


Registration for the Google Code Jam 2017 is now open
Past rounds can be found here
The complete schedule can be found here
- Qualification 07.04.2017 23:00 UTC — 27 hours
- Online Round 1: Sub-Round A — 15.04.2017 01:00 UTC — 2 hours 30 minutes
- Online Round 1: Sub-Round B — 22.04.2017 16:00 UTC — 2 hours 30 minutes
- Online Round 1: Sub-Round C — 30.04.2017 09:00 UTC — 2 hours 30 minutes
- Online Round 2 13.05.2017 14:00 UTC — 2 hours 30 minutes
- Online Round 3 10.06.2017 14:00 UTC — 2 hours 30 minutes
- Onsite Finals 11.08.2017 11:30 UTC — 4 hours
Update —: Round 2 starts in 2hrs-7mins. Top 500 participants will advance to Round-3.
Gl & Hf !!







How to solve D of qualification round with maximum bipartite matching? The best I could think was to place maximum bishops and rooks on nxn chess board.
edit-solved.
You can divide the problem into one problem for rows/columns (x, o) and one for diagonals (+, o), the first can be solved greedily, and for the second one you do a maximum matching between the diagonals that haven't been used (as long as the edge represents a valid position on the grid).
Can you prove why any placing is optimal? And how can we decide which ones to upgrade?
I was able to reduce the problem to what you said, and I think it's just about placing maximum bishops(+,o) and rooks(x,o) but why is it correct?
Since you're using the maximum matching it has to be optimal. Upgrading happens when you modify one occupied cell in one of the two subproblems.
I am still unsure why greedy + MBM gives optimal answer.
I started to think that both have to placed with bipartite matching simultaneously. As, depending on how you place your 'x' you may not be able to place maximum number of '+'. eg : when n = 4, if we place 'x' in (1,2), (2,1), (3,4) and (4,3) we won't be able to place the maximum number of '+' with such an arrangement. The maximum is 6(+) + 3(x) = 9 models, but if the above configuration is followed, we only get 4(x) + 4(+) = 8 models.
They've uploaded a very detailed Contest Analysis. You can check it here
Thanks! I didn't know there was an editorial :|
The particular thing in the problem is that the value of o is 2, this gives you the equivalence between solving the main problem and the two subproblems
Oh! I see now. That's clever :)
how many points needed to go to next round "Online Round 1: Sub-Round A" ?
25 points
I solved A but can any one give a proof of that solution ( iterate the string and if the current character == '-' flip the next k pancakes )?
let us say at i-th position we have a '-' symbol and this is the left-most '-' symbol. Now, since you have to change all the '-' symbols to '+' symbols, you have to use at least one operation starting from i-th position.
I hope it gives you an idea about the proof.
I'm sorry but I didn't get it, also I'm interested with proof of optimality ( minimum number of operations ).
If i-th position is the left-most position with '-' symbol, then the claim is that it would be optimal to perform an operation at i-th position because there is no other way to convert the i-th symbol.
In case you perform an operation at a position j before i such that j + k <= i then, by our assumption, we would be creating new '-' symbols before i-th position, hence increasing the number of operations.
to understand this, first you have to notice that the flips are commutative. by noticing it, you also understand that two flips on the same range are the same as not doing any flip. so, starting from left, there's only one way to turn the first '-' into '+'. this is true for the rest of the pancakes: if there's a '-' on the pancake with index
i, there'd be two ways of turning it into a '+': by doing a flip starting atior by doing a flip starting beforei. you know that by flipping something beforeiyou'd be either canceling a flip you already did (thus turning a '+' into '-') or adding a flip you didn't do (also turning some '+' into '-'). so the only possible way of turning the current pancake is to make a flip starting at it.How to solve C-large anyone ??
