


Good day everybody)
Welcome to regular Codeforces round #224 for Div.2 participants, first Div2 Only in new 2014 year:). As always Div.1 participants can take part out of the competition.
The problems were prepared by authors Pavel Kholkin (HolkinPV) and Gerald Agapov (Gerald). I can't already remember exactly in how many rounds I participate as author, co-author of just active assistant) Traditionally thanks to Michael Mirzayanov (MikeMirzayanov) for perfect Codeforces and Polygon systems and Mary Belova (Delinur) for translating the problems.
UPD: Score distribution will be dynamic, but the problems will be in supposed order of increasing complexity. The first dynamic round in this year)
We wish everyone good luck, high rating and excellent mood)
UPD2: the contest is over, we hope you enjoy it) the editorial is already here)
Congratulations to winners:
1) tankmagiciangirl
2) NagaiNatsuyasumi
3) lijian3256
4) TankKiller
5) dashabi







Thanks!:) Just finish my final-term examination, time to have a rest!:p
uhhhh lucky you are , i got an exam tomorrow so i guess i won't be participating :/ Good luck everyone :) !
I had an exam today but I will be participating :D
Do you have the keys of every round. I really want to learn
I'm too. :)
What's the point of postponing the score distribution announcement? I wonder about this every time and I could never find a convincing reason?
In my experience, there were times when there are some late changes like two problems were swapped or we concluded that a B problem should cost 1500. Since often there is much stuff to do for the authors also in the contest day, we usually decided the score distribution after everything was done.
Aha now it makes sense, thanks for replying :)
If I was an author, I would never post the score distribution before the contest. As well as the first letter of title for each problem, number of samples, or, maybe size of each statement in bytes. I don't see why any of this useless (before the contest starts) information should be published — if you are interested in it, you can find it just after round begins, it is the same as asking author to announce topics of forthcoming problems.
Or are you planning your tactics on sheet of paper depending of scoring before the round?
You can say that the distribution (and how it works, in case of dynamic) is part of the rules. Rules should be published before the contest.
IOI is a good example of this. The exact rules are different each year — for example, there was full feedback (although people can tell stories about how it worked, or to be more precise, how it did not, on the first day) and limits on the total number of submissions, and tests of each batch were reordered randomly; in Italy, there was a limited number of feedback tokens, etc. There's a choice of strategy involved, but that is not what the competition is meant to test — it's problem solving skills. The way it is, you can choose the strategy beforehand, you don't have to spend time on that during the contest.
It's the same thing here — just that it's more notable in IOI, because the rules and strategy can vary significantly; in CF rounds, there are just 2 fixed choices. Still, the same principle applies.
The score distribution has no relation to the contents of the problems. It's just points assigned to each task. It does not have to reflect the difficulty of the problems, just the author's opinion (which is often off); that same opinion decides which problems to use in a contest, would you make that "during the contest" only?
You are talking about different thing. It is ok to announce if it will be dynamic scoring or fixed scoring. But values of score for each task is really useless.
On IOI jury publish rules long time before the contest, but they never announce scoring (for example, costs of subgroups) for each task before the tour starts.
I disagree with you on the point:
Choosing appropriate strategy is always the part of competition. Even if you chosen a strategy before round you will have to correct it several times due to unforeseen contest circumstances, so you'll never be able to obtain a significant advantage with choosing good strategy before the round.
So, I think, there is no need to publish scores for separate problems before round starts. Anyone should select his own strategy when round begins.
UPD: In addition, even on IOI full published rules don't give you an opportunity to select contest strategy once and for all. Participants of IOI 2010 didn't know that there will be three optimization problems from totally eight problems on the round: that should significantly change any possible strategy you can bring on tour.
Unforeseen events are an undesired situation. We don't want them to happen, so your argument can be extended as "there's no point in doing anything, because it can always go wrong", by applying it as a counterargument to anything.
