


Introduction
Instead of algorithms and math, I'll be doing something completely different here. There is something that has bothered me for a long time: people not understanding the tools they use to participate in contests and thus failing to take real advantage of them. And it all goes back to not understanding the command line.
Some of you might say, "well surely, the command line is something obsolete and you're only clinging to it because you [insert ridiculous amateur-psychology here]?" No! The command line is not obsolete, and unless competitive programming becomes so mainstream that software vendors start writing professional-grade tools aimed specifically at us, it won't be. $$$~$$$
What is the command line? Any of these:
As you can see, it comes in many background colors and fonts, but the basic idea is always the same. It's a box you can type commands in, which it will then execute.
Why use the command line?
- Flexible and very powerful. In competitive programming, there are a number of tasks you have to do to work with your code locally: compiling, running, testing, stress testing and so on. Modern IDEs have tools for these, but they are not really designed with us in mind. Many people have written extensions to do these things comfortably, but what if you need to do something slightly different, something the extension author had not anticipated? You get stuck and have to make-do with some stupid hack. The command line allows you to do all those things, however you want to. It's very possible that just by changing a few small things will allow you to do what the extension author had not anticipated.
- Submit exactly what you wrote. A very basic thing in competitive programming that you have to do is test your program, at least on the sample tests. The first thing that beginners usually do is they press the "run" button in their IDE and manually type the test case into the black box that appears. This is very error-prone and very time-consuming. A better way would be to read the input from a file, but now what you submit will be different from what you test locally. People will often tell you to use something called an "ifdef", but that also has its issues, see below.
- Interactive problems. Some contests such as Google Code Jam offer a testing tool for interactive problems; IOI also offers various tools to test problems. If you have never learned the command line, you'll probably have to think for a while about how to run this. With the command line, it is dead simple.
- Deeper understanding. Understanding the command line means understanding how everything your IDE does actually works. Then you are also in a better position to customize your IDE if you choose to continue using it. I mentioned testing tools for interactive problems above. Usually, you have to pass your program as an argument to them. If you have always relied on an IDE to run your code, you might not even grasp the concept of an "executable" and getting this interaction tool to run will be an impossible task. I've had to teach this stuff to people who were otherwise relatively proficient in competitive programming.
- Full control. The command line offers you the most fundamental level of control over what's actually happening in your computer.
Update 11.09.2022 More generally still, I've noticed that people often learn the bare minimum when it comes to being able to edit and run programs locally. They find one configuration or setup that works by trial and error and stick with that, even though when you look into it, it may be a ridiculously convoluted Rube Goldberg machine. This will work until the situation slightly changes, and then you're stuck.
The recent example that prompted me to write this comes from Meta Hacker Cup. There, you have to run the program locally on your computer within a 6-minute window, on a test file that may be quite large (let's say, 60 MB). For a number of people, the workflow included opening these files and copy-pasting their content somewhere else. With files this size, it is quite impractical and can easily crash editing programs that are not optimized for large files (regardless of the speed of your computer).
Learning the command line means learning how your computer works. Understanding this stuff means that you can take advantage of it and streamline your setup for testing locally.
About editors and IDEs
As far as text editors go and what I've seen people use to write code, there are basically four categories.
- Classical text editors. Examples: Emacs, vi, gedit, nano, Far Manager, Notepad.
- Lightweight modern code editors. Examples: Visual Studio Code, Sublime Text.
- Full-fledged IDEs. Examples: Visual Studio, CLion, Xcode.
- Code::Blocks.
This is obviously not some objective classification, and the lines between the categories get very blurry, but I hope on an intuitive level you understand what I mean.
My advice: don't use items in category 3 for competitive programming and don't use items in category 4 for anything. Full-fledged IDEs are meant to be used for medium-to-large software projects and are designed with that in mind. They want you to create a Solution and then a Project, then set up a Build Configuration and so on. This is all very good and important if you are maintaining a real software project with hundreds of classes and nontrivial build sequences, but utterly pointless if all your programs are in a single file, which is what you have to do in competitive programming. Many people copy-paste their code into the box on CF simply because amid all this complexity, they have no idea where their .cpp file actually is.
