


Hello everyone!

27 May, 12:35 MSK new codeforces round takes place for participants from the second division. Participants from the first division can participate out of competition. Round consists from 5 problems, and you will be given 2 hours to solve them. Pay attention on round start time.
The problems will be almost the same as on Open Olympiad of Mozyr State Pedagogical University, which takes part parallel to the round. The full problem set would be in codeforces gym soon. I am also going to tell you about the Olympiad a bit later.
- The problemsetters are: me (Vladislav Vishnevski), Valery Kameko (v4lerich) and Yury Shilyaev (hloya_ygrt).
- The testers are: Alex Kernozhitsky (gepardo), Arseniy Kolosov (KArs) and Ilya Klimko (klinchuh).
- The coordinator of the round was Alexey Vistyazh (netman).
- Alex Dryapko was reading the statements (sdryapko).
- And of course, the round would be impossible without Mike Mirzayanov (MikeMirzayanov), author of polygon and codeforces systems.
Thanks everyone for contribution you did to the setting of the round.
The main character of the round is Vladik, who loves to solve problems and himself.
Good luck to everyone! :)
UPD 500-1000-1500-2000-2500
UPD Editorial.






Can't register. Showing "rating should be 0...1899 to register ..."
According to your profile page, your rating in not is this range.
According to this post: Participants from the first division can participate out of competition.
"Participants from the first division can participate out of competition"
3 consecutive rated rounds from hloya_ygrt . Amazing.
well, there was only 1 problem of his in tinkoff challenge.
Is netman international grandmaster?
no
Might be they have prepared the post long back and drafted it.
Once a international grandmaster, alway a international grandmaster :P
What is MSPU Olympiad 2017 ????
looks like no one knows what is MSPU !
even google lol !!!
It's because the onsite contest is not very well-known, especially outside of Belarus. The contest is held in Mozyr, Belarus by a local university.
By the way, as it's mentioned in the post,
ty
Well, it's more like Vladik and friends wanted to organize an onsite contest for other highschoolers from Belarus. Since it happens on-site and Vladik currently lives in Mozyr (which is a minor town in Belarus with about 100k population), the only possible venue is the local university called MSPU. So that's why is's called "MSPU Olympiad".
None of problemsetters studies there (and none of then will, lol), so in other terms it has nothing to do with MSPU.
You can think of it as of a mirror of an onsite contest for Belarusian highschoolers, if it's more convenient for you.
Div 1 Users are not able to register. Update — It's fixed now.
Good start time , to prevent conflict between it and SnackDown Pre-elimination.
Is this contest rated?
Asking the real question: Is it also rated for Div1? (Nah, probably will be fixed soon)
Why people are downvoting my comment? Did I say something wrong or unnecessary?
I think all #codeforces_rounds are rated (if they did not say it is not) for people who are able to register so you should not ask about that every time :)
Not all contests are rated. I found that in previous contests. And whenever codeforces announces a contest they mention that if that contest is rated or not. But, in this post, they didn't say anything.
The best way to bring down your contribution is to ask the question "Is it rated?". Most of all contests are rated, and in the announcement of the contest autors always indicate if it is unrated. Welcome to CF:)
Unfortunately I am having a final exam tomorrow at contest time. I am thinking about not going to my faculty to be able to register =D
Do it bro, you can have the final exam another time so you have to register, even if the same thing happened again next year, register again and have your exam later { listen to me and say "Good Bey" to your future :) }
Something wrong with registration. When I registered, I wasn't considered "out of competition".
Just wanted to point out that the time link on "Codeforces Round #416 (Div. 2) has been moved to start on 27.05.2017 09:35 (UTC)." leads to The World Clock.
Codeforces round, Codechef May lunchtime and snackdown pre elimination all in same day == Busy day for me :3
And AtCoder Grand Contest 015 also :'D
Too bad the contest starts 30 minutes after the start of this round. :(
Edit: I had the time zones wrong, it's actually 30 minutes after the end of this round!
*end of this round
and Yandex.Algorithm round 2 also :)
hopefully short statements !!!
how about the scoring distribution ? UPD : fixed
Am I the only one who loves standard scoring distribution?
Am I the only one who is afraid of seeing the "double final-boss distribution" (500-100-1500-2500-2500)?
Submission stuck on the same pretest for over 8 minutes =/ Edit: fixed
Please write it to clars of contest, because we are not updating the comments often.
How is this suspicious? I have been through such moments. I code one task, it has some bug, I code another one and then it occurs to me how to fix the bug in the first one.
Fix the bug within 1 minute??
Yes.
He also used different headers for A,B,D and E,C
could anyone tell me if I can unregister from any contest after submitting one solution, or it is not allowed ?
Then your rank won't --; and it means that everyone here can do the same. So, no. :)
No, you can't unregister after submitting a solution.