As to the UPD part, it's not published because that's an objective statement about the problems' content, and also because the specific problems are chosen late (right at IOI? I'm not sure).
Yes, the scores are useless, and that's precisely why they can be published. If they were objective, they'd contain information about the problems' difficulty (knowing this sometimes marginally helps me solve some problem, by discarding ideas that seem too easy/hard) and couldn't be published. As it is, you can just view it as a CF tradition and a way for the author to express an opinion about the problems without giving out useful info :D
By the "unforeseen circumstances" I meant not authors mistakes nor technical issues, but usual contests situations like "I've planned to write this problem in 30 minutes, but it have already took me two hours, so I need to change my tactics and write other tasks because there is only one hour left..." etc. In other words I wanted to say that even if you have an information about tasks scores, you're still not prepared to everything that can possibly happen with you on the contest. So your idea to not to involve choosing a strategy at the contest time is impossible in real life.
If you agree that scores are useless, why don't we pubish some other useless information I mentioned above like size of statement in bytes? =) Anyway, I'm not insisting that everybody has not to do that, it's up to each author to decide if he wants to publish or not.
I don't know details how those problems appeared on IOI, but participants said, that it was really a big surprise for them.
I see. Still, I can't relate to it. I have never changed a strategy during a contest — when I work on problems, I'm completely focused on the problems, not at how well I seem to do. At best, I find a moment at which I stop working seriously and take a break, which almost always (FB HC is one exception that I can still remember) goes until the end of the contest. I don't have the time nor intention to change my strategy, I only do that when thinking back to the contest in question.
I'm for publishing "for the lulz" information!
Curious mind wants to know why score distribution is always announced just before the contest?
I have registered for this contests but after all I will not be able to participate. Will I lose rating?
No, your rating will stay the same.
If you are not sure to participate then you can always Unregister before closing registrations.
No, as long as you didn't make any submission.
and by the way you can unregister from here (click on the red X next to your handle)
Am I missing something, or the contests start one hour earlier this year?
it is starting at regular time (1930 MSK). this is just a guess, but it maybe due to daylight savings that it's one hour earlier in ur timezone.
I haven't been doing well in contests lately. I hope things change in this one. Looking forward to it. Best of luck everyone!
My first contest with Python! GL ! :)
Just keep in mind that not every problem is solvable in Python when the constraints are tailored for natively compiled languages, and you'll be fine ^^ .
I want to rating under color of my eyes... (red)
Are you a vampire ? :-s
it will happen! just a bit later)
Wow, 52 unsuccessful hacking attempts. That's truly the result of the red coder :)
don't trouble the poor guy. he's still celebrating that he got 1 successful hack. :P
EDIT: his C (5721795) TLEed for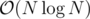 is ok, but it looks like he is using segment tree. i gave up trying to understand his code after 5 mins.
is ok, but it looks like he is using segment tree. i gave up trying to understand his code after 5 mins.
nas low as300. complexity ofThe last word: Good luck!!!~
Is problem B, really "B"?! It is much harder than problem C!
It's really harder than C, but can be solved using relatively easy binary search. T don't understand, why so many people did not solve this problem. Especially you, Xellos (no offense, just surprised).
I used cycle logic, didn't know (even if I didn't try to think about it) how to predict results for binary search... I think this approach is more intuitive...
let t be the time when c<=a
in time (t+1) c<=a also (monotone rule)
so we can try binary search for earliest t
once you get t you can calculate a and c very easily
new c = c — t
also, b is reduced by t times
let q be the time needed to raise b to non-negative
b-t*m+q*w>=0 q*w>=-(b-t*m) for (b-t*m) < 0
then new a = a — q
then you got it
http://codeforces.com/contest/382/submission/5712988
How b is reduced t times ?
