


Yesterday I saw this blog and thought that one bad editorial is better than zero good ones, right? So, enjoy it!
Here are links to contests: Div. 1, Div. 2
Div2A
393A - Nineteen
Looking at examples and thinking about different cases lead to the idea that the best result would be to build a string which starts with $$$nineteenineteenineteen...$$$. The first word $$$nineteen$$$ requires 3 letters $$$n$$$, 3 letters $$$e$$$, 1 letter $$$i$$$ and 1 letter $$$t$$$. Every next occurrence of $$$nineteen$$$ requires the same set of letters, but we need only two letters $$$n$$$ for each new word. In other words, we can start with $$$n$$$, and then every word will need exactly two extra $$$n$$$-s. Let $$$cnt[c]$$$ denote the number of characters $$$c$$$ in the string. Then the answer is $$$min\left(\left\lfloor\frac{cnt[n] - 1}{2}\right\rfloor, \,\left\lfloor\frac{cnt[e]}{3}\right\rfloor,\, cnt[i],\, cnt[t]\right)$$$. (In theory this minimum could be $$$-\left\lfloor\frac{1}{2}\right\rfloor$$$, but in C++ it is equal to zero, so everything works fine)
#include <bits/stdc++.h>
using namespace std;
int main() {
ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL);
string s;
cin >> s;
map<char, int> cnt;
for (auto c : s) {
cnt[c]++;
}
cout << min({(cnt['n'] - 1) / 2, cnt['e'] / 3, cnt['i'], cnt['t']}) << '\n';
return 0;
}
Div2B
393B - Три матрицы
We can write this system of equations, using the fact that $$$B[j][i] = -B[i][j]$$$ and $$$A[i][j] = A[j][i]$$$
From that, it is easy to conclude that $$$A[i][j] = \frac{W[i][j] + W[j][i]}{2}$$$ and $$$B[i][j] = \frac{W[i][j] - W[j][i]}{2}$$$.
By the way, there is some interesting math connected to this problem: link
#include <bits/stdc++.h>
using namespace std;
int main() {
ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL);
int n;
cin >> n;
vector<vector<double>> w(n, vector<double>(n));
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
cin >> w[i][j];
}
}
vector<vector<double>> a(n, vector<double>(n));
vector<vector<double>> b(n, vector<double>(n));
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
a[i][j] = (w[i][j] + w[j][i]) / 2;
b[i][j] = (w[i][j] - w[j][i]) / 2;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
cout << a[i][j] << ' ';
}
cout << '\n';
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
cout << b[i][j] << ' ';
}
cout << '\n';
}
return 0;
}
Div2C/Div1A
392A - Заблокированные точки
Let's look at all pairs of neighboring points such that one of them is special and the other one is not. I claim that it is necessary and sufficient to block at least one point in every such pair
Necessity is obvious. Let's prove sufficiency. Assume that we blocked at least one point in each pair, but there are two points $$$A$$$ and $$$B$$$ such that $$$A$$$ is special, $$$B$$$ is not and they are 4-connected. Then look at the path between these points. It starts with a special point and ends with non-special. That means that there are two adjacent points in this path such that the first one is special and the second one is not. But it contradicts our statement that we blocked at least one of the points in each pair.
Now let's look at these pairs. For simplicity, we will look at only $$$\frac18$$$-th of a circle.