C is little bit tougher than usual :(
This is becoming usual
This contest was awesome but I'm really afraid of systest!!!
:)
What is the hack for Div2B?
Time limit. O(n^2*logn) does not pass time limit. Generated random output on n=10000 that's it.
Does C++ solutions fail that too?
Yup, I hesitated at first, but than I saw hacks on B, now I have +10 ;)
Did same got 2 wrong attempts. Values of element I provided were in reverse. Does that affect sorting?
C++'s std::sort is fastest on reversed arrays AFAIK. I used "random_shuffle" for generator.
So the solution O(nm*logn) will pass?
I make a test case like this-
Full test case is here in this link.
This test case give me unsuccessful hacking attempt. Can you explain why It pass in 0.997 sec while in my pc (Operating System: Linux Mint 18.03 Processor: Intel Core i5 4th Gen, Ram: 8 gb) it takes 37 sec to run the same code in this test case ?
Add -O2 while compiling! It will run in < 0.5 seconds :)
You can make this hack successful. Try taking the first number last. I mean
9999 9998 9997 9996 ....... 5 4 3 2 1 100009999 9998 9997 9996 ....... 5 4 3 2 1 10000This case run in .904 sec in codeforce's custom invocation.
Whats wrong with randomization? :P
You can just write random_shuffle(p, p+n); :)
After coding a solution for C i understood that it's wrong. So, how to solve C?
dp[i] = max_sum with first i elements.
Can you give more details?
precalculation + DP
What was your approach? In precalculation, I considered all codes minimum and maximum(which can be influenced by other codes in between). I couldn't get an idea in DP
First calculate the beginning and ending of every segment and its comfort value then DP it by using DP(pos_of_the_seg_that_I'am_considring, the_pos_of_the_last_member_of_the_last_seg)
here's my code it might help you to understand: code
Thank you. my dp parameters were 3 so my dp table was 5000*5000*5000 and I could not think of anything else. Bye bye expert :'(
Hack case for B?
I just used counting sort, so i can't imagine a hack case except TLE one.
I solved in O(m * log(n)) :D
Me too.
n=1e4 and m=1e4 :p for each m , l=1 , r=1e4 :p this will give TLE for them who used sort ..
I tried that to some solutions, but failed :/
I tried that to some solutions ,but succeeded :3
O(nm) for counting sort is 10^8 operations, it goes in less than two seconds
How? since when 10^8 goes in less than two seconds?
I got Unsuccessful hack for hacking a solution in Problem B that sorts every time.
How ? Isn't the complexity for this solution O(n * m * log(n)) ?
Try to remove the log(n) factor.
noelnadal You didn't understand what I mean.
I am sorry for that.
NVM
The setters code works in O(n * m), but as you see some highly-optimized solutions in O(n * m * log) also passed.
hloya_ygrt Please look at Mohamed_Sakr'B code and tell me what is the complexity of this code.
My O(n * m) code in Python produced TLE, however the same passed in C++. There appears to be some issue in tester I believe.
Python is much slower than C++, so you were lucky and you didn't pass a case which was not the worst case.
Normally, the settings are normalized in such a way that the choice of language wouldn't matter. However, I guess there was an oversight in this problem.
Python is much more slower than c++.
Sorry, this time we couldn't guarantee that python solution will pass.
Why It wasn't mentioned in Problem statement?
His complexity is O(NM) That should pass! Doesn't matter which language he was using -_-
Lets make this round unrated -_-
Probably it is about participants should estimate their program's real time, not only complexity. The task was stupid itself and giving straightforward solution to pass would be even more stupid.
My expected case O(n * m) solution in C++ also got TLE. I cannot generate a case on my machine that takes more than 0.4 seconds.
http://codeforces.com/contest/811/submission/27374505
nth_element doesn't always works in O(n). Your amortized complexity is O(n * m) but worst case complexity is still O(n * m * log n)
Yes, I know. That's why I said "expected case".
The chances of it being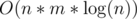 should be extremely low using a "median of 3" style approach.
should be extremely low using a "median of 3" style approach.
Use PyPy
compilerinterpreter next time: 27395525.What do you mean highly-optimized? Solutions which do exactly what is said in the statement get accepted.
Where did you get that information? :) The system testing is still pending.
Okay, I couldn't hack them with a maximum test was what I mean :D Let's see :)
Why O( n*m ) works? N,M <= 10^4, dont tell me solution that counts number of elements smaller than x after x and bigger than x before x in range gets AC. I tried to come up with something better...I even tried solving it with segment tree but I didnt found solution.
I think complexity of 100M (10^8) should be able to pass in 2 seconds. That's only 50M in a second which is passable.
Of course it depends on the code and language, but generally it should pass. I've seen some optimized codes where complexity of 100M passes in one second.
