


Originating from Project Euler, Dirichlet convolution saw its use in optimizing the problem to compute the partial sum of some specific multiplicative function. This article is aimed to introduce the exact technique applied.
Prequisite
This tutorial can be viewed as an extension of the previous tutorial, so I recommend to take a look at that one first.
Dirichlet convolution
Dirichlet convolution is a way to generate a new function from two functions. Specifically, the Dirichlet convolution of two functions f(x) and g(x) is:
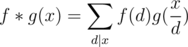
We already know that one property of such convolution is that if f(x) and g(x) are all multiplicative, f * g(x) is multiplicative as well. Based on the property of the Möbius inversion 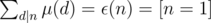 , we can also claim that
, we can also claim that 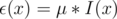 .
.
Optimization technique
Let's say that I wish to find the n-th partial sum of some multiplicative function f(x), i.e. I want to know the value of 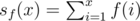 for a given n. Now let's pretend that I (miraculously) find a "magical function" g(x) such that both the partial sum of g(x) (denoted as sg(x)) and the partial sum of
for a given n. Now let's pretend that I (miraculously) find a "magical function" g(x) such that both the partial sum of g(x) (denoted as sg(x)) and the partial sum of 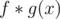 (denoted as
(denoted as 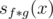 ) are (miraculously) very easy to obtain in O(1) time complexity. I can then perform the following trick to compute sf(x).
) are (miraculously) very easy to obtain in O(1) time complexity. I can then perform the following trick to compute sf(x).
Let's begin with the definition of the Dirichlet convolution:
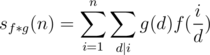
We can assume that i = pd, and sum things via p and d.
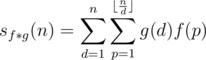
Now we can split the part where d = 1.
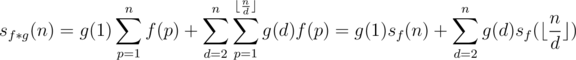
We can see that sf(n) has surfaced. Let's move all the rest of the equation to the other hand.
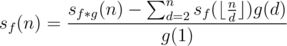
According to the harmonic lemma introduced in the last article, only at most 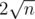 different elements exist for
different elements exist for 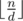 . We can thus recursively calculate the value of those sf(x), dividing the product
. We can thus recursively calculate the value of those sf(x), dividing the product 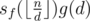 into at most different segments, and sum them up in
into at most different segments, and sum them up in  complexity.
complexity.
What is the overall complexity of the algorithm? If we implement a hash table to store every sf(x) we computed, then with the integer division lemma (see last tutorial), it is not difficult to observe that only these values 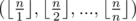 of sf(x) are computed. Since computing an sf(x) costs
of sf(x) are computed. Since computing an sf(x) costs 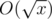 , the overall cost should be
, the overall cost should be 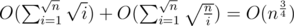 .
.
Upon now we have not used the interesting fact that f(x) is multiplicative. Come to think of it, we can actually use the linear sieve to pre-compute a few first elements of sf(x), omitting the need to process them recursively. Let's say that we pre-compute the first 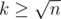 elements of sf(x). We can calculate the complexity
elements of sf(x). We can calculate the complexity
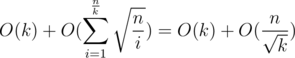
Apparently, when 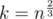
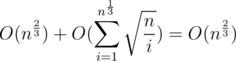
Hence, the algorithm is optimized to 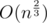 .
.
The following code gives a brief idea on the implementation of the technique.
/* Prefix sum of multiplicative functions :
p_f : the prefix sum of f (x) (1 <= x <= th).
p_g : the prefix sum of g (x) (0 <= x <= N).
p_c : the prefix sum of f * g (x) (0 <= x <= N).
th : the thereshold, generally should be n ^ (2 / 3).
*/
struct prefix_mul {
typedef long long (*func) (long long);
func p_f, p_g, p_c;
long long n, th;
std::unordered_map <long long, long long> mem;
prefix_mul (func p_f, func p_g, func p_c) : p_f (p_f), p_g (p_g), p_c (p_c) {}
long long calc (long long x) {
if (x <= th) return p_f (x);
auto d = mem.find (x);
if (d != mem.end ()) return d -> second;
long long ans = 0;
for (long long i = 2, la; i <= x; i = la + 1) {
la = x / (x / i);
ans = ans + (p_g (la) - p_g (i - 1) + mod) * calc (x / i);
}
ans = p_c (x) - ans; ans = ans / inv;
return mem[x] = ans;
}
long long solve (long long n, long long th) {
if (n <= 0) return 0;
prefix_mul::n = n; prefix_mul::th = th;
inv = p_g (1);
return calc (n);
}
};
Decoding the magic
Though we have finished discussing the algorithm, I have not yet shown how to find the "magic function". Unfortunately, there is no guarantee that such function exists in the first place. However, we can think about a question: how many functions are there that is very easy to compute the partial sum of it?
