


Hello!
Right now happens the first tour of the Open Olympiad in Informatics, and tomorrow will be the second one. This contest is prepared by Moscow Olympiad Scientific Committee that you may know by Moscow Team Olympiad, Moscow Olympiad for Young Students and Metropolises Olympiad (rounds 327, 342, 345, 376, 401, 433, 441, 466, 469, 507, 516, 541, 545, 567, 583, 594, 622, 626, 657, 680, 704).
Open Olympiad consists of the most interesting and hard problems that are proposed by a wide community of authors, so we decided to conduct a Codeforces regular round based on it, which will happen on Mar/13/2021 12:05 (Moscow time) and will be based on both days of the Olympiad. Each division will have 6 problems and 2 and a half hours to solve them.
We kindly ask all the community members that are going to participate in the competition to show sportsmanship by not trying to cheat in any manner, in particular, by trying to figure out problem statements from the onsite participants. If you end up knowing some of the problems of Moscow Open Olympiad (by participating in it, from some of the onsite contestants or in any other way), please do not participate in the round. We also ask onsite contestants to not discuss problems in public. Failure to comply with any of the rules above may result in a disqualification.
Problems of this competition were prepared by Akulyat, KiKoS, wrg0ababd, budalnik, blyat, alexX512 isaf27, ismagilov.code, DebNatkh, Siberian, NiceClock guided by cdkrot, vintage_Vlad_Makeev, GlebsHP, Zlobober, meshanya, ch_egor, grphil, voidmax, Endagorion and Helen Andreeva.
Thanks to adedalic and KAN for the round coordination, statement translation and preparation of problems for the second division, and also thanks for MikeMirzayanov for systems Codeforces and Polygon, which was used to prepare problems of this olympiad.
Also thanks to 4qqqq and Aleks5d for providing an additional problems that helped to create (I hope) a balanced problem set for the round, and Um_nik for testing!
Good luck everybody!
Due to the official competition source codes of other participants will not be available for an hour after the end of the round.
UPD1:
Please do not discuss problems publicly until 12:30 UTC.
The scoring distribution for both divisions is not standard:
- div1: 750 — 750 — 1500 — 2000 — 2500 — 3000
- div2: 500 — 1000 — 1750 — 1750 — 2500 — 3000
UPD2: Editorial
UPD3: Winners!
Div. 1:
Div. 2:







amazing fact:in the first few minutes after the announcement is published,the announcement‘s rating is negative(???
sorry to make the first comment meaningless
Nice redemption arc!
makes meaning now
Why it's getting a lot of downvotes? Currently it has -246!!
Task's are too hard for their positions + low TLs.
During the last contest, I performed really poorly, and I finally got a negative rating change. So I really hope I can do better this time.
I expect my rank<1000, to do this, maybe solving the first four problems are needed.
Hope everyone enjoy the fun of coding(and get a good result), stay Cheeki Breeki! >_<
sorry to make the second comment meaningless too:<
Don't worry about your rating! It really hurts the process of problem solving and having fun.
If you start to really care about it, in NO TIME you discover you are trying your best just to get that $$$+ \Delta$$$ instead of learning real CP, which is pretty toxic.
?
In my opinion, i suggest to virtual participation a contest so that you can enjoy the fun of problem solving and avoid $$$ - \Delta $$$
I don't think people so CP for fun only, rating is an integral part of it. It gives the thrill of winning and losing and having ranks. I love it.
Wish I can get perfect ranking and rating change.
Dude, is your profile picture from Yosuga no sora? If that's so, do you know this guy — nitesh.dtu?
Edit: I checked the picture, it really is Sora Kasugano. Man of culture!
Sorry, I don't know him/her.
Really liked this point, We kindly ask all the community members that are going to participate in the competition to show sportsmanship by not trying to cheat in any manner . I think we should have this in each contest.
Notice the unusual start time!
As a contestant, I want to become a tester :) Why to many down votes
What's the problem with my comment
No one knows!
That's the point what I like. As for sure, fair competition is very important for a round or the competition will be meaningless.
btw, the time of this round is very great for Chinese users. I will partcipate in it and try my best solving problems. Good luck to all of the participants! :)
Amazing starting time. I can finally get rid of my regular 'drink coffee and have a stomachache during contest' cycle. Yay!
Change my opinion-Pacific time zone sucks for almost all types of schedule, either contests are 1AM in the night, or they are 6:30AM in the morning.
From the past few weeks the unusual timing became usual to us.
But they have different timing each contest lol. Seems they are doing something inorder to accomodate americans who have contests at 6 in the morning.
Wow, Americans must be doing contests with a fresh mind.. Nice
Why are some contests held at different times than usual? I think the usual timing is right for everyone!
Sad American Noises from the corner
Because some contests are mirrors of Russian OIs, like Open Olympiade or Technocup which held some hours before CF round.
Happy Indian Noises Intensifies
The usual timing is right for someone, not everyone.
As we all know, the particpants of Codeforces Rounds are from many different countries and areas, so that they live in different time zones. For example, for Chinese, the Codeforces rounds are usually held at 22:35 (local time) or even later. That's why "Codeforces Round #706" was held 2.5 hours earlier than usual.
Olympiad rounds are challenging and fun!
There are 22 writers in this contest. Can't believe it!!
I can bet this won't be an easy codeforces round. Expecting Div-2 to be Div-1.5 by the length of contest.
Your last 2 contests had weak pretests. Hoping for strong pretests this time.
This means that we cannot discuss the problems here or anywhere for one hour after the end of the round?
where are the "as a tester" comments!
Matured testers
I guess it means the round is gonna be challenging. :)
Too many reds means too many problems to upsolve :v (to learn) !
After see the author list and contest length. I am scaring about my rating :v
You need not be scared about much rating loss. As a matter of fact, you can always use alt accounts to avoid penalties and consequently a major rating loss. :v
Here are 2 of many examples how it's done:
if u copy-paste the same code on different id's wouldn't that leads to plagiarism?