Thank you..I recognized O(n*m) solution quickly but didnt code it..poor me
I think, sort function can work faster than nlog(n) in some special cases. suppose if the array is completely sorted or sorted backwards. I too got Unsuccessful hack when I tried to hack with reverse sorted numbers like 10000 9999 9998.....
Then I tried random numbers and then I got successful hack for every solution that used a sort.
This is the response that I was waiting for.
I had that in my mind but I was tooooooo Lazy to generate Random Permutation :D
Its actually very easy to generate random permutation.
Suppose N=5000.
Put all elements from 1 to 5000 in a vector.
Then use random_shuffle() on the vector and print the elements in order.
The elements in your test case were in reverse order? If yes, C++ sort() works fastest for reverse order. A similar situation happened with me.
Yes that was the Problem, TY :D
How to solve E? I thought about counting how many components we add/subtract on every prefix/suffix and then using that we can answer queries, but I don't know whether that's correct.
how to solve D ?
Since there's guaranteed to be a path to finish, there has to be a . next to (1,1), either to the right or down, so you can check whether there is a swap on that direction. I assume I know that left = left, right = right, rest is symmetrical. Since there is a path you can go right until there's a '.' underneath you to test whether down/up are swapped. Right now you either reached the finish state or you have checked for both swaps. So you can get a path to finish state by using BFS and then just write all corresponding turns.
1, If (1,1) is not a good place to test if R and L is swap, then test D and U, then use the result to find a good place to test R and L.
2, If (1,1) is not a good place to test if U and D is swap, then test L and R, then use the result to find a good place to test U and D.
3, Use normal DFS/BFS with tracing to find the path.
4, Remember to terminate if you accidentally reach the finish square.
missed by a minute :(
just find out if Up and Down are swapped and if Right and Left are swapped then BFS it.
My code:code
nice problems, but I hate interactive problems.
After locking B I saw very easy solutions of B without segment tree :D
What is the solution for E? And what do people hack on B? I could hack only one guy who used a segment tree to answer queries :D
You can use the same idea as in APIO 2017 problem 1.
Where can I find APIO 2017 problems/solutions? Google didn't help.
Which case for B? I used segment tree too.
Max case :D
I got through pretests on E by using segment tree. Complexity: m*logm*n*alpha(n) (Not sure if it will pass)
Just maintain the component id's of left and right border of segment [l, r]. While merging two segments [l, mid] and [mid+1, r], you only need to find combinations along [mid, mid+1] You can do this this using dsu
There can be many component ID's along a border right? Can you explain more?
I think because n <= 10 so there are maximum 10 ID's along a border
Just wanted to know.
Is O(N*M*LOG(N)) passing for B?
Many people failed to hack the solutions with
std::sort.I tried to hack, but it works less than 2 sec. Can you explain hack test for std::sort?
I also failed (I typed exactly same code in custom invocation form and tried many cases but...)
It is, apparently. I tried to hack a guy who used that in my room. His solution ran in 967 ms. Idk why :/
I know what you probably used.
You probably did this ..
n = 10000 , m = 10000 all integers in inc order from 1 to 10000
and then l = 1 , r = 10000 , x = some random number
I believe it must be this .. or close to this .
Yeah, except that mine was reverse sorted. I found out that it's better to use random, but there's still no guarantee. I've seen the same brute-forces timing out on different test cases ~30. Some time out at 29, some at 35
Got some mysterious bug in D, and it's almost impossible to debug input which works when I test it and gets WA on first pretest.
And my 10+ wrong submissions don't even seem to appear in standings.
Did somebody get runtime error in Div2D on 5th test? What is kind of test?
Your program accidentally goes to the finish square, and your program must terminate (but your program didn't)
For problem C I got TLE on pretest 12, I understand the problem is : checking if it's ok to add segment [i,j] which work's in O(n) can it be calculated in O(1)?
I think it can be calculated in O(1). For every element(city) keep its least appearance and highes appearance. Now we will precalculate ok[i][j]. Go from i to j, and for every next element ask where its highest appearance and lowest appearance is. Also, keep track of how many elements are bad (we call element bad if it appeared from i, but its highest appearance is after current right pointer (right border). When highest_appearance[current_number] == current_index that means one element is not bad anymore, so cnt--. If at any point cnt ==0, than that range is OK, othervise its not.
What is the intended approach for the problem E? is it DP-like one?
The same algorithm for Div2B gave Time Limit Exceeded on Pretest 10 in Python 2.7 (http://codeforces.com/contest/811/submission/27381826), however passed for C++ 14 (http://codeforces.com/contest/811/submission/27386544). This is wrong behavior, right?
I ended up spending all my time on this :(
No, it is not wrong behavior :D Python is just slow :D
Just because cycles are really slow in python
Welcome to the disadvantages of python. I was gonna use python but then I thought as there was a tight bound to code in c++ only.
