


475A - Bayan Bus
As usual for A we have an implementation problem and the main question is how to implement it quickly in the easiest (thus less error-prone) way. During the contest I spent almost no time thinking about it and decided to implement quite straightforward approach — start with empty string and concatenate different symbols to the end of it. The result is quite messy and worst of all I forgot one of the main principles in the [commercial] programming — separate logic from its presentation. The "presentation" here is all these bus characters which are all the same across different inputs. So I paid my price, my original solution failed on system tests.
Much better approach afterwards I looked up in Swistakk's solution — you copy&paste the "template" of the bus from the example test into your source code, then you just change the characters for each of 34 possible seats. Result becomes much cleaner — 8140120.
475B - Strongly Connected City
For B we already might need some kind of algorithm to solve it, though for the constraints given you might use almost any approach. If you just have a directed graph then in order to check whether you can reach all nodes from all other nodes you can do different things — you can dfs/bfs from all nodes, two dfs/bfs from the single node to check that every other node has both paths to and from that node, or you can employ different "min distance between all pairs of nodes" algorithm. All of these seem to work fine for this problem.
But we shouldn't ignore here that the input graph has a special configuration — it's a grid of vertical and horizontal directed lines. For this graph all you need is to check whether four outer streets form a cycle or not. If they form a cycle then the answer is "YES", otherwise "NO". The good explanation why this works was already given by shato. And then the entire solution takes just 10 lines of code — 8140438.
475C - Kamal-ol-molk's Painting
There are probably several completely different ways to solve this problem, I will describe only the one I implemented during the round. The start point for the solution is that there are three cases we need to cover: either first time we move the brush right or we move it down or we do not move it at all. Let's start with the last one. Since we're not moving the brush at all then it's obvious that altered cells on the painting form a rectangle. It can also be proven that the only case we need to consider here is the rectangle 1x1, that's the only rectangle which cannot be achieved by moving some smaller rectangle. So we need to count the number of altered cells, if it is equal to 1 then the answer is 1.
Now we're left with two cases to consider, you start by moving right in the case and you move down in the second case. You can write some code to cover each of those cases, but you can also notice that they are symmetric in some sense. To be more clear, they are symmetric against the diagonal line which goes from (0, 0) point through (1, 1) point. If you have some code to solve "move down first" case, then you don't need to write almost completely the same code to solve "move right" case, you can simply mirror the image against that diagonal and invoke "move down" method again. Small trick which saves a lot of time and prevents copy-pasting of the code.
Now let's try to solve this last case. Basically the approach I used can be shortly described like that: we start in the leftmost topmost altered cell, then we move down and that move already leaves us only one option what do in the next moves until the end, so we get the entire sequence of moves. As well as getting these moves we also get the only possible width and height of the brush, so we know everything, I was not very strict while moving the brush so at the end I also compared whether these moves and these sizes in fact give exactly the same image as we get in the input.
That was the brief explanation of the "move down" method, now let's get into details. First of all since we move down immediately from the start point then there is only one value which can be valid for the brush width — it is the number of altered cells which go to the right from the start point. So we know one dimension. Now let's try moving the brush. Ok, first time as we said we move it down, what is next? Then you might have a choice whether you want to move right or to move down again. The answer is to move right first because your width is already fixed while height might be unknown still, so if you miss point to be altered in the left column of the brush and you move right, you might still have a chance to paint it if you take the correct height of the brush. But if you miss the point to the right of the current topmost brush row then you won't be able to cover it later, because your width was fixed on the first step. Here is a picture:
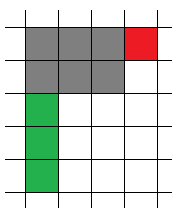
Grayed out is the current position of the brush. So what I'm saying is that you should move to the right if the cell in the red area is painted, otherwise you will definitely miss it. So this simple thing gives you the entire idea on how to build the only possible sequence of moves. You also need to calculate some possible value for the brush height. It can be calculated just before moving right, in order not to miss any painted cells you need to extend you height of the brush to cover all the painted cells in the leftmost column of you current brush position (this was highlighted as green on the image above). Now you know all the information about the probable painting — you have both dimensions of the brush and you know how it was moving, as I said before all you need to do is to double check that these moves and these dimensions in fact give you the same painting you get. If it gives the same painting then the answer for this case is width·height, otherwise there is no answer for this particular case.
