


Idea: Sulfox
#include <bits/stdc++.h>
using namespace std;
int t, a, b, c, d;
int main() {
for (cin >> t; t; t--) {
cin >> a >> b >> c >> d;
cout << b << " " << c << " " << c << endl;
}
return 0;
}
1337B - Kana and Dragon Quest game
Idea: EternalAlexander
#include <bits/stdc++.h>
int x,n,m,t;
void solve(){
scanf("%d%d%d",&x,&n,&m);
while (x>0&&n&&x/2+10<x){n--;x=x/2+10;}
if (x<=m*10)printf("YES\n");
else printf("NO\n");
}
int main(){
scanf("%d",&t);
while(t--)solve();
return 0;
}
Idea: EternalAlexander
#include <bits/stdc++.h>
#define maxn 200005
std::vector<int>conj[maxn];
int n,k,u,v,depth[maxn]={0},size[maxn]={0},det[maxn];
long long ans=0;
int cmp(int a,int b){return a>b;}
int dfs(int u,int f){depth[u]=depth[f]+1;size[u]=1;
for (int i=0;i<conj[u].size();++i){
if ((v=conj[u][i])==f)continue;
size[u]+=dfs(v,u);
}det[u]=size[u]-depth[u];return size[u];
}
int main(){
scanf("%d%d",&n,&k);
for (int i=1;i<n;++i){
scanf("%d%d",&u,&v);conj[u].push_back(v);conj[v].push_back(u);
}dfs(1,0);
std::nth_element(det+1,det+n-k,det+n+1,cmp);
for (int i=1;i<=n-k;++i)ans+=det[i];std::cout<<ans;
return 0;
}
1336B - Xenia and Colorful Gems
#include <bits/stdc++.h>
using namespace std;
int t, nr, ng, nb;
long long ans;
long long sq(int x) { return 1ll * x * x; }
void solve(vector<int> a, vector<int> b, vector<int> c) {
for (auto x : a) {
auto y = lower_bound(b.begin(), b.end(), x);
auto z = upper_bound(c.begin(), c.end(), x);
if (y == b.end() || z == c.begin()) { continue; }
z--; ans = min(ans, sq(x - *y) + sq(*y - *z) + sq(*z - x));
}
}
int main() {
for (cin >> t; t; t--) {
cin >> nr >> ng >> nb;
vector<int> r(nr), g(ng), b(nb);
for (int i = 0; i < nr; i++) { cin >> r[i]; }
for (int i = 0; i < ng; i++) { cin >> g[i]; }
for (int i = 0; i < nb; i++) { cin >> b[i]; }
sort(r.begin(), r.end());
sort(g.begin(), g.end());
sort(b.begin(), b.end());
ans = 9e18;
solve(r, g, b); solve(r, b, g);
solve(g, b, r); solve(g, r, b);
solve(b, r, g); solve(b, g, r);
cout << ans << endl;
}
return 0;
}
Idea: EternalAlexander
#include <iostream>
#include <string>
#include <vector>
using namespace std;
const int mod = 998244353;
int main()
{
string s, t;
cin >> s >> t;
int n = s.size();
int m = t.size();
vector<vector<int> > f(n + 1, vector<int>(m + 1));
f[n][0] = 1;
for (int i = n - 1; i >= 1; --i)
{
for (int j = 0; j <= m; ++j)
{
if (j == 0)
{
if (i >= m) f[i][0] = n - i + 1;
else if (s[i] == t[i]) f[i][0] = f[i + 1][0];
}
else if (j == m)
{
f[i][m] = 2 * f[i + 1][m] % mod;
if (s[i] == t[m - 1]) f[i][m] = (f[i][m] + f[i + 1][m - 1]) % mod;
}
else
{
if (i + j >= m || s[i] == t[i + j]) f[i][j] = f[i + 1][j];
if (s[i] == t[j - 1]) f[i][j] = (f[i][j] + f[i + 1][j - 1]) % mod;
}
}
}
int ans = f[1][m];
for (int i = 0; i < m; ++i) if (t[i] == s[0]) ans = (ans + f[1][i]) % mod;
ans = ans * 2 % mod;
cout << ans;
return 0;
}
Idea: Sulfox
PinkRabbitAFO gives another solution which inserts tiles with value $$$1$$$, $$$2$$$, $$$\ldots$$$, $$$n-1$$$, $$$1$$$ in order. See more details here.