Yeah, I didn't realize that sometimes problems are not normalized to work irrespective of the choice of language. Not many python users here I guess.
however this code http://codeforces.com/contest/811/submission/27378308 is passing pretest 10
Didnt check B's constraints and used seg tree :/
I can understand that feeling :(
Can u explain me solution with segment tree? I tried to come up with seg tree solution but I couldnt because each query you are searching for elements smaller than x or higher than x, but x is different each time.
In each node of segment tree, store the numbers in the range start-end and sort it.
Now, when there's a query like: 1 100 50
Then split it into two ranges:
1. 1-50
2. 50-100.
In the first range find the number of elements greater than val[50](let it be x) and in the second range find the number of elements less than val[50](let it be y).
Getting this number can be done through binary search in the required nodes since the elements stored in each node are sorted.
If x==y, then position wouldnt change.
I am not experienced too much with seg trees. I never saw a seg tree whose node stores literally vector of elements. Isnt it too much that every node has more elements? also, can you send me code, so i can see implementation of that?
Code: 27377920, http://ideone.com/wHHPs1
It might seem that it might take too much memory but in reality it only requires NlogN memory since each element will appear in atmost logN nodes.
http://codeforces.com/blog/entry/15890 in this blog there is section segment tree with vectors. This could help a lot for your approach! Thank you for explanation.
Please start systest fast before AGC starts ;D
edit: denied :D
https://ideone.com/SlRErL
Can someone tell me what's wrong with my Solution for C?
If I understand right your code, you are wrong for two reasons:
First, you only make operation XOR to value iff
mx[ a[ i ] ] >= x && maxx[ a[ i ] ] == i, so if the previous sentence is ok you perform the XOR operation but all values between[ mx[a[i]], maxx[a[i]] ]that are different to a[i] and have amaxxgreater thanmaxx[ a[i] ]you doesn't include them, so it is wrong because for definition in the problem statement the XOR operation includes all different values in the segment [l, r].Second, if you find an
a[i]that havemx[ a[i] ] < x, you can't include the segment [ x, i ] in your current answer, because you never could take a valid segment that include all values equals toa[i].Maybe you have more mistakes but these are the most easiest to see.
My bad ,didn't read statement carefully and to add to it this logic was passing for 11 test cases so never bothered to read statement again.Bdw thanks for your help.I got it accepted by minor change.:(
http://codeforces.com/contest/811/submission/27391034 In case you want to take look . Thanks again
What is the intended solution for B?
Counting inversions (though I used
quickselect)?Won't using quickselect result in TLE?
I mean using quickselect will give you O(n*m) time complexity which is 10^8 in worst case. This idea came to my mind but I didin't implement it because of time constraint
Why would 10^8 not pass?
O(n * m) is fine because tl is 2 seconds, there is only simple operations like adding and comparing integers, and codeforces is very fast.
Actually, computers are so fast that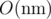 is absolutely fine with n,m ≤ 10000.
is absolutely fine with n,m ≤ 10000.
My solution with quickselect got TLE: http://codeforces.com/contest/811/submission/27376379
As did mine: http://codeforces.com/contest/811/submission/27374505
Notice the TLE case, though. It may be that nth_element is not well implemented in the standard library linked by codeforces, since it appears to only TLE for reverse sorted data.
You can just count how many elements are smaller than p_x in that range, and thereby check if position stays the same.
Can you please elaborate on how to calculate elements smaller than p_x in a given range efficiently?
I just calculated it with linear scan, pretests passed in 31ms.
My solution was based on a segment tree, were each leaf stores respective sorted segment of original sequence. So, complexity is perhaps O((m+n) *log(n)). (build () in n*log(n) + answer m queries for log(n))
overkill.
I'm sure the query on your code is O(log^2(n)), for it to be logn it should use fractional cascading (not needed since it usually doesn't speed up much).
I thought during contest Maybe we can solve C using similar segment tree. And can we actually solve C using that?
I don't think so. Especially since some people got TLE using a set.
Can anybody help me figure out the reason behind memory limit exceeded in Problem D? http://codeforces.com/contest/811/submission/27386058
Maybe that is not a memory limit exceeded but a runtime error; those two errors usually not classified correctly.
I'm not sure, but you should do this ans[p.a][p.b] = p.ch; when you push node to queue
How come O(n*m*log(n)) solution is passing for the problem B?
Same question! I attempted to hack one's code but failed! O(nm log n) algorithms terminated in 1.2 seconds in the worst case!
My poor 50 pts...
Shouldn't O(n√nlogn) MO's algorithm or O(nlogn) functional segment tree be the intended solution?
Why the bruteforce passed?
Because n,m<=10^4.
Intended soln was O(N*M) bruteforce because 10^8 fits in TL.
Yes, it did, but should it? And what about O(nm log n)? Then I get nothing more but less pts because of MO's algorithm and Binary Indexed Trees?
Because its generally known that upto 10^8 operations would fit in 1-2 secs.
I too used seg tree because I didnt check the constraints properly.