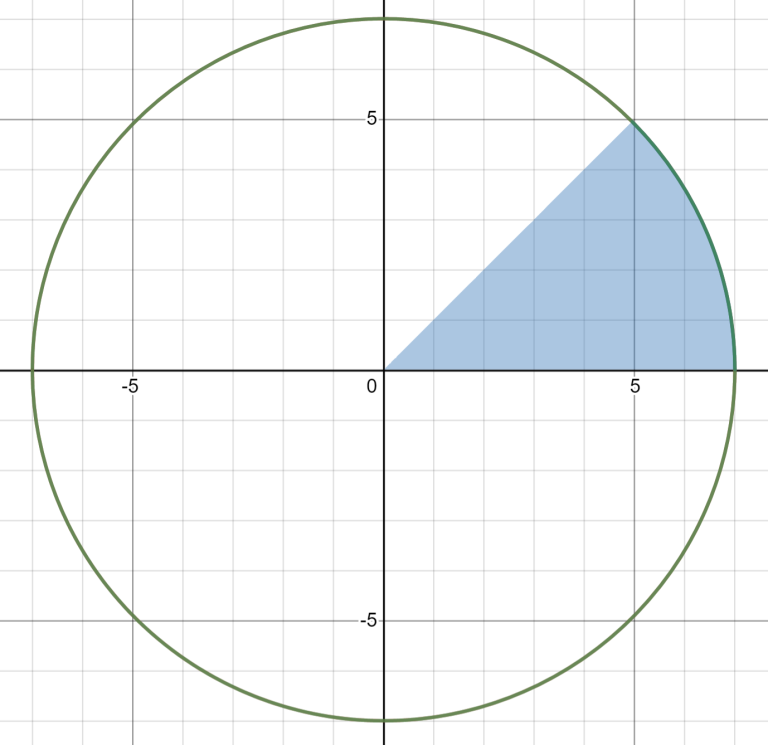
And let's draw all horizontal pairs with a point inside the selected piece.
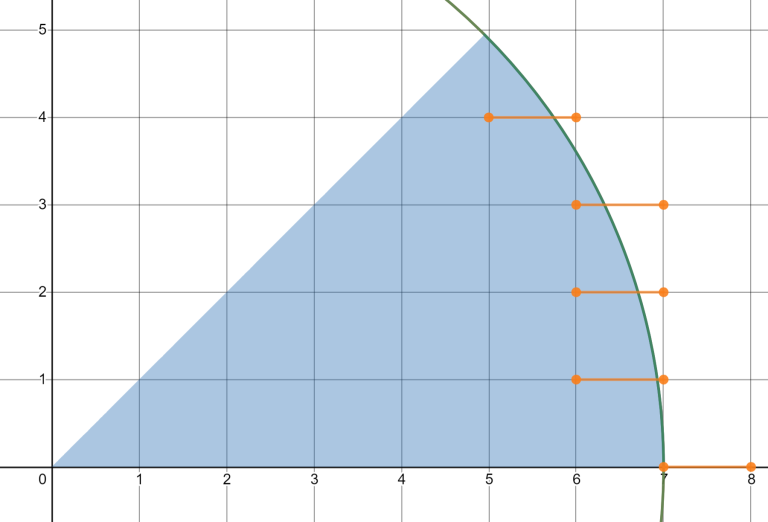
There are also some vertical segments, but it can be proven with some geometry that the segments on the neighboring horizontal line are either on the same x-coordinate, or one is shifted by one. This means that if we choose the leftmost point in each of these segments, we will cover all vertical pairs as well.
With some symmetry, this can be done for other pieces of a circle.
There is only one thing left — we need to bring all pieces together. It is easy when two pieces share a horizontal or vertical line, but in the other case, we need another picture.
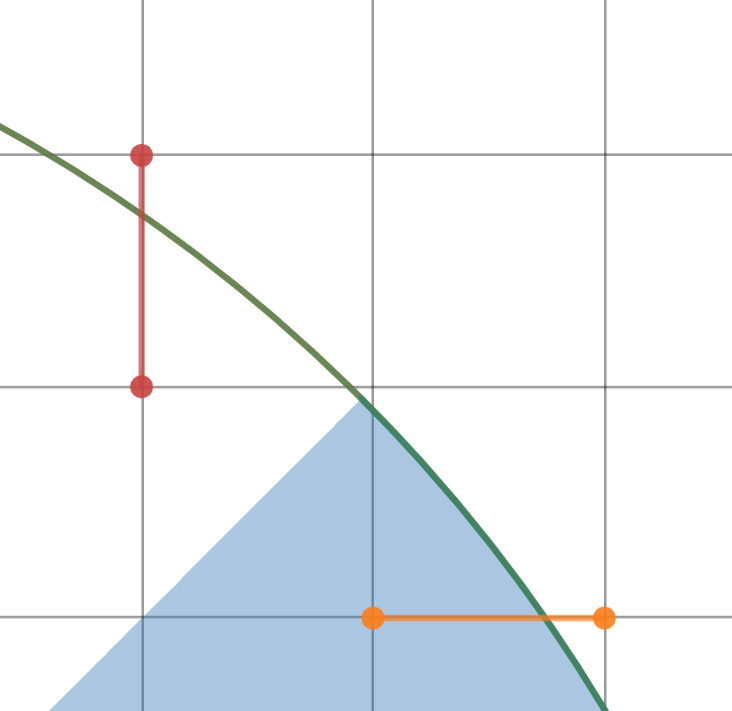
In this case, everything is already fine, we don't have any "leaks" between parts
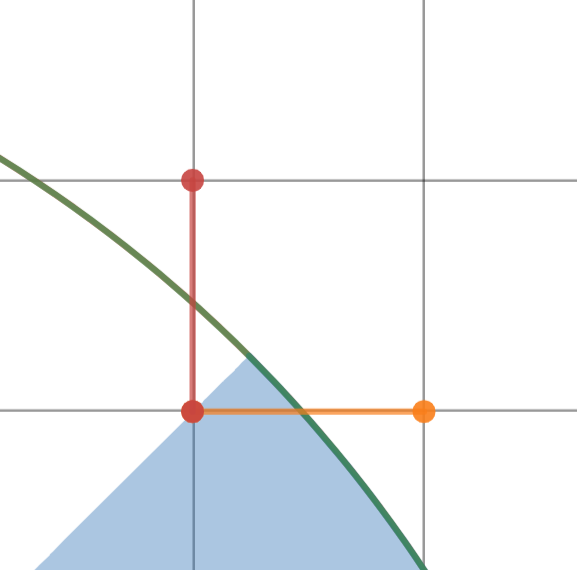
In that case, we don't have any leaks either, but we have overlapping segments, and that means that we case save 1 point here and 4 points total.
All we need now is to calculate the number of segments in a circle sector (it is $$${n}/\sqrt{2}+1$$$) and differentiate these two cases.
#include <bits/stdc++.h>
using namespace std;
int main() {
ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL);
long long n;
cin >> n;
if (n == 0) {
cout << 1 << '\n';
return 0;
}
int L = sqrt(n * n / 2);
pair<long long, long long> near = {L + 1, L};
int ans = (L * 2 + 1) * 4;
if (near.first * near.first + near.second * near.second > n * n)
ans -= 4;
cout << ans << '\n';
return 0;
}
Div2D/Div1B
392B - Ханойская башня
First, understand this solution of the standard Hanoi puzzle, if you don't know it. I will use the same idea to solve this problem. Let's create a function $$$calc(from, to, n)$$$ which will count the minimal cost to move $$$n$$$ disks from $$$from$$$ to $$$to$$$. If $$$n=1$$$ then we either move the disk directly to $$$to$$$, or we first move it to the $$$mid$$$ (the remaining rod) and only then move to $$$to$$$. If $$$n > 1$$$ then again, there are two possible strategies. Either we use moves from standard solution — move $$$n-1$$$ disks to $$$mid$$$, move 1 disk from $$$from$$$ to $$$to$$$, then move $$$n-1$$$ disks to $$$to$$$. Or we can make more moves but possibly with less cost: move $$$n-1$$$ disks to $$$to$$$, then 1 disk from $$$from$$$ to $$$mid$$$, then $$$n-1$$$ disks back to $$$from$$$, then 1 disk to $$$to$$$, and finally $$$n-1$$$ disks to $$$to$$$. Here are pictures for both cases:

