


Hello, codeforces.
I think this technique is important, and easy to code, although I haven't found much about it, so I've decided to make a blog explaining it.This technique allows to compare substrings lexicographically in $$$O (1)$$$ with a preprocessing in $$$O (NlogN)$$$.
As this is my first post on codeforces, please let me know if there are any mistakes.
Prerequisites:
- Basic strings knowledge.
- Sparse Table(Optional).
What is a Dictionary of Basic Factors?
As in the sparse table we will have a matrix of size $$$N\log{N}$$$ called $$$DFB$$$, where $$$DFB[i][j]$$$ tells us the position of the string $$$S[i ... i + 2^j-1]$$$ (the first time it appears) among all the strings of size $$$2^j$$$ ordered lexicographically.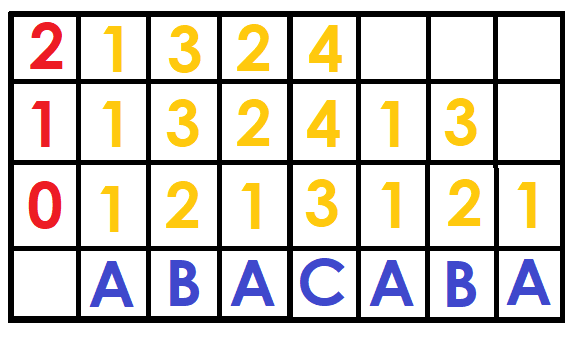
So, how do we build the matrix? Let's start with the lowest level, for powers of size $$$2^0$$$, we simply put the position of the character $$$S[i]$$$ in the dictionary (1 for 'A', 2 for 'B' ... and so on).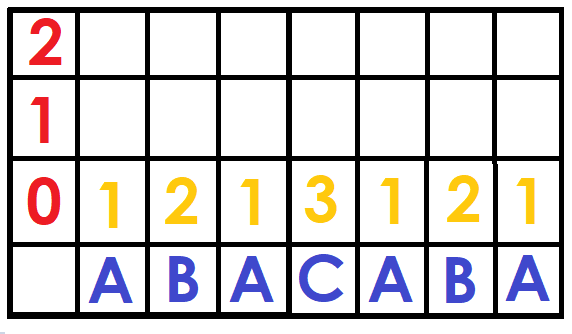
For the following $$$ DFB[i][j] $$$ we can save a pair of numbers that are $$$(DFB[i][j-1], DFB[i+2^{j-1}][j-1]) $$$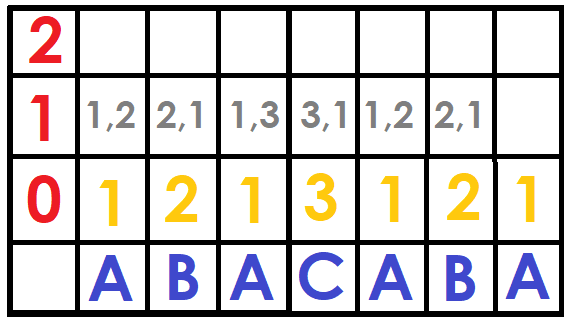
Now we replace the pairs by their position (the first time the pair appears) on the ordered array of those pairs. This can be done with Radix Sort in $$$O(N)$$$, otherwise with a normal sort in $$$O(NlogN)$$$ (But this will slow down the algorithm).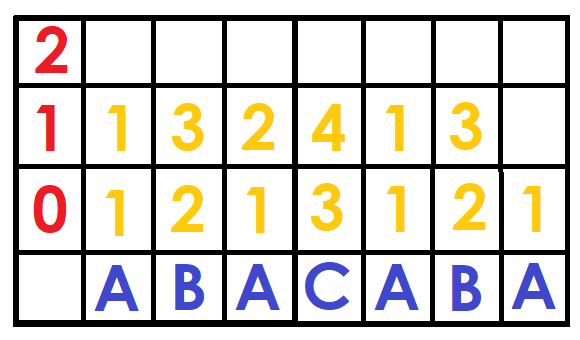
We do that for all powers of two and we will have the complete matrix.
Handling queries:
Suppose we want to make a query that is "Say which of the two substrings $$$S[l_{1}...r_{1}]$$$ and $$$S[l_{2}...r_{2}]$$$ is smaller lexicographically?".
First of all, let's analyze that if the substrings have different sizes, we can compare only the prefixes of size $$$M$$$ where $$$M$$$ is the minimum size between the two substrings, if both prefixes are equal then the smallest lexicographically is the substring of smaller size.