If you implement all of these steps carefully and you won't paint cells more than one time, then you will be able to achieve an O(N·M) complexity.
475D - CGCDSSQ
It seems that all the solutions for this problem based on the same observation. Let's introduce two number sequences: a0, a1, ..., an and x0 = a0, xi = gcd(xi - 1, ai). Then the observation is that the number of distinct values in x sequence is no more than 1 + log2a0. It can be proven by taking into account that x is non-increasing sequence and value for greatest common divisor in case if it decreases becomes at most half of the previous value.
So we have this observation and we want to calculate the count of GCD values across all the intervals, I see couple of ways how we can exploit the observation:
We can fix the left side of the interval and look for the places where gcd(al, ..., ar) function will decrease. Between the points where it decreases it will stay flat so we can add the size of this flat interval to the result of this particular gcd. There are different ways how to find the place where the function changes its value, some people were using sparse tables, I have never used those so won't give this solution here. Otherwise you can use segment tree to calculate gcd on the interval and then do a binary search to find where this value changes. This adds squared logarithmic factor to the complexity, not sure if that passes the TL easily. Otherwise you can do basically the same by doing only one descent in the segment tree. Then you get rid of one logarithmic factor in the complexity but that will make segment tree a bit more complicated.
Another solution seems to be much simpler, you just go left to right and you calculate what is the number of segments started to the left of current element and what is the greatest common divisors values on those intervals. These values you need to store grouped by the gcd value. This information can be easily updated when you move to the next element to the right — you can check that part in my submission. Our observation guarantees that the number of different gcd values that we have to track is quite small all the time, it's no more than 1 + logAmax. Submission: 8141810, maps are used here to count gcd values, using the vectors instead makes it running two times faster but the code is not that clear then.
475E - Strongly Connected City 2
Here we can start with the simple observation — if we have a cycle then we can choose such an orientation for the edges such that it will become a directed cycle. In this case all nodes in the cycle will be accessible from all other nodes of the same cycle. I was using the bridges finding algorithm to find the cycles. So you find all the cycles, for each cycle of size si you add si2 to the answer. Then you can collapse all the cycles into the single node (storing the cycle size as well). After merging all cycles into single nodes original graph becomes a tree.
Now it comes to some kind of a magic, as far as I've seen from the discussions here people were make an assumption about the optimal solution, but nobody proved this assumption. Assumption goes like this: "there exists an optimal solution which has some node (let's call it root) such that for every other node v you can either reach root from v or you can reach v from root using directed edges of this optimal solution". Intuitively this assumption makes sense because probably in order to increase the number of pairs of reachable nodes you will try to create as least as possible components in the graph which will be mutually unreachable. So we have this assumption, now in order to solve the problem we can iterate over all nodes in the tree and check what will be the answer if we will make this node to be a root from the assumption.
Let's draw some example of the graph which might be a solution according to our assumption:
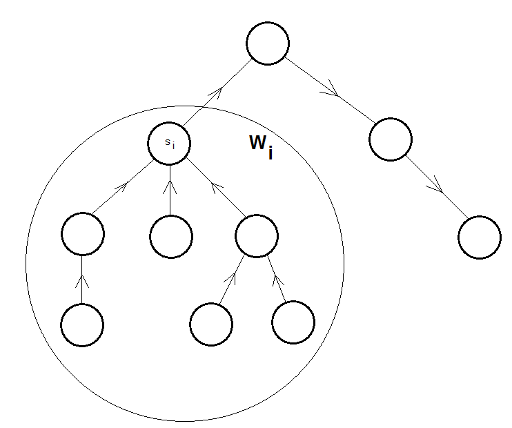
Here the root is drawn on top and every other node has either a path to the root or a path from the root. So let's say we decided that some node will be a root but we didn't decide yet for each of its children whether their edges will directed to the root or from the root. In order to fulfil our assumption the orientation of the edges within some child's subtree should be the same as the orientation of the edge between the root and its child. There will be two more numbers which we need to add to the result — pairs of reachable nodes within some child's (root children only!) subtree and pairs of reachable nodes for nodes from different subtrees. Let's introduce some variables:
si — size of the i-th cycle from the step when we were merging the cycles. In our tree all cycles are already merged into a single node, so si is a weight of the i-th node. It can be equal to 1 if node i did not belong to any cycle.
