


Thank you very much for taking part in the contest!
- -0:05. Starting the chat with the Questions Answering team: tnowak and our beloved coordinator antontrygubO_o. We hope that there won't be that many questions :)
- -0:01. One minute to go! I hope that everything goes smoothly. I'm so afraid of posting the editorial accidentally that I moved this timeline into another blog...
- 0:01. First blood in Div2! Congratulations to majorro!.
- 0:03. First blood in Div1 as well! Congratulations to Errichto, your knapsack is ready for a journey to win!
- 0:04. Sho first to solve Div2B. Well done!
- 0:05. We also have the first question. So far so good...
- 0:06. Um_nik gets the first pretests pass in Div1B. The cheaters are caught!
- 0:09. bandiaoz packs the first Knapsack in Div2! A difficulty spike is coming...
- 0:12. Benq is leading in Div1 after the first successful construction of a Xorry tree. He needed just under $$$4$$$ minutes to complete task, scary pace...
- 0:20. batman_begins the first person to catch Div2 cheaters. Congratulations!
- 0:25. Benq first one again! This time it's problem Div1D/1 which shows no challenge to him!
- 0:40. Noone has attempted Div1D/2 yet. It looks like the strongest contestants have switched to solving E and F. Maybe we gave a too low bonus score for this subproblem? Easy subtask is quite hard, but I guess that implementing the harder version can still give you some benefit if you can't solve E or F.
- 0:42. Ok, I was wrong. Benq orz!
- 0:48. 1700012703 is leading the Div2 contest with $$$5$$$ solves! How do you pronounce this nickname?
- 0:59. ecnerwala solves problem Div1F!! Congratulations, a well deserved top spot (for now :) ).
- 1:05. Um_nik and maroonrk sent first submissions for Div1E. Unfortunately, both failed on pretest $$$3$$$, each with a different wrong answer.
- 1:10. Benq steals the top spot from ecnerwala with a successful attempt on Div1F. There's still one more unsolved task left...
- 1:13. ksun48 joins the WA party on Div1E. Will we see some correct submission?
- 1:14. Is it a miracle? No, it's just Um_nik. First blood on Div1E! Can he outperform Benq by solving task F?
- 1:20. ainta solves problem Div1F as well. Who's going to be the first one to take both of E and F?
- 1:25. There are $$$15$$$ people in Div2 with $$$5$$$ problems solved. Nobody has claimed a subtask of F yet.
- 1:38. We have a first successful hack! Congratulations to Mark2020. We haven't expected hacks at all, though.
- 1:40. shb is the first person to solve the easier subtask of Div2F. Will he win the contest? Or is someone else catching up?
- 1:41. Um_nik solves Div1F! There's still some space for improvement for him. D-hard awaits.
- 1.57. Anton, do you have some keyboard problems? Did you really want to answer the question with: bbbaba, bbbaba?
- 2:06. Um_nik finishes the contest with a full score. Congratulations!
- 2:15. There's a bunch of wrong answers on Div1E. Is someone going to get another accept?
- 2:30. The contest has ended. The editorial is up! :)
We're only interested in differences between the elements. Is there another way to express the operation?
The operation in the $$$i$$$-th turn is equivalent to selecting one element and subtracting $$$i$$$ from it.
The sequence $$$1$$$, $$$2$$$, ..., $$$n$$$ satisfies task's constraints. After the additions all positions will contain $$$\frac{n\cdot(n+1)}{2}$$$ candies.
We want to minimize the number of negative numbers as much as we can by applying the operations. What is the minimum possible number of those negatives?
Let $$$X$$$ be the number of non-zero numbers in the grid, and let's see what happens in different scenarios.
- both cells have negative numbers, then $$$X$$$ goes down by $$$2$$$.
- both cells have positive numbers, then $$$X$$$ goes up by $$$2$$$.
- one cell has a positive number while the other one has a negative number, then $$$X$$$ stays the same.
It is important to notice that we can apply this operation not only for the two neighboring cells, but for any two — to achieve this effect we apply this operation on any path between the cells consecutively.
The parity of $$$X$$$ never changes. So, for even $$$X$$$ the answer is the sum of the absolute value of all numbers, $$$S$$$. Otherwise, one element will not be positive in the end -- so it's best to choose the one with minimum absolute value, $$$V$$$, and subtract $$$2\cdot V$$$ from the sum.
The existence of zeroes doesn't really change anything, both formulas output the same value in such a case.
This gives us a solution in $$$O(N\cdot M)$$$
Are there any items which you can put in the knapsack to fulfill the goal with one item? What happens if there are none?
If there is an item of size $$$C$$$ satisfying: $$$\lceil \frac{W}{2}\rceil \le C \le W$$$, it is enough to output only that item. Otherwise, we should exclude items which are larger than the size of the knapsack and take a closer look at the situation. Consider greedily adding items in any order until we find a valid solution or run out of items.