Just take the max element (say X) , if its frequency is >= K then this is the answer else add its frequency to X / 2 and (X-1) / 2.
write a binary tree with the generated possibilities from N like so: root is N. left (let's call it L(n)) is the biggest subsequence generated and right (R(n)) is the smallest (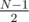 on both children for odd
on both children for odd 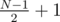 on the left and
on the left and 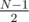 on the right for even N). Now start placing the people: you'll notice that, for a given node, the first person will stay on the node, the second will go to the left subtree, the third will go to the right, fourth will go left again, fifth will go right, and so on. Now it's easy to write an algorithm: call the answer f(n, k). if k = 1, you're on the answer node already, so just print L(n) and R(n). If k - 1 is odd, then the last guy will go to the left subtree, so the answer will be f(L(n), (k - 1) / 2 + 1). if it's odd, the last person will go to the right subtree, so the answer will be f(R(n), (k - 1) / 2).
on the right for even N). Now start placing the people: you'll notice that, for a given node, the first person will stay on the node, the second will go to the left subtree, the third will go to the right, fourth will go left again, fifth will go right, and so on. Now it's easy to write an algorithm: call the answer f(n, k). if k = 1, you're on the answer node already, so just print L(n) and R(n). If k - 1 is odd, then the last guy will go to the left subtree, so the answer will be f(L(n), (k - 1) / 2 + 1). if it's odd, the last person will go to the right subtree, so the answer will be f(R(n), (k - 1) / 2).
Norit would look like this:
After qualification round, Square869120Contest #4 will be held at Atcoder.
Let's participate and enjoy!!!!!
https://s8pc-4.contest.atcoder.jp/
Can anyone explain me what does it mean that Round 1 is divided into 3 Sub-Rounds? Does it mean that we have to advance in any of these like in TCO or we have to pass through all of them?
You just need to pass any of the three.
Problem D was very nice! Although I didn't solve it in contest, I thought the author's solution was very elegant.
Can anyone Explain the greedy method used in the editorial in a more simpler way ?And if anyone solved it bipartite matching feel free to explain your method also.Thanks in advance .
The analysis for B is unnecessarily complicated. We can just greedily construct the optimal number by going from the left to the right. (Additionally, to avoid all special cases just prefix both the input and your number with a 0.)
Example:
What is the largest next digit we can use? If we use digit d, the smallest possible final number will have d on all remaining places. If this number is small enough, there are some valid tidy numbers with the next digit d, and if this number is too large, there are no valid tidy numbers in which the next digit is d. And that's all.
My submitted code:
Another simple greedy solution is to notice, that a tidy number can be represented as a sum of at most 9 numbers consisting only of 1s. For example, 133347 = 111111 + 11111 + 11111 + 11 + 1 + 1 + 1. The solution is then to add maximum such number so that the sum doesn't exceed N and the count doesn't exceed 9.
OMG. In compare, I have a mega overkill: I wrote dp[lengthOfNumber][startingDigit] to find maximum number X, such that X ≤ N and f(X) = f(N), where f(num) = number of tidy numbers less than or equal to num.
Code: https://pastebin.com/Pw1c4rXM
I think I have an even simpler solution:
Reading the number n as a string s, for an index i, 0 ≤ i < s.size() - 1, if s[i] > s[i + 1] then we decrement s[i] and for all j, i + 1 ≤ j < s.size(), s[j] = 9. We then increment i. Since there may be cases like 554 we run the algorithm log(n) times (i.e. cases in which we have a violation of the tidy number constraint that was generated by the algorithm before index i).
Total running time is log(n)2.
Afterwards just print s without the leading zeroes.
Without dealing with any leading 0's. Printf res:
I thought that this is the same approach as above, but I was wrong. It is O(lg N). Remember the smallest digit you constructed so far. If you have something bigger, then decrement it by 1, set all 9's at the end and set that new smallest value to new decremented digit.
Just out of curiosity
Would you say problem D was comparable to a div2 D level problem, or div2 E in terms of difficulty?
I guess it was a DIV 2E, but then again i'm a noob.
I'd say it is at least div2 E or a bit higher if you consider that div2 E is getting easier and easier (maybe that's just me).
It was a very beautiful problem, especially because it reminded me of a sport I love :)
I didn't think it would be considered that difficult as close to 1000 people solved it in 27 hrs, but the logic was indeed very good behind the problem.
Which was especially noticeable in the last 408 div2 round.
I hope you're being sarcastic... XD
I'd see it as not sarcastic but last round simply showed that the other div 2 rounds were way easier than what they could be. Also, looks like tons of people misunderstood C's statement, I did that too when looking at the contest later hahaha.
Oh, I kind of misunderstood you comment. I thought you were saying last round's problem E was easy, which is definitely isn't. BTW, I also misunderstood C's statement XD
Test cases for B-small were weak. I had an AC solution which actually failed in cases such as 331.