Wi — weight of the entire subtree rooted at node i.
It can be seen that if we orient all edges in the subtree in the same manner according to our assumption then the number of reachable pairs of nodes will not depend on the chosen orientation. Each particular node i adds the following term to the final result: si·(Wi - si). Now we need to decide what should be the orientation of all the edges adjacent to the root. Let's declare two more variables:
in — sum of Wi for all root's children whose edge is directed towards the root.
out — same for the children whose edge is directed from the root.
So if we have those definitions then the last term for the result will be equal to: (in + sroot)·out + in·sroot. We can see that this term depends only on the in and out values, it doesn't depend on which particular children contribute to each of these values. We check which values for in and out we can achieve, we can do it using the DP similar to the one used in knapsack. So we check every possible value for in, based on this we can calculate out value because their sum is fixed and equals to Wroot - sroot, then we put them into the formula above and check whether it gives us a better total answer.
There is one more thing to be noted about this solution — you can see that I said that we need to iterate over all nodes and make them to be the root, then you will need to get all the sizes of the children for particular root and for those sizes you will need to find all the possible values for their sums. The sum can be up to N, for some root we might have up to O(N) children, so if you've fixed the root then the rest might have O(N2) complexity. This might lead you to a conclusion that the entire algorithm then has O(N3) complexity, which is too slow for the given constraints. But that is not the case because outermost and innermost loops depend on each other, basically there you iterate over all the parent-children relations in the tree, and we know that this number in the tree equals to 2(N - 1), less than N2, so in total it gives O(N2) complexity for this solution.
Submission: 8168350
475F - Meta-universe
Let's try to solve this problem naively first, the approach should be obvious then — you have a set of points, you iterate them left to right and you mind the gap between them. If there is such a gap between two neighbours you split this meta-universe with vertical line and do the same thing for each of two subsets. If you found no such gap by going left to right, you do the same going top to bottom. If you are unlucky again then you are done, this is a universe, it cannot be split. Let's think about the complexity of this approach now, even if get the points sorted and split for free then the complexity will highly depend on how soon you found a place where you could split the meta-universe. For example if you are lucky and you will always split close to the start of the sequence then your total complexity would be O(n), which is very good indeed. If you will encounter the option to split somewhere in the middle of the sequence, which means that you split the meta-universe in two halves, you will get a O(NlogN) solution, not linear but still good enough for this problem. The worst case occurs when you split always after iterating through the entire sequence, that means that in order to extract one point from the set you will have to iterate through all of them, now the complexity becomes O(N2), that's not enough already.
Let's think about it again, we got several cases, two of them are good (when we split in the beginning or in the middle) and the third one is too slow, it happens when we split always in the end. We need to make our solution better in this particular case and that should be almost enough to solve the entire problem. The obvious approach how to get rid of "split at the end" case is to start iterating from the end initially. And it should be obvious as well that it doesn't change much because your old start becomes the end now. But what we can do instead is to start iterating from both sides, then in any case you are winner! Intuitively, if you encountered a way to split at some end of the sequence then you're good to go because you spent almost no time on this particular step and you already found a way to split it further. In the opposite case, if you had to iterate through the entire sequence and found a split point in the middle you should be still happy about it because it means that on the next steps each of your new sets will be approximately two times smaller, that leads you back to O(NlogN) complexity. Also you should not forget that you need to do the same for Y coordinate as well, that means that you need to have four iterators and you need to check them simultaneously.
This is the basic idea for my solution, there is just one more detail to be added. Initially I told that our complexity estimate is given if we "sort and split for free". That's not that easy to achieve, but we can achieve something else almost as good as this one. In order to split cheaply all you need to do is to avoid the actual split :-) Instead of splitting the sequence into two subsequences you can just leave the original sequence and extract part of it which will become a new subsequence. Obviously if you want to make this operation cheaper you need to extract the smaller part. For example if you have a sequence of points sorted by X and you found a split point by iterating from the end of the sequence then you can be sure that the right subsequence will not be longer than the left sequence, because you iterate from the left-hand side and from the right-hand side simultaneously. Now we need to take care about sorting part as well. This one is easy, all you need to do is instead of storing one sequence of points you store all the points in two sorted sets — one by X and one by Y coordinate. In total this should add just one more logarithmic factor to the complexity.