This is correct because all items have sizes less than $$$\frac{W}{2}$$$, so it is not possible to exceed knapsack size by adding one item in a situation where the sum of items $$$C$$$ doesn't satisfy constraint $$$\lceil \frac{W}{2}\rceil \le C \le W$$$.
This gives us a solution in $$$O(n)$$$.
From the analysis above, we can also conclude that greedily adding the items from largest to smallest if they still fit in the knapsack will always find a solution if one exists.
This gives us a solution in $$$O(n log n)$$$.
This is a dynamic programming problem. Recall the DP calculating the Longest Common Substring for two strings. What similarities are there in our setup, and what differs?
If a substring has a negative score, we can throw it away and start from scratch.
Let $$$DP[i][j]$$$ be the maximum similarity score if we end the first substring with $$$A_i$$$ and the second substring with $$$B_j$$$. We will also allow the corresponding most similar string to be empty so that $$$DP[i][j]$$$ is always at least $$$0$$$.
It turns out that the fact we need to search for substrings of our words is not a big problem, because we can think of extending the previous ones. In fact, we have just two possibilities:
$$$A_i$$$ and $$$B_j$$$ are the same letters. In this case, we say that $$$DP[i][j] = min(DP[i][j], DP[i-1][j-1] + 2)$$$ as the new letter will increase the LCS by $$$1$$$, but both of the strings increase by one in length, so the total gain is $$$4-1-1=2$$$.
In every case, we can refer to $$$DP[i][j-1]$$$ or $$$DP[i][j-1]$$$ to extend one of the previous substrings, but not the LCS, so: DP[i][j] = max(DP[i-1][j], DP[i][j-1]) — 1.
An inquisitive reader may wonder why it doesn't hurt to always apply case $$$2$$$ in calculations, so clearing the doubts, it's important to informally notice that we never get a greater $$$LCS$$$ this way so wrong calculations only lead to the worse score, and that our code will always find a sequence of transitions which finds the true $$$LCS$$$ as well.
Implementing the formulas gives a really short $$$O(n\cdot m)$$$ solution.
Is it possible that the graph formed has a cycle? How to evaluate whether a sequence is good?
Since we have $$$n$$$ edges and two of them must coincide (the pair of numbers with the smallest xor), we will have at most $$$n-1$$$ edges in the graph. Thus, we only need to check if the resulting graph is connected. How to do it?
Let's look at the most significant bit, and group the numbers into two sets $$$S_0$$$ and $$$S_1$$$, depending on the value of the bit. What can we say about sizes of $$$S_0$$$ and $$$S_1$$$ in a good sequence?
It is easy to see that if $$$2\leq|S_0|$$$ and $$$2\leq|S_1$$$| then the whole sequence isn't good, as for any number in $$$S_i$$$ the smallest xor will be formed by another number in $$$S_i$$$. So there won't be any connections between the numbers forming the two sets.
Thus, one of the sets must have no more than one element. If that set contains no elements, then the solution can obviously be calculated recursively. If it instead had one element, then as long as we make the other sequence good, it will be connected to something — and thus the whole graph.
Let $$$F(S)$$$ be the maximum possible number of values we can take from $$$S$$$ so that they form a good sequence. Divide the numbers into $$$S_0$$$ and $$$S_1$$$ as above. If $$$S_0$$$ or $$$S_1$$$ is empty, strip the most significant bit and solve the problem recursively. Otherwise, the result is $$$1 + max(F(S_0), F(S_1))$$$. Straightforward recursive calculation of this formula gives the runtime of $$$(n\cdot 30)$$$, as all numbers are smaller than $$$2^{30}$$$.
1447F1 - Frequency Problem (Easy Version)
What can you say about the values which are the most frequent ones in the optimal solution?
Let $$$D$$$ be the most frequent value in the whole sequence. If $$$D$$$ is not unique, we output $$$n$$$. Otherwise, we can prove that one of the most frequent values in an optimal solution is $$$D$$$.
We'll prove this by contradiction. Consider an optimal interval $$$[a, b]$$$ in which $$$D$$$ is not in the set of most frequent values. Let's think of the process of expanding the interval to $$$[a-1, b]$$$, $$$[a-2, b]$$$, ..., $$$[1, b]$$$, $$$[1, b+1]$$$, ..., $$$[1 ,n]$$$. Since $$$D$$$ is most frequent in the entire sequence, at some point in this process it will appear the same number of times as at least one of the other most frequent values. The corresponding interval will also satisfy the task's conditions, hence $$$[a, b]$$$ cannot be an optimal interval if $$$D$$$ does not appear most frequently.
For each value $$$V$$$ we can solve the task when $$$(D, V)$$$ are the most-frequent values independently, ignoring other values. Now we would like to solve the following subproblem: find the longest interval of sum 0 where elements in the array are either $$$1$$$ ($$$V$$$), $$$-1$$$ ($$$D$$$) or $$$0$$$ (other values). The solution's complexity should be proportional to the frequency of $$$V$$$ in order to obtain an efficient solution for the entire task.