For problem — C (large), I got the solution like — write the binary representation of k, then we will compute n for every bit (from right), except the left most bit. If the bit is '0', we get n = n/2, if the bit is '1', we get n = (n-1)/2. After computing for every bit, the answer will be — max(a, b) , min(a, b) where a & b is computed in this way : if(n%2 == 0) a = n/2, b = n/2 — 1; else a = (n-1)/2, b = (n-1)/2
The time complexity of this approach is log(k). But I can't prove why it is correct!!
How many people from online round 1 would qualify to round 2, I can't seems to find info from their site? From what I remembered, it is top 1000 of each round, but is it still the same?
Yes, it's still the same (top 1000 in each round 1 subrounds, 3000 total).
thanks! any source for that info?
https://code.google.com/codejam/terms
"1. You will advance to Code Jam Round 2 if you are one of the highest-ranked 1000 contestants from one of the sub-rounds in Code Jam Round 1. You will be notified by email after the end of each sub-round if you are one of the 3000 contestants advancing to Code Jam Round 2."
thanks
Logic for B & C in round 1A please?
I tried to do maximum bipartite matching for B small but incorrect. Probably missed some corner case. I think the large is DP.
I solved B small/large with maximum bipartite matching. If I had to guess it was probably something to do with the range that you can get from each package.
Edit: forget that, the problem is harder than I thought.
nvm
I got AC B-large with greedy. Just sort each row in Q and take earliest match possible.
C-small I could get AC with BFS, obv. doesn't work for large :D
I think everyone thought this solution at one point. Wish I hadn't overthought it :|
I submitted a max flow solution to B, during contest it passed the small so i submitted the large. The large failed after the contest so I was curious to know what the problem was, I tried submitting the large again in the practice with the same exact code and got a correct verdict! Is it just the test cases are weak for the practice or what
Are there any corner cases in B? I also used maxflow but WA.
well I don't know, actually by comparing with other solutions, my code failed in only a single case out of the 100 and it's this one http://ideone.com/WNzI0X
My code outputs 4 while the answer should be 3. It's too hard to debug though lol
Keep in mind that a package may be suitable for kits of different sizes. What do you return for this?
4 1 1 1 1 1 100 110 120 130I used a simple greedy approach — first try to match the packages with minimum size for each. If that does work, take all and increase answer by one. Otherwise, discard the package with the smallest Qij / Ri and try again, until there are no more packages left. Works in O(N2 * P).
Yes I know, actually I build a flow network of N+2 layers, first layer is source and last is sink. Each layer represents an ingredient and it has P nodes, I add an edge between a node from a layer and the layer next to it if there is at least one common kit size they both can fit in. Basically for each package, the valid kit sizes is a range so you can find if there is a common one or not by a simple range intersection
and my code returns 1 for your input
Yet the correct answer is 0. If the kit is of size >111, you cannot use the first package. If it is of size <119, you can't use the last. Hence, the is no valid kit size, even though the ranges of consecutive ingredients overlap.
loool I feel so dumb now. Thanks a lot for the help
It should return 0. The problem is that you need overlapping ranges to choose the packages. For example, (1 — 2), (2 — 3), (3 — 4) these are the ranges of 3 packages and you can't choose them but there will be flow if you simply connect them from one layer to the other.
Sometimes it's better not to know maxflow algorithm at all. You could have thought a bit more and come up with very simple greedy algorithm.
I tried max flow first. Because I couldn't find appropriate network, I wrote the simplest greedy instead.
Can you, please, explain why this greedy strategy will not work when we have arbitrary ranges (according to the official editorial)?
Especially, I don't see for now why the condition: "for 2 intersecting ranges having at least 1 common point" helps to prove that greedy approach works?
I have exactly the same question. Can anyone explain?
Looks like tests for A are weak. For test:
some accepted solutions (firstly I tried tourist's one) give this result:
Or I misunderstood statement and this is valid construction?
No letter appears in more than one cell in the input grid.
Thank you, I missed that restriction :(
Need to sleep a little bit more — it's bad idea to participate at 4am.
Made the same mistake and discovered it right now thanks to your query . Feel terrible !
Very weak test cases for B, I got AC large using a wrong max flow solution that allows to use a package multiple times.
My code gives 2 instead of 1 for this testcase:
How to solve C-large?
https://code.google.com/codejam/contest/5304486/dashboard#s=a&a=2
Anyone else thinks that the problem statement is too long?