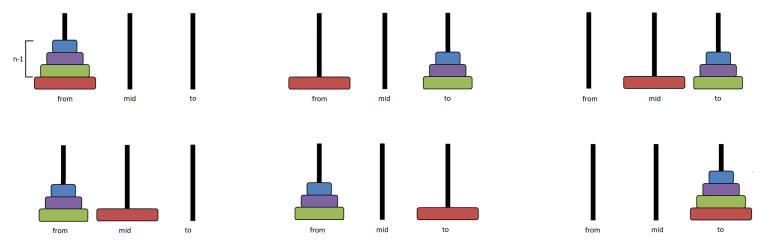
For moving $$$n-1$$$ disks we will make recursive calls. If we just do that, we will have an exponential solution, which is not very nice. But we only have $$$3\times 2 \times n $$$ different calls — 3 options for $$$from$$$, 2 for $$$to$$$ and $$$n$$$. That means that we can just store every value which we already counted (or I can say a fancy word memoization, which means the same thing)
#include <bits/stdc++.h>
using namespace std;
#define ll long long
array<array<ll, 3>, 3> t;
map<pair<pair<int, int>, ll>, ll> mem;
ll calc(int from, int to, int n) {
auto p = make_pair(make_pair(from, to), n);
if (mem.count(p))
return mem[p];
int mid = 3 - from - to;
if (n == 1) {
return mem[p] = min(t[from][mid] + t[mid][to], t[from][to]);
}
return mem[p] = min(calc(from, mid, n - 1) + t[from][to] + calc(mid, to, n - 1),
calc(from, to, n - 1) + t[from][mid] + calc( to, from, n - 1) + t[mid][to] + calc(from, to, n - 1));
}
int main() {
ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL);
for (int i = 0; i < 3; ++i) {
for (int j = 0; j < 3; ++j) {
cin >> t[i][j];
}
}
int n;
cin >> n;
cout << calc(0, 2, n) << '\n';
return 0;
}
Div2E/Div1C
392C - Еще одна последовательность чисел
This is obviously some matrix-exponentiation problem. We just have to figure out the matrix. Well, let's look at what we have
Then we just have to store $$$A_{i-1}(j)$$$ and $$$A_{i-2}(j)$$$ for every $$$j \in [0;k]$$$. And also we have to store the sum, so the matrix will be of size $$$2(k+1)+1$$$, resulting in $$$O(k^3\log n)$$$ in total.
If you need more information about matrix exponentiation, consider watching the video from Errichto. Oh, and I almost forgot. He says exponentation instead of exponentiation. Now you will not able to forget this, enjoy! Here is the link :) (Errichto, no offence, if you are reading this :) )
#include <bits/stdc++.h>
using namespace std;
#define ll long long
template<auto P>
struct Modular {
using value_type = decltype(P);
value_type value;
Modular(ll k = 0) : value(norm(k)) {}
Modular<P>& operator += (const Modular<P>& m) { value += m.value; if (value >= P) value -= P; return *this; }
Modular<P> operator + (const Modular<P>& m) const { Modular<P> r = *this; return r += m; }