I am sorry. I do not do that again though i left that habit already sir .
this is literally strictly against the rules
Um_nik's comment has been deleted!
Probably for the best, it was not tasteful. I'm kinda surprised that I didn't get readonly for that. Looks like KAN tries to be a peacemaker)
With all due respect, sir, the comment was not good!
What was the comment about?
Hope for strong pretests lol
They were even stronger than vibranium lol (Atleast in Div2?)
Hello, What about score table ch_egor? (before showing score table) thank you very much I get my Ans Now!(now)
This is quite important I think, and I hope this will be added to all the announcements of the contests in the future.
I also hope that everyone will remember:
So please DO NOT discuss about the problems especially the solutions during the one hour after the contest is over. (It seemed that this happened last time.)
Hope for strong pretests, too!
Does this mean we will not be allowed to discuss the problems for an hour after the end of the round? (If so, I think it should be written somewhere because right now it is not very clear.)
They updated it now: Please do not discuss problems publicly until 12:30 UTC.
Scoring distribution shows us that this contest will be HardForces
hope this time i will get positive delta
Im outta here. Ratings go brrrrrrr
and this is why you don't improve
YEAH!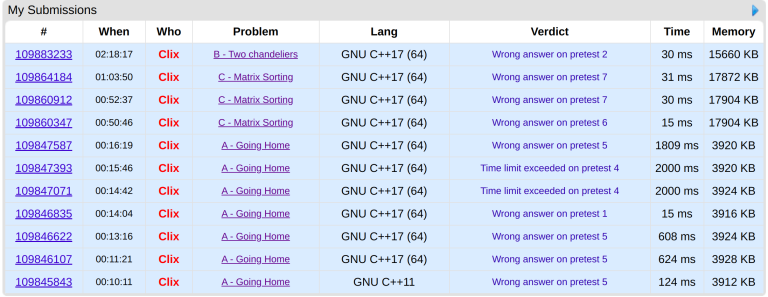
OMG....Feeling sorry for you
this is so much pain in a single photo :( xD
This is very sad, but enough of the honor to try until the end!
Salute your efforts!!!
Classic codeforces crowd. Sucking based on colours.
I liked the baiting in score distribution
Even those who couldn't solve A, solved C and most of them are green or newbie
Really! C is surely not that easy. Something is wrong here. But A was tougher than B. The test cases in A could have been explained more clearly. But that's part of the contest, I mean understanding the test cases.
Codeforces Round #707 (Div 1, Div 2)Codeforces Round #707 (Div 0.5, Div 1.5)
There is no way this could be Div 0.5.
But it's surely div 1.5 , atleast for me :(
Div 2A was just disgusting.
div1 A,B as well
+1 for IU picture! <3
tourist be like: " Div1 D? Let me just solve E and F instead..."
don't know why but i feel lot of fst in problem C
lol same
Was this yours?

I wanted to know whether it was accepted after reJudging or not, But when I entered on your submissions, I found that you had not reached Test 15 in the B problem in time of contest!
Did this solution get accepted after the reJudging?
100% have cheating in this contest.
Using 30 minutes for reading A 10 times, and I still don't understand its statement now.
Then how did you solve it?
Just guess
I honestly wouldn't be surprised if I got failed system test or something on A. I basically did the same. Just tried to guess what the author meant until the example tests worked.
B was easier to solve and code compared to A in DIV 2
A was too hard to understand. Looks like it was google translated :P
WTF, I think the correct contest duration is 2.5 days instead of 2.5 hours.
Very brainstorming and skillful contest.
Shouldn't Div2.D run for lcm(n, m);?? then I used a map for freq-> index
i got tle with this approach
deleted
,but how would it be correct if I used a lower number for simulation?
Why are you discussing.
I just noticed that.
I would delete it
how to delete this?
I don't know!!
Looks like the only way to do this is to ask Codeforces admins: KAN, geranazavr555 and MikeMirzayanov
Am I the only one who didn't notice that all $$$a_i$$$ and $$$b_i$$$ are distinct in Div1 B?
Even worse, the problem is solvable without that assumption, but my $$$O(n\ log\ ANS)$$$ implementation got TLE (thanks to the miserably tight constraints and time limits...). Spent the whole contest trying to optimise that code >_>
Same thing happened with me.It took me 1hr to notice that even author highlighted that.
I didn't notice at first too, and an hour was wasted:(
I didn't notice too. After noticing and making the constant better still TLE btw, so it also required squeezing.
Same here. It was an absolutely miserable experience.
I didn't realize it until I saw your words just now :(
Can you explain how it can be solved if elements weren't distinct? I used a different approach so couldn't grasp the idea in your code.
How to solve Question C?
I guess we can discuss the problems after 1hr from completion
Since a[i] <= 2.5 * 10^6 we can get atmost 5 * 10^6 different sum.
which is possible by any N >= sqrt(5 * 10^6 ) so we can take N as 10^4 and we can optimize to O(N^2) Solution
Me after reading the D2A problem. Petr on Bad Problems
Finally AC!!
It's so cool to keep trying to the end, But why did you spend 2 hours and 17 minutes on problem C? You could have solved problems A and B quickly
Solving problems A and B will not help me anyway. I want to improve. Each time after the contest I regret that I can solve one more during the contest, but could not solve due to nervousness and lack of time. So, from now, I am planning to solve difficult problems first during the contest time. Starting 2 problems are just based on reading the problem, understanding it and then typing it (without much thinking). If you look at my rating graph, I reach around 1700 and then fall down, that too from more than 6-7 months maybe. I usually solve div 2 A B C and after the contest I realise that I could even solve D if I had time (or even if I had sufficient time then I don't know why negative thoughts come into my mind that i could not solve it). So, I just want to gain confidence that I can solve difficult problems in the contest time as well, and when I will gain confidence then I will start from the problem A.
Inefficient strategy. If you end up solving D, still you would be late and you won't get enough points due to penalties. Then, you would have only time for A and B, still you would face huge penalty.