Moreover, although they are very powerful, you won't use any of this power. But you still have to pay for that power by having to deal with long loading times if you have a weakish computer, and using a lot of RAM.
Lightweight code editors, on the other hand, are great. They provide some of the simpler utilities of full IDEs, such as a "rename this variable" function, without introducing all the bloat of full IDEs. In addition, they usually provide easy access to the command line, giving you all the benefits I mentioned above.
The moral of the story is that you should use appropriate tools for different tasks. Software engineering very different from competitive programming, and require different tools. I use GNU Emacs for competitive programming and JetBrains Rider at work, and I would never want to do it the other way around.
Basic tasks using the command line
This section is organized as a "lab". If you are new to the command line and want to learn it, I recommend doing everything I tell here. Of course, this is more of a tutorial on "how to do essential tasks for competitive programming", not a comprehensive tutorial on how to use it in general. But I will go through other necessary commands anyway.
Setup
For this "lab", I suggest using the simplest possible program to code. Forget your good IDE for a bit to avoid any temptations. Don't worry, later we will come back to the fancy editors and using the command line there.
The first step is actually opening the command line.
- On Windows, open the Start menu and search for "cmd.exe".
- On Mac, open the Finder and search for "Terminal".
- On Linux, it depends on your distribution, but you can usually find it by opening some kind of menu and searching for "Terminal". But if you use Linux, you probably already know.
Windows actually has two kinds of terminals: cmd.exe and PowerShell. Both have their ups and downs, but the commands are different. In this blog, I will provide commands for cmd.exe but not PowerShell.
Once you have got it open, type ls (Linux/Mac) or dir (Windows) and press Enter. You should see a list of files and folders located in the folder you're currently in.
Compiling and running your code
I'll be assuming you work with C++, since that is the most common scenario in competitive programming. First, we shall write a program. Of course, you already know how to do this, so there is no point in lingering about it.
I've written a program. Save it as program.cpp.
Now, we need to compile and run it. The first step is to actually locate the file in the command line. In some ways, the command line is a lot like a file browser on your computer:
At any given time, it is in a certain folder, and you can navigate to other folders. But instead of double-clicking a folder, we use commands like cd. You can use:
cd some_folderto go to a folder calledsome_folderlocated in the current folder.cd ..to go to the parent folder.pwd(in Linux/Mac) orcdwithout any extra stuff (in Windows) to print the folder it is currently in.
The first task is to use these commands to find the folder you saved your file in. Since I don't know where you saved it, you're going to have to find it on your own.
What happens when you press that "Run" button in your IDE is actually two things.
- First, your code will be compiled from human-readable code into a magic binary file that the computer knows how to execute.
- Second, the computer will run that binary file.
If you are using Windows, you might first need to install a C++ compiler. A version of GCC is bundled in MinGW. It is a bit cumbersome to install it, but there are many good guides online. After that, you can type g++ like the rest of us. In Linux and Mac, GCC is already installed (on Mac, it's actually clang, but that's not important right now).
In modern IDEs the difference between these steps can be very blurry and also, it's not like that for every programming language. On the command line however, you have to understand that these two things are separate steps, and you have to run them separately. First, the compilation. Type
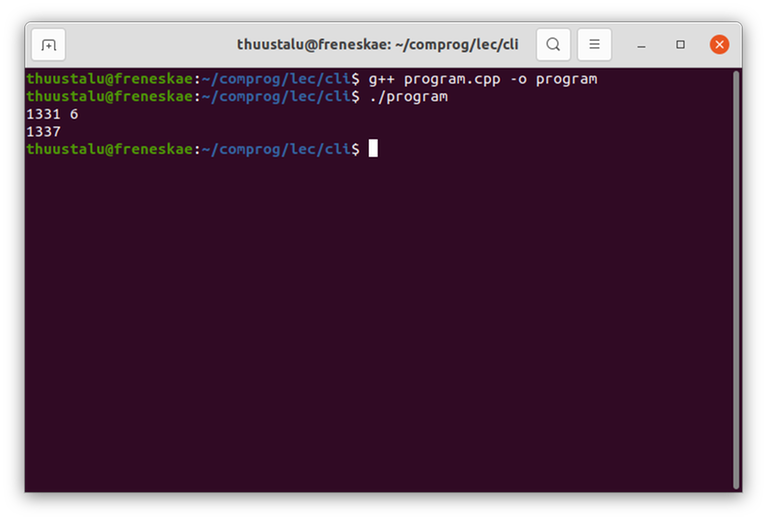
g++ program.cpp -o program
This tells another program, called g++ (the real name is GNU Compiler Collection, g++ is just a shorthand to run it in the console for C++) to compile the file program.cpp into a binary and save it as program (-o is for "output"). program will now be another file in the same folder. This file is one that the computer knows how to execute. To run your program, you can now simply write ./program (in Linux/Mac) or program.exe (in Windows). I'm not going to write (or program.exe in Windows) every time, so if you're using Windows just keep in mind that if I tell you to write ./program, you should write program.exe.