Modular<P>& operator -= (const Modular<P>& m) { value -= m.value; if (value < 0) value += P; return *this; }
Modular<P> operator - (const Modular<P>& m) const { Modular<P> r = *this; return r -= m; }
Modular<P> operator - () const { return Modular<P>(-value); }
Modular<P>& operator *= (const Modular<P> &m) { value = value * 1ll * m.value % P; return *this; }
Modular<P> operator * (const Modular<P>& m) const { Modular<P> r = *this; return r *= m; }
Modular<P>& operator /= (const Modular<P> &m) { return *this *= m.inv(); }
Modular<P> operator / (const Modular<P>& m) const { Modular<P> r = *this; return r /= m; }
Modular<P>& operator ++ () { return *this += 1; }
Modular<P>& operator -- () { return *this -= 1; }
Modular<P> operator ++ (int) { Modular<P> r = *this; r += 1; return r; }
Modular<P> operator -- (int) { Modular<P> r = *this; r -= 1; return r; }
bool operator == (const Modular<P>& m) const { return value == m.value; }
bool operator != (const Modular<P>& m) const { return value != m.value; }
value_type norm(ll k) {
if (!(-P <= k && k < P)) k %= P;
if (k < 0) k += P;
return k;
}
Modular<P> inv() const {
value_type a = value, b = P, x = 0, y = 1;
while (a != 0) { value_type k = b / a; b -= k * a; x -= k * y; swap(a, b); swap(x, y); }
return Modular<P>(x);
}
};
template<auto P> Modular<P> pow(Modular<P> m, ll p) {
Modular<P> r(1);
while (p) {
if (p & 1) r *= m;
m *= m;
p >>= 1;
}
return r;
}
template<auto P> ostream& operator << (ostream& o, const Modular<P> &m) { return o << m.value; }
template<auto P> istream& operator >> (istream& i, Modular<P> &m) { ll k; i >> k; m.value = m.norm(k); return i; }
template<auto P> string to_string(const Modular<P>& m) { return to_string(m.value); }
using Mint = Modular<1000000007>;
// using Mint = Modular<998244353>;
// using Mint = long double;
vector<vector<Mint>> operator * (vector<vector<Mint>> a, vector<vector<Mint>> b) {
vector<vector<Mint>> c(a.size(), vector<Mint>(b[0].size(), 0));
for (int i = 0; i < a.size(); ++i) {
for (int j = 0; j < a[0].size(); ++j) {
for (int k = 0; k < b[0].size(); ++k) {
c[i][k] += a[i][j] * b[j][k];
}
}
}
return c;
}
vector<vector<Mint>> pow(vector<vector<Mint>> a, ll p) {
vector<vector<Mint>> res(a.size(), vector<Mint>(a.size(), 0));
for (int i = 0; i < res.size(); ++i) {
res[i][i] = 1;
}
while (p) {
if (p & 1) {
res = res * a;
}
a = a * a;
p /= 2;
}
return res;
}
int main() {
ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL);
ll n;
cin >> n;
int k;
cin >> k;
vector<vector<Mint>> mt((k + 1) * 2 + 1, vector<Mint>((k + 1) * 2 + 1, 0));
vector<vector<Mint>> vinit(mt.size(), vector<Mint>(1, 0));
// first k+1 elements are for F_{i-1}, next k+1 are for F_{i-2}, the last one is for sum up to A_{i-2}
for (int i = 0; i < k + 1; ++i) {
vinit[i][0] = 1;
vinit[i + k + 1][0] = 0;
vinit.back()[0] = 0;
}
vinit[k + 1][0] = 1;
vector<vector<Mint>> C(50, vector<Mint>(50, 0));
for (int i = 0; i < C.size(); ++i) {
C[0][i] = 0;
C[i][0] = 1;
}
for (int i = 1; i < C.size(); ++i) {
for (int j = 1; j < C.size(); ++j) {
C[i][j] = C[i - 1][j] + C[i - 1][j - 1];
}
}
vector<Mint> p2(50, 1);
for (int i = 1; i < p2.size(); ++i)
p2[i] = p2[i - 1] * 2;
for (int p = 0; p < k + 1; ++p)
mt[k + 1 + p][p] = 1;
mt.back().back() = 1;
mt.back()[k] = 1;
for (int p = 0; p < k + 1; ++p) {
for (int j = 0; j <= p; ++j) {
mt[p][j] += C[p][j];
mt[p][k + 1 + j] += C[p][j] * p2[p - j];
}
}
auto res = pow(mt, n) * vinit;
cout << res.back()[0] << '\n';
return 0;
}
Div1D
392D - Три массива
Let forget about $$$a$$$ for a minute and solve the problem for two arrays. Of course, it can be done with something like two pointers, but it is not extendable to three arrays (at least I don't know how). We need a more general approach. First, let's assume that $$$b$$$ has all elements, which $$$c$$$ contains. We can achieve that by copying $$$c$$$ at the end of $$$b$$$ (it is easy to see that this will not improve the answer).
Suppose for some number $$$k$$$ it has only one occurrence in $$$b$$$ and only one in $$$c$$$. And $$$b[i] = c[j] = k$$$. Then we denote $$$pos[i] = j$$$. Now, if $$$k$$$ has multiple occurrences in $$$c$$$, we will take the smallest $$$j$$$. If it has multiple occurrences in $$$b$$$, we will set the first $$$pos[i]$$$ to $$$j$$$ and others to $$$0$$$. Why that? Good question. Now the answer for the problem is $$$min_i((i-1) + max_{j > i}pos[j])$$$. The expression in the brackets corresponds to the case when we take $$$i$$$ first elements from $$$b$$$. Then we look for all other elements ($$$j>i$$$) and choose the shortest prefix of $$$c$$$ which contains all these elements. That explains why we write the first occurrence of $$$k$$$ in $$$c$$$ to $$$pos$$$. And we fill other values with zero because we don't need them if we already took the first occurrence in $$$b$$$.