As i said that i just want to gain some confidence and remove the negative thoughts from my mind. Ratings don't matter to me much. It can be increased at any time if I am capable enough.
Again this where bad problem statements for Div2.
A is nothing else than a complected problem statement, and the whole thing about the problem is understanding the text. This is, honestly, the worst kind of problems we can get. This is even worse than asking for some googleable formular or the like.
B needs at least a bit fantasy for implementation, but still the main part is understanding what the statement wants to tell us.
C is nice statement, but implementation needs (at least for me) a lot of edge-case searching. So, this problem was again like 5 minutes thinking, then 2 hours asking "What did I get wrong here?". That is good for educational contest.
Maybe the other problems where super creative, but 90% of the partitipants did not even read them.
Edit: And of course, E, F where to hard. No Div2 solved any of them.
'That is good for educational contest.' No it's shit for any type of contest.
I think the contract for Educational contest is that boring implementation heavy problems are ok, because beginners need to learn implementation skills.
Timelimits in B, C and D are a joke. Don't know about E, but looks hard too.
Do you know what's the problem with GNU C++17 (64)? I noticed that you changed compiler to C++14 and got OK, and did the same, but there are some people who have OK with C++17.
But it was only in C. My guess (but I'm not an expert here) is that jumping over the memory is slower with 64bit compiler.
I'm pretty sure that (one of) the slowest part of the solution in all these three problems is reading input. scanf is very slow on GNU C++17 (64), while cin (with ios_base stuff) is fast. The opposite is true for MS C++ 2017 (scanf is fast, cin is slow).
You are right, on GNU C++14 both cin and scanf work 0.9 seconds, while on GNU C++17 scanf gets TL and cin works in 0.5 seconds. :(
You mean too low or too high? My solution for C ran in 1.2s and for B in 1.5s, I'd set both to 3s just to make sure but it's not that much different. D has plenty of reserve time, my solution runs in 1.7s.
To low. In B and C I had hard time, both take more than a half of a time limit while being more or less optimal. In D I also had no problem (it's a miracle btw, I had $$$O(n^2 \cdot q \cdot \log(q))$$$), but I see many people in the standings having some TLEs, while I guess their solutions also have correct complexity.
Yeah, that log seems excessive. I can't see solutions but I expect a lot of overcomplicated shit in B, C and D since I almost fell into the trap of trying to bash out an ugly code for a nice idea several times during this contest.
Does anyone else think that after a certain point in the contest, the submissions for C grew exponentially? When I see the standings, I can see more pupil, newbies and specialist having AC when compared to blue, which is very weird. Not trying to be ratist but I've never seen this kind of acceptance rate for a problem like C.
Only 4 people in my room managed to solve the problem. 3 of them are grays and blue was last to submit AC...
This is what happens when the problem is actually of nice easy observation. And I like it
some couldn't even solve A but somehow solved C
don't worry it's pretest are too weak
Probably solution is available in the internet . they just find out from net after that certain point of contest
what's wrong with expecting higher rated participants to be above lower rated participants in standings? Isn't that the whole point of 'rating'. 'ratism' is a stupid concept
I hope I wasn't the only to solve Div2C/Div1A with NTT. Thanks to AtCoder Library I passed pretests in 1.6s out of 2 second. In general, AC library turned out very useful for me this contest as D2D/D1B required CRT, which is implemented there as well.
i was getting runtime on 6
What does NTT stand for?
I meant DFT (discrete Fourier transform) modulo prime number. It's actually just fast polynomial multiplication; you can treat this algorithm as a black box in many cases. I believe NTT stands for Number Theoretic Transform, but that's a coloquial term. Below is the link describing formally what it does exactly
https://github.com/atcoder/ac-library/blob/master/document_en/convolution.md
can you please explain me how to apply NTT to such problems or tell me some resources from where i can learn application of NTT(appart from cp algorithm).
I'm afraid I don't have a better source. You should learn about polynomials in general and the application of polynomial multiplication in combinatorics. You can use any Math textbook of your choice. In fact, this very NTT application that I used (with a minor modification) is described on cp-algorithms https://cp-algorithms.com/algebra/fft.html#toc-tgt-9
weak pretests on 1A/2C.
Is there a O(n) or O(nlogn) solution for C ?
I solved using FFT in O(M*log(M)) time complexity. M = 2*2.5*1e6
My solution was to solve for $$$n <= 2e4$$$ with an $$$O(n ^ 2 log n)$$$ algorithm
And for $$$n > 2e4$$$ there will be $$$2$$$ positions with equal adjacent differences after sorting($$$ i, i + 1$$$ and $$$j, j + 1$$$, $$$i < j$$$) and those can be the four indices.
Idk it might FST.
i set n as 1600 rip
AC :)
hi5
If you are talking about Div2 C then you just need to notice that the possible sums are just 2*M (M is the max a[i], that is to say 2.5*1e6) so you can just iterate over all pairs and you get a solution in O(min(n^2, m))
cheatforces!
My reaction while reading prolem 2A was similar to https://www.youtube.com/watch?v=KNviwfDeRKg
Solved Div 1A using FFT, missed a silly observation.. how stupid I am.. :/
How to solve it normally? I tried randomized approaches but none worked
We know that sum of two elements is <= 2*2.5*1e6. So, iterate using two for nested loops, and do,
complexity is min(n^2,2*2.5*1e6)
But for iterating over the entire arr it would be n^2. Can you explain to me how it will be a minimum of n^2 and 5*1e6 and not maximum?
You stop when some sum is created twice. There are at most $$$5e6$$$ possible sums, so you do at most that much work.
This might not work. e.g
1 3 1 4notice index(1, 2)and(2,3)have same sum but they are not unique. I used map to remove this which resulted in TLE, i was too lazy to implement without map.FST
I use $$$O(n^2\log n)$$$ brute-force for $$$n \leq 3000$$$, and for $$$n \geq 3000$$$, run 1.9s random check. If can't find the answer then print NO. I don't think it can survive in system test
There is definitely an answer among the first 3163 elements no matter what, so you can do O(n^2), ignoring most of the input
Why 3163? Can you elaborate this please?