#include <bits/stdc++.h>
using namespace std;
int n, s1, s2, t1, t2, d1[105], d2[105], a[105];
int main() {
cin >> n >> s1 >> s2;
for (int i = n - 1; i >= 0; i--) {
cout << "+ " << (i > 2 ? i : i % 2 + 1) << endl;
t1 = s1; t2 = s2; cin >> s1 >> s2;
d1[i] = s1 - t1; d2[i] = s2 - t2;
}
a[1] = sqrt(d1[0] * 2);
a[3] = d2[0] - d2[2] - 1;
a[2] = d2[2] / (a[3] + 1);
a[4] = d2[1] / (a[3] + 1) - a[1] - 2;
for (int i = 5; i <= n; i++) {
a[i] = (d2[i - 2] - a[i - 4] * a[i - 3]) / (a[i - 1] + 1) - a[i - 3] - 1;
}
cout << "!"; a[n]++;
for (int i = 1; i <= n; i++) { cout << " " << a[i]; }
cout << endl;
return 0;
}
#include <cstdio>
const int MN = 105;
int N, lstv1, lstv2, v1, v2;
int dv1[MN], dv2[MN], Tag[MN], Ans[MN];
int main() {
scanf("%d", &N);
scanf("%d%d", &lstv1, &lstv2);
for (int i = 1; i < N; ++i) {
printf("+ %d\n", i), fflush(stdout);
scanf("%d%d", &v1, &v2);
dv1[i] = v1 - lstv1, dv2[i] = v2 - lstv2;
if (dv1[i] > 0)
for (int x = 2; x <= N; ++x)
if (x * (x - 1) / 2 == dv1[i]) {
Tag[i] = x; break;
}
lstv1 = v1, lstv2 = v2;
}
printf("+ 1\n"), fflush(stdout);
scanf("%d%d", &v1, &v2);
int ndv1 = v1 - lstv1, ndv2 = v2 - lstv2;
for (int x = 0; x <= N; ++x)
if (x * (x + 1) / 2 == ndv1) {
Ans[1] = x; break;
}
int delta = ndv2 - dv2[1] - 1; // delta = a[2] + a[3]
if (Tag[2] >= 2) Ans[2] = Tag[2], Ans[3] = delta - Ans[2];
else if (Tag[3] >= 2) Ans[3] = Tag[3], Ans[2] = delta - Ans[3];
else if (delta == 0) Ans[3] = Ans[2] = 0;
else if (delta == 2) Ans[3] = Ans[2] = 1;
else if (dv2[2] > 0) Ans[2] = 0, Ans[3] = 1;
else Ans[2] = 1, Ans[3] = 0;
for (int i = 3; i <= N - 2; ++i) {
if (Tag[i + 1] >= 2) {
Ans[i + 1] = Tag[i + 1];
continue;
}
if ((Ans[i - 2] + 1) * (Ans[i - 1] + 1) == dv2[i]) Ans[i + 1] = 0;
else Ans[i + 1] = 1;
}
Ans[N] = (dv2[N - 1] - (Ans[N - 3] + 1) * (Ans[N - 2] + 1)) / (Ans[N - 2] + 1);
printf("!");
for (int i = 1; i <= N; ++i) printf(" %d", Ans[i]);
puts(""), fflush(stdout);
return 0;
}
1336E1 - Chiori and Doll Picking (easy version) and 1336E2 - Chiori and Doll Picking (hard version)
Idea: Sulfox
#include <bits/stdc++.h>
using namespace std;
const int mod = 998244353, inv2 = 499122177;
const int M = 64;
int n, m, k, p[M], c[M][M];
long long a[M], b[M], f[M];
void dfs(int i, long long x) {
if (i == k) { p[__builtin_popcountll(x)]++; return; }
dfs(i + 1, x); dfs(i + 1, x ^ a[i]);
}
int main() {
cin >> n >> m;
for (int i = 0; i < n; i++) {
long long x; cin >> x;
for (int j = m; j >= 0; j--) {
if (x >> j & 1) {
if (!f[j]) { f[j] = x; break; }
x ^= f[j];
}
}
}
for (int i = 0; i < m; i++) {
if (f[i]) {
for (int j = 0; j < i; j++) {
if (f[i] >> j & 1) { f[i] ^= f[j]; }
}
for (int j = 0; j < m; j++) {
if (!f[j]) { a[k] = a[k] * 2 + (f[i] >> j & 1); }
}
a[k] |= 1ll << m - 1 - k; k++;
}
}
if (k <= 26) {
dfs(0, 0);
for (int i = 0; i <= m; i++) {
int ans = p[i];
for (int j = 0; j < n - k; j++) { ans = ans * 2 % mod; }
cout << ans << " ";
}
} else {
k = m - k; swap(a, b);
for (int i = 0; i < k; i++) {
for (int j = 0; j < m - k; j++) {
if (b[j] >> i & 1) { a[i] |= 1ll << j; }
}
a[i] |= 1ll << m - 1 - i;
}
dfs(0, 0);
for (int i = 0; i <= m; i++) {
c[i][0] = 1;
for (int j = 1; j <= i; j++) { c[i][j] = (c[i - 1][j] + c[i - 1][j - 1]) % mod; }
}
for (int i = 0; i <= m; i++) {
int ans = 0;
for (int j = 0; j <= m; j++) {
int coef = 0;
for (int k = 0; k <= i; k++) {
coef = (coef + (k & 1 ? -1ll : 1ll) * c[j][k] * c[m - j][i - k] % mod + mod) % mod;
}
ans = (ans + 1ll * coef * p[j]) % mod;
}
for (int j = 0; j < k; j++) { ans = 1ll * ans * inv2 % mod; }
for (int j = 0; j < n - m + k; j++) { ans = ans * 2 % mod; }
cout << ans << " ";
}
}
return 0;
}
Solve the same problem with $$$m \le 63$$$.
