


909A - Generate Login
The most straightforward solution is to generate all possible logins (by trying all non-empty prefixes of first and last names and combining them) and find the alphabetically earliest of them.
To get a faster solution, several observations are required. First, in the alphabetically earliest login the prefix of the last name is always one letter long; whatever login is generated using two or more letter of the last name, can be shortened further by removing extra letter to get an alphabetically earlier login.
Second, the prefix of the first name should not contain any letter greater than or equal to the first letter of the last name, other than the first letter.
Thus, a better solution is: iterate over letter of the first name, starting with the second one. Once a letter which is greater than or equal to the first letter of the last name is found, stop, and return all letter until this one plus the first letter of the last name. If such a letter is not found, return the whole first name plus the first letter of the last name.
909B - Segments
Consider a segment [i, i + 1] of length 1. Clearly, all segments that cover this segment must belong to different layers. To cover it, the left end of the segment must be at one of the points 0, 1, ..., i (i + 1 options), and the right end — at one of the points i + 1, i + 2, ..., N (N - i options). So the number of segments covering [i, i + 1] is equal to Mi = (i + 1)(N - i). The maximum of Mi over all i = 0, ..., N - 1 gives us a lower bound on the number of layers.
Because the problem doesn't require explicit construction, we can make a guess that this bound is exact. max Mi can be found in O(N); alternatively, it can be seen that the maximum is reached for 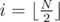 (for a central segment for odd N or for one of two central segments for even N).
(for a central segment for odd N or for one of two central segments for even N).
The answer is 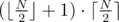 .
.
We can also prove this by an explicit construction. Sort all segments in non-decreasing order of their left ends and then in increasing order of their right ends. Try to find a place for each next segment greedily: if i is the left end of current segment, and segment [i, i + 1] is free in some layer, add the current segment to that layer; otherwise, start a new layer with the current segment.
and yes, this is our O(1) problem! :-)
909C - Python Indentation
This problem can be solved using dynamic programming.
Let's consider all possible programs which end with a certain statement at a certain indent. Dynamic programming state will be an array dp[i][j] which stores the number of such programs ending with statement i at indent j.
The starting state is a one-dimensional array for i = 0: there is exactly one program which consists of the first statement only, and its last statement has indent 0.
The recurrent formula can be figured out from the description of the statements. When we add command i + 1, its possible indents depend on the possible indents of command i and on the type of command i. If command i is a for loop, command i + 1 must have indent one greater than the indent of command i, so dp[i + 1][0] = 0 and dp[i + 1][j] = dp[i][j - 1] for j > 0. If command i is a simple statement, command i + 1 can belong to the body of any loop before it, and have any indent from 0 to the indent of command i. If we denote the indent of command i (simple statement) as k, the indent of command i + 1 as j, we need to sum over all cases where k ≥ j: 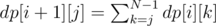 .
.
The answer to the task is the total number of programs which end with the last command at any indent: 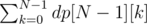 .
.
The complexity of this solution is O(N2).
909D - Colorful Points
We can simulate the process described in the problem step by step, but this is too slow — a straightforward simulation (iterate over all points when deciding which ones to delete) has an O(N2) complexity and takes too long. A solution with better complexity is required.
Let's consider continuous groups of points of same color. Any points inside a group are safe during the operation; only points at the border of a group are deleted (except for the leftmost point of the leftmost group and the rightmost point of the rightmost group, if these groups have more than one point). So, if current group sizes are, from left to right, N1, N2, ..., NG - 1, NG, group sizes after performing the first operation are N1 - 1, N2 - 2, ..., NG - 1 - 2, NG - 1, after the second operation — N1 - 2, N2 - 4, ..., NG - 1 - 4, NG - 2 and so on. This process continues until at least one of the groups disappears completely, at which point its adjacent groups may get merged if they are of the same color.
This way, multiple operations can be simulated at once:
Find the number of operations that are required for at least one group to disappear.
Update group sizes after this number of operations.
Remove empty groups.
Merge adjacent groups of the same color.
One update done this way requires O(G) time. During such an update at least one point from each group is deleted, so at least O(G) points are removed. If N is the initial number of points, we can remove at most N points in total. Therefore, running time of the algorithm is O(N).
909E - Coprocessor
We want to minimize the number of communications between main processor and the coprocessor. Thus, we need to always act greedily: while there are tasks that can be executed on the main processor right away, execute them; then switch to the coprocessor and execute all tasks that can be executed there; then switch back to the main processor and so on. This can be done using breadth-first search. To run reasonably fast, this solution has to be implemented carefully: instead of searching for available tasks at each step, we want to maintain two queues of available tasks (for main processor and coprocessor) and add a task to a corresponding queue once all tasks it depends on has been executed.
