


This is a complete English version of the editorial of Codeforces Round #153. If you have any questions or suggestions, feel free to post them in the comments.
252A - Little Xor (A div 2)
Let's iterate over all segments in our array. For each of them we'll find the xor of all its elements. Then we need to output the maximal xor we've seen.
252B - Unsorting Array (B div 2)
If all elements in the array are equal then there's no pair of numbers we are looking for. Now we can assume that there exist at least 2 different numbers in the array. Let's iterate over all pairs of different numbers in the array and for each such pair we'll check if it can be the answer. If some pair indeed can be the answer, we'll output it and terminate the program. Otherwise, there is no pair of numbers we are looking for, so we need to output -1.
It may seem that the complexity of described algorithm is O(N3). Actually it's not true and the real complexity is O(N). One may notice that in every array of length greater than 3 there are at least 3 pairs of different numbers (remember we assumed that there exist at least one pair of different numbers in the array). Note that these 3 pairs lead to 3 different resulting arrays. On the other hand, there are only 2 possible sorted arrays. According to the pigeonhole principle one of these 3 resulting arrays is unsorted.
252C - Points on Line (C div 2)
251A - Points on Line (A div 1)
Let's select the rightmost point of our triplet. In order to do this we can iterate over all points in ascending order of their X-coordinate. At the same time we'll maintain a pointer to the leftmost point which lays on the distance not greater than d from the current rightmost point. We can easily find out the number of points in the segment between two pointers, excluding the rightmost point. Let's call this number k. Then there exist exactly k * (k - 1) / 2 triplets of points with the fixed rightmost point. The only thing left is to sum up these values for all rightmost points.
252D - Playing with Permutations (D div 2)
251B - Playing with Permutations (B div 1)
First, we need to theck whether permutation s is the identity permutation. If it is, then the answer is "NO".
Now we'll describe an algorithm which works in all cases except for one. We'll tell about this case later.
Let's apply our permutation q until either the current permutation becomes equal to s or we make exactly k steps. If the current permutation is equal to s and we've made t steps before this happened, then we need to look at the parity of k - t. If this number is even, then we can select any two consequent permutations in the sequence and apply (k - t) / 2 times the following two permutations in this order: q and inv(q), where inv(q) is the inversed permutation q. Actually, we don't need to build the sequence itself, it's enough to check only the parity of k - t. So, if it is even, then the answer is "YES".
Analogically, we can replace q with inv(q) and repeat described process again. If we still didn't print "YES", then the answer is "NO".
The algorithm we've just described works for all cases except for one: when the permutation q is equal to inv(q) and at the same time s is reachable within one step. In this case the answer is "YES" iff k = 1.
The complexity of described solution is O(N2).
252E - Number Transformation (E div 2)
251C - Number Transformation (C div 1)
Let L be the least common multiple of all numbers from 2 to k, inclusive. Note that if a is divisible by L, then we can't decrease it with applying an operation of the second type. It means that any optimal sequence of transformations will contain all numbers divisible by L which are located between b and a. Let's split our interval from b to a into several intervals between the numbers divisible by L. It may happen that the first and the last intervals will have length less than L. Now we can solve the problem for the first interval, the last interval and for any interval between them. After that we need to multiply the last result by the total number of intervals excluding the first and the last ones. The only thing left is to add up obtained 3 values.
In order to solve the problem for one interval one can simply use bfs.
Be careful in the cases when we have only 1 or 2 intervals.
The complexity of described solution is O(L).
251D - Two Sets (D div 1)
Let X be the xor of all numbers in the input. Also let X1 be the xor of all numbers in the first collection and X2 be the xor of all numbers in the second collection. Note, if the i-th bit in X is equal to 1 then the same bit in numbers X1 and X2 is either equal 0 and 1 or 1 and 0, respectively. Analogically, if the i-th bit in X is equal to 0 then this bit in numbers X1 and X2 is either equal 0 and 0 or 1 and 1, respectively. As we can see, if the i-th bit in X is equal to 1 then it doesn't affect on the sum X1 + X2 in any way. For now, let's forget about the second condition in the statement which asks us to minimize X1 in case of tie.
In order to find the optimal value of X1 + X2 we need to make one more observation. Let's look at the most significant bit of number X which is equal to 0. If there exist such partitions of the initial collection in which this bit is equal to 1 in X1 then the optimal partition should be one of them. To prove this one should remember that the respective bit in number X2 is also equal to 1. Let this bit correspond to 2L. If the bit we are looking at is equal to 1 in both X1 and X2 then the smallest possible value of X1 + X2 is 2L + 1. On the other hand, if both X1 and X2 have zero in this bit, then the maximal possible value of X1 + X2 is 2L + 1 - 2 which is strictly smaller than 2L + 1.