That is the entire solution, I'd like to get back one more time to the complexity analysis. We have a recurring algorithm, on every step of the recurrence we're looking for the split point, then we split and invoke this recurring algorithm two more times. It looks that for the worst case (which is split in the middle) we will split a sequence into two subsequences of the same size, so we have a full right to apply a Master theorem here. On each step our complexity seems to be O(NlogN) (log factor because of using sets) so the "Case 2. Generic form" section from the Wiki gives us a solution that our entire algorithm has an O(Nlog2N) time complexity. Am I correct?
My submission — 8138406







Wow, I was mentioned in an editorial :D.
As I understand, since no official editorial was published, you got an idea of creating one by your own? This deserves more upvotes.
Some notes:
-In E problem it is worth mentioning that only vertex we need to check as root is centroid. Assuming that we know that our first assumption about existing of such root is true, proving that statement is pretty easy. Moreover that knapsack can be done even faster than O(n2), see that comment /blog/entry/14077#comment-190774
-Your notation in CGCDSSQ problem is pretty confusing. You used gcd(l, r) as gcd(al, ..., ar). New donotation is needed here.
I will read this "New donotation is needed here." as "New donation is needed" :-)
In E there are several ideas which seem to reduce the search space, like which vertex to check for the root role and that we probably want close to equal distribution of the numbers of "in" and "out" nodes, but those need to be proven, during the contest I tried to prove as least as possible and just calculate whatever is possible. This editorial for E covers my solution from the round, I didn't come back to this problem afterwards, but comments about better ideas are obviously welcome.
Changed gcd(l, r) -> gcd(al, ..., ar)
"I will read this "New donotation is needed here." as "New donation is needed" :-)" -> I searched for an appropriate word and I'm not sure if I picked a good one, but it meant to be "denotation" : p.
I think it works as "notation" (noun) <=> (verb) "denote". And you used "notation" in the sentence before it, so why search for a different word? :D
Thank you. This is really good. Have you already won a tshirt?
Nope, not yet. Can you please link this editorial to the contest so it won't get lost?
You will be getting one then! Link added to the post.
Thanks, that's very generous, I'll present it to my mom, promised her the next T-shirt I win.
Nice
After reading all codes with the same verdict(wa12), I realized, that my bug is different from bugs of these guys. So, I just want to ask people to help me pass this test because I have no idea where my code can "cut" 200000 from the correct answer :|
It looks like here:
you only add those who can reach "outbound" nodes from the "inbound" nodes and from root. You can also reach the root from the "inbound" nodes and that seems to be missing in your code.
Let v be the curent vertex, u be the vertex on path from the v to the root(or root). Count of such vertexes = deep. In optimal solution we have or path v - > u or u - > v. I add this thing in first line of this dfs. In general, I calc paths from the root to the "outbound" nodes, from the "inbound" nodes to the root (inf void dfs1), paths from the inbound nodes to the outbound nodes and at last paths which pass through the on BCC. I have not forgotten anything? p.s. For sons of the root deep = sroot, so I add to cur value sroot * sv
I found my mistake. I used vector of chars instead vector of ints... So silly mistake.
Can someone please help me with Problem D :
I am not sure why I am getting TLE here. My submission.
Thanks in advance! UPD : Solved
your time complexity is O(n*logn*logn).
consider n<=100000, logn<=17, your implementation is nearly 20 times slower than O(n*logn).
By checking out other people's submission, several hundres of milliseocnds are needed to be accepted for O(n*logn), so your implementation has a big chance of TLE.
Dsxv
if(query(l,mid) == gc)this has to beif(query(i,mid) == gc)AC submission after changing
ltoi: 87025705Time complexity: $$$O(n(logn)^2)$$$
Hi! I solved it already, (the same mistake as you mentioned) sorry I didn't update my comment. Thanks for your efforts though!
I know the gcd decreases in logn steps that is atleast prime 2 will be out of current gcd but then I thought gcd will stay flat and then what to do and discarded the idea immediatley without even thinking for a moment.
the another solution you talked about for D is just similar to sparse tables but a bit different.