I thought I'd missed a case, it was overflow in the end. But the answer was the only overflowing variable, which my brief overflow check (thinking about the problem) missed :D
I get WA on overflow too often. In one CF round, I got WA, almost immediately rewrote one int to long long, got WA again, and almost immediately rewrote another int (which I'd missed before) to long long. In GCJ last year, I failed to get to round 3 because I missed one long long (out of MANY). Etc. I really should pay a lot of attention to it.
BTW my approach was "jump to the first a--, bruteforce a lot, find the cycle, skip over it, bruteforce a lot" :D
Yeah, this problem caused lots of my WAs too. So one day I decided: if I see the possible overflow of int in my program, I change f***ing everything from int to long long :D. Just want to know your opinion, is it a perfect solution to the problem, or there are some disadvantages? Don't count using double memory amount, in 99% of cases that's not important.
Yeah, it works almost always. Long long operations are slower, it can cause problems if you use a lot of memory and sometimes even this isn't overflow-safe (MTRICK from Codechef Jan14 Long is one example), but it would save me a lot of head-banging :D
Besides, long long takes longer to type; do it several dozens of times and it's really annoying :D. The language D is good in that regard, it has 64bit long and is very similar to C/C++.
You use a lot of predefined expressions for loops, data structures etc., so you can add something like "typedef long long ll" and it won't be long to type :) That's true, sometimes even ll isn't enough. We can use unsigned long long, but it doesn't help much. Also at SEERC 2013 I heard of the type __int128, but most of the compilers do not support it :(
I don't use defines for everything, I'm a hardcore coder :D and my defines are there mostly for the memes they're based on.
128bit integer is probably not popular/old enough for it to exist in compilers. After some years, maybe we'll be taking the same way about 256bit integers.
B<C in my mind
i've used an interesting idea which is too complicated for div2B actualy.
It is obvious that allways b <= 2000 so lets define
next[b][i] = after 2^i step what will be bthen lets defineadd[b][i] = after 2^i step how many time a will decrease. So binary search on answer and check answerO(log MAX_ANSWER). Overall complexty isO(log MAX_ANSWER)^2Also here is the proof of why we can use binary search :let f(x) = after x steps what will be new a valuelet g(x) = after x steps what will be new c valuelet df(x) = f(x) - f(x - 1)let dg(x) = g(x) - g(x - 1)As you see this functions are monotonic and also dg(x) is allways less then df(x) .So they have only one intersection point.
A hard contest T_T...st° sto...
Is it just me or did this contest seem a little harder than a usual Div 2?
it's not just you.
Not just you, definitely.
That was my worst participation ever. I'm glad I'm Div1 and have rating saved :D
Can someone with submission to E please tell their solution, I couldn't get past WA11 and feel that I forgot about some case...
Пусть dp[i][j][b] — количество деревьев с i вершинами, размером максимального паросочетания j и обязательно включенным корнем/или необязательно. Теперь перебираем сколько вершин кидаем в правое поддерево, в левое идут остальные. Если b = 1, то мы ставим ребро в корень, а в детях третьи параметры могут принимать значения (0, 0), (0, 1), (1, 0), если b = 0, то только (1, 1). В процессе перебора размера поддеревьев мы должны выбрать номер корню и отправить сколько-то вершин в поддерево — это choose(n — 1, i) * n. А потом еще и поделить на 2, чтобы не учитывать изоморфные деревья. Если ребенок один, то все понятно. Ну и в конце поделить на n, т.к. корень фиксирован.
Шел бы ты отсюда...
"Roman Stankevich-Korotkevich"???
