In the problem you need to decide whether cashier can give a change to all customers if the price of the ticket is 25 rubles and there's 3 kinds of bills: 25, 50 and 100 rubles. There's no money in the ticket office in the beginning.
Let's consider 3 cases.
- Customer has 25 rubles hence he doesn't need a change.
- Customer has 50 rubles hence we have to give him 25 rubles back.
- Customer has 100 rubles hence we need to give him 75 rubles back. It can be done in 2 ways. 75=25+50 и 75=25+25+25. Notice that it's always worth to try 25+50 first and then 25+25+25. It's true because bills of 25 rubles can be used both to give change for 50 and 100 rubles and bills of 50 rubles can be used only to give change for 100 rubles so we need to save as much 25 ruble bills as possible.
The solution is to keep track of the number of 25 and 50 ruble bills and act greedily when giving change to 100 rubles — try 25+50 first and then 25+25+25.
In the problem you're asked to write the largest possible number given number of paint that you have and number of paint that you need to write each digit.
Longer number means larger number so it's worth to write the longest possible number. Because of that we choose the largest digit among those that require the least number of paint. Let the number of paint for that digit d be equal to x, and we have v liters of paint total. Then we can write number of the length 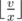 .
.
Now we know the length of the number, let it be len. Write down temporary result – string of length len, consisting of digits d. We have supply of v–len·x liters of paint. In order to enhance the answer, we can try to update the number from the beginning and swap each digit with the maximal possible. It's true because numbers of the equal length are compared in the highest digits first. Among digits that are greater than current we choose one that we have enough paint for and then update answer and current number of paint.
If the length of the answer is 0 then you need to output -1.
In the problem you need to find out how many games you need to play in order to make all people happy. It means that each of them played as many games as he wanted.
Let the answer be x games. Notice that max(a1, a2, …, an) ≤ x. Then i-th player can be game supervisor in x–ai games. If we sum up we get 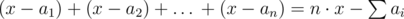 — it's the number of games in which players are ready to be supervisor. This number must be greater or equal to x — our answer.
— it's the number of games in which players are ready to be supervisor. This number must be greater or equal to x — our answer.
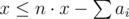
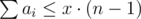
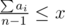
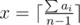
Don't forget about that condition: max(a1, a2, …, an) ≤ x.
In the problem you need to find out minimal number of apples that you need to remove in order to make tree balanced.
Notice, that if we know the value in the root then we know values in all other vertices. The value in the leaf is equal to the value in the root divided to the product of the powers of all vertices on the path between root and leaf.
For every vertex let's calculate di — minimal number in that vertex (not zero) in order to make tree balanced. For leaves di = 1, for all other vertices di is equal to k·lcm(dj1, dj2, ..., djk), where j1, j2, ..., jk — sons of the vertex i. Let's calculate si — sum in the subtree of the vertex i. All that can be done using one depth first search from the root of the tree.
Using second depth first search one can calculate for every vertex maximal number that we can write in it and satisfty all conditions. More precisely, given vertex i and k of its sons j1, j2, ..., jk. Then if m = min(sj1, sj2, ..., sjk) and 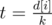 — minimal number, that we can write to the sons of vertex i, then it's worth to write numbers
— minimal number, that we can write to the sons of vertex i, then it's worth to write numbers 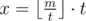 to the sons of vertex i. Remains
to the sons of vertex i. Remains  we add to the answer.
we add to the answer.
This problem is about data structures.
First step of the solution is to divide sets to heavy and light. Light ones are those that contains less than  elements. All other sets are heavy.
elements. All other sets are heavy.
Key observation is that every light set contains less than elements and number of heavy sets doesn't exceed because we have upper bound for sum of the sizes of all sets.
In order to effectively answer queries, for every set (both light and heavy) we calculate size of the intersection of this set and each heavy set. It can be done with time and memory 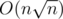 . For every heavy set we create boolean array of size O(n). In i-th cell of this array we store how many elements i in given set. Then for each element and each heavy set we can check for O(1) time whether element is in the set.
. For every heavy set we create boolean array of size O(n). In i-th cell of this array we store how many elements i in given set. Then for each element and each heavy set we can check for O(1) time whether element is in the set.
Now let's consider 4 possible cases:
Add to the light set. Traverse all numbers in the set and add the value from the query to each of them. Then traverse all heavy sets and add (size of intersection * the value from the query). Time is 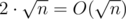 .
.
Add to the heavy set. Just update the counter for the heavy set. Time is O(1).
Answer to the query for the light set. Traverse all numbers in the set and add values to the answer. Then traverse all heavy sets and add to the answer (answer for this heavy set * size of intersection with the set in the query). Time is .
Answer to the query for the heavy set. Take already calculated answer, then traverse all heavy sets and add (answer for this heavy set * size of intersection with the set in the query). Time is .
We have O(n) queries so total time is .
In the problem you're asked to find the number of pairs of non-intersecting paths between left upper and right lower corners of the grid. You can use following lemma for that. Thanks to rng_58 for the link. More precisely, considering our problem, this lemma states that given sets of initial A = {a1, a2} and final B = {b1, b2} points, the answer is equal to the following determinant:
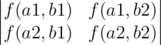
where
f(x, y) — is equal to the number of paths from point
x to point
y. You can calculate this function using dynamic programming.
Finally we need to decide what sets of initial and final points we choose. You can take A = {(0, 1), (1, 0)} and B = {(n - 2, m - 1), (n - 1, m - 2)} in order to make paths non-intersecting even in 2 points.
Let’s build a simple solution at first and then we will try to improve it to solve problem more effectively given the constraints.
For every vertex let’s find the list of the farthest vertices. Let’s find vertices on the intersection of the paths between current vertex and each vertex from the list that don’t contain monasteries. If we remove any of these vertices then every vertex from the list is unreachable from the current monastery. For every vertex from the intersection increment the counter. Then the answer for the problem is the maximum among all counters and the number of such maxima.
Let’s solve the problem more effectively using the same idea. Let’s make the tree with root. For every vertex we will find the list of the farthest vertices only in the subtree. While traversing the tree using depth first search we return the largest depth in the subtree and the number of the vertex where it was reached. Among all of the sons of the current vertex we choose the maximum of depths. If maximum is reached one time then we return the same answer that was returned from the son. If the answer was reached more than one time then we return the number of the current vertex. Essentially, we find LCA of the farthest vertices according to the current vertex. Before quitting the vertex we increment the values on the segment between current vertex and found LCA. One can use Eulerian tour and segment tree for adding on the segment.
Finally, the last stage of solving the problem – to solve it for the case when the farthest vertex is not in the subtree of the current vertex. For solving of that subproblem we use the same idea that was used in the problem of the finding the maximal path in the tree. For every vertex we keep 3 maximums – 3 farthest vertices in the subtree. When we go down to the subtree, we pass 2 remaining maximums too. In that way, when we’re in any vertex, we can decide whether there’s a path not in the subtree (it means, going up) of the same or larger length. If there’re 2 paths of the same length in the subtree and not in the subtree, it means that for the pilgrim from the current monastery there’s always a path no matter what town was destroyed. If one of the quantities is larger then we choose the segment in Eulerian tour and increment the value on the segment. The case where there’s several paths (at least 2) out of the subtree of the same maximal length, is the same with the case in the subtree.
LCA and segment tree can be solved effectively in O(logN) time per query so the total memory and time is O(NlogN).