Idea: EternalAlexander
First, let's choose an arbitrary root for the tree. Then for all pairs of paths, their LCA (lowest common ancestor) can be either different or the same.
Then, let's calculate the answer of pairs with different LCAs. In this case, if the intersection is not empty, it will be a vertical path as in the graph below.
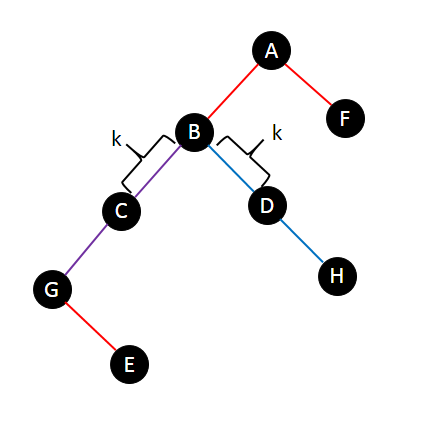
Here path $$$G-H$$$ and path $$$E-F$$$ intersects at path $$$B-G$$$.
We can process all paths in decreasing order of the depth of their LCA. When processing a path $$$p$$$ we calculate the number of paths $$$q$$$, where $$$q$$$ is processed before $$$p$$$, and the edge-intersection of $$$p$$$ and $$$q$$$ is at least $$$k$$$. To do this we can plus one to the subtree of the nodes on the path $$$k$$$ edges away from the LCA (node $$$C$$$ and $$$D$$$ for path $$$G-H$$$ in the graph above), then we can query the value at the endpoints of the path (node $$$E$$$ and $$$F$$$ for path $$$E-F$$$). We can maintain this easily with BIT (binary indexed tree, or Fenwick tree).
Next, we calculate pairs with the same LCA. This case is harder.
For each node $$$u$$$ we calculate the number of pairs with the LCA $$$u$$$.
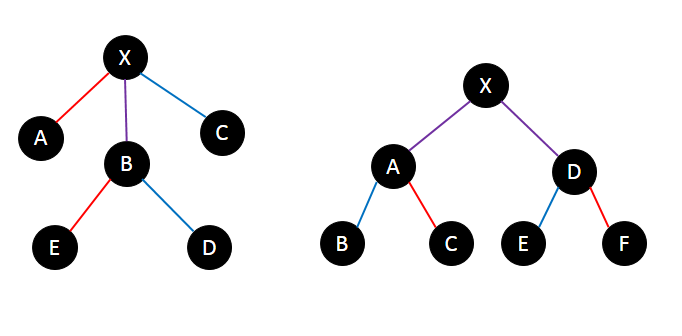
For a pair of path $$$(x_1,y_1)$$$ and $$$(x_2, y_2)$$$, there are still two cases we need to handle.
Let $$$dfn_x$$$ be the index of $$$x$$$ in the DFS order. For a path $$$(x,y)$$$ we assume that $$$dfn_x < dfn_y$$$ (otherwise you can just swap them)
In the first case ( the right one in the graph above, where $$$(x_1,y_1) = (B,E), (x_2,y_2) = (C,F)$$$ ), the intersection of $$$(x_1,y_1)$$$ and $$$(x_2,y_2)$$$ is the path that goes from $$$\operatorname{LCA}(x_1,x_2)$$$ to $$$\operatorname{LCA}(y_1,y_2)$$$ (path $$$A - D$$$)
In this case the intersection may cross over node $$$u$$$.
For all paths $$$(x,y)$$$ with the LCA $$$u$$$. We can build a virtual-tree over all $$$x$$$ of the paths, and on node $$$x$$$ we store the value of $$$y$$$. Let's do a dfs on the virtual-tree. On each node $$$a$$$ we calculate pairs $$$(x_1,y_1)$$$,$$$(x_2,y_2)$$$ that $$$\operatorname{LCA}(x_1,x_2) = a$$$. For $$$x_1$$$ , let's go from $$$a$$$ to $$$y_1$$$ for $$$k$$$ edges, assume the node we reached is $$$b$$$, all legal $$$y_2$$$ should be in the subtree of $$$b$$$.
We can use a segment tree on the DFS-order to maintain all $$$y$$$s in the subtree and merge them with the small-to-large trick, meanwhile, iterate over all $$$x_1$$$ in the smaller segment tree, count the valid $$$y_2$$$'s in the larger segment tree.
In fact, you can use HLD (heavy-light decomposition) instead of virtual-tree, which seems to be easier to implement.
Now note that the solution above is based on the fact that the intersection of $$$(x_1,y_1)$$$ and $$$(x_2,y_2)$$$ is the path that goes from $$$\operatorname{LCA}(x_1,x_2)$$$ to $$$\operatorname{LCA}(y_1,y_2)$$$. But it is not always true, so here we have another case to handle.
In this case, (the left one in the graph above), the intersection is definitely a vertical path that goes from $$$u$$$ to $$$\operatorname{LCA(y_1,x_2)}$$$. This can be solved similarly to the case of different LCAs.
The overall complexity of this solution is $$$O(m \log^2 m + n\log n)$$$.