The ./ can be confusing. On Linux/Mac, when you run a program that is in the same folder as you are, you have to add that ./. There is a good reason, but I can't get into it right now, so I'll just say that this is just how it is.
Now, you can type in the two numbers, press enter, and it will print their sum.
There are a couple things to note here. Since compiling and running are separate steps, you should know that:
- If you want to run the same program multiple times, for example to test it with multiple different inputs, there is no need to compile it twice.
- However, if you modified the code, you also need to compile it again for the changes to take effect.
Finally, in case you get stuck in an infinite loop, Ctrl-C will stop the program.
Simple testing
Once you have written and compiled your code, it is now time to test it, at least on sample tests.
Many beginners do it like this. They click the "run" button on their IDE, then a black box opens. They write the test case to the box manually. This is very error-prone and very time-consuming if your program has a lot of bugs and you have to run and edit it many times before it works.
There are other problems with this approach as well. On some IDEs, the black box immediately disappears once the code has run, which means you haven't got the time to check whether the output is correct. The correct approach here is to figure out how to change the IDE settings so it doesn't do that, but a lot of students instead apply hacks such as adding int trash; cin >> trash to the end of their code so that it will wait for input and not close immediately. Of course, this means that you have to change the code to submit it, which you will forget to do, thus you get a "Wrong answer" or "Idleness limit exceeded" verdict.
In local olympiads, we have discovered that many new-ish students have completely given up testing their code locally, including testing on sample tests, because of such difficulties. Of course, this has a direct and dire effect on their contest performance.
The better approach is to read input from files, but now you have a new problem: how do I make my program read input from files locally but from standard input in the judging system. The wrong solution students come up with is writing their code to read from files and then changing it before submitting. A slightly less wrong solution is to use #ifdef, but then you have to figure out how to compile the code in a special way.
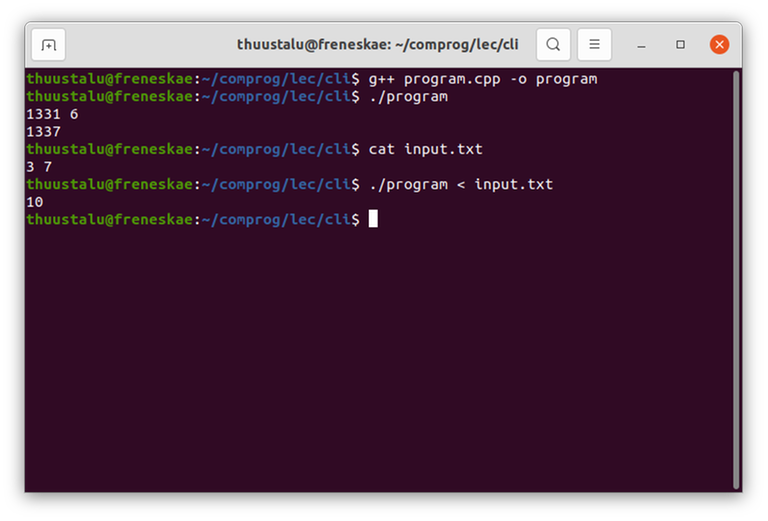
There is a better way! We have already learned how to compile the file program.cpp into an executable called program, and how to run it using ./program. Now, make an input file called input.txt and paste the test case in there. Put it in the same folder as the file program. For example:
Now, from the command line, run the following:
./program < input.txt
The < here is the key. It tells the computer to forward the contents of input.txt into the standard input, as if you manually entered 3 7. With any luck, you should see 10 on the screen.
