


ABBADiv1 (d1 easy)
The main idea here is that you should work backwards from the target string to the initial string. Almost any solution based on this idea can work. The simplest solution, conceptually, is to do a recursive backtracking search. It will run in polynomial time without any memoization at all. Why?
If it runs in exponential time, we need a branch at each step (a choice of whether to try the last move as A or B). But suppose we had the option of picking A, and we picked B. Now we can never pick B again, since the first character in the string will always be A. So that branch will be resolved in polynomial time. The total complexity is something like O(N3).
You can solve it in O(N) with KMP and prefix sums.
ChangingChange (d1 medium)
In this solution we will assume valueRemoved[i] = 1 for all i.
Let's use generating functions. Suppose ways = {1, 3, 6, 2}. Then we will view it as the polynomial 1 + 3x + 6x2 + 2x3. You can show that adding a coin is equivalent to multiplying by (1 + x). So removing a coin must be equivalent to multiplying by 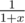 . That's equal to 1 - x + x2 - x3 + x4... (if you don't like calculus, work out the first few terms and you'll see it's 1, -1, 1, -1, 1...). So if numRemoved[i] = n, we want to find the coefficients of (1 - x + x2 - x3 + ... ± xD)n in linear time. You can show by induction that the signs always alternate for any value of n, so all we need is the magnitude of the coefficients of (1 + x + x2 + x3 + ... + xD)n.
. That's equal to 1 - x + x2 - x3 + x4... (if you don't like calculus, work out the first few terms and you'll see it's 1, -1, 1, -1, 1...). So if numRemoved[i] = n, we want to find the coefficients of (1 - x + x2 - x3 + ... ± xD)n in linear time. You can show by induction that the signs always alternate for any value of n, so all we need is the magnitude of the coefficients of (1 + x + x2 + x3 + ... + xD)n.
How can we find those coefficients? Multiplying by that polynomial is equivalent to taking the prefix sum of the coefficients. For example, (1 + 3x + 6x2 + 2x3)(1 + x + x2 + x3) = 1 + 4x + 10x2 + 12x3 + .... There's a combinatorics problem where the values for a given n are the prefix sums of the values for n - 1: the number of right-down paths on an n by c + 1 grid (where c is the coefficient we want). And the formula for that is 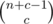 .
.
So, here is the formula that solves the problem:
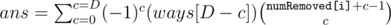
To solve it when valueRemoved[i] ≠ 1, just replace ways[D - c] with ways[D - c·valueRemoved[i]].
WarAndPeas (d1 hard)
Instead of cards and pairs, call them vertices and edges in a complete graph. Let's call the lowest-numbered vertex (the one whose owner never changes) the source vertex. Other vertices that are the same colour as the source are good. Otherwise they're bad.
The critical observation is this: suppose we know there are X good vertices. Then all distributions of the X good vertices are equally likely. This is true regardless of the number of steps. We can prove it by induction on the number of steps (clearly it's true after 0 steps, since each vertex is assigned to the two owners with equal probability). Now we make a new move and select edge E. There are a few cases; note that while the relative chances of these cases depend on the value of X, they don't depend on the distribution of the X good vertices:
- E touches the source vertex. Since all edges touching the source vertex are equally likely to be selected, this preserves the hypothesis.
- E connects a good vertex to a good vertex or a bad vertex to a bad vertex. By the induction hypothesis, all distributions are equally likely. If this outcome happens, the state of the graph is unchanged. Therefore this preserves the hypothesis.
- E connects a good vertex to a bad vertex. Suppose A's colour is overwritten by B's colour. For every distribution where A was good and B was bad, there was an equally likely distribution where B was good and A was bad. So this also preserves the hypothesis.
So, instead of 2N states, we have N states, where state i represents the state with i good vertices. Suppose Carol's state has x good vertices. By linearity of expectation, we can find the expected number of times we enter state i, divide by 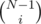 , and we have the answer. Normally you would do this with a system of linear equations, but solving a general system takes O(N3). We can speed it up to O(N) (times log factor for modular inverses) by using the fact that state i can only enter state i - 1, i, and i + 1. Represent the expected value from state x as a function of the expected value from state x + 1. It turns out that the function is very simple: f(x) = f(x + 1) + c for some constant c. We can work it out starting from state 0, going to state N - 1, then working backwards and representing the function as a constant c. Add up the expected value from each state, multiplied by the chance of starting in that state, and you are done.
, and we have the answer. Normally you would do this with a system of linear equations, but solving a general system takes O(N3). We can speed it up to O(N) (times log factor for modular inverses) by using the fact that state i can only enter state i - 1, i, and i + 1. Represent the expected value from state x as a function of the expected value from state x + 1. It turns out that the function is very simple: f(x) = f(x + 1) + c for some constant c. We can work it out starting from state 0, going to state N - 1, then working backwards and representing the function as a constant c. Add up the expected value from each state, multiplied by the chance of starting in that state, and you are done.
Probably that explanation made no sense, so here is the code: https://ideone.com/ggJ2qd.
ChessFloor (d2 easy)
Try all possibilities. The tricky case is that you can't have all tiles the same color, but it was included in samples.
ABBA (d2 medium)
Work backwards from the target state. The previous move can be uniquely determined by the last character of the string, so simulate it until the strings are the same length and then check if they're equal.
