


In this problem one need to determine the number of points for both guys and find out who got more points.
Time complexity: O(1).
501B - Misha and Changing Handles
The problem can be formulated as follows: The directed graph is given, its vertices correspond to users' handles and edges — to requests. It consists of a number of chains, so every vertex ingoing and outgoing degree doesn't exceed one. One need to find number of chains and first and last vertices of every chain. The arcs of this graph can be stored in dictionary(one can use std::map\unoredered_map in C++ and TreeMap\HashMap in Java) with head of the arc as the key and the tail as the value.
Each zero ingoing degree vertex corresponds to unique user as well as first vertex of some chain. We should iterate from such vertices through the arcs while it's possible. Thus we find relation between first and last vertices in the chain as well as relation between the original and the new handle of some user.
You can see my solution for details.
Time complexity: 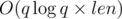 .
.
Note that every non-empty forest has a leaf(vertex of degree 1). Let's remove edges one by one and maintain actual values (degreev, sv) as long as graph is not empty. To do so, we can maintain the queue(or stack) of the leaves. On every iteration we dequeue vertex v and remove edge (v, sv) and update values for vertex sv: degreesv -= 1 and ssv ^= v. If degree of vertex sv becomes equal to 1, we enqueue it.
When dequeued vertex has zero degree, just ignore it because we have already removed all edges of corresponding tree.
You can see my solution for details.
Time complexity: O(n)
504B - Misha and Permutations Summation
To solve the problem, one need to be able to find the index of given permutation in lexicographical order and permutation by its index. We will store indices in factorial number system. Thus number x is represented as 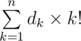 . You can find the rules of the transform here.
. You can find the rules of the transform here.
To make the transform, you may need to use data structures such as binary search tree or binary indexed tree (for maintaining queries of finding k-th number in the set and finding the amount of numbers less than given one).
So, one need to get indices of the permutations, to sum them modulo n! and make inverse transform. You can read any accepted solution for better understanding.
Time complexity:  or
or  .
.
504C - Misha and Palindrome Degree
Note that if the amount of elements, which number of occurrences is odd, is greater than one, the answer is zero. On the other hand, if array is the palindrome, answer is 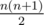 .
.
Let's cut equal elements from the end and the beginning of array while it is possible. Let's call remaining array as b and its length as m. We are interested in segments [l, r] which cover some prefix or suffix of b.
We need to find the minimum length of such prefix and suffix. Prefix and suffix can overlap the middle of b and these cases are needed to maintain. To find minimum length you can use binary search or simply iterating over array and storing the amount of every element to the left and right from the current index. Let's call minimum length of prefix as pref and as suf of suffix. So 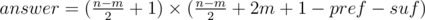 .
.
Time complexity: O(n) or .
Firstly, we convert each number into a binary system: it can be done in O(MAXBITS2), where MAXBITS ≤ 2000 with rather small constant(we store number in system with big radix).
To solve the problem we need to modify Gauss elimination algorithm. For each row we should store set of row's indices which we already XORed this row to get row echelon form (we can store it in bitset), also for each bit i we store index p[i] of row, which lowest set bit is i in row echelon form.
Maintaining the query we try to reset bits from lowest to highest using array p and save information, which rows were XORed with current number. If we can reset whole number, the answer is positive and we know indices of answer. We update array p, otherwise.
Time complexity: O(m × MAXBITS × (MAXBITS + m)) with small constant due to bit compression.
Let's build heavy-light decomposition of given tree and write all strings corresponding to heavy paths one by one in one string T, every path should be written twice: in the direct and reverse order.
Maintaining query we can split paths (a, b) и (c, d) into parts, which completely belongs to some heavy paths. There can be at most  such parts. Note that every part corresponds to some substring of T.
such parts. Note that every part corresponds to some substring of T.
Now we only need to find longest common prefix of two substrings in string T. It can be done building suffix array of string T and lcp array. So, we can find longest common prefix of two substring in O(1) constructing rmq sparse table on lcp array.
Time complexity: 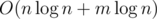
For the better understanding see my solution.
P.S. One can uses hashes instead of suffix array.
