and greedily calculating answer? I understand how people have done graph approach, but don't (yet) see what's wrong in mine.
I tried the same first, mine was failing with:
How to solve F? I had an idea with Dijkstra and then greedy on the shortest path DAG but it's WA on test 10.
Did you sort the DAG adjacency lists by the lexicographical order of numbers or by value? The latter is wrong.
Oh crap, you're right I sorted by value xD Thanks!
I thought about fast Dijkstra with smth like trie and overloading comparator in set using this trie and binary jumps on it (LCA). But don't have enough time to finish idea and implement
I did it, but WA62
UPD: It works, I have made a silly bug
Store numbers in trie lca can be used to compare them.
If one simply 1) compute minimum number of digits for reaching each node using Dijkstra; and 2) sort adjacency lists by lexicographical order; and 3) perform a greedy DFS on the resulting graph, making sure that the number of digits used is always equal to the minimum, one will get WA on test 47. (https://codeforces.com/contest/1209/submission/60551210)
For example, if there existed an edge between node 1 and 2 with number 1, between 2 and 3 with number 2, and between 1 and 3 with number 11, this algorithm will choose 1->2->3, not 1->3.
First, let's add some fake nodes on every edge separating number written on it by its digits. For example for the edge AB with 123 on it you create two more nodes and connect them like A-1-F1-2-F2-3-B.
After that you can assume that you need to find the shortest path by the number of edges in this graph for each initial vertex, and choose the lexicographically smallest one among all paths with the smallest length, because numbers with bigger length in digits are like bigger). To do so you can run some sort of bfs.
Suppose that you want to maintain all classes of equal by value paths with length x. To add one more edge, you iterate over all nodes in current level of bfs and add an ordered pair of (current class of node, digit on edge to the node in the next level) to current possibilities of going further. After that you need to select the smallest pair lexicographically for each node in the next level and update your classes just like in a suffix array building in O(n log n).
If you traverse the edges in ascending order (all 0 edges then all 1 edges and so on) then you only need to care about the first time you visit a node (basically normal BFS).
Heh, seems that you got your point~ It's so simple and accurate idea. But at least the suffix array bfs sounds way more cooler)
I'am not sure, but it doesn't seem quite true. If there are two vertex with the same path to them, 0-edge from the second of them is preferable to us than 1-edge from the first, but we will consider them in the reverse order.
Egor already mentioned this in his comment:
In normal BFS, you pop one node at a time and find new nodes by going from the node you just popped. For this problem, you will have to tweak it such that you will pop all nodes with same distance at a time. You can check my implementation here 60576572.
Thanks, I understood, considering the component really fixes it.
Hi. I saw your code and for the graph like this: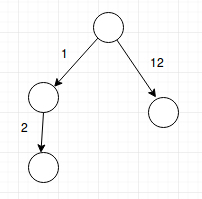
your code would generate a graph like this one: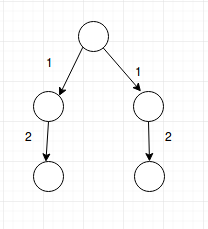
whereas my code was trying to do something like this: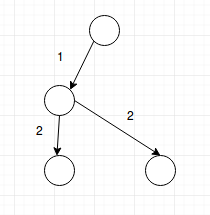
but it's getting WA. Can you please tell why we cannot reuse existing vertices?
I used one vertex multiple times and got accepted.
Thanks. Then there might be something wrong with my implementation. I'll try to see what's wrong with it.
[DELETED]
[DELETED]
Can anyone tell me why the codeforces generate different output for problem C ? It is continuously generating wrong output for pretest 1 which is the given testcase. I tested my code on my local and every online IDE I could find and it was generating same correct output . I request to rejudge my problem C solution . Due to this I ended up submitting my code 4 times which would deduct so many points of mine . It is just unfair as hell . If you want I will post my code you can check for yourself.
UB.