You might be worried that we can't simply ignore the other values, since they may end up being more frequent than ($$$D$$$, $$$V$$$) in the interval that we've found. This might be true, but can only be an underestimation of the optimal interval's length. A similar expanding argument to the proof above shows that:
- we never overestimate the result
- for the values of ($$$D$$$, $$$V$$$) which form the optimal interval we find exactly the right interval value.
For the easy version, it's sufficient to consider all pairs ($$$D$$$, $$$V$$$) in linear time, by using the standard algorithm which computes the longest interval with sum $$$0$$$. Thus, we get a solution with complexity $$$O(100\cdot n$$$).
A bit of thinking may lead you to the observation that solving the task in $$$O(n log n)$$$ or even $$$O(n log^2 n)$$$ isn't pleasant. The constraints are low enough to allow an $$$O(n \sqrt n)$$$ solution, how about giving it a try?
If an element $$$V$$$ appears more than $$$\sqrt n$$$ times, we can simply brute-force this pair with partial sums $$$(D,V)$$$ in $$$O(n)$$$.
For the other elements, for all the appearances of $$$V$$$ we'll consider only at most $$$|V|+1$$$ neighboring occurrences of $$$D$$$ to search for the optimal interval. We can generalize the brute-force solution to work for this case too, by writing a function that solves just for a vector of interesting positions. Don't forget to take into account extending intervals with zeroes as well.
With proper preprocessing, this gives a solution in $$$O(|V|^2)$$$ per value $$$V$$$. Therefore, total runtime is bounded by $$$O(n \sqrt n)$$$.
We're interested in the longest possible recovery path, so let's imagine choosing the longest sequence of operations ourselves. How long can this process last?
Let $$$P$$$ be the number of pairs of neighboring cells with different state. Consider what happens to $$$P$$$ after an operation where we change the state of a cell $$$c$$$. It can be seen that $$$P$$$ decreases by 1 if $$$c$$$ had a neighbor with the same state as $$$c$$$, and $$$P$$$ decreases by 3 if all the neighbors of $$$c$$$ had a different state. Let's call the first kind of operation cheap and the other expensive.
We now know that the process cannot last forever. When is it possible that the patient never recovers? If at some point there is a cycle of infected cells, then none of them can ever become healthy. Conversely, if there is no cycle of infected cells, and not all cells are healthy, then it is possible to make some infected cell healthy. If $$$A$$$ is the initial set of infected cells, let $$$\overline A$$$ be the set of cells which can eventually be infected. By the above, we should output SICK if and only if $$$\overline A$$$ contains a cycle.
We can compute $$$\overline A$$$ using a BFS. No cell with coordinates outside of $$$[0, 500) x [0, 500)$$$ will ever become infected, so we can safely make the BFS linear in the number of cells in this region.
Let's assume that $$$\overline A$$$ contains no cycle. We want to determine the minimum possible number of expensive operations used during the process of making all the cells healthy. We can consider each connected component of $$$\overline A$$$ separately and add the results, so let's suppose $$$\overline A$$$ is connected. The very last operation must be expensive, since it changes the state of an infected cell with three healthy neighbors. There is one other case where we need an expensive operation: if there's no way to make a cheap operation at the very beginning. In fact, this can happen only if $$$A$$$ consists of three cells arranged in a 'triforce'. It turns out that we never need any other expensive operations.
So, assuming $$$\overline A$$$ contains no cycle, we can compute the longest possible recovery period as follows. Compute the number $$$P$$$ of pairs of neighboring cells with different states. Subtract twice the number of connected components of $$$\overline A$$$. Subtract twice the number of connected components of $$$\overline A$$$ for which the corresponding cells in $$$A$$$ are just three cells arranged in a triforce.

Note that the observation that the bad beginning component is only a triforce is actually not necessary to code a working solution (one can just check if there's a cheap move at the beginning, just remember that we're inspecting components of $$$\overline A$$$), but it will help us to prove the solution formally.
Let's now prove that we never need any other expensive operations than the ones described. Suppose $$$A$$$ is a set of at least 2 infected cells, such that (i) $$$\overline A$$$ is cycle-free, (ii) $$$\overline A$$$ is connected, and (iii) $$$A$$$ is not a triforce. We claim that there is a some cheap operation, such that the resulting set $$$A'$$$ of infected cells still satisfies (i), (ii) and (iii). We will always have (i), since $$$\overline{A'} \subseteq \overline A$$$, so we just need to worry about (ii) and (iii), i.e. we need to ensure that $$$\overline{A'}$$$ is connected and that $$$A'$$$ is not a triforce.
We need to consider a few different cases.
Suppose there is a cheap infection operation. Then just perform it. The resulting set $$$A'$$$ will have $$$\overline{A'} = \overline A$$$ still connected, and $$$A'$$$ will not be a triforce since it has adjacent infected cells.