For A, I missed no initial appears more than once on the cake. and couldn't solve the problem.
And for B, I missed (Of course, each package can be used in at most one kit.) and only found out after an hour...
I think many people missed the thing you have said about A :(
I hate problem B xD
Same here :P Though C helped me get into top 1000 :D :D
Didn't even read Problem C :S
Even i never open harder problems before even trying easier ones. ! But this time the submited problems count at begining compelled me to try C first !
Can you tell us how to solve C? I can recongise it as DP shortest path but can't handle how to solve the problem with choosing the horse.
for small : just linear dp for each horse i = 1..N for each city j = i+1 to N if j is within limit of horse i through path i..i+1 i+2..j time[j] = min(time[j],time[i]+dist(i..i+1..i+2...j) /spd[i].
ans = time[n-1];
for large: for each horse do dijikstras to find min time in which it can reach each city reachable time[i][j] = time for horse [i] to reach city[j] in other words one path from i to j of cost time[i][j]
then do floyd warshall shortest path for each pair i,j to get final cost array[n][n]
ans will be in this array
check my solution in GCJ page : username — sanket407
Just don't choose the horse, always use the horse at the current DP, when you update from a town just update all towns within range, not just the ones connected by edges.
Anyone here have a nice(short) solution to problem B? :)
GCJ people are so good at super-tricky problems. I can't believe very high success rate (more than 30%!).
For me it looked completely hopeless without stress-testing.
What is tricky about it? You just have to find a bunch of test cases. Frankly I don't see the purpose of such problems. It's not "good at super-tricky problems" it's "annoying problems".
How is round 1B problem B meant to be solved? I checked my code over and over even with triangle inequality and I still couldn't solve the small case. I have no clue what's wrong!
Did you cover a case that the last horse cant be the same as the first one?
yeah. I swap the last two if they are the same, then check if it works.
For subtask with O = G = V = 0:
Assume a >= b >= c the number of occurrences. (Assuming c >= 1, other case is trivial)
Place a's first. You need (b+c >= a) to seperate all a's. If it is not so then its impossible.
Place b's after every a and then c until finished.
Incase you have some extra c's remaining: Let extra = (b+c) — a. Place each of this after every ab: aba -> abca...
So it goes like abc-abc-abc-ab-ab-ab-ac
Code
How did you get the idea? There are logical reasoning..can you post it? The approach ?
How to small B-large ?? B-small could be done by assigning alternately colors in foll, order largest count — then mid count — smallest count
Can I see your code? I did the same thing but it kept saying i had WA.
check my code in google code jam submissions itself! Same username there as handle here : sanket407
If you don't mind, can you please tell what you did when all of them are equal? (As in the first sample test case)
If you know how to solve B-small, that should extend to B-large.
Notice for the color orange, it can only be adjacent to blues. Suppose there are x blues and y oranges. Of course if we have y > x, then it's impossible, otherwise if we have y=x, it's only possible if y+x = n. After handling this, we can reduce it to a problem where there are x-y blues and 0 oranges. Then, you solve the same case as small, and then replace any single arbitrary occurrence of "B" with "B" + y * "OB"
Honestly, if this was described as part of the problem, I still wouldn't be able to solve it.
During the contest I thought it can make a difference if you join all BOs inti one BOBOBOBOBOB or split into BOB,BOB,BOB, ... Had to bruteforce the numbers of BOBs, RGRs, YVYs. Got AC with that (the numbers sum to N/3 so the max number of combinations could be 111^3).
Now I see that the amount does not matter, thanks
PS: and failed C-large, which I thought is simple >_<
Here is an opposite take on the problem, which first solves hard and easy case follows naturally:
Consider a graph where each of 6 colors is a node. You know the number of edges between orange and blue, and two other pairs, because one should surround the other. You know that in-degree and out-degree of each node should be equal to the total number of unicorns of that color. Loop through a number of edges between, say, R and G, and then the in-degree and out-degree of every other node follows naturally from that. Now you just check if that graph has an Eyler cycle, that is your answer.
So the selection is n^2 and euler cycle takes O(E) and here E ~ N, so O(T * n^3). Isn't it TLE?
No, selection is actually O(N) — you backtrack through the out-degree of one node and the remaining in- and out-degrees follow. Then you need to check whether the obtained graph has an Eyler cycle, which can be done in O(1). Then you output that cycle in O(E) = O(N).