I dont like this question too.
Sorry for bothering but... Is it generally known that up to 10^8 operations would fit in 1-2 secs? Am I out? For long time the number was 5×10^6 for me……
Answer by yeputons: here
Also check this: http://codeforces.com/blog/entry/21772?#comment-264557
The entended algorithm is O(n * m). I also tried to hack a O(n * m * log(n)) solution (which theoritically results in 10^9 operations) but my hack was unsuccessful. I wonder if codeforces servers are that fast.
This problem should be problem D with n,m <= 10^6. I solved with Merge Sort Tree O(m log^2 n), and then wondered how a merge sort tree problem can be solved by 2800+ contestants :|
Yeah, I finished MO's algorithm at arount 00:36, but I found that a lot had finished way before that!
But I think MO is overkill :3
Exactly, I was making a segment tree but the same thought entered my mind. How can a segment tree problem be listed B in a contest.
Haha! I was thinking that, too...
====My thoughts====
Ahh, an easy functional segment tree or MO's algorithm problem.
Wait a minute, is it a B?
Is there an easier way to do it? It is just a B!
O(n^2)? If so, then why not n=10^3 & m=10^3?
There must be traps...
====3 minutes later====
Whatever... MO's algorithm for safety...
====After an unsuccessful hack====
WTF?????????????????????????????
No, it's too simple even for c.
I think the intended solution was brute force O(n*m) but the solution with complexity O(n*m*log(n)) should fail cause it extends upto 10^9.
Yes, i think actual solution should be either MO's or segmented trees. But in previous contest too many times solution with 10^8 complexity pass very smoothly.
Alright... resonable... but still... unhappy :(
I tried to hack a solution with O(n*m*log(n)) complexity and the person had used vectors instead. But it passed with in 0.8 despite the fact vectors are too slow than arrays.
So felt terrible.
Can we solve problem E using Mo's Algorithm?
I like your idea, we can try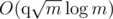 , which seems okay to me.
, which seems okay to me.
dsu-on-buckets-sized-sqrt(n). It would be something likeWould you mind to further elobarate on your idea? I don't quite understand how could you break the DSU apart when you are "shrinking" the interval.
I don't think so. But you can solve it with a segment tree.
please start system test.
Solved 1 problem in last 2 rated contest, Then solved 2 problems in next contest, >>>>> unfortunately that was unrated.;( ;(
Finally a rated one... Can't wait for the ratings to be updated,
Please Finish the system test, for God's sake.... solved 2 problems.
Codeforces Servers
Radioactive Chernobyl' potato and 0.0000001 nm microprocessors.
Rating does not matters there when you are not a grandmaster and can't receive money from Botan Investment. Two problems div. 2 solved are not enough to become a grandmaster. So, you should not worry.
I tried hacking several O(n*m*log(n)) solutions using a full test case of just 1,2,3,...10000 (permutation in sequence).
On my own PC this test case takes 30 seconds, but all my hacks failed. Other people hacked those solutions later with "random" large case instead of sequence 1,2,3,4...10000.
Then I compiled my slow test case with "-O2" and it runs in 4 seconds on my PC instead of 30.
So the question is, what all does C++ sort() in "-O2" flag optimize, besides "numbers already sorted"? Does it check for "reverse sorted" and "almost sorted"? Thanks.
Always use this: http://codeforces.com/problemset/customtest when you want to check execution time.
"I am also going to tell you about the Olympiad a bit later." When??
How to solve C?
dynamic programming:
d[i]-> maximum comfort of people numbered 1..i (or i..n)First we find the first and last occurrences of numbers in the array (not just a [i] <= 1000). Then, for each number, look for the beginning and end of the segment, which must enter if we take this number. Thus, we have an array of pairs of possible segments, which are sorted by their beginnings. Obviously, if the beginning of one segment is inside the other, then the entire segment will be in it, so we need to either take each segment completely or split into sub-sections (choose the largest from this). This can easily be done recursively, for example. one segment is inside the other, then u
I was sure 10^8 cant fit in 2 seconds. I came up with O(n*m) idea very quickly but I didnt code it since I thought it wont pass...cri
Why did I got TLE 27376612 works in O(m * n * logn).Please hepl..
Shouldn't it?
10^4*10^4*log(10^4) = 1,3 * 10^9 (it is average)
How to take in C take account of xor of unique elements in a range ???? I used set and it gave TLE :( So stupid of me
Just replace set with simple array.
And maintain a vector to remember which elements have been encountered ???
Yes, it's called counting sort. https://en.wikipedia.org/wiki/Counting_sort
since a xor a = 0, then ( a xor a) xor a = a. So if you have even number of same elements in range, just do one more xor on same element. Othervise, if there is odd number of same elements in range, xor all of them and answer will be correct.