Similarly, you can write
./program > output.txt
Now, you have to manually write the input, but the output will be written not to the screen, but to a file called output.txt. If the file does not exist, it creates it; if it does exist, it will be overwritten.
You can even combine the two as such.
./program < input.txt > output.txt
And of course, you can replace input.txt and output.txt with any file names you choose.
This will be useful later, in the "stress testing" section.
Stress testing
Suppose you get a "Wrong answer" or "Runtime error" verdict. What will you do? Well, the first step is usually to just look at the code and try to spot obvious mistakes. But it will happen, and it will happen often, that you get stuck. What do you do then?
The first thing to do is to reproduce the error; find an actual test case where your program fails. Then you can debug the code, to find out where it does the wrong thing. This method is very effective for finding mistakes in your implementation, but also to find out that your idea was wrong and exactly why your idea was wrong.
Sometimes you can find such a test case simply by manually testing some case that might be suspicious. Sometimes, you can download the test cases for the problem, for example AtCoder and many olympiads publish all test cases after the contest. But this doesn't help you during a contest; also it may happen that the test case you failed at is very large, which you effectively can't manually debug.
There is a better way! Many of you have seen this comment of mine:
Have you tried the following:
- Write a very naive and simple solution to the problem (maybe exponential complexity) (if you can, you may also just copy someone else's solution)
- Write a program to generate thousands of small (!) test cases
- Using those two, find a test case where your program gives the wrong answer
- Use print statements or a debugger to see where exactly your program does the wrong thing.
The problem. Now, we are going to learn how. First of all, we need a problem to solve, because I don't think anyone is going to make a mistake on the A + B problem we were solving before. So, let's look at CSES 1090 — Ferris Wheel (thanks de_sousa for suggesting it!).
Someone might come up with the following solution:
Sort the children from lightest to heaviest and process them in that order. If a child is too heavy to fit in the current gondola, send that gondola on its way and take a new one. Otherwise, just add the child to the current gondola.
I have implemented it here. Save it as ferris.cpp and compile it as usual to ferris.
If you submit it, you will see that it gets WA on 7 of the 12 tests. Now you might wonder whether you've made a mistake in implementation or if the idea is wrong altogether. To do so, it is best to look at an actual test. Now, on CSES you can actually view the failing test, and there are some small ones, but let's ignore this for the purposes of demonstration, because a lot of the time, this isn't going to be the case. Instead, we are going to find a failing test case by stress testing.
The naive solution. Now, let's look at, line by line, the instructions. The first line is:
- Write a very naive and simple solution to the problem (maybe exponential complexity) (if you can, you may also just copy someone else's solution)
We can't copy someone else's solution on CSES, so we are going to have to write one ourselves. How should we go about it? Here are a few guidelines.
- It doesn't matter how fast or slow this naive and simple solution is. You're only going to run it on small test cases.
- It is best to make this as simple as possible, using as little logic as possible. Make it so simple it can't be wrong.
For this problem, here's an idea. Instead of sorting the list of children, let's try all possible orderings. One of them has got to be right: if you visualize an optimal solution, we can put the gondolas in a line and read the children in this order, then that will be an order for the children. It might be that our solution would put some children in earlier gondolas, but that can't increase the number of gondolas, and it can't decrease either because the set of gondolas is optimal.
I have implemented it here. Save it as ferris_naive.cpp and compile as usual to get ferris_naive.
It's a bit suspicious that I reused some code from earlier, but if the idea is wrong, we will still find a countertest.
The generator. The second line:
- Write a program to generate thousands of small (!) test cases
The way to do this is to write a program that generates one random test case. Some guidelines again:
- This code can be very quick-and-dirty. During a contest, you shouldn't spend time polishing things like that. Whip it out as quickly as you can.
- The generator doesn't need to generate any possible test with equal probability or anything like that. All you need is a program that could reasonably well produce any valid small test case.