We'll be solving the initial problem with a greedy algorithm. Let's iterate over all bits which are equal to 0 in number X from highest to lowest. We'll try to put 1 to the number X1 in this position and then check if there exists at least one partition which satisfies the current condition together with all conditions we've already set up. If such partition exists, then we can leave our newly added condition and move to lower bits. If there is no such condition, then we need to move to lower bits without adding any new conditions. At the end we'll find the maximal value of X1 + X2.
So, we have a set of conditions and we want to check if there exist at least one partition which satisfies all of them. For each condition for i-th bit we'll create an equation over the field Z2 with n variables, where the coefficient at the j-th variable is equal to the i-th bit of the j-th number. If some variable is equal to one then we take the corresponding number into the first set, otherwise -- into the second one. This system of equations can be solved with Gaussian elimination. Note that we don't need to solve the complete system from scratch every time we add a new equation. It's sufficient to recalculate the matrix from the previous state, which can be done in O(NK). Here K is the number of equations in the system.
Now we need to minimize X1 while keeping the value of X1 + X2 unchanged. It can be done in the similar way as finding the optimal value of X1 + X2. We'll iterate over all bits which are equal to 1 in number X starting from the highest one. For the current bit we'll try to put 0 in the corresponding position of X1. If after adding this condition our system of equations becomes incompatible, then we need to put 1 in this position of X1.
The complexity of this algorithm is O(NL2), where L -- is the length of binary notation of the largest number. For further optimization one can use bitset in Gaussian elimination, although it wasn't necessary for getting AC during the contest.
251E - Tree and Table (E div 1)
If N = 1, then the answer is 2.
If there is a node with degree greater than 3 in the tree, then the answer is 0. That's because every cell of the table has at most 3 neighbors.
If there is no vertex of degree 3 in the tree, then the answer is 2n2 - 2n + 4. This formula can be derieved in natural way during the solution of other parts of the problem. Also, one could write a simple DP to calculate the answer in this case. Anyway, let's prove this formula.
At first, let's solve slightly different problem, which will be also used in the solution of main case of the initial problem. We want to find the number of ways to place a tree in which all nodes have degree smaller than 3 on the table so that one node of degree 1 is attached to the upper-left corner of the table (let it be node number 1). It can be shown that if the table has size 2xK, then the number of placements of the tree is equal to K. The last formula can be proven by mathematical induction. If K = 1 then the above statement is obviously true. Suppose K > 1 and let's assume that the table is oriented horizontally so that we have 2 rows and K columns. If we put a vertex adjacent to the first one to the right from upper-left corner then we have only 1 way to complete the placement of the tree. If we put this vertex to the bottom-left corner, than the next vertex should be put to (2, 2) and the problem is reduced to the same one with K smaller by one. We have a recurrent relation f(K) = f(K - 1) + 1 and we know that f(1) = 1. This means that f(K) = K.
Let's come back to the initial problem of counting the nymber of ways to put a tree without vertices of degree 3 on the table 2xN. Without loss of generality let's assume that the first vertex has degree 1. We'll consider only placements in which the first vertex is laying in the first row and at the end we'll multiply our answer by 2. If the first vertex is laying in the first or the last column then then there are N ways to complete the tree (see the previous paragraph). If the first vertex is laying in the i-th column than there are i - 1 ways of placing our tree in which a vertex adjacent to the first one (let it be vertex 2) is laying to the left of it. Also there are N - i ways in which the second vertex is laying to the right of vertex 1. Adding up these values for all columns and multiplying the answer by 2 we get the final formula: 2n2 - 2n + 4.
Now we have only one case left in which there exists a vertex of degree 3 in our tree. Let's declare this vertex to be a root. If there are several vertices of degree 3, any of them can be chosen to be a root. We'll assume that the root is laying in the first row and at the end we'll multiply our answer by 2. Obviously, the root should be put to a cell with 3 neighbors. Each descendant of the root should be put either to the left, to the right or to the bottom from the cell which contains the root. Let's fix this ordering (to do this we need to iterate over 6 permutations). Also if the "bottom" son of the root has degree greater than 1, then we'll also fix the ordering of its adjacent vertices (there are 2 ways to do this). Now the column which contains the root is fully occupied. The last statement means that regardless of the way we place the rest of vertices, the ones to the right from the root will stay there. The same for all vertices which lay to the left from the root. Moreover, we have the fixed number of vertices to the left from the root, which means that there's at most one way to place the root on our table. Note that if the number of vertices to the left from the root is odd, then we won't be able to complete the placement. In order to find the number of vertices to the left from the root we need to sum up sizes of subtrees of its left descendant and of the left descendant of its bottom son.
So, we have two separate subproblems (for vertices laying to the left from the root and to the right from the root) and for each of them we need to calculate the number of trees to place the rest of our tree in the table. There are only two possible situations:
1) We need to place a subtree with its root in vertex v on the rectangular table in such way that vertex v is laying in the corner (let it be upper-left corner).