I do not know but array did not work :( Unordered map did !!! Thanks for help :)
ai ≤ 5000 you could use array
I used Map :( I got tle on main tests, FUCK Using Array it ran in 61ms :(
I dont like Nicki Minaj :(
I like Taylor Swift
I like guys
Care to share the reason?
I used map and it also passed. It also takes log n time. Here
I used unordered map then got AC but TLE in normal map :(
Why does using set give TLE?????
How to solve problem B if constraints were 1 <= n,m <= 10^5 ?
You can use segment tree, approach was described earlier http://codeforces.com/blog/entry/52186?#comment-362512
Or even better — use a persistent one. This way you get an O(mlogn) solution instead of an O(mlog^2n) one, I would put my bets on this being the fastest solution. (I doubt someone can comeone with a linear time solution though — It's quite crazy)
Forgot to terminate the program in some cases, got idleness limit exceeded XD
I think I remember to terminate, but still got this http://codeforces.com/contest/811/submission/27385612
Can someone tell me why?
What I did, was to read the x y after printing the direction and if x or y equals -1 then stop the program.
It seems that you should still be reading the input when you output your solution after bfs (even though you it doesn't change your solution in any way). So in your last while loop you should be reading x and y in every cycle.
Got RTE in D because I didn't remove asserts :'(
anybody knows the reason for getting WA on Test-49 of C ?
I stress tested your code and it fails on this test:
Answer is
9.got it. Had made a silly mistake :( Thanks :)
How to write a stress test?
http://codeforces.com/blog/entry/44493
Would you be so kind to stress mine aswell? Can't figure out why my solution gives a slightly greater answer for #20 than expected.
I think you did the same mistake as I did. Here is the case:
Answer is
1. But your code prints 0.how is it 9?
take only segments with 4 and 5. They sum to 9.
I solved 4 problems but it says 2 out of 5. Is anyone else facing the same issue?
Same here.
I faced it several times before. It will be OK after a while.
That awkward moment when you spend half an hour explaining your O(msqrt(n)) solution for B to your friend, but their O(nm) solution also got AC.
Edit: it should be O(msqrt(n)log(n))
How to go about an O(msqrt(n)) solution?
I could only think of O(msqrt(n)log(n)) solution using Mo's Algorithm + BIT. While you are processing each query using Mo, maintain a BIT containing the occurrence of each number from L to R, and use it to answer each query.
How to remove the log factor from BIT ?
It can be solved in O(Q * log(N)) with offline algo.
Yes I'm aware of that. But I'm curious about maintaining the occurrence of numbers in Mo's query in constant time though.
Compress the numbers and use sqrt decomposition. Since update is O(1) complexity will become O(Q * sqrt(N)).
How did u solve it? Mos algorithm? I thought maybe there is mos algorithm solution because constraints looked perfect for it.
Can anyone help me to find the error, in problem D? 27388425
You may step on a dangerous cell when you "check for left_right". Once you step on a dangerous cell, you will lose the game. So you might lose the game on the first step. Here is my code http://codeforces.com/contest/811/submission/27381946 (How can I paste my code like you?)
Thanks for reply. For share your code, there is a bar icon in comment box. Here you can select the submission and paste your submission id(like 27381946)
Oh I get it.
It gave me TLE on case #87: 1 2 0 0 .F But I tested and it does in 3 moves, and the limit would be 2*1*2 = 4
Was this contest rated or not????
Yes, it was.
So why it's taking longer than usual for the change..!!
Because it is usual? o_O
Can anyone explain what was wrong in the following approach for problem C. I tried to break the problem into a weighted job scheduling problem. The start and end times for jobs are the minimum starting and maximum ending index of each element . The profit is the xor of non individual elements taking each element only once in an interval. Then our goal is to maximize the sum of xor of non overlapping intervals which is the same as job scheduling . My solution was failing on testcase 12
Why wa here? please help http://codeforces.com/contest/811/submission/27379669
Problem D, Idleness limit test 70?
I had submitted this(http://codeforces.com/contest/811/submission/27386058) solution during the contest for problem D(811D - Vladik and Favorite Game). In the test case 6, there is no 'F' in the input given. In the problem, it is stated that there is exactly one 'F' to be given in the input. Am I missing something?
It is present. The complete testcase isn't shown because of its big size..
Oh! Did not realize that. Thanks.
there is 50x50, at the end ..., so F is below
How to solve D? I attempted below implement but WA(My English may not be that good to explain clearly):
We start at a corner, there are 2 "edges", there must be a solution so at least one direction is '.', we can try that direction and get the result(wether moved or not).
Implement a BFS and find the right path to 'F', there will be 2 situations:
1.we keep on going "on an edge", then one direction would be enough
2.we leave the edge at some moments, it means there will be a corner, we can apply the methods above again and get both directions right.
Seems right, but WA. Am I having wrong idea or just buggy code?
27384993
Probably due to buggy code.
I used the same logic.