You should test it in custom invocation tab.
I tested my code in custom invocation tab and its generating wrong output same as before . I tested my code multiple times on online ide and my local machine and its giving correct output. What should I do in this case?
Run it locally under Valgrind/Memory Sanitizer/Address Sanitizer/UB Sanitizer. Alternatively, use custom invocation with "Clang++17 Diagnostics".
Also, proofread the code to make sure it does not have undefined behavior (which is typically the reason behind different behavior on different machines).
seems like it was my fault after all . there was a bug in my code where I was trying to access negative index . But it would have been nicer if was my local machine also gave same output as codeforces.
Bad difficulty distribution again :/ 141 people solved F, while G2 and H were only solved by 5 people each. Problems A-G1 were relatively easy too, so I'm very surprised four LGM-level testers didn't recognize the far-too-high difficulty jump.
Also, G1 gives way too many points for how easy it is. More people solved it than E1, E2 or F, yet it gave more points than E1 and the same amount as E2. Additionally, since it was so much easier than F, the optimal strategy would have been to solve it before writing F. I think this trend of easy subtasks with inflated scores needs to stop, if not getting rid of subtasks altogether.
Agreed, my code for E2 took like an 30-40 minutes of coding+debugging, while I needed <10mins to read, code & submit G1. And I didn't even read G1 until quite late, because I expected it to be more like G-level problem
E1 is fine because I can optimize its code for E2. G1 however should not exist.
I believe subtasks are good at differentiating people who 1) cannot solve neither E1 nor E2, 2) those who can solve only E1, 3) those who solve E1 and after an hour come up with a solution for E2, and 4) good programmers who solve E2 in the first place.
G1 took me longer to figure out than E1+E2. I looked at E2, "hmm if $$$N=M$$$ then just subset DP in $$$O(4^N)$$$ and seems like I can sort the columns and take top $$$M$$$", then I checked if the second observation holds, wrote a solution, submitted, done. F killed me, I barely submitted and I'm really not sure if it's going to pass systests.
Very true, I don't see any point in these subtasks except for wasting participant's time on solving some partial cases of the problem. Yet for some reason they become more and more popular on codeforces. This has to stop.
I would like to understand this topic more to make smart decisions in the future. Why don't you like subtasks?
the goal was obviously to provide an easy problem for beginners and at the same time not waste much time of top participants who can just skip easy version. That's not necessarily true today in this particular contest but you clearly complain about subtasks in general. Right?
I don't like subtasks in general because if part 2 is sufficiently hard, you have to write (usually quite boring) first part to get more optimal points on the problem.
It's less bad in contests where you only care about last submission time such as GCJ.
To be honest, they simply irritate me in codeforces rounds. I usually don't like solving partial cases of the problem to earn few points as I don't see this points to be "fair".
Subtasks are acceptable in some long rounds (like codechef long) or rounds with really small amount of problems (like ioi and stuff). You have the time to investigate the problem and solving subtasks usually advance you to the solution of the bigger problem or, at least, of some bigger subtasks. In codeforces it's often not the case and when you solve smaller subtask, you basically have to start from scratch in solving harder one (at least, I feel it this way). And you don't have time to investigate the problem, you're under constant pressure of clocks going too fast and round being too short.
Subtasks might be used in codeforces rounds in some exceptional cases, but now it is hard to find recent div. 1 round without subtasks and I clearly don't like it.
"Additionally, since it was so much easier than F, the optimal strategy would have been to solve it before writing F." — and what is wrong with that? Recommended strategy is solve problems in increasing number of points so of course you should try reading and solving G1 before F.
And G1 makes it kind of 'unworth' solving G2, as it's much more difficult than F and deserves more points. QwQ
By the way, it leads to a result that solving H offers 4000 points while solving G only results in 2250. Just look at the scoreboard: ABCDEFG1H always ahead of ABCDEFG.
UPD: The problems themselves are quite awesome, though. Just hope a better score distribution.