2) We need to place subtrees with roots in v1 and v2 on the rectangular table in such way that vertex v1 is laying in the upper-left corner and vertex v2 is laying in bottom-left corner.
Obviously, each of these two problems has non-zero answer only if total size of subtrees is even.
Let's show how to reduce a problem of the second type to a problem of the first type. So, if either v1 or v2 has two descendants, then the answer is 0. If both of them have one descendant, then we can solve the same problem for their children which'll have the same answer. If both v1 and v2 have no children, then the answer is 1. At last, if one of these two vertices has 1 descendant and the other vertice doesn't have any descendants, we have a problem of the first type for this only child of vertices v1 and v2.
The only thing left is to solve a problem of the first type. Let f(v) be the number of ways to place a subtree having vertex v as its root on the rectangular table. The size of this table is determined uniquely by the size of subtree. Let's consider two cases:
a) Vertex v has degree 2.
b) Vertex v has degree 3.
In the case when vertex v has degree 2 and there are no vertices of degree 3 in its subtree, then f(v) = s(x) / 2, where s(v) is the size of subtree with its root in vertex v. We've already proven this formula above. Now let's suppose that there's at least one vertex of size 3 in the subtree with root v. If there are several vertices with degree 3, we'll chose the one that is closer to vertex v. Let it be vertex w. We have 2 possible cases for it:
a.1) Path from vertex v to vertex w will go in such way that the vertex which lays before vertex w in this path is located to the left from vertex w on the table.
а.2) Path from vertex v to vertex w will go in such way that the vertex which lays before vertex w in this path is located to the top from vertex w on the table.
Its easy to show that there's no third option.
In each of two cases a.1) and a.2) we'll fix directions of descendants of number w (one direction is taken by the parent of vertex w, so there are exactly 2 possible directions). In case if descendant of degree greater than 1 is located in the same column with w, we need to fix directions of its descendants, too. After this we have problem of type 1) or 2) to the right of vertex w. To the left from w we have a tree which either can't be put on the table or can be put in exactly 1 way. In order to check this we need to look on the length of path from v to w and the size of subtree of grandson of w, which is located to the right from w (of course, if it exists). Now we need to sup up answers for all possible variants.
So we know how to solve problem of type a), when vertex v has degree w. The only thing left is to solve problem b), when v has degree 3. To do this we need to fix directions of its descendants and after that we'll have either a problem of type 1) or a problem of type 2), which were formulated above.
The complexity of solution is O(N).







is there editorial in English?
is there editorial about Div1.E ?
Now there is.
For the Problem A div 2 — i saw two kind of solutions.
In this code below it iterate over all segments in our array. For each of them we'll find the xor of all its elements. Then we need to output the maximal xor we've seen. code 2744731
In this code it does not do that and only find some of those. code 2702002
can anyone please tell me the deference of these two. Why is the second one correct. Why we need not to iterate over all segments.
Both solutions are iterating over all possible segments. The only difference is that the second one does it more efficiently. One can notice that the xor of all elements from the segment [a, b] is equal to the xor of all elements from [a, b — 1] xor the value of element on the b-th position. Thus, we don't need to calculate the xor of every segment from scratch, as we can use the values for the segments we've already processed.
DIV 2 PROBLEM B : "One may notice that in every array of length greater than 3 there are at least 3 pairs of different numbers"__ i do not understand this part .... suppose there ara two different numbers on the array and they are X and Y .... the rest positions of the array is filled with X. then we get : X X (X) X X (Y) X X X ..... here we get only two different pairs ... like : (X,Y) and (Y,X) as (X,X) is invalid for swapping .... then what does the line actually means .. ??
Is there an O(N) solution for problem A div 2 ?
well there exists an O(N * log(max number)) solution by using trie like the idea in problem 282e
For Div 2 E, will anyone please explain why this statement is true — " It means that any optimal sequence of transformations will contain all numbers divisible by L which are located between b and a." It is written in the editorial.
Suppose we managed to skip some number X divisible by L, which lies between B and A. Let Y be the last number from our sequence that is greater than X. There exists a number k such that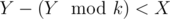 . However, L < Y and
. However, L < Y and 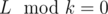 , which means that
, which means that 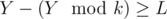 . We've got a contradiction, thus every number divisible by L, which lies between B and A should be in our sequence.
. We've got a contradiction, thus every number divisible by L, which lies between B and A should be in our sequence.
Can someone explain the solution of Div1 D with an example as how to use Gaussian elimination in finding the answer ??
in div 2 c could anyone explain why he use the equation (k*(k-1)/2) instead of using combination C(n,k)
k*(k-1)/2 = C(k, 2)
can we use dp in A div2?
Why kC3 (where k is the length of segment satisfying the constraint) is giving wrong answer for problem Div1 A ?