ADD: There is another approach to solve this problem in 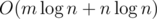 but it's rather slow in practice. We can do binary search on answer and use hashes, but we do it for all queries at one time. The only problem is to find k-th vertex on the path, we can do it offline for all queries in O(n + m) time. We run dfs and maintain stack of vertices. See my solution for details.
but it's rather slow in practice. We can do binary search on answer and use hashes, but we do it for all queries at one time. The only problem is to find k-th vertex on the path, we can do it offline for all queries in O(n + m) time. We run dfs and maintain stack of vertices. See my solution for details.






For problem 504B (501D for Div 2) we can also use square root decomposition instead of trees in order to transform the permutation, and still wouldn't hit the given time limit.
Problem C can also be done without observing that every good interval is an "overinterval" of those 2 ones. For each starting l I just computed smallest good r using sliding window idea and maintaining some informations about actual interval. Those informations consisted of number of bad pairs (i, n - i + 1) completely outside of interval (this needs to be equal to 0) and some counters of needed values to make sure that pairs of form (i, n - i + 1) where only one of those two indices belongs to our interval can be satisfied. See my submission: 9413910
If I'm not mistaken problem E can be done if we will store jumppointers together with hashes of strings represented by paths they are corresponding to (in both directions from down to up and from up to down) and that should be easier to code.
Do you really think that if your solutions looks like those: https://ideone.com/42hc8F and http://ideone.com/2OxibB then this problem (E) is appropriate as one of 5 problems given in a 2-hour long contest?? You seem to forgot that you had unbounded time and contestants got <=1 hour for that problem alone. Moreover you purposefully set constraints so that solutions in slightly slower complexities will get TLE. Telling by number of lines of your solutions that was another "great" idea.
There is a "P.P.S" in russian version of E editorial, that says that there were big tests against jumppointers + hashes. At least if I understand what you mean here. However, some contestants got AC with this idea tweaked a bit (which resulted in many-many cases in their code).
I think the prolem can be made using O(1) time for query.My idea is maintaining something like a suffix array on tree.You just sort all the suffixes(like node i and his 2^j th ancestor(which you build like a RMQ)) and you are going to keep sa second suffix array with these string reversed, and for these, you preacalculate lcp between two consecutive suffix, than lcp being tha minimum between the LCP between poitions in sorted array of the two suffixes.You also noeed to get LCA in O(1) with an easy euler crossing and maintaining anther rmq.And, yeah, the sources are two big and the official idea is to easy and to hard to code for a div1E problem, which should be very interesting and the code should be about 150 rows, in worst case, or something like that.
I'm curious about that solution, most people tried doing it in O(log^2 N) per query but it is too slow. If we try to do it in O(log N) going up is not the problem but going down is. I managed to do something like that 9420369 but it was ugly and long too, and constant factor was very large, I had to do about 10 O(log N) operations for a single query. Is there anything better?
For 501B we could use two lists(python3) for solving rather than using dictionaries. 9409569
Your solution has complexity O(q2 × len). I described significantly faster one.
Can someone please explain problem 504C — Misha and Palindrome Degree in detail? help is appreciated :).
Hello can someone explain that how to add the two permutations in Factorial number system.
Thank you.
I wrote a blog for 501 D Misha and permutations. Here it is.
You can find the details there.
FigureOutByYourself-forces.
HELP, Can anyone explain the addition of two numbers in the factorial number system without converting them to decimal under n! as required in Misha and Permutations Summation
Imagine you have the factoradic F = (2, 3, 0, 1, 0) with n = 5, which means 2*4!+3*3!+0*2!+1*1!+0*0!
Now lets calculate F+F = (2+2, 3+3, 0+0, 1+1, 0+0) = (4, 6, 0, 2, 0), which means 4*4!+6*3!+0*2!+2*1!+0*0!. In the Factorial Number System, it makes no sense to use a number greater than the factorial used in the same position, as it could be represented as the next position (e.g 5*3! = 1*4!+1*3!). So we should modified our previous calculation F+F to be represented in this way F+F = (2+2, 3+3, 0+0, 1+1, 0+0) = (4, 6, 0, 2, 0) = (1, 0, 2, 1, 0, 0) = 1*5!+0*4!+2*3!+1*2!+1*1!+0*0!
And when you need to calculate F*F mod n! (as n = 5), it is the same as removing the first element of the result.
Here is my solution, with a class Factoradic which might help you :)