Alternatively, we can define Ti as the lowest number of coprocessor calls required to execute i-th task, and derive a recurrent formula for Ti. If u is a task and v1, ..., vk are its dependencies, then clearly for each i Tu ≥ Tvi because u must be executed after vi. Moreover, if vi is executed on the main processor and u — on the coprocessor, then executing u will require an additional coprocessor call. Therefore, Tu = maxi(Tvi + si), where si = 1 if u is executed on the coprocessor and vi — on the main processor; otherwise, si = 0. Now all Ti can be calculated by recursive traversal of the dependency graph (or traversing the tasks in topological order). The answer to the problem is max Ti.
909F - AND-permutations
Permutation p (pi & i = 0)
If N is odd, the answer is NO. Indeed, any number in odd-numbered position i pi must be even, otherwise the last bit of pi&i is 1. For odd N there are less even numbers than odd-numbered positions, so at least one of the positions will hold an odd number, thus it's impossible to construct a required permutation.
If N is even, the required permutation exists. To build it, first observe that (2k - i)&(2k + i - 1) = 0. For example, for k = 5:
100000 = 25
011111 = 25 - 1
100001 = 25 + 1
011110 = 25 - 2
and so on.
We can use this fact to always match 2k - i and 2k + i - 1 with each other, that is, set p2k - i = 2k + i - 1 and p2k + i - 1 = 2k - i.
The full procedure for constructing the required permutation is as follows. For a given even N, find the maximum power of two that is less than or equal to N 2k. Match pairs of numbers 2k - i and 2k + i - 1 for each i = 1..N - 2k + 1. If we are not done yet, numbers from 1 to 2k - (N - 2k + 1) - 1 = 2k + 1 - N - 2 are still unmatched. Repeat the process for N' = 2k + 1 - N - 2.
For example, for N = 18 on the first step we set 2k = 16 and match numbers 15-16, 14-17 and 13-18. On the second step unmatched numbers are from 1 to 12, so we set 2k = 8 and match numbers 7-8, 6-9, 5-10, 4-11 and 3-12. On the third and the last step the remaining unmatched numbers are 1 and 2, so we set 2k = 2 and match numbers 1 and 2 with each other. After this no unmatched numbers are left, and we are done.
Permutation q (qi & i ≠ 0)
We can do a simple case analysis for N = 1..7 manually, noticing that the answer is NO for N = 1..5, a possible answer for N = 6 is \textbf{3 6 2 5 1 4} as given in problem statement, and a possible answer for N = 7 is \textbf{7 3 6 5 1 2 4}.
If N is a power of two, then it is represented in binary as 10..0. We must have qN ≠ N, therefore qN < N, so the binary representation of qN is shorter than that of N. It follows that qN&N = 0, so the answer is NO in this case.
Finally, if N > 7 and N is not a power of two, the required permutation always exists, and can be built in the following way. Split all numbers from 1 to N into the following groups (k is the largest power of two which is still less than N):
1..7
8..15
16..31
\ldots
2k - 1..2k - 1
2k..N
For the first group use the permutation that we found manually. For each of the remaining groups, use any permutation of numbers in this group (for example, a cyclic permutation). The numbers in each group have leading non-zero bit at the same position (which corresponds to the power of two at the beginning of the group), so it is guaranteed that qi&i contains a non-zero bit at least in that position.







Woaaaaahhhh..Lightning fast editorial. Amazing. :)
This is the first contest ever in which I wrote editorials together with the problems, so they were ready even before the start of the round :-)
I always wonder that why all the problem setters don't do it this way in every contest?
I mean.. it will be so nice for both the parties. Not only we (the noob coders) will get editorials instantly but it might help the setter sometimes to get to know a mistake (if there is in a problem) while writing its solution. This will reduce the chances of a round getting unrated.
Anyways..you have done a great job.. One of the best contests on codeforces. Congrats for this. :)
Hi, can you provide code for problem D , it looks like a lengthy implementation , the algorithm was not very hard to come up with, also , love the B problem , felt it was a O(1) problem and I was not disappointed :)
Nice Nickolas <3
My solution of D: https://paste.debian.net/1002718/
As always, solution for a problem is quite easy but why I can't come up with it..
Anyway, thanks for great problems!