Suppose there is no cheap infection operation, but there is a cheap operation turning a cell $$$c$$$ from infected to healthy. Consider what happens if we perform it. Since there is no cheap infection operation, any cell in $$$\overline A \setminus A$$$ must have three neighbors in $$$A$$$. So it has at least two neighbors in $$$A \setminus {c}$$$. So it lies in $$$\overline{A \setminus {c}}$$$. So $$$\overline{A\setminus{c}} \supseteq \overline A \setminus{c}$$$. We claim that (ii) is satisfied, i.e. $$$\overline{A\setminus{c}}$$$ is connected. If $$$c$$$ is a leaf in $$$\overline A$$$, this is clear, since removing a leaf from a tree does not disconnect it. If $$$c$$$ is not a leaf in $$$\overline A$$$, then it has at least two neighbors in $$$\overline{A\setminus{c}}$$$, so $$$\overline{A\setminus{c}} = \overline A$$$ is again connected. So the only possible issue is with (iii), i.e. $$$A \setminus {c}$$$ might be a triforce. In this case, $$$A$$$ must be a triforce with an extra cell added, and we should just have chosen another $$$c$$$.
Suppose there is no cheap operation. This means that no elements of $$$A$$$ can be adjacent (since a tree with more than one vertex has a leaf). Moreover, any element of $$$\overline A \setminus A$$$ is surrounded by elements of $$$A$$$. Because $$$A$$$ has at least 2 cells and $$$\overline A$$$ is connected, we must somewhere have three cells in $$$A$$$ arranged in a triforce. See the picture below. The green cells are not in $$$A$$$ since no elements of $$$A$$$ are adjacent, and the red cells are not in $$$A$$$ since $$$\overline A$$$ is cycle-free. So $$$A$$$ cannot have any cells other than these $$$3$$$, since $$$\overline A$$$ is connected.
This covers all cases, finishing the proof.
Binary search is your friend. To determine if the answer is bigger or smaller than $$$r$$$, we need to count the number of pairs of points $$$A$$$, $$$B$$$ such that $$$d(O, AB) > r$$$.
We need to reformulate the condition $$$d(O, AB) > r$$$ to make the counting easier.
Draw a circle of radius $$$r$$$ centered on $$$O$$$, and consider two points $$$A$$$, $$$B$$$ strictly outside the circle. Note that $$$d(O, AB) > r$$$ if and only if $$$AB$$$ does not intersect this circle.
Now draw the tangents from $$$A$$$, $$$B$$$ to the circle. Let the corresponding points on the circle be $$$A_1, A_2, B_1, B_2$$$. Observation: the line segments $$$A_1 A_2, B_1 B_2$$$ intersect if and only if $$$AB$$$ does not intersect the circle. Moreover, if we pick polar arguments $$$a_1, a_2, b_1, b_2 \in [0, 2\pi)$$$, for the points in the circle, such that $$$a_1 < a_2$$$ and $$$b_1 < b_2$$$, then the line segments intersect if the intervals $$$[a_1, a_2], [b_1, b_2]$$$ overlap.
We don't need to worry too much about precision errors, because if $$$r$$$ is close to the real answer, then it doesn't matter what our calculations return.
(To compute $$$a_1$$$, note that $$$\cos \angle AOA_1 = r / \left| OA \right|$$$. So we get $$$a_1, a_2$$$ be adding / subtracting $$$\cos^{-1} \frac r {\left|OA\right|}$$$ from the argument of $$$A$$$.)
We can prove the observation by considering three different cases, shown in pictures.
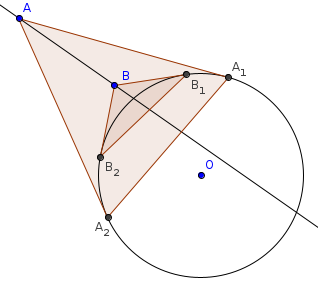
One circle segment contains the other, and the line $$$AB$$$ intersects the circle outside the segment $$$AB$$$.
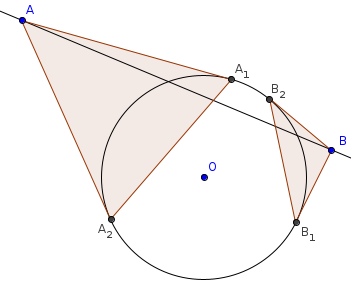
The circle segments are disjoint, and the line segment $$$AB$$$ intersects the circle.
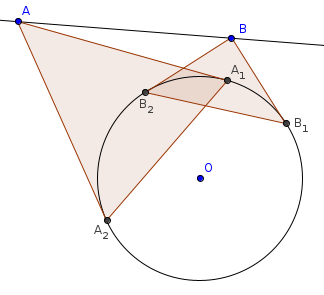
The circle segments partially intersect, and the line $$$AB$$$ does not intersect the circle.