Yes, it's because (3163 choose 2) > 5 million
We have to find $$$x$$$, $$$y$$$, $$$z$$$, and $$$w$$$ such that $$$a_{x} - a_{z} = a_{y} - a_{w}$$$. Let's create set of integers and iterate through all pairs $$$<i, j>$$$ in $$$[1,n]$$$, check, if the number $$$a_{i} - a_{j}$$$ is in set, if yes, print answer, otherwise insert $$$a_{i} - a_{j}$$$ into set. Due to Dirichlet principle, the number will be found in no more than $$$C = 2.5 \cdot 10^{6}$$$ iterations. Also it means, that if $$$n \ge \sqrt{C}$$$, answer is YES.
Also remember, that we can bring one pair of iterators $$$x, y, z, w$$$ equal. Look at cycles in my submition, it can happen there no more than one time, so the total number of iterations is $$$\le 2C$$$.
Can you give some content about the Dirichlet principle you're talking about? (Preferably YouTube)
Can you elaborate on the Dirichlet Principle that you are using here? Why the next pair be found within
C = 2.5 * 10**6iterations?Dirichlet principle is quite obvious statement: if there are $$$n$$$ holes and we put $$$n+1$$$ balls there, there has to be a hole with $$$2$$$ or more balls.
I used to know it as pigeon hole principle
Anyone noticed the weird constraint for the elements in Div2C?
Why so much down votes in this comment? Did I say someting wrong?
And some interesting fact: you can pass Div2 C's pretest by just simple rand().
What is the idea?
link
And it can pass system test. I got fst because I made a very very stupid mistake in brute-force part :(
Thanks the organizers for this contest although I may suffer from a minus delta. At least it has given me the chance for a successful hack, which did not happen since June 2020 :-)
How to slove TLE in problem 2 in div 2?
Use difference array
Can we discuss? I am getting runtime error then WA on pretest 2.. Shall I share my submission?
message me
Will the system testing be done right now or an hour later?
Please do not discuss problems publicly until 12:30 UTC.
I think div1a should be easier or we should have open-then-rated system.I am pretty sure atleast a 200 people didn't submit anything because they couldn't solve anything in div1.
In today's contest something was weird ,In standing I saw many who has solve d2C but made wrong on d2A/d2B.....
And C was not that easy!? Or Do I missed any trick???
Yeah As I guessed Same question was available on gfg link
There is a simple observation that makes it easy -- if you see it, you can get AC quickly
No, this is an implementation problem, too. And there are edge cases with duplicate numbers... I had the right idea after some minutes, still needed 8 WA and more than an hour to get it right.
I initially thought that the edge cases mattered, but it seems that a "naively" written solution still passes.
No matter what, there is always going to be a solution among the first 3163 elements, regardless of the presence of duplicates.
Check this out: https://codeforces.com/contest/1500/submission/109893462 (no edge cases)
can you explain, why the answer would be found in first 3136 elements?
As : what would happen when the answer is no and tc consists of constraints limits in that case it would be n^2 which is around 4*10^10 iterations . [UPD : understood]
This is much simpler and intuitive, thanks for sharing!
it took me more than an hour to see this easy observation. also solving C and not able to solve A or B looks a bit fishy tbh.
I think what happened is that many people who submitted C didn't make the observation. A naively written solution could still pass.
So, check out this submission here: 109894474 I cleared the map each time to simulate a solution that uses a map to a single pair. I even commented out the line that reduces n to 3163, to demonstrate that it is possible to get AC without actually making any sort of observation (recall, many people who are just starting out would still implement an O(n^2) algorithm when n >= 10^5 if they didn't know a better one)
I guess this explains it (I guess the test cases are weak as well)
Yes, I agree with this. Some people just implemented the n^2 algorithm without knowing why it worked.
Cause C was available on gfg while a nd b not
And dumb me didn't implemented it thinking that it would give me TLE.
Problem C — Uneven TCs? For some reasons, there are weak Test Cases. Testcases only contain N<1000 which is easily acceptable in N^2. Moreover, in a few test cases N=200000 but in those TCs the N^2 approach is getting completed in N. This is somewhat unfair for those who don't submit the solution because of N^2 TLE reason. There may be other proofs that will prove that N^2 will never give TLE but thinking a general way, it won't.
actually, it can be proven that if you have an array of size greater than let's say 1000 then you'll always find an answer (hint a[i] is of 10^6 order). that's why the n^2 solution worked as it'll find the answer in some starting 1000 elements of the array itself. hence it was the intended solution. I hope it clears everything.
Yes, but how to prove it?
You've a[i] of order 10^6 means 10^6 — 1 unique differences available lets say this equals t. Also, in an array of size n, we have nC2 ways of choosing 2 elements and hence nC2 differences available. If nC2 > t then by PHP, there'll be atleast one difference occuring more than once. Which limits n to some order of 10^3.
In D1B, I wrote
int posa[500005],posb[500005]and used $$$posa[a_i],posb[b_i]$$$. However $$$a_i,b_i$$$ might be $$$10^6$$$! Despite this fact, this program with too small array bounds passed pretests. I really wonder how strong pretests are.I'm afraid of system testing
Can somebody give me a hint on how to approach DIV-2 problem-C. I am totally clueless about how we can do it in less than O(n^2)
The sum of the two numbers must be less than 5e6, and you can find the answer at most 5e6 times.
You don't have to implement it less than that. O(n^2) solution will pass the test cases. Don't know the reason though.
The initial problem scores seems too small for me.:(QAQ
I solved 2 problems but my score is smaller than some people with 1 problem.
Let's admire the great score setter.
BTW, if the number of my incorrect submissions * 50 > the score according to the accepted time will I get less perf?
:(
You get at least 30% of initial score
I didn't like div2A, spent 15+ mins trying to understand the statement
The same.
I spent 13 mins on A, but only 11 mins on B.