#include <bits/stdc++.h>
#define maxn 200005
int n,m,k,u[maxn],v[maxn],ch[maxn<<6][2]={0},sum[maxn<<6]={0},pt[maxn],head[maxn]={0},tail=0,cnt=0,root[maxn]={0},
anc[maxn][19]={0},son[maxn]={0},depth[maxn]={0},dfn[maxn],size[maxn],idx=0;
long long ans=0;
std::vector<int>in[maxn],vec[maxn];
struct edge {
int v,next;
}edges[maxn<<1];
void add_edge(int u,int v){
edges[++tail].v=v;
edges[tail].next=head[u];
head[u]=tail;
}
namespace BIT {
int sum[maxn<<2]={0};
void add(int p,int x) {if (p==0) return;while (p<=n) {sum[p]+=x;p+=p&-p;}}
int query(int p) {int ans=0;while (p>0) {ans+=sum[p];p-=p&-p;}return ans;}
void Add(int l,int r){add(l,1);add(r+1,-1);}
}
void update(int x){sum[x]=sum[ch[x][0]]+sum[ch[x][1]];}
int insert(int rt,int l,int r,int p){
if (!rt) rt=++cnt;
if (l==r) {sum[rt]++;return rt;}
int mid=(l+r)>>1;
if (p<=mid) ch[rt][0]=insert(ch[rt][0],l,mid,p);
else ch[rt][1]=insert(ch[rt][1],mid+1,r,p);
update(rt);
return rt;
} int merge(int u,int v){
if (!u||!v)return u+v;
ch[u][0]=merge(ch[u][0],ch[v][0]);
ch[u][1]=merge(ch[u][1],ch[v][1]);
sum[u]=sum[u]+sum[v];return u;
} int query(int rt,int L,int R,int l,int r){
if (l>R||r<L)return 0;
if (l<=L&&R<=r){return sum[rt];}
return query(ch[rt][0],L,(L+R)>>1,l,r)+query(ch[rt][1],((L+R)>>1)+1,R,l,r);
}
void dfs1(int u,int f){
anc[u][0]=f;depth[u]=depth[f]+1;size[u]=1;
for (int i=1;i<=18;++i)anc[u][i]=anc[anc[u][i-1]][i-1];
for (int i=head[u];i;i=edges[i].next){
int v=edges[i].v;
if (v==f) continue;
dfs1(v,u);size[u]+=size[v];
if (size[v]>size[son[u]])son[u]=v;
}
} void dfsn(int u){
dfn[u]=++idx;
for (int i=head[u];i;i=edges[i].next){
int v=edges[i].v;
if (v==son[u]||v==anc[u][0])continue;
dfsn(v);
}if (son[u]) dfsn(son[u]);
}
int lift(int u,int x){
for (int i=18;i>=0;i--)if (x>=(1<<i)) {u=anc[u][i];x-=(1<<i);}
return u;
}
int lca(int u,int v){
if (depth[u]<depth[v])std::swap(u,v);
for (int i=18;i>=0;i--)if (depth[anc[u][i]]>=depth[v])u=anc[u][i];
if (u==v)return u;
for (int i=18;i>=0;i--)if (anc[u][i]!=anc[v][i]){u=anc[u][i];v=anc[v][i];}
return anc[u][0];
}
void dfs3(int x,int rt){
pt[x]=x;root[x]=0;
for (int i=0;i<in[x].size();++i) {
int d=in[x][i];
int rd=std::max(0,k-(depth[u[d]]-depth[rt]));
if (depth[v[d]]-depth[rt]>=rd){
int l=lift(v[d],depth[v[d]]-depth[rt]-rd);
ans+=query(root[x],1,n,dfn[l],dfn[l]+size[l]-1);
}root[x]=insert(root[x],1,n,dfn[v[d]]);
}for (int i=head[x];i;i=edges[i].next){
int t=edges[i].v;
if (t==anc[x][0]||(rt==x&&t==son[x])) continue;
dfs3(t,rt);
if (in[pt[x]].size()<in[pt[t]].size()){
std::swap(pt[x],pt[t]);
std::swap(root[x],root[t]);
}while (!in[pt[t]].empty()){
int d=in[pt[t]][in[pt[t]].size()-1];in[pt[t]].pop_back();
int rd=std::max(0,k-(depth[x]-depth[rt]));
if (depth[v[d]]-depth[rt]>=rd) {
int l=lift(v[d],(depth[v[d]]-depth[rt]-rd));
ans+=query(root[x],1,n,dfn[l],dfn[l]+size[l]-1);
}in[pt[x]].push_back(d);
}root[x]=merge(root[x],root[t]);
}
}
void dfs2(int x){
int len=vec[x].size();
for (int i=head[x];i;i=edges[i].next)if (edges[i].v!=anc[x][0])dfs2(edges[i].v);
for (int i=0;i<len;++i)ans+=BIT::query(dfn[v[vec[x][i]]]);
for (int i=0;i<len;++i){
int j=vec[x][i];
if (depth[v[j]]-depth[x]>=k) {
int l=lift(v[j],depth[v[j]]-depth[x]-k);
BIT::Add(dfn[l],dfn[l]+size[l]-1);
}
}for (int i=0;i<len;++i){ans+=BIT::query(dfn[u[vec[x][i]]]);in[u[vec[x][i]]].push_back(vec[x][i]);}
dfs3(x,x);
while (!in[pt[x]].empty())in[pt[x]].pop_back();
for (int i=0;i<len;++i){
int j=vec[x][i];
if (depth[u[j]]-depth[x]>=k) {
int l=lift(u[j],depth[u[j]]-depth[x]-k);
BIT::Add(dfn[l],dfn[l]+size[l]-1);
}
}
}
int main(){
scanf("%d%d%d",&n,&m,&k);
for(int i=1;i<n;++i){
int u,v;
scanf("%d%d",&u,&v);
add_edge(u,v);
add_edge(v,u);
}dfs1(1,0);dfsn(1);
for (int i=1;i<=m;++i){
scanf("%d%d",&u[i],&v[i]);
if (dfn[u[i]]>dfn[v[i]]) std::swap(u[i],v[i]);
int l=lca(u[i],v[i]);
vec[l].push_back(i);
} dfs2(1);
std::cout<<ans;
return 0;
}







Fun fact: 1336A - Linova and Kingdom and 1336C - Kaavi and Magic Spell were prepared for Codeforces Round 564 (Div. 1) but unused for some reason.