Now we have computed some intervals and want to find the number of pairs of intervals which partially overlap. To do this, first sort the endpoints of the intervals. Do some coordinate compression on the left endpoints. Build a Fenwick tree on the compressed coordinates. Sweep through the endpoints. Whenever you see a left endpoint, add it to the tree. Whenever you see a right endpoint, remove it from the tree, query the tree for the number of points greater than the corresponding left endpoint, and add the result to the answer.






This editorial was created... 3 months before the contest? That might be the fastest editorial ever on Codeforces.
Time is relative. How it moves for one may be very different for how it moves for another :p
That time is very strange...
Someone just got inspired after watching Dark
.
The
Contest timelinesection is pretty nice and active. I like it.Best editorial ever, HOLY!
Why O(nm) is enough for D? 5000^2 = 25000000 is a very big number. As for me, I was searching for smth like O(nlogn) the whole contest...
In most cases, as long as $$$n < 10^4,$$$ $$$O(n^2)$$$ solution can pass
Ok, thanks. Actually, I ran program with two cycles that were doing 5000 iterations each, and it was running ~10 seconds ¯_(ツ)_/¯.
Probably you've run your program in Debug mode (if we are talking about c++), try to switch your mode to Release and test again.
You are right. Thank you so much!
I might be wrong, but for Div 2 D, shouldn't it be $$$dp[i][j] = max(dp[i][j], dp[i - 1][j - 1] + 2)$$$?
And there is another small typo under that line (but it's not a big deal)
Yes, I believe it should be max instead of min.
I did the same and got AC during the contest.
Great explanation for Problem D
Nice $$$O(n)$$$ solution to D (or at least $$$O(n \log n)$$$)
In problem D we can test two values $$$A$$$ and $$$B$$$ in time $$$O(occ(A) + occ(B))$$$, where $$$occ(x)$$$ means how many times $$$x$$$ appears. We should fix A as a mode and loop over all values of $$$B$$$ in order to get solution for D1. But if we can somehow bound number of interesting occurences of $$$A$$$ to $$$O(occ(B))$$$ than we would be able to solve that problem in linear time, right? And that is what we are gonna do now.
We will mark some occurences of $$$A$$$. Let us go through values of $$$B$$$ from left to right. For each value of $$$B$$$ let us mark closest unmarked occurence of $$$A$$$ on the left and on the right (note that closest occurences may already be marked). We keep only marked occurences of A and there are at most $$$2occ(B)$$$ of them, so that suits us.
What is left to do is to prove that answer doesn't change if we discard the rest of unmarked occurences (which I left as an exercise) and to implement that quickly. It is very easy to implement that in $$$O(n \log n)$$$ what I did during testing, but it probably is doable in $$$O(n)$$$, but I haven't given it much thought.
Nice solution! (I ranted about my bad nlogn solution, but this one is much cleaner so nvm)
Consider this array: $$$[1,2,1,1,1,2,1]$$$. In this case $$$A=1$$$.
When $$$B=2$$$, we mark the $$$1$$$s occurring at indices $$$1,3,5,7$$$ and the new array is $$$[1,2,1,1,2,1]$$$. Note that $$$[2,1,1,2]$$$ is a valid solution in the new array but this corresponds to $$$[2,1,1,1,2]$$$ in the actual array, which is not a valid solution. Could you clarify this? @Swistakk
We are not removing unmarked occurences of $$$A$$$ from the array, we are just stating that those unmarked occurences can't be the first time or the last time $$$A$$$ appears in the solution, so you can just skip over them.
Yes, it makes sense. Thanks!
Good catch, my wording could have been more precise. As loan explained, I don't consider them as contained in optimal interval, but I still remember for each occurence of A where is the next/previous original occurence that tells me how much I can expand this interval without containing more of its occurences
1447D time limit is too tight that bottom-up implementations are accepted but not top-down with same time complexity.
mine is O(2 * N^2) top down and it's Accepted in 592ms.
Generally recursive implementation will spend more time There is a very good comparision between those two ways
I don't think it's recursion or the TL. I think it's your implementation. Looking at 98495013, you use binary search in your dp, adding an additional log factor.
No, I was talking about my previous submission https://codeforces.com/contest/1447/submission/98483575. As per my analysis, it should be O(3*N^2).
Using big O notation, your time complexity is O(nm). However, you don't have a great constant. Intended solution's dp returns an int while yours returns a tuple. Also, I'm not sure why you're comparing top down and bottom up. Does your solution pass if you write it iteratively?
Sorry if this is a stupid question but what is the "standard algorithm" of computing longest subarray with sum 0?
Subarray $$$[a, b)$$$ has sum 0 <=> $$$prefsum(a) = prefsum(b)$$$
So store an array of minimum position with given prefix sum?
Exactly. Take a note this prefix sum may be negative, but it is within interval $$$[-n, n]$$$, so you may use a static array of length $$$2n+1$$$ with offset $$$n$$$. And remember about first empty prefix sum.
Thank you for answering!