Nice random scores on ACD.
D: easiest — in the same way as with 2D prefix sums, for each top left corner $$$(r,c)$$$ you just list "colour, smallest square for which we first see it" for the first $$$Q+1$$$ such colours; this list is created by merging the lists for squares with top left corners $$$(r+1,c)$$$, $$$(r,c+1)$$$, $$$(r+1,c+1)$$$ in linear time and that directly gives us the answers
B: alright, not trivial, not too hard, obvious binsearch and some number theory behind
A: Not The First Problem In The Contest Please! I solved it mainly by noting that if there are many different values (around $$$\sqrt{\max A_i}$$$), the answer always exists and we can ignore all except those few values to find it. Otherwise, there are some special cases — if there are 2 values that occur at least twice or one that occurs at least 4 times, the answer is obvious; if all values used in the sums are different, bruteforce works; and finally, there's the case $$$a+a=b+c$$$. It could be a 500-750pt A if it was just a yes/no problem and all values were guaranteed to be different, but this way, there are just way too many details to consider. Harder than B or D.
C: Nice problem, requires not getting bogged down in implementation even if you know the gist of what you want to check. The matrix A is almost irrelevant — we're splitting $$$B$$$ into chunks of rows. If there's an axis $$$a$$$ such that each chunk is increasing along that axis, and there's a chunk that contains at least 2 different values on that axis, we can "unsort" by $$$a$$$, splitting this chunk between rows that have different values on axis $$$a$$$. If we consider sorting instead of unsorting, in reverse order, we find that as long as the rows in each chunk are originally in the same order, we'll end up with $$$B$$$. Vice versa, any other unsorting means we'll never obtain $$$B$$$ since something would be sorted in a way we don't want. When there's no more splitting possible, we hash the rows and check if we can build $$$A$$$ by merging the chunks of rows we have at the end without changing the order in each chunk.
In implementation, it's essential to notice that the conditions "is increasing along axis" and "has at least 2 different values on axis" don't need to be checked for chunks, only for adjacent rows. We discard pairs of adjacent rows that are already in different chunks, and for each axis, we remember how many remaining pairs are strictly decreasing and which ones are strictly increasing. When splitting between two rows, we only update these conditions for this pair of adjacent rows and each axis, and this way, we only check each pair of vertically adjacent values once, leading to $$$O(NM \log)$$$ complexity.
There's also the question: can two identical rows end up in different chunks? If that happens, then there must be a split along some axis that had values $$$a, \ldots, b, c, \ldots, a$$$ in one chunk in $$$B$$$, where at least one of $$$b,c$$$ is different from $$$a$$$ and the split happens between rows with $$$b$$$ and $$$c$$$. However, the first time this happens, this chunk can't be increasing — the value among $$$b,c$$$ that's different from $$$a$$$ is either larger than the next $$$a$$$ or smaller than the previous $$$a$$$. That means the answer is no, all rows with the same value must be in the same chunk, and that greatly simplifies the final check with hashing — if we're adding a given row to the end of partially built matrix $$$A$$$, we know which chunk we must take it from.
I believe there's no real need for special cases, just take a looser bound — the special cases get accounted for fast.
If so, that's a different thing you need to pay attention to. The difficulty of a problem shouldn't be assessed by "I'll guess that with a loose bound, this is all I need", but how hard it is to figure out why a given solution works.
Maybe? The thing is, if $$$N$$$ is much higher than $$$\sqrt{max A_i}$$$ and there are still less than $$$\sqrt{max A_i}$$$ distinct values, surely there are two pairs of equal elements.
My Div1C passed pretests even I typed n instead of m somewhere. It was so scary.
It somehow passed systests(and hacked by myself).
Dont we all agree that most of the C accepted submissions were from GeeksForGeeks!
Div2 C? Could you please provide the link? Got it: https://www.geeksforgeeks.org/find-four-elements-a-b-c-and-d-in-an-array-such-that-ab-cd/
Div1C can be solved with "bitset" in O(N^3/w)
I also used bitsets, but it only passed after I put in this pragma from Chilli: https://codeforces.com/blog/entry/77480. The runtime was 1996 ms, which was really scary. Thanks Chilli!
You are very lucky :)
bruh
Apparently bitset isn't needed. My O(n^3) passed without bitset.
Orz
Great problems, thanks!
+1
Problems C & D were very nice.
Good contest with strong pretests, especially in problem B and problem C.
What's more, the tl of problem B and the ml of problem D are very friendly. No one can get TLE or MLE on them.
Can somebody explain me in short how to solve DIV2 problem-C. I was very clueless about how to solve it in less than O(n^2)
Think of brute force, and show that it'll work using the pigeonhole principle
Brute force would be to calculate sum of all pairs. Which itself is n^2.
n^2 is enough to pass time limits
my submission https://codeforces.com/contest/1501/submission/109856495
It is min(n^2,10^6). That's why, It pass time limits.
what would happen when the answer is no and tc consists of constraints limits in that case it would be n^2 which is around 4*10^10 iterations . [UPD : understood]
Pair sum can be from 2 to 5*10^6. Let's assume you are doing 10^7th iteration so there will be at least one pair sum which have more than 1 frequency and have distinct indexs.So, Answer will be always Yes for large N values.
I don't get it, for me n<=10^5 tells me that n^2 solutions don't work..I thought an hour of how to get a lower complexity
I even looked up in cp4 handbook, and they say only if n < 10^4 you can use n^2, so I was certain it won't work...
TLE: https://codeforces.com/contest/1500/submission/109883422 AC: https://codeforces.com/contest/1500/submission/109892108
I resubmitted my TLE code during the contest and got an AC. Can anyone explain why? Can we rejudge? Sorry to disturb you.
You have used in 2nd submission gnu c++ 17 instead gnu c++ 17(64).
Sorry, I don't know the difference.
Same for me...
Contest TLE: https://codeforces.com/contest/1500/submission/109868976 Resubmitting AC: https://codeforces.com/contest/1500/submission/109893896
My code with scanf can't pass div1 C, but it only takes 102ms after switching to fread. How could such thing happen on codeforces?