- As a consequence, even though rand is evil, it's totally fine to use
rand()here to generate random numbers. - It's a good idea to take the random seed from an argument and not set it by time, so you can easily regenerate a test if you need to.
I have implemented a simple generator for the Ferris Wheel problem here. Save it as ferris_gen.cpp and compile as usual to produce ferris_gen.
The code is pretty self-explanatory; the main question you might have is "what are argc and argv"? Another brilliant feature of the command line! Once I have compiled the code, I can run it from the command line as such: ./ferris_gen 5 3 8. The stuff after the program name are its arguments, and they can be accessed through argc and argv. argc is the number of arguments; in this case, 4. argv is the list of arguments. In this case, argv will be an array containing ["./ferris_gen", "5", "3", "8"]. This allows me to change the random seed or input size without changing the code or reading it from input.
The script. Now, the third line.
- Using those two, find a test case where your program gives the wrong answer
Now, how do we combine our three programs to actually find a failing test case? There is one more important part of the command line that we have to talk about: scripting. You don't have to type everything into the command line manually. It is possible to save lists of commands as scripts. When you execute one, it will run all these commands sequentially. Scripts also support familiar features of programming languages such as ifs and loops, so you can write little programs this way.
Our task is now to generate thousands of test files, run both the naive and the correct solution on them. To do it, I have written a script file.
For Linux/Mac: save the following as script.sh
for i in `seq 1 100`; do
# prints the current test number
# I like to do this so I can see progress is being made
echo $i
./ferris_gen $i 4 5 > input.txt
./ferris < input.txt > output.txt
./ferris_naive < input.txt > answer.txt
diff output.txt answer.txt || break
done
For Windows: save the following as script.bat
@echo off
for /l %%i in (1, 1, 100) do (
echo %%i
ferris_gen.exe %%i 4 5 > input.txt
ferris.exe < input.txt > output.txt
ferris_naive.exe < input.txt > answer.txt
fc output.txt answer.txt || goto :out
)
:out
The syntax is weird, but it is essentially a for-loop. How those lines in the middle work has been discussed already:
- use
ferris_gento generate a test case, forward it toinput.txt, - run
ferriswith the input ininput.txt, save the output tooutput.txt, - do the same for
ferris_naive, save the output toanswer.txtthis time.
All that's left to do is to check if output.txt and answer.txt are the same. diff (fc in Windows) is a command that does that. If the files don't match, it will print the mismatched lines and exit with a nonzero exit code. The part after || is executed only then, and it is just a break.
If this code breaks early, the script has found a test case where the naive and wrong solution disagree. It will be available in input.txt. Otherwise, it found no countertest. In this case, try varying the input size parameters, or run it on more cases.
On Linux/Mac, to run the test, you first need to give yourself permissions to run it; to do that, use
chmod +x script.sh
And finally you can run it as: ./script.sh (Linux/Mac) or script.bat (Windows).
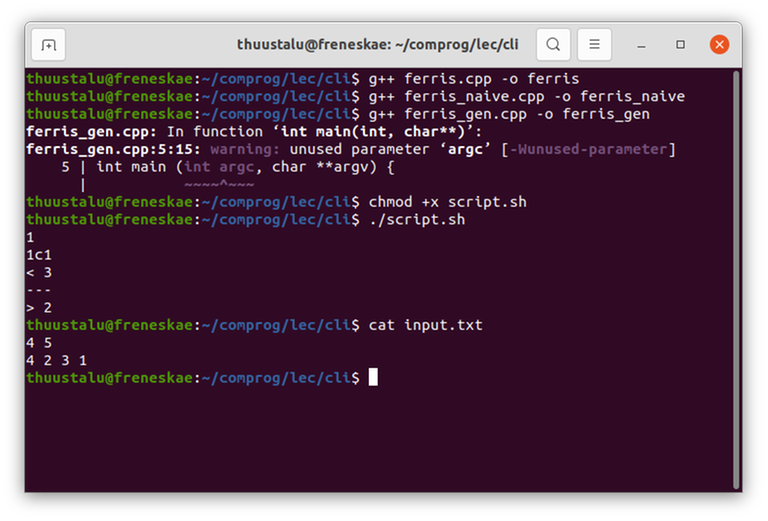
In my case, it found a countertest on the very first try:
4 5
4 2 3 1
Indeed, the greedy solution will sort them and come up with this partition: $$$\{\{1, 2\}, \{3\}, \{4\}\}$$$. But there is a better way: $$$\{\{1, 4\}, \{2, 3\}\}$$$. We have identified, that the greedy idea is probably wrong or incomplete. It's now time to rethink the solution.