For problem 1336A — Linova and Kingdom
My approach is to do dfs and then sort the nodes is decreasing order wrt size of sub tree. If two nodes has same sub tree size, then we will pick the node with smallest depth first.
Can you please tell me, why this approach is wrong.
It is just wrong logic.
For problem 1337E — Kaavi and Magic Spell
My approach is to use dp with 3 dimensions, for every character I put in A, I am calculating no. of substrings it is forming.
Initial state: dp[0][i][i] = 2 (if S[0] == T[i])
My state transition: dp[i][st][end] = Summation of (dp[i-1][st+1][end]) if S[i] == T[st] Where st runs from 0 till T.length and end starts from st.
And my submission is here https://codeforces.com/contest/1337/submission/77231262
My solution is failing at 7th test case, could you please let me know if the approach is correct and where I am going wrong?
sorry I mistook something...just forget what I said
forget about the logic.. n^3 dp array won't fit into memory limits
we can define front and back of a string only if it is non empty. front and back are same for an empty string so solve case i==0 saparately .
This round has given me confidence. Thanks to the authors and the examiners!
Is there Chinese solution?
You can check luogu, some nice guys have written Chinese editorials there.
Thanks problem-setters for the editorial. I will try to solve C next time
will there be any dp solution for 635 div2 'C'?If yes, Please explain.
I think you can do it by something like $$$dp_{i,j}$$$ -> the answer when $$$j$$$ nodes chosen in the subtree of $$$i$$$. But the complexity will be $$$O(nk)$$$. And you can use the alien trick to optimize it to $$$O(n\log k)$$$ or sth, but it seems very stupid.
Isn't counting how many nodes are there that are under a node u and connected with you is DP. Like this? 76935092
This was greedy approach,i think so.
I think greedy was the last step where I used priority_queue. Maybe I am wrong. I face problems with dp and greedy.
In this problem, if you have used the fact that you have to color all nodes of subtree of ith node (except the ith node) before coloring the ith node, then you have used a greedy approach.
And I did exactly the same.
Manan_shah, probably you can contribute to this.
actually my solution is the same as the editorial. 76863601
The cnt is maintaining the no. of nodes in the subtree of a node including that node. Our approach would be to select the leaves, but if the value of k is greater than that, then we need to select other nodes that are at levels above the leaves and contribute to happiness.
A crucial observation is that when a node is selected, it would decrease the happiness of all the other which are in the subtree. And as we have selected the nodes in the subtree already, the happiness would increase by the depth(level)-nodes in subree.
So we sort the array of level-no. in subtree and select the largest k.
I noticed that I could have computed level by dfs also as presented in the editorial. I had the bfs approach in mind first and then I noticed that it isn't the only thing so I had to use dfs.
I dont understand what you said tha "and as we have selected the nodes in the subtree already, the happiness would increase by the depthe nodes in subtree" please can you explain again..
our main idea is to select the leaves but now if we have more to select, we will pick one level above the leaves. So, which ones should we pick? We pick the ones having maximum happiness. Now if we pick one,we know that it will add happiness by the level of that node, but as we have picked all in its subtree before its picking,we need to subtract the number of nodes in its subtree as while travelling up, the current node won't count.
so, finally we just sort all the values(level-no. in subtree)(net happiness which every node would provide)
Hope this helped.
ohh, now i got the point. thank you so much
What's the use of level[0]=-1000000; in your code?
Video editorial of 635-Div2-C
Thank you sir for your amazing contents and editorials ❣️
I have prepared video editorials, check them out for more insight about the problems.
Div2C/Div1A
Div2D/Div1B
If possible try to make video editorial for DIV2-E, It would be more helpful if you do so.
This guy explain div2 E in excellent way.
link — https://www.youtube.com/watch?v=6OJdAemQSKo
is the note of div 2 E right?
ok i got it i didnt read the input the first string taken is S not t
Div2 C and Div2 D were great problems. Thanks to the authors of the round!
