


Это русский разбор задач D, E и F.
D — Дерево с ограничениями
Будем строить дерево сверху вниз, пытаясь выполнять данные ограничения. Можно заметить, что если вершины i и j (i < j) должны быть в некотором поддереве, то любая вершина k (i < k < j) также должна быть в этом поддереве. Из этого следует два вывода:
- Задачу "найдите дерево с корнем 1, которое будет иметь N вершин и для которого выполняются данные ограничения" можно переформулировать как "найдите дерево с корнем 1, для которого выполняются данные ограничения, которое должно содержать как можно меньше вершин и которое содержит вершину N"
- Нам нужно знать только минимумы и максимумы для левых и правых частей каждого поддерева.
Пусть, мы пытаемся построить поддерево с корнем i, которое должно содержать вершину m, вершины [j1..j2] слева от корня и вершины [k1..k2] справа от корня. Если ограничения для левой или правой части поддерева отсутствуют, то мы можем поместить все вершины полностью направо или полностью налево (мы все равно должны проверить выполнение имеющихся ограничений). В противном случае должно выполняться i < j1, j2 < k1. Левый ребенок корня должен быть вершиной i + 1. Вершины [j2 + 1;k1 - 1] могут располагаться слева или справа от корня. Построим левое поддерево с корнем i + 1 так, чтобы оно содержало вершину j2 и имело как можно меньше вершин. Пусть, вершина с наибольшим номером в этом поддереве mid. Тогда должно выполняться условие mid < k1. Можно сделать так, чтобы правый ребенок имел индекс mid + 1, и нам осталось построить правое поддерево так, чтобы в нем обязательно была вершина max(k2, m).
Сложность алгоритма O(N + C)
E — Разрезание массива
В общем случае нам нужно вычислить следующее выражение:
max(... + |sj - 2 - sj - 1| + |sj - 1 - sj| + |sj - sj + 1| + ...) = max(... ± (sj - 2 - sj - 1) ± (sj - 1 - sj) ± (sj - sj + 1) ± ...)
Эта задача может быть решена с помощью динамического программирования. Будем рекуррентно считать следующую функцию, в которой нам нужно выбрать подмассивы j..k из массива [i; n]:
f(i, j, c1, c2) = max(... ± (0 - 0) c1 (0 - sj) c2 (sj - sj + 1) ± (sj + 1 - sj + 2) ± ...), где 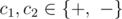 заданы.
заданы.
Рекуррентная формула для этой функции:
f(i, j, c1, c2) = maxp1, p2(c1 ( - sump = p1..p2ap) c2 (sump = p1..p2ap) + f(p2 + 1, j + 1, c2, ± ))
Мы легко можем избавиться от p1:
f(i, j, c1, c2) = max(f(i + 1, j, c1, c2), maxp2(c1 ( - sump = i..p2ap) c2 (sump = i..p2ap) + f(p2 + 1, j + 1, c2, ± ))
Мы можем избавиться от p2 используя дополнительную функцию g(i, j, c1, c2), означающую, что в подмассиве j уже есть некоторые элементы:
f(i, j, c1, c2) = max(f(i + 1, j, c1, c2), c1 ( - ai) c2 ai + g(i + 1, j, c1, c2))
g(i, j, c1, c2) = max(f(i, j + 1, c2, + ), f(i, j + 1, c2, - ), c1 ( - ai) c2 (ai) + g(i + 1, j, c1, c2))
Осталось разобраться с началом и окончанием динамического программирования. Есть несколько способов это сделать. Например, мы можем посчитать максимумы и минимумы значений s1 или sk в зависимости от их концов или начал, или мы можем сделать исключения для использования c1 and c2 если j = 1 или j = k.
Сложность алгоритма O(n * k)
F — Скейгербосс
Задача сводится к тому, что у нас есть k женских особей и k мужских особей, и нам надо их соединить так, чтобы в одной клетке было не больше пары. Задача решается потоком.
Будем перебирать ответ к задачи ans (например, двоичным поиском). Проведем единичные ребра от истока к женским особям и от мужских особей к вытоку. Проведем единичные ребра от входа до выхода каждой клетки. И проведем единичные ребра от женских особей к входам каждой клетки, если она может туда дойти не больше, чем за ans. Аналогично проведем единичные ребра от выходов каждой клетки до мужских особей. Ответ не больше ans если в таком графе существует поток размером k.
Описанный выше подход достаточен, чтобы решить первую часть задачи. Сложность алгоритма O(k3 * log(k)). Для решения второй части задачи нужно оптимизировать данное решение. Хорошо соптимизированное решение с данной сложностью может пройти по TL, но существует решение со сложностью O(k3).
Можно заметить, что вам не надо перестраивать граф каждый раз для запуска потока. Если вы запускаете поток для ans = a, а затем запускаете поток для ans = b, b > a, вы можете просто добавить недостающие ребра и "продолжить работу" потока. Сложность этого подхода O(k3 + l * k2) где l — количество раз, вы будете производить этот трюк. Использование такого наблюдения разными способами должно быть достаточно для сдачи второй части задачи.
Вы можете достичь чистой сложности O(k3) используя корневую декомпозицию. Вы можете разделить k2 ребер на k групп по k ребер в зависимости от значений ans, для которых можно использовать эти ребра. Запуская поток после добавления каждой группы ребер вы получите сложность O(k3). Затем вы знаете, какую группу ребер нужно изучать для нахождения ответа и, запуская поток после добавления ребер этой группы, вы получаете снова сложность O(k3).
Вы также можете поделить ребра на группы в зависимости от их длин (потраченного времени), а не в зависимости от их количества. Вам нужно будет добавлять ребра одинаковой длины одновременно. Так можно еще больше ускорить работу алгоритма.
Я (White_Bear) хотел бы передать особенные поздравления mmaxio, Petr, niyaznigmatul и Egor, которые решили F2 на Java.






