


Hello CF ! I don't understand the editorial or the solution to USACO 2016 Feb Plat P2, P3. Can somebody help me understand them ? Thank you so much for all your help !
Problem 2 USACO 2016 Feb Plat 2 Problem, USACO 2018 Feb Plat 2 Solution I understand that one has to use the idea of Kruskal, but why these lines are true (or what do they acutally mean) ?
Also, if we're connecting a row and have already connected k columns (for k > 1), then we only need to remove m−k fences in that row, since the columns we've already processed are guaranteed to be connected.
Doesn't it depend on which vertical fence you remove ? There are two cases, for the first one you need to remove 4 fences, and for the second one you need to remove 1 fences (note: the picture shows the graph, not the original configuration. Edges are Cell-Cell distance, and vertices are cells)
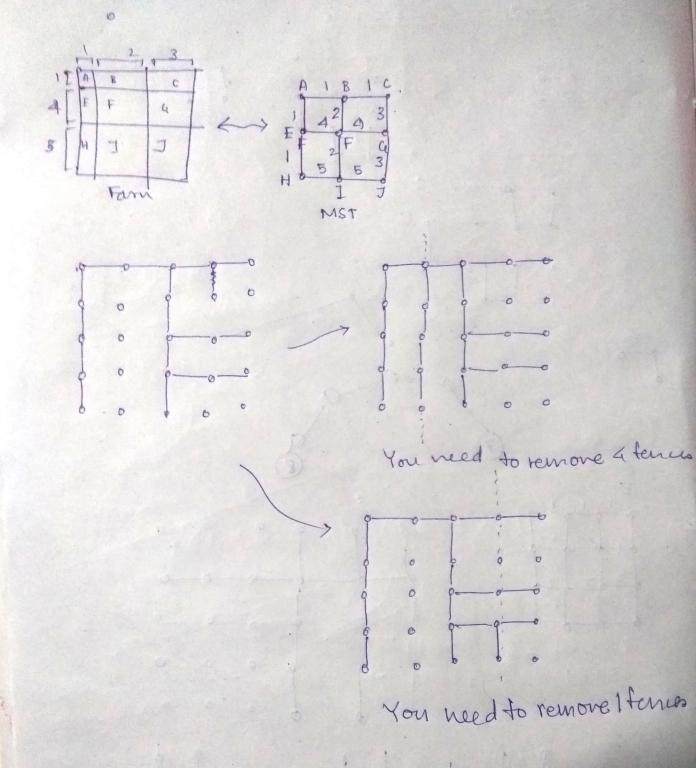
Another way to think about this problem is to note that, if we have an optimal solution, then the solution isn't affected by switching two adjacent rows or two adjacent columns.
What does this means ?
Problem 3 USACO 2016 Feb Plat 3 Problem, USACO 2018 Feb Plat 3 Solution For this, I understand and can come up with the O(N3K) algorithm with myself, but I don't understand how you optimize it to 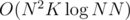 .
.
In the editorial, I understand all but this para:
We can compute the best solution using k doors via dynamic programming, iterating on k and adding one door at a time. We can use a divide-and-conquer algorithm to solve the linear version of this problem. The idea is that we can compute the middle values of the dynamic program first: if we compute the position to put our k-th door in dp[k][n/2], then dp[k][i] for i<n/2 must be to the left of that and dp[k][i] for i>n/2 must be to the right of that. In this way, we can on average halve the search space at each level of the recursion, so we don't have to do O(n) work to compute each value of the dynamic program. At each level of the recursion, we do O(nk) work, meaning the total runtime of this algorithm ends up being O(nklogn) for the linear version of this problem.
In particular, how you calculate dp[k][n / 2] without calculating dp[k][1], ..., dp[k][n / 2 - 1] first ?
PS: Here's a question my friend asked on CSE: https://cs.stackexchange.com/questions/101109/intuition-behind-floyd-warshall-being-faster. Can you answer it there/here ? I and him came up with the problem while discussing it.






Problem 3: dp[k][x] depends on dp[k - 1][1], dp[k - 1][2], ... dp[k - 1][x]. It does not depend on dp[k][1], dp[k][2], ..., dp[k][x - 1]. You don't need them. Probably you are not understanding DP definition.
Stackexchange thing: You are basically doing Bellman-Ford for each sources. I have no idea why you are thinking both are "similar" in any way, but they are very different. Bellman-Ford inducts on edge length, and Floyd Warshall inducts on the indice of middle vertices. Look up the proof of Floyd-Warshall (Yes, again you are not understanding DP definition).
People think Floyd is simple as its code, but in fact it has a very clever insight. You can't optimize the attached code blindly, without that insight.
Thank you so much for your reply ! I now understand the solution to the third problem (after googling "convex hull trick" )
For the Floyd-Warshall, (I think) I understand the proof of Floyd-Warshall.
What I don't understand is the clever insight you're speaking in the last sentence. If I am asked to come up with an algorithm to find all pair distances, either I'll come up the most obvious one (Dijkstra from each vertex, total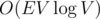 ) or the DP mentioned in that SE thread with complexity O(EV2), but DP on the middle vertex index will be the last thing that would come to my mind. We were asking for the intuition/insight behind how can someone come up with that.
) or the DP mentioned in that SE thread with complexity O(EV2), but DP on the middle vertex index will be the last thing that would come to my mind. We were asking for the intuition/insight behind how can someone come up with that.
Yeah, induction on the middle vertex is what makes Floyd-Warshall interesting. I didn't came up with it but just learned, so not sure what to say.