Actually, I computed the cycle every time and then checked that it had length N, and if so, printed the answer, so the total complexity was O(TN2), that passed.
Here is the solution: https://pastebin.com/hfxVkTyZ
I had something similar.
Can't you just check the in/out degree of each vertex in O(1) to check if an Euler cycle exists? This leads to an O(N) algorithm, I think.
That is what I said in the first paragraph exactly.
The only subtle moment is that you need to also check that the graph is connected — ex. for test 12 2 2 2 2 2 2 you get in your graph 3 connected components, in each of which in- and out-degrees are equal.
Good point. I was just checking that it was possible, not claiming you didn't already say that. I figured you could simply do this in O(1) by doing a DFS through a graph with collapsed edges.
This is so far the best solution for this deadly problem.
Either take round1-C in 4am, or say bye-bye to GCJ :(
Any ideas why A-large could fail?)
UPD:
I made wrong assumption:
If we sort horses by start position we can ignore all horses starting from first horse that ride faster than previous one.
It passed small input, it's very sad((
MAXN error? I had issue with A large because in the beginning it said MAXN = 100 but it was really 1000. (or maybe I just read it wrong the first time)
1113 Solved C Large. 730 Solved B Large.
This is bad for people who didn't even read C xD xD
Kudos for HYPERHYPERHYPERCUBELOVER alex9801 who drunk lot of beers but still passed R1B safely
It makes us feel bad about ourself. :(
By the way these statements are horrible...
Always this hate, I can't understand it..
It's a nice variation to shorter statements. I see that statements like these in weekly contests might get annoying, but GCJ is once a year.
You are right that we should appreciate long statements with a nice story behind it but in this exact situation somehow it was really difficult to have fun. (At least for me)
In the last Google Code Jam 2016, I finished 1557 in round 1B. Since then, I set the goal to advance to round 2 in Code Jam 2017 (i.e. be in top 1000).
All year, I trained to solve problems almost everyday. I kept journal of how many hours I spent on training per day, per week, per month. According to my journal since May 2016, I spent about 500 hours (and those are only hours when I worked at home in total silence).
So I thought that those efforts are enough to move from 1557 place (2016) to top 1000 (this year).
And here are results of all my efforts during whole year:
Round 1B 2017 — 6617 place!!!
I.e. I became much, much, much worse at competitive programming as a result of ~500 hours of training. It's fu....g unbelievable!!!!!!
Apparently, I have no talent whatsoever and probably I should quit...
dislike my comment if u quit competitive programming after this code jam (Y)
Probably! You should only do it if it's fun!
Will you enjoy losing chess all the time to everybody including those who trained 10 times less than you?
I won't believe you will enjoy losing game all the time.
I personally enjoy very much to have an insight and find a clever solution, see my submissions in green light with magic word Accepted. It's awesome feeling. Every time, I solve hard problem (which is rare), I'm so glad and I continue starring at my code for minutes thinking how beautiful my solution.
But if you spent hours, hours, hours, hours and hours in training to only see:
WRONG! WRONG! WRONG! TIME OUT! WRONG! YOU WRONG! WRONG! TIME OUT! YOU WRONG AGAIN!
Then you can't enjoy. You can't enjoy this disaster!
I wouldn't play chess in competitions if I felt I wasn't good enough and hate to lose. But I would still practice playing chess because it's a fun way to spend some time and maybe some day I will be able to enter a chess tournament.
You are right! Life is unfair. But if I can share one lesson from contests, it's that you can't expect to "deserve" results just because you've worked hard. That's not how this works.
Try not to take the competitive part very much serious. Competitive programming is just a thing where competitors of all levels may occasionally compete together. Just imagine if you are placed to compete with world top chess players. With dozens of them. No much point in that, right? The difference is that the CP allows this situation to happen.
Honestly, I never liked the competitive part itself. I like to solve problems, especially when I learn something by solving them. From this point, competitions don't provide me any motivation reasons, but they do provide modern problems.
So try just to forget about the competition part. No matter what rating do you have, no matter how are you placed in a contest. The best way may be not to take part in contests for a while, so you will be just facing the problems themselves. And there is no need to take it very formal, like "I've spent X hours today", you should enjoy the process, and I think it's easier to achieve when the process is more free.