Thanks, and excuse me, what's the meaning of:
Checker comment
wrong output format Unexpected end of file — token expected
"token expected"??? What token should I output?
I'm guessing its because your program terminated before reaching end point.
When checking if the direction is correct/wrong and if its wrong, your position will be the same so you will have to repeat the move with the opposite direction.
If you havent done this, I guess it might be the cause of the error.
Thank you. I found my bug! I forgot a "return" in my function and values of x and y were updated twice... Feeling worse... I didn't find it during the contest but till now.
Append: the correct one
27390186
We can find a path from (1, 1) to 'F' using bfs, and then we have to check whether left-right( call it swapl) or up-down (call swap swapu) are swapped or not, and then print the path according to new left-right and up-down.
To find the swapping :- As there always exists a solution so you can find either swapl or swapu is true.
Suppose we can go to (1, 2) then we will print 'L' and check if it moves to (1, 2) then swapl is true ( Similar is the case for swapu if we can move to (2, 1) )
If we cannot go to (1, 2) then we will go down till we find place when we can move from (i, 1) to (i, 2) and check again similarly as described above. Same is the case with finding swapu.
Refer this Most of the things are similar so it's just copy-paste with few changes.
Can you explain how to handle case like
.*..
....
...F
what happens if I press 'D' as first button pressed, but 'R' and 'D' have been interchanged.
The problem stated that only the LR and UD can be swapped with each other.
In that case, it's quite easy to be div2 D, and < 500 accepted submissions. What am I missing?
The statement was overcompicated and Im sure a lot of participants didnt even get what they had to do in that task. :(
Sorry but this problem isn't harder than div2B.
Well, my solution for Div2B is nearly 10 lines, and no thinking was required to code it. My solution for Div2D is nearly 250 lines with a lot of corner cases, and you're saying that it was easier than B...
No, I didn't say that. I just meant in terms of difficulty of concept, it's not harder than div2B in general. I'm not comparing it with this round's B.
I'm not able to disagree, but the setters arguments were that this task had at least small idea and a bit complicated realization.
Of course we didnt try to make a statement harder, but many of the participants misread it due to some reason and probably tried to solve an no-solution version of the problem. Sorry about that.
Even I misread, probably because the actual problem is too simple, and I assumed some hardness from my side. Contestants misreading statement doesn't make the problem hard though.
Anyone else got WA Many requests even though number of request shouldn't be big? (While debugging I inserted
return 0after second request. EDIT: Apparently, I just forgot to comment debug stuff. :DChange it to:
You can delete line with
fflush(stdout);, because you doendl.endlin C++ always do something likefflush(stdout);.True. I'm used to using fflush(stdout); because I have this in my code:
#define endl '\n'Vladik MikeMirzayanov 811B - Vladik and Complicated Book I submitted python code and got 27390552 TLE same algorithm, with same complexity in C++ got 27390500 accepted. Any idea was it bug or it happens every time ? Isn't time limit different for different languages ?
Python is a slow language, so it can get TLE on such problems (there are 108 operations). So it's better not to write problems that consume much operations.
No, unlike contests like USACO, CF has one time limit for all the languages.
P. S. Problemsetters try to make TLs for easy problems in the way that Python solution pass. But it's impossible for this problem, else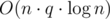 codes pass easily and the authors tried to avoid this.
codes pass easily and the authors tried to avoid this.
In Q-2 constraints of test case and question didn't match . I got T.L.E in test cas 29 which contains 6*10^4 but in question constraints were 10^4 . Please correct your test cases.
it's 6*10^3 actually
6000 is not 6·104, it's 6·103. So the tests are correct.
Why did O(n*m logn) didn't pass can someone help me ??
Because the correct solution is O(n*m)
I mistake a variable and it even passed pretest... thanks for weak pretests.
just fyi pretests are meant to be weak
Wtf? We didn't make any effort to make those pretest weak. There are 13 random large and small tests there and it's not our fault that your solution with a bug passed them.
Found the Div2 C problem confusing. Can somebody please explain the question.
Choose non-intersect segments with values of its XOR sum, each segment must contain one or more whole color set(if one color 'a' is in it, then all other 'a's must be in that segment too). Maximize the sum of the values.
But how do we make all possible intervals? Shouldn't there be O(n^2) possible intervals (for example when input is 1..5000)? In test 1 it would've been: [4, 4], [4, 4, 2, 5, 2], [4, 4, 2, 5, 2, 3], [2, 5, 2], [2, 5, 2, 3], [5], [3]
So total complexity would've been O(n^3).
I just solved it without making all possible intervals in O(n^2), for example, in test 1 my solutuion only considers intervals: [4, 4], [2, 5, 2], [5], [3]
I don't get why this works.
Is that because taking sum of two numbers allways gives greater result than XORing them?
Yes, a + b = (a XOR b) + (a AND b)*2
Codeforces Round #416 (Div. 3)
Problem X
This is an interactive problem.