It could be greater if the authors didn't gave the case 1 1 1 1 1 1000000000 in the sample. Then, a lot of people like us would have assume ans = 1e18 first instead of 9e18. And would have got WA and do debugging. Anyway, C and D was nice. Learned a lot solving these.
There's no reason that you wouldn't use 9e18 anyway...
Problem C was harder than Problem D for me. :(
Thank you for funny legends!!!
Can someone please explain to me why Div.2 C got wrong answer on test 6? https://ideone.com/EhLzvj. My idea is that I create a vector from 1 to all the leaves. I then create another copy of it and increase the sum by the difference between each of the vectors. Can anybody help me and tell me how to get it to be accepted?
Well, it is simply wrong logic.
Thank you for your help. I have just understood why it doesn't work.
Why am I getting all these downvotes? I just asked a question about a problem that I thought about incorrectly! What is wrong? Do you just see a downvote and say I will go with the flow or what?
Maybe Div.2 C seems too easy.And your idea is totally wrong that seems like you are fake.
Wait what? What do you mean I am fake? A robot or something? I honestly don’t get it. I am just a kid in college who is currently a trainee at ACM and who is definitely passionate for competitive programming. What is wrong with you!
There is an another reason.If you usually chat in codeforces,you will find that the people whose rating is high hardly gets downvotes.But I exactly don't care about thing.
What do u mean ?!?!? He just asked a q.U don't wanna answer just scroll down.
dude just dont listen to him , he is just another blockhead who had been struggling in his life, don't give shit to these people.
Aren't you?
No one understands why you said the guy asking his question is fake. Maybe you just like to keep receiving downvotes, I suppose...
Because Chinese people in 某谷 always pretend themselves.I 'm sorry for what I say.
Tips: Next time before you decide to retort upon somebody, check his contribution first.
"fake" means "strong, but pretending to be weak" among OIers in China.
I don't agree with him that you are "fake", I believe you asked the question because you really didn't know why it was wrong.
However, I think it's better to find a counter-example by yourself instead of asking here. If you really want to ask here, I suggest you explain why you thought it was correct. Your explanation was not detailed, so I had to read your code, and I just couldn't understand why you thought it was correct.
This dude needs english classes for babies.
The whole commenting area would be blown up if everyone having problems like yours sent a comment. If your algorithm is tested wrong and you don't know why, there are many ways to figure out besides sending a comment asking for help. Also, when a link is posted, it is more often an exhibition of another solution with a different thinking to a certain problem that people wanna share, rather than an ask for help. So try to work independently :)
Yeah, you are right. It's just that this is my first comment on a round and I so a few questions from people asking about their code so I assumed it would be fine. Sorry for the inconvenience.
kaogu
Why in div2 D they are using upper_bound and then decrement z instead of using lower_bound while iterating on z. When I use lower_bound it give wrong answer.
And that is why you should read carefully the definition of these functions.
Upper_bound gives value which is stricly greater than given value.
why we are not checking for both values of z(upper_bound) and z-1?
What do you mean by "checking both values of z and z — 1"?
let the value of x(from one of the gems) is 50 and we want find upper_bound in following array 2 5 35 52 78 100
z=upper_bound() will give the value 52 which sould be taken but we are decrement z which will give the value 35
Ah. You misunderstood what z was for. z was actually meant to find the largest element smaller than given value.
z is upper_bound() which is smallest element greater than given value
infact stricly greater
Yep, that's why we have to decrement z.
Here's an example.
Output:
Hope this clears things up.
Thanks, now i got my mistake.
Could you please explain why z is being decremented?
Since we want the greatest value less than or equal to (let's call it) v, we find the number just before the least value strictly greater than v. There's some number just before and just after v in the set. (Or there are no numbers before, and that has to be handled separately.)
upper_boundandlower_boundboth give the number just after, and only are differ in whether they include v itself. The before and after are right next to each other, though, so finding the value just after and decrementing will get the value just before.In the example, suppose we have the set {2, 4, 6, 8} and we want to find the value just before 5.
upper_boundgives us a pointer to 6, which is just after. Decrement the pointer, and you end up just before at 4.Now suppose we want to find the value just before 6, where equal to 6 is still ok.
upper_boundgives a pointer to 8 because it never gives back the value itself. Decrement the pointer, and you end up at 6.I wish there was a standard function for finding the value before, but there isn't.
If r = {5} g = {5} b = {1,7} we fix g = 5 and look for upper bound from b which is 7 and according to the editorial solution z-- will indicate 1 so red(5) <= green(5) <= blue(1) which is violating the context . Isn't it ?
You have it backwards. That would give the condition red(5) >= green(5) >= blue(1).
I also had the same doubt. Actually {x,y,z} are different in editorial and implementation. I will be explain using implementation code. You can figure out the difference.
Some Definitions-
lower_bound() — greater or equal to the element.
upper_bound() — strictly greater than the element.
These are steps we are doing -
1. We are fixing x from vector a.
2. We need to find z from vector c such that z>=x hence we use lower_bound.
3. We need to find y from vector b such that x>=y hence we first use upper_bound to find element strictly greater than x then decrements it which guarantees that y<=x is followed.