Few.
Certainly we know that 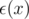 , I(x) and Idk(x) are all trivial functions that have formulas for their partial sums, but there are hardly any other ones that come handy in the form of the Dirichlet convolution. The fact suggests that we can apply a trial-and-error method to test these trivial functions until one of them satisfies the condition that is also trivial.
, I(x) and Idk(x) are all trivial functions that have formulas for their partial sums, but there are hardly any other ones that come handy in the form of the Dirichlet convolution. The fact suggests that we can apply a trial-and-error method to test these trivial functions until one of them satisfies the condition that is also trivial.
Still, if we know some property of the function f(x), we might have some other ways to work around it.
For instance, consider the Möbius function μ(x), we have already noticed that , which tells us to take I(x) as the "magic function". Another example would be the Euler's totient function 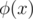 , we can prove that
, we can prove that 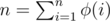 (with the "pk" method, i.e. show that
(with the "pk" method, i.e. show that 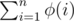 is multiplicative first, and then compute
is multiplicative first, and then compute 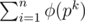 ), so
), so 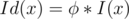 .
.
Example problems
Example 1. Find out the number of co-prime pairs of integer (x, y) in range [1, n].
Solution 1. We already know that
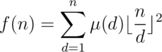
Now since we can calculate the partial sum of μ(d) faster, we are able to apply the harmonic lemma on the formula and optimize the loop to . Note that while we have to compute multiple partial sums of μ(d), the overall complexity is still if we do not clear the hash table, due to the fact that all values we plugged in is in the sequence , which are already computed while processing μ(n) anyway.
Example 2. Find out the sum of gcd(x, y) for every pair of integer (x, y) in range [1, n] (gcd(x, y) means the greatest common divisor of x and y).
Solution 2. Since
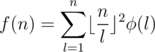
We just apply the optimization technique exactly the same as above.
Example 3. Find out the sum of lcm(x, y) for every pair of integer (x, y) in range [1, n] (lcm(x, y) means the least common multiple of x and y).
Solution 3. We know that
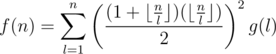
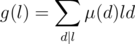
Now we just have to find a "magic function" for g(l). With a little luck, we can notice that Id(l) = g * Id2(l), and we just apply the optimization technique exactly the same as above.
(Should you be curious about the reason why Id(l) = g * Id2(l) holds true, the answer is still just the "pk" method: it is vital to show that g * Id2(l) is multiplicative, and simply calculating g * Id2(pk) will yield the result.)
Practice Problems
function
Counting Divisors (square)
Extension
Under some circumstances an implemented hash table might not be available. Fortunately, that does not mean you have to hand-code it for the optimization. With a little observation we can notice that all keys appearing in the hash table are in the form  . Therefore, if we use i, i.e.
. Therefore, if we use i, i.e. 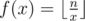 as the hashing function, we can prove that
as the hashing function, we can prove that 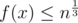 and f(x) never collides.
and f(x) never collides.







The previous tutorial is not accessable.
It appears that I accidentally saved it as a draft. The issue should be fixed by now. Sorry for the inconvenience!
Is not true that the sum of Euler totient is equal to n. Only the sum of totients of divisors of a given number is the same as the number.
Some practice problems, both for the above technique and similar ideas (e.g. Meissel-Lehmer), roughly sorted by difficulty:
EDIT: Never mind. Great blog!
__Now we just have to find a "magic function" for g(l). With a little luck, we can notice that Id(l) = g * Id2(l), and we just apply the optimization technique exactly the same as above.
(Should you be curious about the reason why Id(l) = g * Id2(l) holds true, the answer is still just the "pk" method: it is vital to show that g * Id2(l) is multiplicative, and simply calculating g * Id2(pk) will yield the result.)__
Nisiyama_Suzune, by solving the equation on pen and paper I got g * Id2 = Id2. But according to you g * Id2 = Id. Am I wrong? Can you please verify it?
$$$i=0->\sum_{d=0}^kp^{2k-d}$$$ $$$i=1->-\sum p^{2k-d+1}$$$