Really interesting problems, thanks! I wish I could solve the F, the solution was near but my brain was making circles around it so I didn't reach it.
Greedy simulation for problem B got AC
Did anyone solve D by another method : making a right arrays which stores the logical next element and making a left array which stores the logical previous element in array and then performing logical deletion by changing the left and right array values. Eg. _ a a b b_ _ left[i] {-1 , 0 , 1 , 2} ........._ _ right[i]{ 1, 2, 3, 4}_ .................... after one operation , left[i] becomes {-1,X,X,0} and right[i] becomes {3,X,X,4} and so on (by proper implementation procedure taking case of indices etc) and then count total number of steps(again proper implementation required). If anyone solved like this , please provide your code .
I solved that way, but we still need to "compress" the string or it will lead to TLE (my first submission made me realize it).
My code is not a beautiful thing, considering my hurry during the contest, but I've added some comments trying to help. http://codeforces.com/contest/909/submission/33698415
Thanks for the nice problems. Can you help me why recursive top down solution is failing on time on this solution?Link Is the constant time factor of creating recursion stacks that much?
well , time limit is a little strict honestly (not saying badly formed) , on top of that you are using java + recursion.. also memory is also O(n*n) which I think slows it down a bit more... It would have been better if n <= 3000 , the problem would still remain the same but some failed solutions would have passed ,
You have O(N2) dp states, and for one state you are doing O(N) operations here:
That makes your solution O(N3), so no surprise it is TL.
You have to get rid of that bad cycle and use prefix sums to get the value in O(1).
Thanks for providing editorial right after the contest!
I was hoping to find some magical connection between two unrelated subproblems from F at least here, but it seems that there is indeed no connection :)
Something quite similar to (A&B==0) subproblem appeared as a problem at CF in past: 288C - Polo the Penguin and XOR operation. Today I got a construction algorithm which sounds a bit different from editorial (I didn't check, maybe it gives same permutations as one from the editorial and I just approached it from the other end). Here is the code: 33686199, function run_solver_false is what we are looking for :) And below I'll try to give some explanation on what's going on there.
Let's take a permutation 2 1 4 3 6 5 8 7 10 9... first, to resolve last bit and p[i]!=i statement. Now let's fix bits one by one from lower to higher. In order to fix a bit X, let's take all positions for which this bit is broken and make a swap of p[i] and p[i-(1<<X)]. We know that (i-(1<<X)) will have 0 at position X, so we are not going to break stuff at that position — but we are still afraid that the number we'll get from p[i-(1<<X)] has 1 at position X as well.
One can check that it is not the case: in each block of size (1<<X) which we consider as a candidate for making a fix there is exactly one number with bad bit, and this number will always stay at second to last position in the block — we will put it there when constructing our base permutation, and then when considering a move at level X (which can possibly affect this number) number in the block to the right will be OK — it will be "bad number" of level X+1. For example: the only moment we can move 4 from position 3 is when trying to fix position 7, but we know that there will be 8 there and it will not need a fix. Generalizing it, the only bad number in block ends with 1000...00 (X times 0), and it will stay at place because the number ending with 1000...00 (X+1 times 0) to the right from it will not need a fix.
Could someone explain the solution to problem C. What is the dp array actually storing?
dp array is storing the ways in which a level of indentation can be reached at the n-th instruction.
for example, lets start with the first line, the indentation level has to be lowest so the array will look like
1 0 0 0 0 ... 0 (n-1 times 0)
if it is a for instruction the possible indentation levels when the next instruction is received can only be '1' tab or '1' space. so the indentation can only be equal to '1', ie.
0 1 0 0 0 0 0 ... 0 ( n — 2 times 0 )
and similarly
and what is the logic behind other dp states??
Any dp[i][j] represents the ways in which the program can be written with the first i+1 instructions with last line having indentation level of j.
This holds for i = 0 Since the indentation can only be zero on the first line in one way.
This holds for any i by inductive reasoning. (You can verify this from the algorithm in the editorial. slycelote has also suggested a correction, please take it into account too)
So it holds at the n-th instruction. So dp[n-1][j] represents ways of writing the program with first n instructions with indentation equal to j.
As the indentation can vary from 0 to n we must add up all the terms do[n-1][j] as the program can end with any indentation level.
Hope this explained the problem
I wrote a blog for you click here
Sir, thank you for this excellent article. Without you I would not have been able to understand the solution of this problem
can someone prove that the lower bound we find in problem B is really the smallest number of layers ?