There is no reason in working hard for some placing in some round — it does not show anything at your level. There is no point to take those useless numbers in mind. Enjoy, learn, solve — and only after all that — compete.
Good point. Honestly I don't like the word CP. If someone do web development in a very competitive company he is also doing "competitive programming". Fact is, we do "Algorithmic problem solving", while some fraction of them use "competitive training" to improve their skills, or just for fun.
Your rank in a contest depends completely on the type of problems you've practiced before. eg: if you've practiced lots of graph and not much else, but the contest is full of geometry, probability, etc. then you are bound to fail in that contest because that problemset is not your strong suite. If however there were some tricky graph problems, you might be able to solve it even though the total number of accepted solutions is low ( tricky problem ).
Today's problemset had my weaknesses. Naturally I failed today. But does that mean I don't have "talent" or anything like that? Mmmm.... I don't know and I don't care.
Here is a problem:
http://codeforces.com/contest/779/problem/D
I didn't solve it.
But when I looked at editorial, solution turned out to be dead simple. There was nothing I didn't know to solve this problem. Yet, I didn't find that solution.
I honestly can't understand why I didn't find that solution.
I understand when I failed to solve some problem which uses trick or algorithm I didn't know. But often, it turned out that everything I need to know I already know.
It's total mystery to me.
So it turned out that solving problems are not entirely about knowledge.
You expect a lot from yourself, and beat yourself over not being able to fulfill your own expectations. Not just that, you probably spend more time thinking "WHY CAN'T I SOLVE THIS" or "I HAVE TO SOLVE THIS BECAUSE I'VE TRAINED SO MUCH I HAVE TO" than on the problem itself.
This is nothing short of an epiphany! You are right. It's not just about knowledge. You have to know what to let go. Shake off bad days, and keep going.
You can say the same about last round's problem D. Dead simple solution, but only a few people could think it up. So many randomized algos from div1 guys also passed, which means even div1 guys had troube finding the actual solution. It didn't have any DP, tree, graph, mo's algo, centroid decomposition, etc. nothing. Just a dead simple greedy solution that everyone understood when they read the editorial.
Let's make a deal here and now. Do exactly this again for the year 2017 and let's look at what will happen.
PS: I've also got far shittier place this year =)
Same for me, took 67th (!) place at 2016 Round 1B. And now 1094th.
Last year in round 1B I screwed up with task B — I spent too much time on it, and at the end I submitted a solution in which my value of infinity was smaller than the correct answers for some test cases (which I didn't catch in the small test set for obvious reasons). I also had no clue that the task C was a standard problem. I ended up 1180th and didn't advance. A week or two later in 1C I lucked out with 31st place and eventually went on to advance to Round 3.
See how much variance is in such contest? You have good days and bad days. You can still easily qualify in Round 1C while in the first hundred, you'll forget this round and be extremely grateful for all the hard work you've put in to it!
Can someone explain how to solve B large in detail.
Hint: O need to be in between Bs, V needs to be in between Ys, and G needs to be in between Rs.
V can only be surrounded by two Ys, so the best way to arrange Vs is 'YVYVY...VY' The whole string can be seen as a single V.
So we can reduce this problem into the same as the small dataset.
The only special case is there are only Vs and Ys with the same amount, which is a valid case.
got it, thanks
Where's round 1B analysis ?!!!
Is anyone going to add the recent GCJ rounds to gym?
Around what rating(estimated) would you have to be above to solve the first problem? Just curious about how far behind I am :) Thanks!
I'm a grey and solved A small and large in 40 minutes.
I'd rather have small constraints (say n=1000 instead of n=10^6) than easier problems in small versions.
Now you have to test your large solution carefully, because there arent any pretests.
Fortunately I passed, despite of my c-large failed.
Is there any upsolving?
you can practise there on the gcj page itself ! download test files and submit output files !
How to solve large C?
I tried all sorts of heuristics and even simulated annealing, without success. My idea was that the reason it's a small input is that with heuristics you need a bit of luck to get it correct, so it's only reasonable to allow multiple tries.