Now get $$$a$$$ back. What changes if we have some numbers in $$$a$$$? Well, in that case, we can set $$$pos[i]=0$$$ for all occurrences of that number in $$$b$$$ (not only all except first). That means that if we iterate over prefix of $$$a$$$ from $$$0$$$ to $$$n$$$ then we will have to change some $$$pos$$$ to zero. But I prefer changing zeros to some values, so we will iterate from $$$n$$$ to $$$0$$$.
Well, let's iterate. Suppose we decided not to take prefix of length $$$i$$$ in $$$a$$$, and instead took prefix of length $$$i-1$$$. If there are some occurrences of $$$a[i]$$$ before $$$i$$$, then nothing changes in $$$pos$$$. But if there is no $$$a[i]$$$ before $$$i$$$, we have to update some $$$pos$$$ and recalculate $$$min_i((i-1) + max_{j > i}pos[j])$$$. I believe there are different structs that can do it, I will describe what I used.
In the expression, there are maximums on the suffix. They can be stored as pairs $$$(p, m)$$$ which means that up to position $$$p$$$ maximum on a suffix is at least $$$m$$$ (maximum-on-a-suffix is a non-increasing function, obviously). Now, to calculate the answer, we don't have to go through all $$$i$$$. We only need to consider such indices $$$p$$$ that some pair $$$(p-1, ?)$$$ exists in our set. That means that we have to check exactly one option for every pair of adjacent pairs. Remember, we only have to add pairs to this set. And it is easy — add a pair and remove enough pairs before it (while their $$$m$$$ less than new $$$m$$$). With every addition or removal, we have $$$O(1)$$$ additions or removals of options for an answer. Current answers can be stored in a multiset since we only need the minimal value. And if we are looking at a prefix $$$i$$$ of $$$a$$$, then we have to update the answer with $$$i$$$ + (the smallest value from multiset).
This is probably not the cleanest explanation, so there is a random picture which can help:
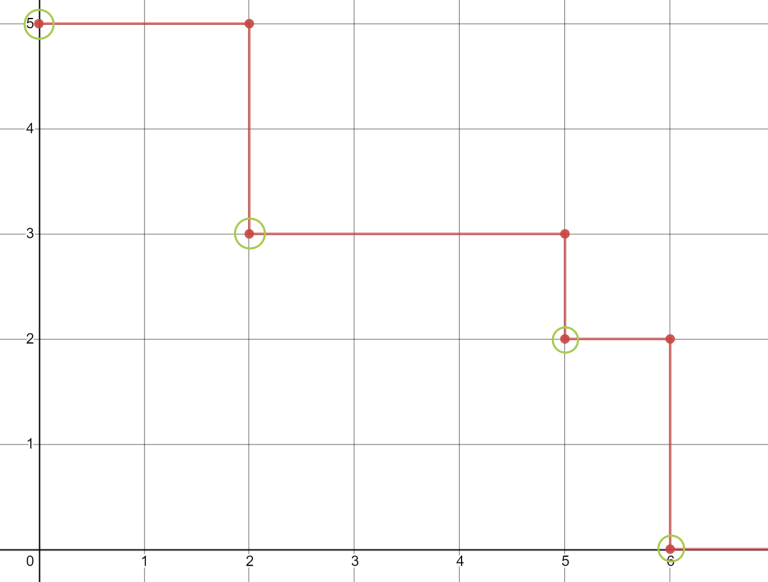
The picture can contain off-by-one error, depending on your indexing and my mistakes.
$$$pos = [1,\,0,\,5,\,3,\,0,\,3,\,2]$$$.
The picture illustrates maximums on a suffix for every $$$i$$$. In a set, we store one pair for each horizontal segment. When we need to update the answer, we look at all points with a green circle (or actually 1 to the right of these points because in this picture maximum at $$$x=2$$$ is $$$5$$$, so we need $$$(3,3)$$$, not $$$(2,3)$$$, but that is exactly what I meant when I said about off-by-one errors).
