


Problem link: http://www.spoj.com/problems/DQUERY/en/
I was maintaining a map<int,int> for each node in the tree. Nd I'm getting WA with this approach. Plz help me fix this.
Solution link: http://ideone.com/1CcC8d
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3690 |
| 2 | jiangly | 3647 |
| 3 | Benq | 3581 |
| 4 | orzdevinwang | 3570 |
| 5 | Geothermal | 3569 |
| 5 | cnnfls_csy | 3569 |
| 7 | Radewoosh | 3509 |
| 8 | ecnerwala | 3486 |
| 9 | jqdai0815 | 3474 |
| 10 | gyh20 | 3447 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 165 |
| 3 | adamant | 162 |
| 4 | TheScrasse | 160 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 152 |
| 8 | orz | 146 |
| 9 | SecondThread | 145 |
| 9 | pajenegod | 145 |
Problem link: http://www.spoj.com/problems/DQUERY/en/
I was maintaining a map<int,int> for each node in the tree. Nd I'm getting WA with this approach. Plz help me fix this.
Solution link: http://ideone.com/1CcC8d







The easiest way to solve this problem is with square root decomposition. Divide the array into blocks of size , then sort the queries first by the block of the left end and then by ascending right end. The left pointer will move at most
, then sort the queries first by the block of the left end and then by ascending right end. The left pointer will move at most  times for each query and the right pointer will move at most N times for each block, so total complexity is in the order of
times for each query and the right pointer will move at most N times for each block, so total complexity is in the order of 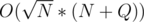 .
.
Since numbers are at most one million, you can keep track of how many elements you have in the current window with a simple array count[i]. Every time count[i] becomes zero, you have one less element and every time it becomes one with an increase operation, you have one more element.
I don't agree with you!
The easiest way to solve this problem is with Segment Tree.
You can use persistent-segment-tree to solve this task online, or you can remember all queries and solve it offline, using standart segment tree.
I solved this task in January. Here is my code.
Do you really think segment tree is simpler?
Take a look at the code of sqrt-decomposition: SQRT-Dec C++ Code
If you think your code is simpler than that then we have really different perceptions of what's simple and what's not.
Well, I think, my code is simpler than yours :) Also it's online.
Here it is: #FUYCFc
That's a really nice implementation of persistent segment tree. Good job!
can you explain how u did it using persistent segment tree.I understand that we keep segment trees for every prefix, and for every prefix i we can generate the new segment tree by chaning log(n) nodes of prefix(i-1).But how are we calculating the number of distinct elements in the sement [l,r]?
One way to do it:
The idea is to keep only the last occurrence of each number in each prefix
Let root[i] be the ith root/segment tree and corresponds to the prefix [0, i]
How to get root[i + 1]?
Let the (i + 1)th number in original array be X, if it isn't the first occurrence of X, update segment tree and make the number at the index of previous X = (0) and value at current index(i+1) = (1), otherwise just make the value at current index = (1)
To answer query [l, r] do range sum query on (r)th root over the same range [l, r]
This way each number will be counted only once, and since we are keeping only last occurrence, the answer for any [?, r] is present after processing root[r]
In other words, you may reorder the queries by their right end point in ascending order and use a normal segment/bit tree to answer queries offline