Well for the lower bound to be the smallest number we would need to prove that we can construct each layer such that each segment that covers the maximally covered area [i,i+1] is a part of each layer.
First off, note that the maximally covered segment is in the middle as a segment [i,i+1] is covered by (i+1)*(n-i) segments (taking one starting point <=i and ending point >=i+1). (There are two such areas when n is even)
Then we can construct a solution: starting from i=0 take any segment starting at i, and ending at n-i, and split that segment at some point. One of the segments will cover the maximally covered area. Repeat this for all such split points. increment i, repeat.
It is clear that every layer includes a unique segment that covers the maximally covered area, and every segment is included in one layer. Thus, as every layer includes a unique segment that covers the maximally covered area, the number of layers is the same as the number of unique segments that cover the maximal area, aka the lower bound. So the lower bound is the smallest number of layers.
If you think of the construction procedure in the editorial, you'll realize that the only time we add a new layer is when current segment [i, i + 1] is occupied in each of the existing layers. And that's exactly what the lower bound argument used.
An Elegant Sol to B :
Ref
Surely not as elegant as the O(1) solution!
B — Segment in Haskell
`
In Java
In C how time complexity is O(N*N)?
U can use prefix sum to calculate the summation instead, hence reducing the complexity from O(n*n*n) to O(n*n).
In problem (C — Python Indentation) output for the following input is 23. But how? I don't get it.
Задача С. Пронумеруем позиции в строке слева направо и будем в массиве А хранить количество вариантов программы, начинающихся на данном шаге написания программы с данной позиции. Рассмотрим очередной шаг написания программы. Если предыдущая команда "f", то следующая команда пишется со сдвигом на одну позицию вправо, т.е. количество вариантов, в которых последняя строка начинается в позиции 1 равно нулю, в позиции 2 — равно числу вариантов в позиции 1 на предыдущем шаге, в позиции 3 — в позиции 2 и т.д. Для всех i имеем A[i]:=A[i-1]. Если предыдущая команда "s", то следующая команда пишется либо в ту же позицию, либо в ЛЮБУЮ позицию левее, т.е. в данном случае для всех i A[i]:=A[i]+A[i+1]+A[i+2]+ ... и т.д. до последней возможной позиции начала первой строки на предыдущем шаге. После выполнения всех шагов написания программы нужно найти сумму вариантов для всех позиций начала последней строки. После написания первой строки A[1]=1, все остальные члены массива равны нулю. Далее N-1 раз повторяем описанный алгоритм нахождения числа вариантов начала последней строки в каждой из позиций. При чтении условия возникает впечатление, что соседние строки не могут начинаться с позиций, номера которых отличаются на количество отступов больше одного, т.к. в тексте задачи явно не сказано, что после завершения цикла следующая инструкция может начинаться с любой позиции с меньшим количеством отступов. К сожалению, приведённые примеры не позволяют избавится от такого заблуждения.
You can use this test case to debug your code:
In problem C, in the first input testcase given, the dp matrix formed by the given editorial will be : 1 0 0 0 1 1 1 1 0 1 1 1 0 0 1 1 and the final answer will be 2 but the answer in this case is 1. Can you please explain what am I missing here. Link to my code
Looks like the editorial has a typo, the actual recurrent formula is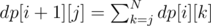 .
.
slycelote Thank you for correcting the typo. Please also provide some details about how we derived this recurrence if ith command is a simple statement.
As pointed out in the editorial, indentation of the command following the simple statement must be less than or equal to indentation of the simple statement. In the formula above, k is indentation of the simple statement, j is indentation of the next statement, and we sum over all k such as j ≤ k.
[user:sukhbhir947] Lets say you put the i+1th command with indentation k, then the ith command can only be with indetation k or k+1 or k+2 or .... n. So the number of ways of putting the command i+1 with indentation k will the sum of all the ways you can put the ith command with indentation k, k+1, k+2 ... n.
Hope it helps!
Thanks a lot!
Hello all, I need some help in understanding problem C's editorial. If ith command in the program is a simple statement then how did we derived the recurrence relation for i+1 th command.
if ith one is simple then no matter what is the current command we can indent it in any of the statements before the last indentation of ith command(maximum indent).
see if fffs then we are about to add f. As the maximum indentation of previous command (i.e. s) is 4 so, we can put the current f in any of the for loops or with that s!