[Vladik and Unsuccessful hacks]
Valera was participating Vladik's contests. He found an O(nm log n) implementation on problem B.
He tried to hack the solution but failed so his ratings dropped.
Now, the task goes to Vladik. Given problem B, your program should output a testcase which can defeat the O(nm log n) code (preventing it from terminating in 2 seconds).
problem B:811B - Vladik and Complicated Book
Output
First line contains two space-separated integers n, m (1 ≤ n, m ≤ 104) — length of permutation and number of times Vladik's mom sorted some subsegment of the book.
Second line contains n space-separated integers p1, p2, ..., pn (1 ≤ pi ≤ n) — permutation P. Note that elements in permutation are distinct.
Each of the next m lines contains three space-separated integers li, ri, xi (1 ≤ li ≤ xi ≤ ri ≤ n) — left and right borders of sorted subsegment in i-th sorting and position that is interesting to Vladik.
Input
For each mom’s sorting on it’s own line print "Yes", if page which is interesting to Vladik hasn't changed, or "No" otherwise.
Interaction
To finish output buffer (i. e. for operation flush) right after printing testcase and newline you should do next:
fflush(stdout) in C++
System.out.flush() in Java
stdout.flush() in Python
flush(output) in Pascal
read documentation for other languages.
output
5 5
5 4 3 2 1
1 5 3
1 3 1
2 4 3
4 4 4
2 5 3
input
Yes
No
Yes
Yes
No
Use custom invocation in order to avoid this kind of stuff. It's not that hard to generate a sequence that forces O(nmlogn) to work more than 4 secs. Actually, one random shuffle applied to a natural order was enough :)
Really? Shouldn't a descending-order sequence be the worst case of STL sorting? It just took 1.2 seconds...
My data looks like this:
10000 10000
10000 9999 9998 9997 ...
1 10000 9999
1 10000 9999
1 10000 9999
...
By the way, running time in custom invocation is accurate?
Yeah, that was my first thought, but it seems that std:sort somehow checks whether the array is almost sorted. I think it's accurate enough, but you should always account for minor sways that might infuence your hacking attempt negatively. Fortunately, in my case average running time was about 4.3 seconds against those 2 in time limit, so :)
You really made me laughing!
(Valera is masculine)
Sorry for that, fixed.
TLE in test-case 35.[ B category ]
please someone elaborate shortly what is the actual logic of "B" problem
You don't have to sort the queried interval — A simple counting is good enough, and actually sorting makes thing worser as sorting costs more time than counting.
If you are adventerous you could also scroll through other comments above to find some more efficient solutions.
Or you can "simply" write segment tree and solve it in O(mlogn) :D
My submission: http://codeforces.com/contest/811/submission/27377243
Would someone mind help me look at my code for Problem E? I suppose my code have a time complexity of O(N*(M+Q)*logM) with each merge action as O(N), but I suspect that I messed up part of the implementation thus causing TLE.
http://codeforces.com/contest/811/submission/27392571
Thanks in advance.
Editorial please :DD
In hacking section there is many successful hacks on problem B of today's contest, But I got two unsuccessful hacking attempt on this problem. And after system test finished, I see the submission I try to hack get TLE in system test. Then what is the problem in my test case ?
I Use a test case like this-
Full test case is here in this link.
This test case give me unsuccessful hacking attempt. Can anyone explain why It pass in 0.997 sec while in my pc (Operating System: Linux Mint 18.03 Processor: Intel Core i5 4th Gen, Ram: 8gb) it takes 37 sec to run the same code in this test case ?
there is using special key -02 for c++ in testing system. it optimizes code. If you want hack this task B you should use random array, his sort will be take more times(n*log(n)).
Almost the same as mine hack. I failed, too.
I took 14 secs on my computer... but 1.2 secs on Codeforces servers. :(
will there be an editorial?
Yes, it is finally out.
can someone help me in problem C the code gets TLE on test 60 27397952
One of my solutions of C is slightly wrong, but it passed.
newx2 = min( newx2, first_index[ a[x--] ] );is right, but I wrotenewx2 = min( newx, first_index[ a[x--] ] );I guess it's hard to create test cases that can catch every wrong program.
The data of problem C is not strong enough! My friend"s code fails in my data 5 1 3 1 3 2
http://codeforces.com/contest/811/submission/27394757 My code was accepted but can't pass the data.
when eitorials will be published of questions of this round
I'm new to codeforces here. I had participated in this round. I just want to ask how do we know when editorials of the round will be up. (I'm not entirely sure that the editorials are released was just hoping that they are)
Usually when the editorial is published the post is updated with its URL
27471809 This is my submission for Problem C Vladik and Memorable Trip.Getting WA on test case 29..Can anyone Point out my mistake..Thanks in Advance :)
Problem D doesn't match the difficulty 2100.