301A Similar Hard version of problem B for practise
Can someone help me identify why my solution is wrong ? https://codeforces.com/contest/1447/submission/98488500
I do normal LCS, then reconstruct the positions where the LCS exists into two arrays. Now I go through all possible substrings that contain an LCS and maximize value across all.
Check the code, it'll make more sense there.
Any help is apprecited!
In every case, we can refer to DP[i][j−1] or DP[i][j−1] to extend one of the previous substrings, but not the LCS, so: DP[i][j] = max(DP[i-1][j], DP[i][j-1]) — 1.Can anyone explain this point in Solution of problem D along with an example? I could not understand this part of the solution.
Btw Great contest kpw29! Loved the concept of A.B and C!
$$$A = ababaa$$$ $$$B = abbabb$$$
Consider the above 1-indexed strings. Since $$$A[4] \neq B[4]$$$, both of them can't be included in the LCS at the same time. So, $$$dp[4][4]$$$ must be the same LCS as $$$dp[4][3]$$$ ($$$B[4]$$$ is not included in the LCS) or $$$dp[3][4]$$$ ($$$A[4]$$$ is not included in the LCS).
To get from $$$dp[4][3]$$$ to $$$dp[4][4]$$$, we extend $$$B$$$'s substring by $$$1$$$, leaving $$$A$$$'s substring and the LCS the same. This results in subtracting $$$1$$$ from the similarity score.
Similarly, to get from $$$dp[3][4]$$$ to $$$dp[4][4]$$$, we extend $$$A$$$'s substring by $$$1$$$, leaving $$$B$$$'s substring and the LCS the same. This also results in subtracting $$$1$$$ from the similarity score.
So, $$$dp[4][4] = max(dp[3][4]-1, dp[4][3]-1) = max(dp[3][4], [4][3]) - 1$$$. This generalizes to $$$dp[i][j] = max(dp[i-1][j], dp[i][j-1]) - 1$$$.
Thank you for such a good explanation 2020akadaver. I usually do not understand DP editorials but this was one of the rare excellent ones! Kudos
After 35 minutes trying to get some property out of problem A, i checked if I was not in div1 contest by mistake, next contest I will start with problem C.
Hi, I don't understand why in problem C doesn't matter if the matrix has a zero.
If the matrix has a zero, i can transform all negatives in positives, taking the negatives with the zero.
Yes! You can but in that case minimum abs value would be 0 only!
Oh! I see! Thanks
Can Div 2C be solved with DP? Cause mine got TLE
No. Also, its not DP but rather straight up recursion/backtracking. In the worst case, you will never find a valid sequence and you will have 2^n iterations making the complexity O(2^n). I did the same and got TLE on system check.
F is too easy and standard for 3000... and E deserves 4000.
We honestly didn't expect so many wrong answers on E. The proof is a bit tricky, but analyze the setup and exclude two quite obvious cases where you can't use the cheap operation didn't sound significantly harder for us.
We hope you've enjoyed solving the problems anyway!
A, C and D was nice and I enjoyed them a lot! Thank you for providing the problem set.
[Deleted]
i made a divide and conquer solution for C but it's missing cases on tc 1023 pretest 2 if anyone can see what's wrong with my approach 98480163
One thing I can clearly see is that u have used w/2 but u must use (w+1)/2. Rest you have done hell lotta extra things which complicates the code and they need not be done. You should refer editorial :)
ya that's for sure
1447D — Catching Cheaters
In this problem why we not considering starting index of any substring; dp[i][j] just indicates that first substring ends at i and second at j
Is it because the value will be at least zero?
tnx for fast & complete editorial
this is the most kind and elegant editorial i've ever seen. step by step hints made me understand better and think more by myself. thanks a lot.
loved the idea of "contest timeline"
Div-2D Had a very hazy understanding of how the +2, -1 tracking would address the fact that the actual substrings chosen must have both start and end characters to be part of the LCS.
The solution I was trying for was tracking the starting matched characters along with traditional LCS to calculate score at each step. So at (i,j) I would know the LCS and the (i_, j_) where this LCS started. Of course, cases like <2 and <0 scores must be handled appropriately.
Ran into the issue that I can't really have 5000x5000x3 integers, got memory limit exceeded in testcase 12. The trick to that I discovered from one of the successful submissions as I was looking for one which matched my approach and I found one where the MLE was tackled by the fact that we need the previous and current row only as we aren't answering queries that would need these previous values.
98501736
Very interesting questions indeed!
Does anyone know about test case 1023 in C ? All the solutions failed on that one.
keep a counter of the number of testcases, print input if counter = 1023, check testcase in the checker log.
Thank you for a great contest!!
Can anybody please tell me what's wrong in using ceil in div2C after contest i tried by replacing ceil with (w+1)/2 and it gave AC
I think you tried ceil(w/2). Here w/2 will be performed first and it is integer division so it will floor. Basically for example if w=5, then ceil(5/2) -> ceil(2) -> 2. You need to work with floating point there if you want ceil to work.
ohh shit i forgot about that ,thanks man
Can anyone tell me why my submission 98492742 for Div2D fails for test case 6?