So y<=x<=z relation has been followed as mentioned in editorial(note the difference in conventions).
can anyone please explain the editorial of problem 1336B — Xenia and Colorful Gems?
I am not able to understand it?
sorry!
He is talking about 1336B, the Div1B aka Div2D.
I used greedy approach ... just sort all three array and take 3 pointer i,j,k and move the pointer which would give lowest value as compared to the ones we would get by moving any other pointer.
Here is this link of my submission ... https://codeforces.com/contest/1337/submission/76877219
can u plz explain ur approach
Nice solution
Otherwise, if we choose its parent to develop tourism instead of itself, the sum of happiness will be greater.
Here is a mistake. Should be "the sum of happiness will be smaller."
I think so too. Been stuck at that line for a while. Authors please clarify.
I think you mixed up "tourism" with "industry"? In the statement, you are asked to choose $$$k$$$ cities to develop industry, but here in the lemma, we are choosing cities to develop tourism.
Can anyone please explain Div2-D problem. I understood the core idea that we iterate over any one array and find closest int rest two but why is there 6 possible cases?
i need to know too
Imagine the solution : if it is ordered like $$$r_x \le g_y \le b_z$$$, then you need to run through the green set, and for every $$$g_y$$$ take a red $$$r_x$$$ just below $$$g_y$$$ and a blue $$$b_z$$$ just above.
But what if the solution is rather $$$g_y \le r_x \le b_z$$$ ? You then need to run through the red set first (the middle one).
Etc... You have to try all permutations.
because there can be 6 possible permutations of x,y,z
A bit different solution for 1336D:
Let $$$a_1,\,a_2,\,\cdots,\,a_n$$$ be the initial values. Also let $$$t_0$$$ and $$$s_0$$$ be the initial number of triplets and straight subsets and let $$$t_i$$$ and $$$s_i$$$ be the number of triplets and straight subsets after inserting a tile with value $$$i$$$. This solution has 3 phases:
Finding the values of $$$a_1,\,a_2,\,a_3$$$ with at most 4 queries: First we insert tiles in this order: 1, 2, 3. If $$$t_3 > t_2$$$, we can find $$$a_3$$$. If $$$t_3 = t_2$$$ (we can conclude that $$$a_3 < 2$$$ and) we can use the equation $$$s_2 - s_1 = (a_1 + 1)a_3 + a_3a_4 = a_3(a_1 + a_4 + 1)$$$ to determine whether $$$a_3 = 0$$$. Now if $$$t_1 = t_0$$$ or $$$t_2 = t_1$$$, we insert a tile with value 1. Let $$$t'_1$$$ and $$$s'_1$$$ be the number of triplets and straight subsets after this insertion. If $$$t_1 = t_0$$$, we can find $$$a_1$$$ by comparing $$$t'_1$$$ and $$$t_3$$$. If $$$t_2 = t_1$$$, we can use the equation $$$s'_1 - s_3 = (a_2 + 1)(a_3 + 1)$$$ to find $$$a_2$$$.
Finding the values of $$$a_4,\,a_5,\,\cdots,\,a_{n - 1}$$$ with $$$n - 4$$$ queries: To find the value of $$$a_i$$$ ($$$4 \leq i \leq n - 1$$$), let $$$T$$$ be the current number of triplets. Also let $$$S'$$$ be the number of straight subsets before inserting the tile with value $$$i - 1$$$. Now we insert a tile with value $$$i$$$. If $$$t_i > T$$$, we can find $$$a_i$$$. If $$$t_i = T$$$ (we can conclude that $$$a_i < 2$$$ and) we can use the equation $$$s_{i - 1} - S' = (a_{i - 3} + 1)(a_{i - 2} + 1) + a_i(a_{i - 2} + a_{i + 1} + 1)$$$ to determine whether $$$a_i = 0$$$.
Finding the value of $$$a_n$$$: Let $$$S$$$ be the number of straight subsets before inserting the tile with value $$$n - 1$$$. We can use the equation $$$s_{n - 1} - S = (a_{n - 3} + 1)(a_{n - 2} + 1) + (a_{n - 2} + 1)a_n$$$ to find $$$a_n$$$.
I tried using calculus in Div 2 Problem D(XENIA AND COLORFUL GEMS) but was not able to achieve a good equation has anyone done it with using Maxima and Minima approach , if yes Please explain it :)
Wow
?? :) :) Did you do it using Maxima Minima?
no
I solved it in practice using the concept of minima , i fixed two pointers for sorted r and b then binary searched g to get the best avg value of r's and b's pointer. Incrementing two pointers greedily for minimum distance segment . https://codeforces.com/contest/1337/submission/77064128
thanks for sharing it :)
May be it will be helpful
thanks for helping me out
This code is of div 2 problem A. Code
why it didn't got TLE as the range of the numbers is 10^9 and if the variable d=10^9 and and b+c=2 then the loop this code should give TLE
I think if loop goes beyond 10^7 or 10^8 it should give TLE
When using one simple loop, you can iterate up to 10^9. 10^7 / 10^8 is TLE for python.
P.S. If you want, I can send you link to interesting problem, that have idea, that using up to 1.5 * 10^9 in 2 seconds and solution for it.