Its called Miracle dood:)
scanf becomes much slower, if stdio.h is not included as first header working with streams, which is your case.
Iss contest mei kuch bhi ho raha hai yaar (Miracle)
MikeMirzayanov Please look into it as just by changing C++17(64) to C++17 can get you AC.
Hi, I had a query regarding my submission of the Div2(C) Going Home question. I had submitted two submissions for that question. My first submission got skipped and the second submission got accepted .The second was optimized solution as compared to first solution. But the first solution would have worked also because I had submitted the first submission again after the contest was over and got accepted. If my first solution was checked then I would have got much better rank. I would like to know more about why this happened?
I am sorry to hear that. But it is because of the rule of Codeforces. Only your last submission to a problem will be considered as your valid submission. And if it gets AC, all your previous submissions will cost 50 points.
If you want to know why it is designed in this way, let me explain in a deeper way.
There are typically two types of competitive programming contests. One is judging real-time and the other is judging after contest ends. In a real-time judging contest, participants can try many times for a problem until they get AC.
But in the other type of contests, participants must specify one submission as they final submission for each problem. Just like taking exams, you can not submit many answers to the teacher and say "Hey, please check all my answers. If one gets passed, then I get credit."
Because Codeforces enables real-time testing, you may think Codeforces is the first type contests. However, in my opinion, Codeforces rounds are much more like the second type. Because it just does pretests during contests. Nobody knows the system test result until contest ends.
So, in the next Codeforces round, please remember not to resubmit if you think you have given a correct answer.
It got TLE in contest DIV1 B https://codeforces.com/contest/1500/submission/109868976, but resubmitted got AC: https://codeforces.com/contest/1500/submission/109893896
Is this supposed to happens?
Can you please explain why this solution for div2 A is giving wrong answer https://codeforces.com/contest/1501/submission/109849523
Don' use b[i] — a[i]+ 1. It will fail if b[i] — a[i] is even. It should be ceil((b[i]-a[i])/2.0).
(b[i] — a[i] + 1) / 2 is perfectly fine for ceiling...
Me too.
Can somebody explain me why O(n^2) is accepted for n<=200000 in DIV-1A (DIV-2C)?
You will find a solution before than all operations.
Worst case there are 2.5⋅106 + 2.5⋅106 possible values(a+b)
I suppose you are looking at a brute force solution. If you already cleared out the a+a=a+a and a+b=a+b case, then there is at most one value appearing more than 1 time, and it does not appear more than three times, let's call it v. Later you will discover that this is not important, but let's first assume that v appears only one time. Then, since a[i]<=2.5e6, so the sum of two elements <= 5e6, so if there are >5e6 pairs, at least one will collide. That's why the brute force solution always exits and will pass.
does that mean if n > sqrt(5e6), the answer is true anyway?
yes
you can use the pigeon hole principle to understand why a solution always exists for n > sqrt(5e6), and this is the reason Bruteforce works here
AC:https://codeforces.com/contest/1500/submission/109898116 TLE:https://codeforces.com/contest/1500/submission/109870735 It's the same Code. I submit it after the contest several times and all get accepted but got TLE during the contest...
My clean 30 Line code to DIv2 C. only based on pigeonhole principle. 109899822
My $$$O(n^2logn)$$$ solution using hash table don't know it but passed ^_^
Problem C — Uneven TCs? For some reasons, there are weak Test Cases. Testcases only contain N<1000 which is easily acceptable in N^2. Moreover, in a few test cases N=200000 but in those TCs the N^2 approach is getting completed in N. This is somewhat unfair for those who don't submit the solution because of N^2 TLE reason. There may be other proofs that will prove that N^2 will never give TLE but thinking a general way, it won't.
NO Man tcs have 200000 values at max. see test cases in my submission.
int128 -> long long
TLE -> AC
https://codeforces.live/contest/1501/submission/109879852
https://codeforces.live/contest/1501/submission/109903321
??? I can't understand
int128 is emulated by software while int64_t(by which long long is usually represented) is supported natively by hardware, so it is only natural that int64_t is faster in general
Also your solution passed by such a narrow margin that it can be explained by just fluctuations.
This is because there are total n*(n-1)/2 pairs of two numbers possible. So there can be maximum n*(n-1)/2 different sums possible.
And from the constraint a[i]<=2.5*10^6. So, maximum possible sum will be 5*10^6.
That's why when n*(n-1)/2 is greater than 5*10^6, then answer always exists. So, when n>4000, the there always exist a answer. Hence not getting TLE.
:)
Look at this submission :
https://codeforces.com/contest/1501/submission/109911010
If you place 762 instead of 763 you will get WA on test 5. Can someone explain why this solution works for 763? I think someone can easily hack if they try. Tests were very weak!!
Your solution 109863008 for the problem 1501C significantly coincides with solutions shaw_off/109861748, rUnTiMe_TeRRORrr/109863008. Such a coincidence is a clear rules violation. Note that unintentional leakage is also a violation. For example, do not use ideone.com with the default settings (public access to your code). If you have conclusive evidence that a coincidence has occurred due to the use of a common source published before the competition, write a comment to post about the round with all the details. More information can be found at http://codeforces.com/blog/entry/8790. Such violation of the rules may be the reason for blocking your account or other penalties. In case of repeated violations, your account may be blocked. Here is the code that was published before this Competition as it was published before this competiton Contest -707 Div 2 Problem C **link to the contest -[](https://codeforces.com/contest/1501)** link — code avaialble on net link to my submission — [](https://codeforces.com/contest/1501/submission/109863008) please look MikeMirzayanov
I reverted all punishments if for a user the only matched code is in problem 1501C.
but i think this contest should be unrated because many participants had the same submission on problem Div2c. Many newbie and pupil only solve only C. If the round is still rated , it is unfair to another participant who did with self-ability.
And Div2c is available on internet
This must be a joke.