Can't tell what the correct solutions are doing at a quick glance, so we'll just have to be lazy and wait for the editorial. :(
I only know, how to calculate probability that at least k of n works fine.
dbl getProb(vector prob, int n, int k) { vector work(n + 1, 0); // work[i] — probability that exactly i cores works fine sort(prob.begin(), prob.end()); work[1] = prob[0]; work[0] = 1 — prob[0]; for (int i = 1; i < n; i++) { work[i + 1] = work[i] * prob[i]; for (int j = i; j > 0; j--) work[j] = work[j] * (1 — prob[i]) + work[j — 1] * prob[i]; work[0] *= 1 — prob[i]; }
}
Stupid question but how did you solve small C? It looked deceptively simple (judging from the number of successful submissions) but somehow I couldn't crack it after almost an hour. :(
It's a well-known fact that if you know the sum of some numbers and you want to maximize their product, then you need the numbers to be as close to each other as possible.
In this particular problem, the only thing you can do to make the numbers close is to increase some small numbers so that they become closer to the big numbers we have (or increase all numbers so that they become closer to some greater value). In other words, our goal is to maximize the minimum among all numbers.
So let's do a binary search over this minimum. Once we fix some minimum V (which is to be maximized), we can take the sum of V - P[i] for all P[i] ≤ V. Then compare this sum to U and proceed with the binary search. Code goes here.
This is precisely what I did but still got an incorrect answer. Can you spot the error in my code?
As I saw from some solutions, you need to choose some j >= k, and maximize product of the j highest probabilities (with the method from small C). Choose the best from all such j. Also check the case when you increase the highest probabilities to 1.0 as many as possible.
I don't know how to prove it.
can anyone tell me the approach for A-large B-large?
B large is DP. We want the answer for each of 24*60 seconds such that ith second is cam/jam's responsibility to look after the child such that jam has already looked after the child for t seconds. So the dp table looks like dp[i][cam/jam][t]. Quite simple, but I still couldn't solve it.
How do you account for a possible exchange at midnight with these DP states?
I take the answr for 24*60 + 1th second. Something is wrong with my code as it is currently failing the 1st test case itself, but I think if we take 24*60+1th second, we will get that exchange. This is assuming that there is always an exchange at midnight, unless the read the statement wrong.
Not necessarily. If the same person starts and ends the day, then there would not be a midnight exchange.
So that's what I'm doing wrong. Thanks!
Well in this case you need one more state to keep track of starting person.
Define
f(c,j,i,s)as the smallest number of exchanges so that Cameron has watched the baby forcminutes, Jamie has watched the baby forjminutes and the baby is currently (at the end ofc+jth minute) being watched by Cameron(i=0)or Jamie(i=1)and the first one to watch the baby was Cameron(s=0)or Jamie(s=1). Store the activity status of each minute in an array so you can check in constant time who is doing activities at minutec+j-1. Each recursion step is a simple constant time check and there are only 720*720*2*2 states to store in the DP.The final answer is
min(f(720,720,0,0), f(720,720,0,1)+1, f(720,720,1,0)+1, f(720,720,1,1)).This looks so much easier to code than what I did :|
1.) Why do we need s i.e. "the first one to watch the baby"?. 2.) I kept the same state except "s" f(c,j,i) and struggled to take into account a possible exchange at midnight. My 1st and 3rd sample input return 1 instead of 2.
Link to my code:http://ideone.com/JiT8bW
[Edit] Got it. If the final person is same as the starting person, there is not need of an exchange at night.
In A-large, first sort the pancakes in decreasing order of their radii, so that i+1 can always be placed on i. Let dp[i][j] be max value of exposed surface area of a stack of j pancakes considering only first i in our list.
Then,
dp[i][j] = max( dp[i-1][j], dp[i-1][j-1] - pi*r[i]*r[i] + surface_area(i))i.e. when we do not place ith pancake or when we place ith pancake on stack of length j-1.Greedy is sufficient for A large. We can reverse sort based on radius. Then we choose each pancake as the base pancake, and choose k-1 other pancakes with at most this chosen pancake's radius with largest sum of surface area. Once the base pancake is chosen, we know the area of the disk is fixed, we just need maximum area on the sides.
Nice approach!
Can it still be
dp[i][j] = max( dp[i-1][j] , dp[i-1][j-1]+ pi*r[i]*r[i]-pi*r[x]*r[x] + surfacearea(i).Where x is the pancakes chosen at for the state (i-1,j-1).
?
This is not correct as it would subtract upper surface area of pancake x which is exposed to air.
When the pancake x, was added at state (i-1,j-1), I added the upper surface area of x.
at (i,j), That pancake x, is glued to the ith pancake so it does not have a lower surface area. We need to subtract both circles of i and x.
then add the surface area of i. (assuming we choose i at this step.)