Once someone told me "I already have little time to practice and now you're telling me to write MORE code? What's WRONG with you?" after I explained this. In reality, writing these extra bits of code will only take a few minutes if you can code fluently, while trying to debug code without an actual case can take hours. Yes, I actually use this method regularly during contests.
Measuring time taken
Sometimes, you need to know exactly how much time your program took. Maybe you're not sure whether it will TLE or barely pass. Maybe you're optimizing the constant and need to know if you're on the right track.
Something people will do is measuring the time taken in the code:
int main () {
auto start = duration_cast<milliseconds>(system_clock::now().time_since_epoch()).count();
// insert awesome algorithm here
auto stop = duration_cast<milliseconds>(system_clock::now().time_since_epoch()).count();
cerr << "Took " << stop - start << "ms" << endl;
}
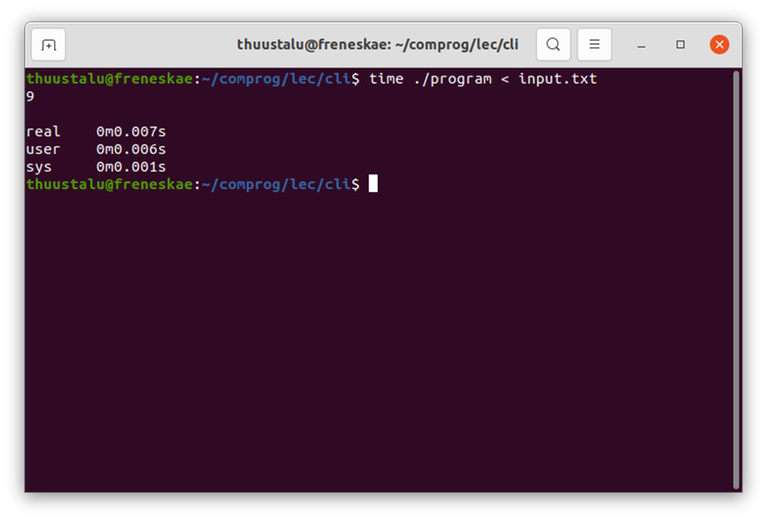
There is a simpler way! On Linux/Mac, from the command line, you can simply write
time ./program < input.txt
I don't know how to do this on Windows.
The time command will run everything after it as normal, and report the time taken. Now, this doesn't make in-code time measuring completely pointless, especially if you want something more fine-grained such as measuring how much each step took, but a lot of the time it is unnecessary, and the time command will do just fine.
Testing interactive problems
Testing interactive problems is hard. One way is to manually type inputs, which can be fine, except a lot of the times it isn't. One way is to write your own (simple) interactor to see if your code works properly. Now you have the problem: how do I make the two processes communicate with one another?
There are ways to do it with "pure" command line (with mkfifo and so on), but I think it is simplest to just use Google Code Jam's tool, which I have linked here. Now that you know how to run programs from the command line, it should be simple to run this one to test your program. You can simply write
python3 interactive_runner.py ./judge -- ./solution
Using the command line in code editors
So, am I telling you to stop using any modern code editing tools, going back to the 80s? No! People who create IDEs are generally aware of how useful the command line is and have provided ways to access it.
GNU Emacs
By M-x ansi-term. Or, in normal people' language, by typing Alt-X, then "ansi-term", then enter.
Visual Studio Code
By using "Terminal" in the top menu:
Sublime Text
By installing the Terminus extension.






One thing to note: if you're testing time limit (or if you're testing on big cases at all), it's VERY important to add the -O2 flag to your compilation, as I remember in 2017 thinking a recursive FFT code wouldn't pass the problem because it took 10s in my computer but with the flag it took less than 2s for a max test.