As in the Sparse Table, suppose $$$ k = \ log {(r-l)} $$$, then we can represent the substring $$$ S [l ... r] $$$ as the pair $$$ ( DBF [l] [k], DFB [r-2^k+1] [k] ) $$$. Now to compare two substrings of equal size we simply lexicographically compare their pairs in $$$O(1)$$$.
For example, suppose we have the string "ABACABA" and we want to know which string is lexicographically smaller between $$$ S [0 ... 5] $$$ and $$$ S [1 ... 6] $$$ ("ABACAB" and "BACABA").Since $$$\log{(5-0)}=2$$$, the pairs to compare would be: $$$(DBF [0] [2], DBF [2] [2])$$$ and $$$(DBF [1] [2], DBF [3] [2])$$$, which would be $$$(1,2)$$$ and $$$(2,4)$$$ therefore the first substring is lexicographically smaller. 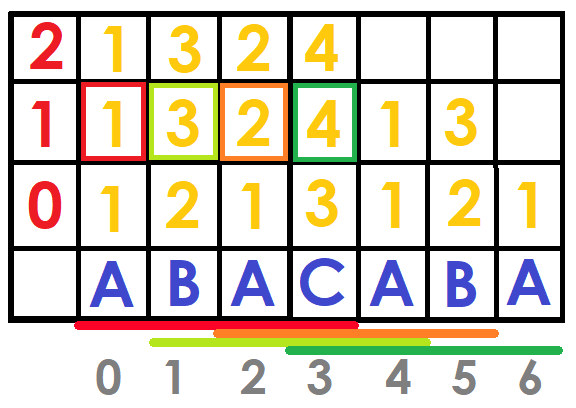
Proof:
Since we have that $$$DBF [i] [j]$$$ is the position of $$$ S [i ... i + 2 ^ j + 1] $$$ between all substrings of size $$$ 2 ^ j $$$. If we want to compare two substrings, which would be represented as pairs, and we compare the first element in the pairs, we are comparing prefixes of size $$$ 2 ^ k $$$ of the substrings (where $$$k$$$ is the logarithm of the size of the substring). If they are the same, we compare the second elements of the pairs, which would be the same as comparing suffixes of size $$$ 2 ^ k $$$ of the substrings.
This technique can also be used to build the suffix array (If you still don't know how to do it, check this link, you have already learned most of it).
Implementation in a suffix array made by Tet .
Thanks for reading, I hope this article will be useful. Any questions or suggestions let me know in the comments.







Very good blog, I had not found any of this content, thank you very much, contribution for you xD
+1 upvote ; )
wow, very interesting...it resembles the rmq sparse table technique, to some extent (not really, but kinda).
This technique is really important, but it's actually well known ... under the name Suffix array. https://cp-algorithms.com/string/suffix-array.html
It is one of the basic algorithms for advanced string problems.
Many people do not make the suffix array this way, despite being the most optimal. This is only the technique to compare the strings that is used in the suffix array, it is not the suffix array. I just wanted to teach the technique apart from the suffix array.
Ok, it's like 95% of algorithm of Suffix Array building without suffix array itself in the result. And if you know that, it's just weird to not mention that in the article
You are right, I should mention the uses, thanks
Despite being written on the page you linked, the technique of comparing arbitrary substrings via preserving all the levels in a table is neither required to build SA, nor really known widely. Let alone the observation that you can use the technique in isolation without wasting anything on suffix sorting.
The really well-known technique of comparing substrings is via quickly computing LCP of the two suffixes, which is a significantly different approach.
By the way, this classification-via-doubling technique is not even inherent to suffix arrays. The same is used in fast DFA minimization (1971) and finding repeated patterns in 2D arrays and trees ("Rapid Identification of Repeated Patterns in Strings, Trees and Arrays" (1972) by Karp, Miller and Rosenberg — referenced by Manber and Myers 1993 paper on suffix arrays).
Technically, most famous suffix array building algo based on this stuff, not equal. And this blog brings fresh look on problem compare two substrings. I guess besides hashes with binary search most popular is overkill chain
suffix array -> lcp array -> rmq. And in bonus with this table lcp of two substrings can be find easily in $$$O(logn)$$$.It can also be solved with linear preprocessing. Just count the suffix array, then count longest common prefix (LCP) and then you can actually find the index of the symbol which differs (which gives more info, than just comparison) using RMQ in O(1). It's kinda hard to write the code to differentiate O(nlogn) from O(n), but possible.
Good one , upvoted :)
A small fix: I think you mean Radix sort, not Counting sort.