How to solve C? just DFS? i trid,WA on pertest 4,im so weak...
I'm not sure but maybe finding the longest non-decreasing subsequence and marking all elements in it as 1 and if the rest of the elements aren't in sorted order there's no solution otherwise mark others as 2.
Is there an easier way to solve G2 than maintaining 2-edge-connected components?
By the way, very nice problemset! C was really cool.
Create a sequence X with zeros. For every set of positions of the same value, for the segment between first and last occurrence add +1 in X. Then, we're looking for minima in X and between every two consecutive minima: a number that occurs most times. If for first occurrence of a value you store the number of occurrences of this value then the whole thing can be done with a segment tree.
Marcin_smu did it easier, without any interval operations. I don't know how though.
hahaha
Is G1 simply merging the intervals?
A DSU based implementation of G1,
https://codeforces.com/blog/entry/69791?#comment-542689
This meme suggests that it was good to have subtasks in E and G. Was that intended? ;p(I messed up)The goal of subtasks for E and G was to make the qualification (for the event) nice and without difficulty gaps. I agree that G1 should be lower-scored or non-existing, sorry about that. I don't think there was any tester that solved all problems to find the difficulty gap between F and G. I asked some of my friends to test G or H, and other testers mainly solved easier problems. There just aren't usually strong people that have enough time to test everything :( and this contest was kind of rushed so we didn't have time for an editorial, sorry for that too.
You can estimate difficulty by explaining solutions to testers after they've tried all problems they can and letting them give input based on that. When I tested 580, I gave input based on my intuition even for problems I couldn't solve.
Lurk more on /b/. The usual template is that the guy that gets thrown out of the window offers an obviously good or asked for but not really tried idea while the other two propose stuff nobody asked for or ideas that were tried but didn't work (not bad per se, but considered worse by the author). Example. I'm not counting ironic meme and antimeme variations.
Yup, I agree it needs to be done more often. But here G was quite easy to come up with a solution and only hard to implement. We still realized that it's hard and gave half more points than for F. That's like a jump from 2000 to 3000 points.
Sure. I don't mind the difficulties, G2 probably should have had a greater portion of G's points but it's not a big deal, at least it made difficulty jumps less steep.
Actually, I change my mind. G1 should not be lower-scored. It isn't easier than D and for sure not much easier (enough to make an issue out of it). Obviously, G2 should get more points.
Who suggest subtask for G? Such thing is bullshit. Looking at scoreboard, G2 < F LOL while > 100 people solve F, what is for G2?
I was one of people that agreed for that subtask and explained a reason above. Indeed, the scoring was bad though.
Could you let us see other participants' solutions?
Codes still closed , reason ?
Still not able to see the test cases
Low-effort screencast
can't see video.
It is still processing, also the link was wrong in the first edit.
Yay, now I can watch you fail F!
Knock yourself out.
Really good problem set.
The announcement of the Dasha Code Championship says this about the first round:
While this blog states
Which of these is correct? Will the top 30 contestants who choose not to attend the onsite-event receive shirts, or will the shirts be given to the top 30 contestants, regardless of whether they participate in the onsite?
How to get a tight upper bound for the simulation in problem B? Also, is there any other approach other than simulation?
Can anyone hack my randomized solution for E1?
svf
#
G2 accepted by $$$O(m\cdot n^\frac{2}{3})$$$ (sqrt decomposition) and SIMD optimizations of GCC: 60577013
What a beautiful time complexity XD
First three were easy ones. Naive implementation required only :)
I was debug-submitting my solution for F with incorrect idea and got AC. Although it should have TL and WA.
Hello to problemsetters and testers.