CheeseRolling (d2 hard)
Use DP with 2N·N states, and iterate over all 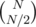 possibilities for the bracket. The complexity is
possibilities for the bracket. The complexity is 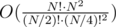 .
.







Thanks for fast editorial. :)
"But suppose we had the option of picking A, and we picked B. Now we can never pick B again, since the first character in the string will always be A."
Damn! Missed it.
In ABBA(d2), I don't understand clearly why the above approach works. What if the initial is a suffix in the target string. Will this algorithm give the correct result?
We don't bother with the initial at all. Both operations add a unique character to the end of initial, so working back from target we can tell the operation that was last applied by looking at the last character of target. By identifying this operation and reversing it until the length of target is equal to the length of initial, we can tell if initial can create target or not.
Can you explain CheeseRolling(d2 hard) in detail?
Let's define f(S) as a function that takes a state (a subset of the people) and returns an N-element vector that gives the number of ways each person of the state can win (so, the answer to the problem will be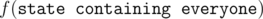 ).
).
To compute f(S), we can iterate over all divisions of S into two equal-sized subsets A and B. Then for each i, j such that i beats j, we should increase f(S)[i] by f(A)[i] * f(B)[j] + f(A)[j] * f(B)[i].
https://ideone.com/QvHpbb
why A and B have to be equal sized ?
can't this logic work instead, to compute f(S) we iterate over all i that are not already included in S, then for each j in S, if i beats j, we increase f(S and i included)[i] by f(S)[j]
in other words, let
dp[s][i]= number of ways player i can win in the subset s, then for each subset s, we iterate through all i that are not in s, then iterate through all j that are in s, and if i beats j we dodp[s|(1<<i)][i] += dp[s][j]Is this solution correct? Could you explain this: when we have set of two players, second player wins, we add third player and he stronger than second, so we say that third player wins at least in those cases when second. The main question is how we follow the structure of the tournament bracket? When we add fourth player, will be answer correct? I think will be smth like that
Sorry for my English :D
understood, Thanks :D
Can you elaborate on the running time ?
Is it always possible to divide S into equal-sized subsets A & B? what if when S(subset of people contains 5 .
The constraints section of the problem statement states that "N will be a power of 2." So yes, it is always possible to divide S into equal-sized subsets A and B.
Interesting fact that I forgot to mention: in d1 hard, if Alice gets vertex 0 and Bob gets all other vertices, the expected number of steps (not peas) is exactly (N - 1)2. I don't know why.
in d2 hard, will the backtracking with complexity O(N!/(2^(N-1)) pass in the given time?
Because every unique permutation has 2^(N-1) permutations with identical answers if you know what i mean!
No, it should TLE.
This is more of a conceptual question for the 550. I know that 1/(1+x) has a taylor series over reals, but why does this idea also extend to prime fields? Namely, isn't it true that x^p = x mod p, so eventually, the terms above may cycle, and the infinite series doesn't really make sense any more. I tried googling this unsuccessfully, so any resources on this are appreciated.
EDIT: Never mind, I found a link that explains this in a bit more detail here: http://www2.ee.ufpe.br/codec/Analise_Gf.pdf
Ugh, yesterday I have solved Div1C using inclusion-exclusion theorem (I mean code is the same, but I came to it through incl-excl), where there was trivial argument behind this and today when there wasn't one I forgot about incl-excl which results in a really simple argument why this formula is right >_>.
For those who don't like the generating function approach for div1 medium, there's a very simple and beautiful DP solution:
I was fearful of div1 medium, now I think I can solve it. DP is so beautiful.
Another, probably simpler solution for div1 medium:
Notice that removing k coins is the same as adding mod-k coins (here mod=1000000007). Now, for every query we can iterate over all i for which D-i is divisible by valueRemoved, and add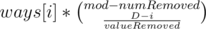 to the answer.
to the answer.
I can't prove correctness of this solution, but it seems to work.
How to get the time complexity of the d2 hard problem?
I don't really understand this sentence from problem Div1 550 analysis.
Could someone clarify this?
What will be the states of DP in Div2 Hard? What will be the transitions? Can somebody explain the solution in detail?
Read previous comments.
You can solve it in O(N) with KMP and prefix sums.
Could you please explain further.
The initial string or its reverse must match the target string somewhere, otherwise the answer is Impossible. Also, due to the nature of the B-adding operation, you'll add B's alternatively to the left and to the right of the current string. This means that among the places where the initial string matches the target, you're looking for the one in which the extra B's you need to add to the left and to the right of the string are "almost equal". Depending on parity, this means exactly equal or differing by 1 (parity also changes if you look for the reverse or not). You use KMP to find all matches and prefix sums to keep track of the B's to the left and to the right of each match.
Thanks, so the answer is yes if we can somehow alternatively add B's to the start and end of the initial string or it's reverse. And the first character to the left should not be an A. Right ?
Hi,
is it possible for someone to explain the generating functions approach for div1 mid, please? I.e. it is not clear, why those functions are used and what is their purpose here, what it means to add one more coin (i.e. to increase D or what?), how (1 - x + x2 - x3 + ... ± xD)n suddenly becomes (1 + x + x2 + x3 + ... + xD)n. And so on — the explanation is not clear :(
Would be great, if somebody can clarify that for the sake of studying that. thanks!