More about compilation flags:
If you are using gcc, you can add -fsanitize=address,undefined -fno-omit-frame-pointer -g to your compilation command. It makes your undefined behaviors detectable in runtime, as your program will crash and you'll get a descriptive runtime error message. Also, -Wall -Wshadow tells you in compilation time parts of your code that might have an error.
I think that with those flags and the script.sh technique one can always see what is causing the runtime errors verdict.
Doesn't doing that make the program run way slower?
It is slower, indeed. But the point is to use that to prevent runtime errors. It will be slower only in your local machine. And, as you said, if you want to measure or have an idea of the real runtime of your submission in the judge, you have to use the same compilations flag the judge uses, including -O2.
By the way, it is only a couple times slower. It is extremely feasible to test your solution even in large test cases.
Since we're discussing compilation flags: I have a set of 2 compilation modes: normal and debug. Normal mode to benchmark stuff and debug mode to catch possible errors.
Also, I prefer using
makeover shell scripts for compilation.Here's my
Makefilefor reference:Note that the triple dollar signs should be replaced by a single one.
Usage: run
makefor cleaning up executables,make solfor compilingsol.cpp(same goes for compiling stuff likea.cpp),make sol D=1for compilingsol.cppin debug mode,make sol P=1for compiling with OpenMP.I've dabbled with vim and CLion. I'm not good at all with technology, so I just used more or less vim basic setup (I played around a bit, but I ended up messing up vim).
One big advantage for CLion is that it automatically colors in when there's an error (in red for instance). Anyone know how to make vim do something similar?
Not a direct answer, sorry, but this is one of these places where items from "category 2" really shine as sort of "best of both worlds". I opened a C++ file in VS Code, it suggested some extensions for C++, I installed them and now have the same functionality without the massive machine that is CLion.
Similarly, I'm using Sublime Text (in WSL or Ubuntu), and it has great support for C++ via the LSP (Language Server Protocol) package and the Clangd Server. This provides lots of diagnostics and warnings while you write your program.
Clangd also respects
compile_flags.txt, a file that can be placed in the current directory or anywhere in the current directory hierarchy, and in which you can specify all your-Wall -Wextra ... -std=gnu++17flags.You can use clangd. I use coc-clangd to integrate coc.nvim with clangd. For writing safer/better code in general, you can also use clang-tidy.
I also use coc-clangd, however it seems to have problems with external libraries such as pb_ds. Do you know any fix for that?
Do you have a compile_flags.txt file? If you make that file in your project root (or any parent directory, like your home dir) then clangd will use that file to figure out what flags to pass to the compiler. So if you want to use a library, you can put the corresponding "-I" and "-l" flags into the file and clangd will become aware of them.
Don't know if this will solve your problem, but it helped me set up clangd to work with macOS's nonstandard gcc location.
I remember having this issue as well, but I switched to using precompiled headers and stopped having this issue, so you could probably try that.
I use precompiled headers for debugging, with
#ifdef, but I can't quite understand how to use this for something I actually need the codeforces judge to compile. Do you have any examples?You can also try neovim which has builtin LSP(language server protocol) support, just install the plugin nvim-lspconfig and a c++ language server (e.g. clangd) and your are good to go.
in powershell. And I see no reason not to use powershell on windows. Or
if you want just one number.
Also, MinGW is good, used by codeforces and all that, but still, I'd prefer to install the official distribution, i.e. MS Build Tools. You can then select clang, MSVC or whatever you want in its installer.
For one reason, it's a lot simpler to type
program < input.txtthanGet-Content input.txt | ./program.I have some comments.
First of all, CLion or some Visual Studio can be useful in competitive programming, mainly because they have a very user-friendly debug (compared to using gdb from command line). Probably Sublime text or other category-2 editors have some plugins for this. I don't know if Visual Studio Code has it built-in.