I'm using pair<int,pair<int,int>> DP[i][j] where:
I'm not sure because your code is quite complicated. But usually people failed on test 6 when they didn't consider the possibility to restart the substrings (setting dp[i][j] = max(dp[i][j], 0) in the editorial)
Guys, i am not sure why my solution of problem C is wrong. Can anyone help me debug it? That would be much appreciated! 98506202
Your solution will most likely fail for the case:
1 3 1
the result my code (and my understanding of the problem) is: 1 1. Can you tell me the correct result pls. And thank you for responding.
EDIT: oh crap, i realized now, i misread the symbol in the orignial problem
Item of $$$1$$$ is not enough to fill more than half of the knapsack. Your if w/2 is incorrect, should be (w+1)/2
What is the actual proof for div1F? The pictures make it intuitive but I'm not sure how to rigorously prove.
One fun way to prove it is to use a bit of Euclidean Geometry. The intersection $$$X$$$ of $$$A_1A_2$$$ and $$$B_1B_2$$$ and the projection $$$Y$$$ of $$$O$$$ onto $$$AB$$$ are inverses with respect to the circle, so $$$OX \cdot OY = r^2$$$ and one of the points lies inside the circle if and only if the other one lies outside.
The reason this is true is that the red lines are the polar lines of $$$A$$$ and $$$B$$$ with respect to the circle, so $$$AB$$$ is the polar line of $$$X$$$ and $$$OX$$$ cuts $$$AB$$$ at the inverse of $$$X$$$.
There is an older version of the editorial which was rewritten by _h_ so that it's a bit clearer, but in the process the more rigorous proof was lost. I wanted to revert to that revision, but forgot, and since Ari's answer is really good, I will allow myself to just rely on that :)
Here's a proof close to the pictures in editorial.
Let's imagine the circle is a solid "obstacle". I claim that A and B "see" each other -- i.e. the segment AB does not intersect the circle -- iff they both see some point on the circle. This then proves the observation, since the points on the circle seen by A are precisely those between A_1 and A_2.
Suppose A and B see each other. If the line AB intersects the circle, then A and B both see one of the intersection points, so done. Otherwise A and B both see the point on the circle closest to the line AB, so again done.
Now suppose A and B both see some point X on the circle. So the circle does not intersect AX or BX. So A and B both lie on the same side of circle tangent at X. So done.
For what it's worth, this argument doesn't use any property of the circle other than the fact that it's convex (for second implication).
Sorry, I got confused about what we wanted to prove. The above is correct, but not strong enough to prove the observation... let me try again.
Note that B "sees" A1 if and only if B and O lie on opposite sides of the tangent line A A1. Consider the four different cases of whether B sees A1, A2, both, or none. If B sees A1 but not A2, then the chords B1 B2 and A1 A2 must intersect, since the segment B1 B2 contains A1 but not A2. In this case, it should also be clear that the line AB does not intersect the circle. The cases where B sees A2 but not A1 is of course the same.
If B sees neither A1 nor A2, then B lies on the same side as O of both tangents A1, A2, and from this it should be clear that AB intersects the circle. Similarly of B sees both A1 and A2.
Hi, My solution gives TLE for pretest 3 for div2 C problem. Plz help why cause imo it takes O(nlogn) and it follows the same way as suggested in alternative soln of the editorial. 98491654
I think indexof() function will take O(n) time inside the for loop so it's O(n^2)
I saw many people who get accepted on Div2E/Div1C uses a 2d structure to store data, which are very similar to this one 98462641. What is the name of this method? It seems a common way
In my way, I just binary search the seperate position in every step 98511888
Never mind, I understand it is actually Trie
Very much fancy the step-by-step tutorial which guides one to think more and more deeply. :)
Thanks! I wish all the editorials were done this way :)
Very high quality contest and tutorial! Thanks!!!
We're glad to hear that!
How would the solution change in Div2 D if it was also said to output the selected 2 substrings for which we are getting the best similarity? Any clues or suggestions are appreciated.
Let pos[i][j] be a number from 1 to 4. if we have maximum answer when we start substrings from A[i] and B[j] and end the in A[i] and B[j] the pos = 1. if we have it when we are using DP[i — 1][j — 1] then pos = 2. we can have pos = 3 or 4 when we are using DP[i — 1][j] or DP[i][j — 1]. Now all we need is to find maximum DP[i][j] and start finding the substrings using pos[i][j]. It wouldn't take much time and we can handle it in O(n.m) in worth case.
That was really a fantastic editorial. The way they provided hints and moved towards the solution was great. Maybe just adding a sample solution code will be more great. We will be waiting for these types of editorials everytime.