Hos is this incorrect please ?
Let x be the uppermost pancake of j-1 length stack having surface area dp[i][j-1]. We are adding pancake i to this stack. So, the area of x which is now covered by i should be subtracted from dp[i][j] and surface area* of i should be added.
*Note: We are not considering surface area of it bottom side
I solved it using DP.
1) Choose all possible top pancake. Let this index = prev.
2) DP[prev][k] = maximum surface area of choosing k pancakes when prev is the previously chosen pancake.
The complexity is much larger than it appears as there is an inner loop in the DP. Better approach would be to go with the greedy one by BlackVsKnight.
I used a greedy approach.
First of all, sort all intervals by start time (along with marking which one belongs to C/J). Now two consecutive intervals might belong to either same person or different person. The answer will atleast be the number of consecutive pairs with different person.
Answer will increase by 2 only when C looks after the child between two Js or if J looks after the child between two Cs. So I'll try to avoid these situations.
Code: here
For problem A in round 1C, I wasted about 1.5 hour but couldn't find a mistake (many WA attempts) in the approach. I am solving it with dp(index, required) which is index position am currently on and required pancakes, this outputs two values, firstly best answer and secondly last disc index included in this answer, second part is used to add new disc area to existing stack. Finally required answer is DP(n-1,k).first.
I changed my approach at last to make it AC. But it will be really helpful if someone could guide me to the mistake in previous approach.
here is the code
We cannot use best result calculated for i + 1 disks and attach it to i'th disk. It may be so that we need to take a disk with a smaller surface area on the i + 1'th place.
Please check the code, the fault is not in the algorithm, I am taking care of it in dp state traversal.
I look through the code several times and I don't yet understand how do you handle that.
The problem with that approach, is that in the intermediate calculations, you might choose to ignore a stack that is part of the best output, in favor of another stack that appears better at the time.
That is because the score at any moment, is dependent on both the side surface area, and top surface area. And since the top surface area changes as we go back up in the recursion (by adding larger pancakes to the stack), we can't really depend on it while choosing which stack to proceed with.
I guess it's better explained using an example.
In the first case, your code will tend to choose the second pancake (5, 1) over the first (1, 15) as alone it has the larger surface area.
In the second case, your recursion will lead you to the same case as the first example, and yet again choose the (5, 1) pancake, while it's better to choose the (1, 15), due to the presence of the third one. .
Thanks, will check if it works for given examples.
How do I solve C small-2 (in round 1C)
I used adding an increment of 0.00001 unit to the lowest priority core in a priority queue repeatedly to solve C small-1
I tried a similar one for small-2 ( choosing top k cores for prirority queue) but it failed..
How to solve "Ample Syrup" in linear time?
I might be wrong but here is my guess, let's take K pancakes with maximal side surface. Then we can prove that in optimal answer there will be at least k — 1 from this set. So we just see which one has maximum upper surface in this set, and change it with one pancake from other N — k pancakes, at a time and see if answer is better. It is O(N).
EDIT: To make it clear, you don't necessarily remove bottom pancake from those K pancakes, you just choose different pancake from other N — K ones to be the new bottom and remove the one with minimal side surface from starting K pancakes.
Cool!
How would we pick K pancakes with maximal side surface in linear time?
It is a well known problem, you can find worst case linear time algorithm here. Also there is expected linear time algorithm which is simpler, I guess.
Thanks for the info, didn't know there was a linear approach for that problem.
What is displayed on 2017 shirt ?
I think it is the Samuel Beckett Bridge.
Has anyone received their t-shirt yet?
I received it 3 weeks ago.
Do you get a notification of when it is going to arrive?
It's delivered by DHL (at least in my country). If so, a courier will call you.
Thank you!
Received two days ago.
Do you get a notification of when it is going to arrive?
I got my shirt three days ago, no notification.
Thank you!
To DCJ finalists: Is anyone free on GCJ competition day?
I'm planning to travel around the city but currently I don't have anyone to go with (the other 4 Japanese finalists are all GCJers).
I didn't receive my shirt yet, Is it normal to be that late?! Is anyone else also didn't receive his/her till now?!
I haven't received mine either.
If anyone still cares, just a quick update: I got an email that my T-shirt is in transit.