Second, as I think this is an educational blog for newcomers to command line, it makes sense to explain why the commands are called as they are and how to remember all this:
cdstands for "change directory",pwdmeans "print working directory",lsis probably short for "list" meaning "list the contents of the working directory",catis a substring of "concatenate", because one can pass several filenames to it as arguments, andcatwill output the corresponding files one by one, thus concatenating their contents.And what is wrong with
#ifdef? You say that "you have to figure out how to compile the code in a special way", but 1) it is not that difficult to add-DLOCALto our compilation line, especially if we create a shortcut in the editor that will compile the file for us, and 2) well we can use#ifndefif we intend to submit to codeforces only, as afair codeforces uses some flag like-DONLINE_JUDGE. Probably other platforms also use something like this.many editors nowadays (including sublime text, vim, vscode, etc) support debug adapter protocol (DAP). It's just like LSP (originates from vscode too) but for debugging. Can be used with lldb (which is better than gdb imho), works very well.
It is pointless to mess with flags with ifdef or with command line redirect when you can just use following:
So... What is the deal with category 4?
I've never used it myself, but must be a real disaster if it needs a category all to itself.
Context: I used codeblocks for maybe the first year when starting competitive programming.
Main problem is that it is unstable, for some reason there is always some problem with it especially in onsite environments.
I mean don't take it too seriously though — there is at least one good use for it: I haven't tried it myself but people tell me it is a reasonably convenient installer for MinGW.
I tried to use codeblocks in my 1st ICPC regional onsite and it froze every 5 minutes. I tried using it in both windows and linux, worked ok in windows, but didn't work stably in linux.
great blog, really helpful ^_^
You forgot category 5, online ide :p.
The past few years, I have done competitive programming almost entirely on ideone. With decent internet, you get fast load up times (just opening website) and super easy compilation and running input (paste input and click run code).
You also get the added bonus of being able to open up your work on other computers or even your phone with ease (I used to code on phone with portable keyboard sometimes) :).
The only problem is testing very large input or having programs that run for long time (ie some output only programs) in which case I use vscode or vim.
Hi! Thanks for the tutorial. Can you tell me how to print the errors in my debug file? I read everywhere to use 2> but it seems to not work for me. Currently I am using a debug.h file which I import from my local directory and use debug() methods there. The error prints in an
error.txtfile.Thanks again for the tutorial!
Why does it not work?
2>is supposed to redirect thestderrstream to the specified file.You should, of course, refrain from putting
freopen(and other file handling methods) in your code.Regarding the
timetool: using/usr/bin/time -vprints more info, including RAM usage.Can be made shorter by using a format string (
man /usr/bin/time) and aliasing:Hi, thanks for this wonderful topic. I want to know if there is a way to limit the memory consumed by the program. For example, testing the code that contains the following snippet can crash the machine.
This will gobble the Main Memory in no time. It happened to me so many times, and every time, I just used to restart my laptop wasting a lot of time waiting for it to reboot :(
ulimit?
How did I not test this? So bad of me. Thank you very much.
ulimitis a saviour here.Usage:
Some problems (probably, constructive problems) ask us to print any valid answer. A stress test cannot be done in that case. There is a need for a custom judge (a simple program that validates the output) if the problem asks to print any valid answer. I've built one. I use it when I want to test my solution against bigger test cases.
Here's the link: Custom Judge — Python Program. This should be easy to understand as it is modular and comments are also mentioned everywhere.
I wrote it for Linux. Minor changes will be required if using Windows.
Which screenshot application is that, looks amazing!
Screnshot application is the built-in screenshot in GNOME.
Assuming you're referring to the soft shadows around the windows, that's not a feature of the screenshot application. GNOME windows always have shadows like that, and if I use the "grab the current window" option when screenshotting, it includes the shadows.
What's the benefit of using the command line over say, CLion? Other than stress testing. The listed benefits don't seem to really be benefits:
Benefits of CLion:
Debugger
A singular keypress to compile and run your program
All the helpful stuff while editing — red underlines and yellow highlights, in-editor details about problems — many of which you can fix in one click
aargh why do bullet points only work the first time
How to use the Terminus extension in sublime text? I have installed it but donot know how to make a new file or open a existing file in sublime.
Auto comment: topic has been updated by -is-this-fft- (previous revision, new revision, compare).
tnx man (˘・_・˘)