The whole problem, was to figure out that the brute force works. Now somebody provides a brute force solution, which works for distinct numbers — it was obvious that tons of them are available and you cancel all punishments based on that...
109903632 109904857
I want to know why making the one which uses vector get Memory limit exceeded!
I think it is totally unnessary!
Not justifying the constraints of the problem or anything, but this is just one pitfall of
std::vector. I agree that the problem didn't have a good memory limit anyway.Note that we say
std::vectortakes amortized $$$O(n)$$$ space. More precisely, when there are $$$n > 0$$$ elements, its internal capacity becomes $$$2^{\lceil \log_2 n \rceil}$$$, which in the worst case can be as large as $$$2n - 2$$$. This might have given the MLE verdict.Problem 2C is pretty standard problem available on all coding tutorial websites including GFG.https://www.geeksforgeeks.org/find-four-elements-a-b-c-and-d-in-an-array-such-that-ab-cd/
@MikeMirzayanov
so it will be the evidence to say this contest was unfair.
? Their sol is n^2 *logn
Codeforces is now filled with idiots. Whenever they perform bad on contests, they blame the problem statements and writers
agree but in this contest it did't balance to all participants because of the cheating on Div2C.
what type of cheating? on telegrams?
Tbh, it isn't cheating. According to codeforces rules, you can use any publicly available 3rd party code written before the contest. I guess they were just lucky
Completly correct!!
I don't really think we should downvote this contest so heavily. It's true that many parts of the contest can be improved, but such downvoting is a disrespect to the authors and their contribution to the community.
I do agree . They have done a lot of hardwork and downvoting so harshly is not fair .
Even this contest wasn't bad.A,B were same as other rounds have.C have observation.And D was obvious binary search with some implementation.I don't know what people expect from cf.What people do is:if they performed bad,blame on authors.In todays contest atleast till Div2d didn't require any advance knowledge neither any advance math.
Did you see the rest of div1 problems? I'm not sure that 2600 rating is normal for div1C. Or 2900 for div1D. Maybe I don't understand something, but these problems should be a bit easier.
In fact, there were 2 more problems on the contest, that were as hard as div1F. IMO, the authors of the contest just overestimated the skill of the participants.
Div2B can actually be directly simulated (of course compressing the sequences, e.g., 1 1 1 1 1 1 -> (6,1)). Since with compression on each iteration we insert only one element, no matter how many we have removed, and we remove only once, it is linear in N.
when will the ratings get updated based on this contest ?
Not submitted DIV 2.C O(n^2) solution with the fear of getting TLE. Could not find during the contest that sum cannot exceed 5*10^6.
hard contest
Seriously
can anyone help me here why n^2 solution is passing?
What about the differences:
Note that for the differences we can switch the sign, so we can use the absolute value.
Thats exactly the same problem. Just move w to the right and y to the left and you get x+y = z+w
Yes, but the result of the subtraction is max half the size of the result of the addition. So the loop runs only half the time.
"So half way through the O(n2) you definitely find the answer and you can terminate there so the O(n2) solution will need to run at most 5×106+1 iteration to find the answer."
But what if we don't find an answer, then the loop will run O(n^2) times (right?), would that not be TLE?
There is some possibility that we won't find answers for cases where n^2 < 2.5*10^6 but for cases of n^2 > 2.5*10^6 (we may need few more numbers because of some collisions in the chosen indices) we are bound to find an answer. I hope this clears your doubt :)
It is guaranteed to have an answer when is $$$n$$$ is roughly $$$\ge 4000$$$ (Pigeon Hole Principle)
Let me demonstrate that:
We only have $$$7$$$ days a week sat through Fri.
If I ask you to name the names of 8 days, at some point it is guaranteed to name some day twice or more.
With that, let us go back to the problem, we only have $$$2$$$ through $$$5 \times 10^6$$$ possible pair sums (Holes), Now when you run your nested loop you are going to generate sums more than the number of holes that you have, and so you are gonna have pairs with repeating sums.
Is this round rated?
Ratings are already published for Div1 users.
In Div2 C, I used an intuitive approach to solve that worked. Basically, I iterated over differences (ax — az) from 0 to k*C/N, where C = 2.5*10^6, N is the input size, and k is some constant (say 2) and then I checked whether four such indices exist or not. My question is how to prove that only checking first k*C/N differences works? Also, what is the tight lower bound for such k?
https://codeforces.com/contest/1501/submission/109905290
When will the rating be updated, if you don't mind me asking?
Is the round unrated now ?? I can't see any rating changes in my profile or any one else
Thank you in advance
Was this contest rated
If anyone noticed,contest final standings had been continuously changing yesterday in a span of every 2 hours albeit by a small margin of 2-3 yet ratings hadn't been updated and no info about contest being unrated had been published by the contest setters.
As a contestant, I think that if you want to hold a contest on CF, you should provide the best problems and sincerity to contestants. A good round should have novel ideas, strong data, and amazing solutions, instead of old problems, cumbersome details, and bad pretests. As we all know, contestants would be sad if they solved a problem but got failed on system test instead of accepted because of small detail. Isn't it? :)
niu bi a ni
was this round unrated ??
Why is this round unrated
wait for the announcement
Hope this round will not unrated.
,
Why my code is getting TLE? https://codeforces.com/contest/1501/submission/109937856
TL I made a small modification to your code, it passes #73, but it failed #74. Now replacing unordered map with array passes the limit, AC. Second code is runner up's C code. What is the reason for this?
I was thinking that it was getting TLE because my map was getting updated each time and for that it needs more iteraton but after seeing your modification I have realised that my thought was wrong. But I have seen many contestants did it in similar way but got no TLE. Didn't find any dissisimilarity. If anybody knows the reason behind this TLE please tell me.
Do you mean, similar unordered-map type solutions passed?
Yes. I have lost the code but I have found no dissimilarity between these two. Maybe there are very few dissimilarity. But didn't get it.