Вот это поворот:)
:)
the tree is a binary tree, one parent and two children at most.
let f[n][k] be the number of trees of n nodes, max matching k such that the root is required for the maximum matching (i.e there's no augmentation that unlatches the root and keep the matching size k).
let g[n][k] be the number of trees of n nodes, max matching k such that the root can be unmatched and keep the same matching size.
to calculate f, g we have to split the nodes we have into two subtrees and select the root of each subtree, and distribute the required matching (k) among the subtrees, you can force the node with the smallest index is always in the left subtree and recurse.
for a root to be required in the matching one of it's children must be not required in the matching.
for a root to be not required in the matching both children must be required in the matching.
based on these rules you can calculate f[n] using f[n-1], g[n-1], and calculate g[n] using f[n-1].
the answer is f[n][k]+g[n][k], watch out for the cases when you distribute the nodes and one of the subtrees is empty I had to handle those separately.
here's my AC sub 5723599, I got RTE during the contest because I didn't handle the case where k>n.
For problem C What should be the output for following?
Is it
or
1 1 of course. perhaps that's the 7th pretest
It is :(
why this is true ? i think answer is 3 1 1 1
No, since all numbers in the answer must be different. Check the problem statement.
ok! thank you
:( This test case came to my mind when there was :05 seconds left. That is why its better to write code with less if else's . You don't hit such bugs :(
1 1
1 1 of course
C is very complicated only got 300 points perhaps my solution isn' t complete enough
in my idea contest should be unrated
Advice: If you don't want hard problems, never register for "div2 only" contests ;)
Is there any particular reason why div2-only is harder than usual ? It sure seemed to me a little harder than usual. It's my worst participation yet. I don't mind the score though.
Just wondering why div2 only is harder.
Just because they don't want div 1 unoficial contestants to be bored ^^"
Hah. Fair enough. Or rather said, unfair enough xD. Though, it was a good contest. Wish I could improve to do better in the following ones.
Well, they are not ALWAYS harder. But sometimes they are because if they' re as simple as Div.1&Div.2 Contests, many Div.1 participants will solve the problems easily.
I got Re35 in D because of stack overflow. Is there a way to change the size of the stack in java(like #pragma comment(linker, "/STACK:64000000") in C++) ?
That's why I used BFS instead.
But, nevertheless, hadn't enough time :(
You can use this Thread constructor.
thanks.
i got MLE on test 35 :(
Hi,
I got WA on case no 14 in third problem.
input is:
3
1 4 2
my output is
1
3
Can someone tell me the correct answer to this case??I must be missing some simple observation.
1 3was the answer, not your output. the checker log says "output contains 0 elements". so it seems that your code produces no output at all for this input.okay..thanks a lot! :)
I misunderstanding problem C,I think the new number should be different from the array.After contest I modify a little bit,then I got AC.What a sad story, T_T
I am very shocked to find out that my short, elegant, n^2 log n, non-recursive solution to D written in Java was MLE http://codeforces.com/contest/382/submission/5724315
Amazing ! 4 from the top 5 are Unrated before :)
This is a common behavior in Codeforces Round (only div 2) !!!
I feel like I have used up all the luck in this year :-) 5722902
Looks like 2011 is a lucky number... http://codeforces.com/contest/380/submission/5706257
How !!
+125 Still a Pupil. Need to do better :/
My submission for problem D was rejected due to "memory limit exceeded". Nevertheless, after changing "string t[2000]" by "char t[2000][2000]" and reading chars instead of strings in the main program, it was accepted. It seems that the memory limit is more restricted when you read strings, that implicitly use the heap memory (I suppose). Is this what is supposed to happen?
When you insert a character into string, and the string's storage space is too small, the string will allocate a new array which is ≈ 2 times bigger and copy the data into the new array. As a result, for each of the strings the reserved memory could be greater than 2000 bytes.
Try
t[i].reserve(2000);for eachiin the start, then memory will not be reallocated (and it is also slightly faster).If it still fails, then this is due to dynamic memory (maybe the allocated blocks can't be packed so closely as in
char t[2000][2000]).EDIT: I realized that 2000 * 2000 is too small to hit the memory limit anyway. Perhaps there is something else wrong.
More Info
Problems were nice , congratz to authors , but please make the text easier to understand , not everyone is very good at english, and i couldnt solve the A and B because of that . Please explain at least 1 example ...
Thanks!