#include <bits/stdc++.h>
using namespace std;
int main() {
ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL);
int n;
cin >> n;
vector<int> a(n), b(n), c(n);
for (int i = 0; i < n; ++i)
cin >> a[i];
for (int i = 0; i < n; ++i)
cin >> b[i];
for (int i = 0; i < n; ++i)
cin >> c[i];
for (auto k : c) {
b.push_back(k);
}
map<int, int> whereb;
map<int, int> wherec;
for (int i = (int)b.size() - 1; i >= 0; --i)
whereb[b[i]] = i;
for (int i = (int)c.size() - 1; i >= 0; --i)
wherec[c[i]] = i;
vector<bool> first_in_a(a.size(), false);
vector<bool> first_in_b(b.size(), false);
set<int> ina, inb;
for (int i = 0; i < a.size(); ++i) {
if (!ina.count(a[i])) {
ina.insert(a[i]);
first_in_a[i] = true;
}
}
for (int i = 0; i < b.size(); ++i) {
if (!inb.count(b[i])) {
inb.insert(b[i]);
first_in_b[i] = true;
}
}
set<pair<int, int>> maxs;
multiset<int> res;
maxs.emplace(1e9, 0);
maxs.emplace(-1, 1e9 + 5);
res.insert(maxs.begin()->first + next(maxs.begin())->second + 1);
auto del = [&](pair<int, int> p) {
auto it = maxs.find(p);
assert(it != maxs.end());
auto inext = next(it);
auto iprev = prev(it);
res.erase(res.find(iprev->first + it->second + 1));
res.erase(res.find(it->first + inext->second + 1));
maxs.erase(it);
res.insert(iprev->first + inext->second + 1);
};
auto add = [&](pair<int, int> p) {
auto it = maxs.lower_bound(make_pair(p.first, -5));
if (it->second >= p.second) return;
if (it->first == p.first) {
++it;
}
while (prev(it)->second <= p.second)
del(*prev(it));
maxs.insert(p);
it = maxs.find(p);
auto inext = next(it);
auto iprev = prev(it);
res.insert(iprev->first + it->second + 1);
res.insert(it->first + inext->second + 1);
res.erase(res.find(iprev->first + inext->second + 1));
};
for (int i = 0; i < b.size(); ++i) {
if (first_in_b[i] && !ina.count(b[i])) {
int inc = 1e9;
if (wherec.count(b[i]))
inc = wherec[b[i]] + 1;
add({i, inc});
}
}
int ans = n + *res.begin();
for (int i = n - 1; i >= 0; --i) {
if (first_in_a[i]) {
if (!inb.count(a[i])) break;
int inc = 1e9;
if (wherec.count(a[i]))
inc = wherec[a[i]] + 1;
add({whereb[a[i]], inc});
}
ans = min(ans, i + *res.begin());
}
cout << ans << '\n';
return 0;
}
Div1E
392E - Удаляем подстроки
There will be three different $$$dp$$$, let's get that out of the way. I wanted to make $$$4$$$, but in the end decided to merge two of them.
Also, before everything, let's update $$$v$$$ with $$$v[i] = max_j(v[j] + v[i - j])$$$. Because sometimes we want to remove segment of length $$$5$$$, but $$$2 + 3$$$ gives more points.
First, let's discuss what a good substring is. It is either increasing, decreasing, or increasing up to something and then decreasing. And in any case, the difference between neighboring elements is exactly 1.
$$$dp\_mon[l][r]$$$ — the biggest score we can get from segment $$$[l;r]$$$ if in the end we are left with monotonous sequence, starting from $$$w[l]$$$ and ending with $$$w[r]$$$ (that means that we cannot remove $$$w[l]$$$ or $$$w[r]$$$). If we can't do that, $$$dp\_mon[l][r] = -\infty$$$.
$$$dp\_all[l][r]$$$ — the biggest score we can get from removing the whole segment $$$[l;r]$$$.
$$$dp[l][r]$$$ — the best score we can get on segment $$$[l;r]$$$ (no restrictions).
The answer will be $$$dp[1][n]$$$.
When we have these $$$dp$$$, it is not very hard to calculate them. To get $$$dp\_mon[l][r]$$$ we either have to remove everything in between (if $$$|w[l] - w[r]| = 1$$$), or for each number between $$$l$$$ and $$$r$$$ check if it can be in that monotonous sequence, and if it can, split by this number and add two $$$dp\_mon[l][j] + dp\_mon[j][r]$$$ (with intersection, yes).