I think why your code gives TLE(not sure) is the code just stores one instance of a pair, but in the editorial, it mentioned we have to store all four instances of pairs and if we get to such a position we can break, by printing appropriate indices, but the code is not intended to do that, that is the reason for TLE(the test case 73 and 74 are specially made for this purpose like it has first 535 elements which have unique sum for each i belonging to N) so basically we get to near $$$1.07*10^8$$$ operations. But, it is evident that vector passes, I suspect that it is due to cache friendliness nature of vector(not sure). Like, I may quote one instance, in the last topcoder SRM 801, div 2 hard question, map solution was supposed to pass with the given complexity, but it didn't whereas it vector counterpart passed(although it is faster by a $$$logn$$$ factor), Click I am not able to come up with any other reason for this behaviour. Please correct me if I am wrong.
Why the div2 of the contest is unrated? Or the rating changes haven't been figured out yet?
This round should be unrated...I found a guy who just copy pasted from geeksforgeeks and did a little bit modification and got AC ...he didn't even try to write his own code...you can see in his submission....function name and code ,even comment is exactly same as geeksforgeeks...
https://codeforces.com/problemset/submission/1501/109870879
https://www.geeksforgeeks.org/find-four-elements-a-b-c-and-d-in-an-array-such-that-ab-cd/
I found just one guy and don't know how many have done the same thing ...
And I also know all cheaters have down voted me...they want to make this comment hidden..
You are being downvoted because your comment is useless as everyone knows that problem setters gave this question by miatake whose sol is already available and everyone knows and even Mike has accepted amd this is not the 1st time that this happened on codeforces so just stop thi nuissance and focus on your practice.
When everyone knows and even mike accepted this..then this round must be unrated...let's wait what happens.
I said this is not 1st time this happened. Just because of 1 question it would be very unfair to declare this round as unrated. Also div1 ratings have been updated so round is rated. Stop crying like a child just because you didn't know that solution is available on net. If you would have known then you also would have done the samething
as we all knows many people have cheated in this round and many not...I am just asking..is it fair to give +ve delta to a cheater and negative delta to those who didn't cheat.Make this round rated...I have no problem but before that remove all these cheaters
unrating the round is unfair to those people who fairly submitted solutions and ended up receiving positive delta.
Consider everyone's pov not just cheaters and those who are getting -ve.
:)
I think it’s not a big mistake that there is a duplicate problem of Div2 C
The question was not at all difficult. What made it tricky was that most of us didn't know that this question would get accepted even in n2logn time.
U are wrong.They have added TC #73 to reject n2logn submissions.P.S. try submitting ur solution again
there have not any rule that " you can not copy solution from internet.". so its not illegal bro. actually its the author mistake. :( i also affected like you sir.
Hope it will be rated :)
Why the ratings of Div2 doesn't change ?
hey MikeMirzayanov sir , can u pls tell when will rating updated for contest-707 div2 its upto 18 hour from contest ends
guys upvote comment
I think they did not update ratings because, now for div2-C O(n^2logn) solutions are not working and giving tle on 73th testcase which were accepted before.
So what is the correct approach now which will pass all the test cases?
UPD:- So it seems n^2 solutions are working fine which means all the solutions copied from gfg will fail if systests happen again.
But #73 was submitted at 2021-03-14 07:36:49,this cannot be the reason why the rating of div2 has not been updated with div1.
Man O((n^2logn) are giving tle.My solution was min(n^2,5*1e6) is still passing all tests.P.s. ur solution is O(n^2logn)
Got it, O(n^2) works and it is correct.
my brute force algo is working fine for C.Its also n^2
This is entirely my fault — it's even bolded! — but did anyone else miss the key condition "elements are distinct" for D2D/D1B? I only realised just now when reading a code that was identical to my own solution...
Ratings have been updated now.
Thank you !
congratulation to all cheater who copied code from the internet and get high rating change. congratulation congratulation !!!
hahaha cheaters downvote me :)) you are trash and your skill never become better hahaha
It is clearly stated all material published before contest is valid
Many codes of Div 2 C which passed during the system tests are now giving TLE on test case 73 and 74, and still, they have got points. So isn't this unfair with the people who didn't submit that knowing that it will give TLE?
Eg: Submission C
.
I participated in Div.1 and I'm upsolving the Div.2 easy problems.
WTF is this shitty Div.2 A????
Can someone please help me understand why O(n square) logic works for the Div2 C problem? The limits for n are (10 to power 5) so it should ideally give TLE for a N square logic according to me
problem link: https://codeforces.com/contest/1501/problem/C
Solution link: https://codeforces.com/contest/1501/submission/110046641
Thanks in advance
$$$1 <= a_i <= 2.5*10^6$$$
This means there are at most $$$5*10^6$$$ possible sums.
So, if $$$n > sqrt( 5*10^6 )$$$ there is always a solution.
Stop when some sum is created twice.
Complexity $$$O(min(n^2,5*10^6))$$$
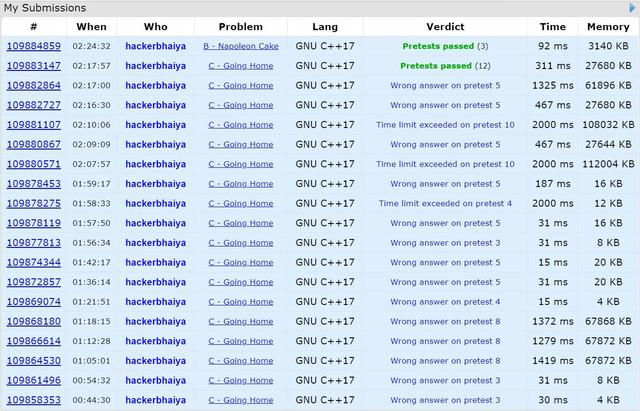
My Submission
Can somebody please tell me why my code:110064321 TLEs in Div.2D and any possible optimization I can do? Thanks.
The constraints are wrong on 1B. Says colors are greater than or equal to 1, but in the tests they can in fact be 0. Had fun debugging that -_-...