Hope it helps.
for DIV-D : i didn't understand the time complexity part. We have G groups and at each step we remove 1 group and then update the remaining one. so, updating takes O(G-1) time (if we do linearly). so, complexity will be about O(G^2) ! I think that the size of groups reduces at each step and possibly that is the point i am missing. But can someone please provide any mathematical stuffs. will be a great help! :)
AND thanks for such a nice tutorial happy new year :)
Time complexity will be the sum of O(G) over all operations. At the same time, the total number of points removed will be at least the sum of G over all operations because for each operation we remove at least one point from each group. We cannot remove more than N points in total, so this sum is not more than N, and the sum of O(G) is not more than O(N).
Hey all Can someone please tell me the detailed solution of problem C (Python Indentation) I approached the question as a)if there are two 'for' statements (not consecutively) the total number of possibilities get multiplied by 2
b)if there are n 'simple' statements(consecutively) inside a 'for' loop then total number of possibilities increase by n-1 Please tell me my blunders in my approach.
can someone please explain the second approach mentioned in the editorial of E.
Do you have a specific question?
For Problem C Python indentation why is the final answer the sum of (j takes on all levels) dp[n-1][j],and where is the running variable k in the summation used?.(k=0 to N-1) Thanks!.
This is another typo. Sum is over all possible indents of the last command k, and dp[N - 1][k] is the number of programs which end with command N - 1 at indent k.
In the tutorial of the 909C-Python Indentation it's given that: "If command i is a simple statement, command i + 1 can belong to the body of any loop before it, and have any indent from 0 to the indent of command i:" But then the formula sums from i=j to n. Shouldn't it be from 0 to j?
If command i is a simple statement, indentation of command i + 1 must be less than or equal to indentation of command i. In the formula, k is indentation of command i + 1, j is indentation of command i + 1, and we sum over all k for which j ≤ k — this requires summing upwards from j, not downwards.
Thanks for the explanation. Appreciate that.
There is a slightly slower solution to D that will AC.
It is essentially an optimized simulation; we don't need to check the neighbors of every point, only the points that get new neighbors. Which are the points that get new neighbors? Well, these are just the points adjacent to the removed points (be careful not to mark a removed point as having a new neighbor).
We'll keep three sets: one with all the points, one with the points that have new neighbors (we'll actually need a current and a next for this set, and then use pointer swapping, but it's easy to think of it as just one set), and one with the points you are going to remove. On each iteration of the simulation, check if the points with new neighbors need to be removed, and add them to the remove set. Then, add their neighbors to the "has new neighbors" set. When you iterate over the "remove" set, just make sure you delete any of those elements from the "has new neighbors" set.
Each element can be removed at most O(1) times, and each of its neighbors will be added to the "has new neighbors" set, so there are at most n insertions to that set, and of course n deletions as well, so the amortized complexity is O(n logn).
Your solution is definitely easier to implement, but I think in some cases this might be easier to think of.
Can someone explain for Problem D:
Answer for input: bccdeefggiaacndddd
should be 2.
But according to solutions it is : 1
My solution for 2 is : (bc)(cd)(e(ef)g)(gi)(a(ac)n)dddd
Why should it be 2? Each point, except for the last 3 "d"s, has a neighbor of a different color and thus will be removed during the first operation; after that the points will be "ddd" and none of them have a neighbor of a different color, so second operation can't be done. Points do not have to be paired up to be removed
My bad!! Understood problem statement now.
Thanks :)
Here's an alternate construction for the second part of F. Assume we want a solution for some value of n that is greater than 6 and not a power of two.
If we have a solution for n - 1. We just find a power of 2 say 2p less than n such that n contains a 2p in its binary representation. Then we construct a solution for n by assigning the 2p in our previous solution a value of n and n the value that 2p had before the reassignment. We leave everything else the same.
Next if we don't have a solution for n - 1, but we do have a solution for n - 2 (i.e in the the case n - 1 is a power of 2). We just take our solution for n - 2 and put {n, n - 1} on the end and we have a solution for n.
Then we just use this process to construct a solution using the solution for n = 6 in the example.
For problem D , I use the set to maintain the remaining indexes which can be operate,but i got TLE on test 5. (:
I have a slightly different solution to problem D.
After making groups, we can observe that the simulation process cannot take more than $$$sqrt(n)$$$ "steps", because at each "step", we remove all values with equal ceiling function divided by two value, and the number of edge removals are bounded above by $$$logn$$$ "steps", so the overall complexity is $$$O(n(sqrt(n)+log(n))$$$ which is around $$$7*10^8$$$ operations for $$$n==10^6$$$, which passes in $$$33$$$ milliseconds.