Now $$$dp\_all$$$. First, let's update it with every $$$dp\_all[l][j] + dp\_all[j + 1][r]$$$. Now suppose there is an option, where we can't split the segment into two pieces. Consider the last segment we removed. It is some subsequence of our $$$[l;r]$$$ segment. Elements of that subsequence split this segment into pieces. Each of these pieces is independent of each other. That means that if the first element of the subsequence is $$$w[j]$$$ then $$$[l; j-1]$$$ and $$$[j; r]$$$ are independent and we already updated the answer with the sum of $$$dp\_all$$$, and similarly with $$$r$$$. There is one case, though. When this subsequence starts at $$$w[l]$$$ and ends in $$$w[r]$$$. But that's what we have $$$dp\_mon$$$ for! Now for every element on $$$[l;r]$$$ we have to check if this subsequence is increasing from $$$w[l]$$$ to $$$w[j]$$$ and then decreasing from $$$w[j]$$$ to $$$w[r]$$$. That means that we add two $$$dp\_mon$$$ and after that remove this subsequence with a score of $$$v[len\_of\_subsequence]$$$. The length can be calculated from $$$|w[l] - w[j]|$$$ and $$$|w[j] - w[r]|$$$.
The last is $$$dp$$$. That's the easiest one. Either we remove everything — this is $$$dp\_all$$$, or there is some element which we decided not to remove. Then, as discussed in previous paragraph, it is enough to update $$$dp[l][r]$$$ by every $$$dp[l][j] + dp[j + 1][r]$$$.
And I know that probably some of $$$dp$$$ are useless, but I feel like it is easier to understand the solution with multiple $$$dp$$$ with different purposes.
#include <bits/stdc++.h>
using namespace std;
#define ll long long
const int inf = 1e9;
int main() {
ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL);
int n;
cin >> n;
vector<int> v(n);
for (int i = 0; i < n; ++i) {
cin >> v[i];
}
v.insert(v.begin(), 0);
for (int i = 1; i <= n; ++i) {
for (int j = 1; j < i; ++j) {
v[i] = max(v[i], v[j] + v[i - j]);
}
}
vector<int> w(n);
for (int i = 0; i < n; ++i) {
cin >> w[i];
}
auto getv = [&](int ln) {
if (ln < v.size()) return v[ln];
return -inf;
};
vector<vector<ll>> dp_all(n, vector<ll>(n, -inf));
vector<vector<ll>> dp_mon(n, vector<ll>(n, -inf));
vector<vector<ll>> dp(n, vector<ll>(n, 0));
for (int i = 0; i < n; ++i) {
dp_mon[i][i] = 0;
dp_all[i][i] = v[1];
if (i != 0)
dp_all[i][i - 1] = 0;
}
for (int k = 1; k <= n; ++k) {
for (int l = 0; l < n; ++l) {
int r = l + k - 1;
if (r >= n) break;
for (int j = l + 1; j <= r; ++j) {
dp_all[l][r] = max(dp_all[l][r], dp_all[l][j - 1] + dp_all[j][r]);
}
if (w[l] != w[r]) {
if (abs(w[l] - w[r]) == 1) {
dp_mon[l][r] = dp_all[l + 1][r - 1];
} else {
for (int j = l + 1; j < r; ++j) {
if (w[l] != w[j] && w[r] != w[j] && ((w[l] < w[j]) == (w[j] < w[r]))) {
dp_mon[l][r] = max(dp_mon[l][r], dp_mon[l][j] + dp_mon[j][r]);
}
}
}
}
for (int j = l; j <= r; ++j)
if (w[j] >= w[l] && w[j] >= w[r])
dp_all[l][r] = max(dp_all[l][r], dp_mon[l][j] + dp_mon[j][r] + getv(abs(w[l] - w[j]) + abs(w[j] - w[r]) + 1));
dp[l][r] = max(dp[l][r], dp_all[l][r]);
for (int j = l + 1; j <= r; ++j)
dp[l][r] = max(dp[l][r], dp[l][j - 1] + dp[j][r]);
}
}
cout << dp[0][n - 1] << '\n';
return 0;
}
This is my first editorial (and first blog too), so any suggestions, improvements, etc are welcome.






Thanks for your work!
How much rating would you give Div2C/Div1A Blocked Points?
I have no idea how to rate problems
According to this website, it is somewhere around 1300