Sure. The usual solution is to wait after the end of systests, submit model solutions in practice mode and then link them. I just forgot to do that :)
Solution for problem Knapsack. https://codeforces.com/contest/1447/submission/98518206
this failed on test 2. Can somebody tell me why this solution is wrong.
i got
hope u get your mistake the anwer should be -1
OMG! THE BEST EDITORIAL EVER in the history of cf !!! wow, great job ! Community appreciates your awesome work
'For the other elements, for all the appearances of V we'll consider only at most |V| + 1 neighboring occurrences of D to search for the optimal interval.'
Can someone explain this part of the explanation for problem F2? Thanks in advance.
Great contest btw!
You're looking for a segment with sum $$$0$$$, if you take at least $$$|V| + 1$$$ consecutive elements for number $$$1$$$ then there's no way that something including the last element be in the optimal solution, as there are at least $$$|V|$$$ other elements before you reach any $$$-1$$$, and there are $$$|V|$$$ elements in total.
I hope it helps!
in problem C as per the alt solution if i sort the elements, how do i keep track of the original indices?
Sort pairs of the form (element, initial index).
For div1 D2
After reading the editorial for D1, I was wandering if the property "Most frequent element will be in optimal solution" can be extended to "Most frequent element and second most frequent element will be in optimal solution"
WA on test 6
then I try some random stuff.
I sort every element by their frequency.
let's call the most frequent value by $$$V$$$ I do the similar thing in D1, just that except for enumerating all of the other element that could have the same frequency as $$$V$$$, I took the first 750 of them
it somehow passed. 98560373
Can someone help me prove it right or hack me ?
Hmm, this is quite strange. I recall writing a solution which did something very similar and failing the tests.
In theory, if you have all elements but one appear 2 times then by taking 750 random values which appear 2 times you should have quite a slim chance of finding the right pair to use.
I actually tried smaller number after that submission, it turns out that setting 750 to 100 will pass too.
Maybe it's not necessary to have the right pair to find the optimal solution.
(I cannot prove it though .. qq
Any Greedy solutions for div2 D?
IN div 2D,can anyone explain what does this line means
If a substring has a negative score, we can throw it away and start from scratch- 1.This is similar to kadane's algorithm for the maxiumum subarray sum problem. If we ever get a negative value for the maximum subarray sum ending with the previous element in the array, it is best to "throw that away" than to add that "maximum sum" to the next value in the array. I hope this helps!
Adding more to this question, can someone please tell how defining the dp for every combination of prefixes of the two strings(that is, dp[i][j] = ans for prefix i from A, and prefix j from B), in itself answers for all possible combinations of 'substrings' under i and j, and not just the prefixes. I really am not able to get this :(
"DP[i][j] be the maximum similarity score if we end the first substring with Ai and the second substring with Bj"
In 1447D - Catching Cheaters we used the above assumption. But wouldn't this only give us the possible Similarity Scores, when the last characters of the string are trimmed? Thus the first characters of the strings A and B will always be used.
Since Ai would always contain the first i characters, so for instance if the first characters in A is not necessary for the substring since we always take the first i elements, it will still consider it.
For Div 2 F, i've come up with an approach with the complexity of $$$O(nlogn)$$$ , But it fails on test #5
Here's my submission. anyone can tell me where i'm going wrong?
I know a lot of people solved C. But for Those who are unable to think why greedy works or unsatisfied with editorial can read this :)
so we have to fill our knapsack such that sum(wt)<=w and sum(wt)>=(w+1)/2. let say there is one element which is satisfying above condn output that. otherwise elements are present in combo of ai < w or ai > w now do you want to include an item which has size > w in knapsack?? no because taking that in any situation will deny our requirements so let's shrink the array to only those elements which has size<w/2
Now we have all elements < w/2 if sum of all remaining elements <w/2 that means we can't make req. config output -1
now there is always a way to make sum>=(w+1)/2 and sum<=w how?? sort it. iterate in reverse manner. stop where sum>=w/2.
now why let define number line as ----region1-----w/2----region2------w---region3------- now if we are on region 2 we are ok output now many of you are thinking it may be possible we are at end of region 1 and some number comes and we promoted to region 3 right?? so my dear friend promoting from region 1 to region 3 requires w/2+something value which is not present in our array. because if it was there we can output that :)
If something is still unclear let me know :)
Thank you for your amazing explanation! Better than editorial
Observation
Now we have to prove there is always exist such $$$sum$$$ satisfy the condition.
How to translate "triforce" into Chinese? I wrote a blog at https://www.cnblogs.com/jz-597/p/14008291.html but I don't know how to show the concept concisely.
kpw29 can you please explain the formula 1 + max(F(S0),F(S1)) for the problem div2E .
For Problem F, I'm really puzzled.I try to solve it using binary search. In my opinion, when I cannot find an answer while the most occurences freq of an element in the longest subarray is x, there won't be answer for x' (x' > x). Therefore, I use binary search to find the largest x and record the answer using ans. However, I can't pass Test Case 5. Can someone please point out where the flaw is? https://codeforces.com/contest/1446/submission/106463443
Solution for problem D case1 is DP[i][j] = max(DP[i][j], DP[i- 1][j- 1] + 2)