Here is idea of INCORRECT solution:
Let's launch Dijkstra from 1, where weight is equal to the length of value of the path and also build tree of shortest paths simultaneously and support online LCA on it. So now we will update shortest path for vertice $$$to$$$ if we go from vertice $$$v$$$ if length of value of the path is smaller or if length of value of the path is equal and prefix of some length of path from $$$LCA(v, to)$$$ to $$$v$$$ is smaller than prefix of some length of path from $$$LCA(v, to)$$$ to $$$to$$$. In debug submit prefix length is equal to 500 edges. It's possible to find the test with TL and WA.
I wonder why there are no test when there are 2 paths from 1 to $$$v$$$ with same lengths and with LCP of $$$O(n)$$$ length. For me it seems like obvious test.
https://codeforces.com/contest/1209/submission/60576721
Can anyone help me with G1?
NO!! become purple first
Thanks bro
Check out this explanation using DSU, https://codeforces.com/blog/entry/69791?#comment-542689
Errichto Is there any way to solve problem E1/E2 by max flow?
I'm not aware of any and I didn't think about it. The only thing I did there was to write some randomized approach to break tests.
I tried to solve E2 using randomization, and finally I got AC :3
60578430
Could someone help me figure out whats wrong in my solution 60578600. Basic idea was to maintain 2 vectors one and two and both satisfy the condition of maintaining elements in increasing order, at some point of time if I can't place in the 1st array I try to relocate elements by popping from the first and moving into the second until I find a suitable place. If at some point I am not able to do the above I report answer as NO.
Any proof of D ?
Errichto How to choose the upper limit for time in problem B? if they have periods T1, T2,... they would repeat after LCM of T1,T2, ... ,but with a shift I don't know a formula for that!!
I see 1000 would pass the test.
I am writing this post to say a thank you to Errichto and others who helped him for this contest. I believe preparing 10 problems in a short amount of time is a tough task, and I believe they did a great job . We should be thankful to Codeforces and everyone who made this happen.
I am 31 years old and decided to start practicing competitive programming problems again after being inactive in some years. During the last 3 months, I learned a lot from great problems, and I am always glad to have the chance to practice in such a wonderful platform, i.e. Codeforces.
I am really surprised why some (even some red coders which I suppose to behave more maturely based on their experience in contests) complain about some small things such as 250 points difference between problems G2 and F. In some cases, they question everything, and posts are getting more aggressive. This is not what we expect from this wonderful community.
When will the tutorial be published ?
It is out now! Hope you enjoyed the contest!
Editorial
In problem D , How to get hint from the problem that dsu will be used in it ?
There's no DSU in the optimal solution.
Could someone explain the idea of Problem C. Thanks in advance.
I can not warp my mind around problem E. To me it seems like if we just select n maximum numbers from the matrix and put them in our desiring rows by just shifting them, then the result would be the sum of those maximum n numbers. Can any one point to me how this is wrong?
Try this 4 2
1 1
10 10
10 1
1 10
There is no way to get 40, in fact the answer is 31. Your approach works only with N<=3.
Yes, I think I got it, thanks a lot man.
Fast system testing, fast rating changes, good problems. Best contest ever
When there will be the list of onsite finalists?
ai luv purupulem efu
Can someone explain how the complexity for E1 was calculated and if the possible the logic of bit masking in this problem. I solved it by brute forcing the different permutation for the n columns container the largest elements but cannot solve it using dp
Deleted
When will T-Shirt winners announce ?
Congratulations to the winners of T-shirts! :)
30 best participants, except for the participants of onsite rounds.
1. Petr
2. jqdai0815
3. LayCurse
4. zeliboba
5. 300iq
6. sunset
7. djq_cpp
8. maroonrk
9. LHiC
10. Um_nik
11. tourist
12. Endagorion
13. Anadi
14. Kostroma
15. webmaster
16. neal
17. dreamoon_love_AA
18. zx2003
19. lumibons
20. zemen
21. RAVEman
22. 998kover
23. ko_osaga
24. Shayan
25. danya090699
26. Swistakk
27. _h_
28. Panole233
29. inaFSTream
30. gisp_zjz