So if i have two nested loops having iterations upto 10^4 (each loop),would it show TLE
No. 10^8 is ok.
ya sure pls send it
can`t find endlish version. will try to explain in messages
If so then also it should give TLE because t<=1000 so overall worstcase will be 10^12
Ya, point to be noted
Well,I got some links which talks about compiler optimization and the way we wrote our code.
how many operations per second :: codeforces
5*(10^9) operations working in one second :: codeforces
how to estimate if a solution would pass time limit or not :: codeforces
The compiler is probably smart enough to optimize that to O(1), as in skipping the loop entirely.
Is there a better explanation for Div1 C ?
Let me try. I will explain the same dp but with another indexation and less cases to handle.
Informal: Let
dp[i][j]($$$i\leq j$$$) be the number of ways to perform $$$j - i$$$ operations in such a way that the string we've built so far will be in the position[l..r)of the final string, provided that we did not perform invalid actions. For example, if $$$T$$$ isabacthendp[2][5]is the number of ways to buildac*where*is any symbol, counting that if we'll ever finish this as a spell then we add exactly 2 more letters to the beginning. Thisdpis easy to calculate usingdp[i][j - 1],dp[i + 1][j],s[j - i]and probablyt[i]andt[j - 1].More formal: Let's change the rules for our game. The new rules follow.
We have an infinite sequence of free cells, numbered by $$$0$$$, $$$1$$$, $$$2$$$ etc. Before we start, we put a separator before any of the cells (either before the 0-th cell or between any two consecutive cells). In each turn we delete the first character of $$$S$$$ and put it either into the left nearest free cell to the separator (if any), or into the right nearest free cell. We cannot put a character $$$c$$$ into the sell $$$i$$$ if $$$i < m$$$ and $$$c\neq T_i$$$. After each turn we can claim our victory if the first $$$m$$$ cells are filled (by the letters of $$$T$$$, as follows from the rules).
I state that the new game is equivalent to the old one. Indeed, putting the separator before the $$$i$$$-th cell in the new game corresponds to promising that we will add the character to the front of $$$A$$$ exactly $$$i$$$ times in the old game. I leave understanding of the relation between victories in these two games as an exercise to the reader.
Now it's easy to calculate
dp[i][j]which is the number of ways to eventually fill exactly the cells[i, j). The answer to the problem is the sum ofdp[0][j]for j from $$$m$$$ to $$$n$$$.It's not necessary to calculate it in this order; one could also do
for i := n..0; for j := i + 1..n.what exactly is l and r ?
Oops, I meant $$$i$$$ and $$$j$$$
I've seen that many top contestants used this indexing, but I couldn't understand it before. Thanks for the explanation.
I myself failed to understand the tutorial too. I've read some comments under the announcement blog and have looked through some implementations.
Assume that both strings $$$S$$$ and $$$T$$$ are of equal length, that is $$$m = n$$$. If it is not the case, append some special characters to $$$T$$$ that say that any character may be there. You have to count number of ways to build string $$$T$$$ using the two operations. Let $$$dp(l, len)$$$ be the number of ways to build string $$$T[l, l + len - 1]$$$ having used first $$$len$$$ characters of $$$S$$$. When you have a string $$$T[l, r]$$$ and you consider the next character, that is $$$S[r - l + 2]$$$, you can proceed to states $$$T[l, r + 1]$$$ and $$$T[l - 1, r]$$$, but only when $$$T[l - 1] = S[r - l + 2]$$$ or $$$T[r + 1] = S[r - l + 2]$$$ respectively. If $$$T[i] = ?$$$, a special character, then it is always true that $$$T[i] = S[j]$$$, for any $$$j$$$. To get the answer remember that you don't have to use all $$$\lvert S \rvert$$$ characters, you may stop after some steps, so you need to sum $$$dp(1, len)$$$, for $$$len \ge \lvert T \rvert$$$. I assumed that $$$\lvert S \rvert = \lvert T \rvert$$$, but you still need to store the initial length of $$$T$$$ before appending special characters to calculate the answer.
Have a look at my submission 76955112. The hack I use when filling initial $$$dp$$$ state is proceeding up to $$$n + 1$$$ as without it I don't get correct $$$dp(n, 1)$$$ because $$$dp(n + 1, 0)$$$ is used.
I would like to see the tutorial to be presented in a clearer way so I can understand how exactly our solutions are different.
Your approach of filling special character made the problem much easier to understand. Thanks for the explanation.
Thank you so much !!!!
Here is a solution for div2 C (detail explanation with code ) Check Here
Is this a sort of blog of yours?
Yap!
You say that for a node with c children and at level x from root, if we choose as tourism city then it will contribute (c)*(x). But that presumes that all the ancestors are tourism cities as well. What if not all ancestors are tourism cities?
There is no meaning of building industry on the ancestors (it wont maximize) Because if a node has c*x happiness (assuming all the ancestor is tourism spot) Then we will first build industry on that not on its ancestor
And thats why if a node give c*x additional happiness its ancestor will give less for sure
In step 4 you said that if a node has c children and it is at a depth of x,then it will give c*x happiness if we select it...select it as what?? Industry or tourism?? if we select it as a tourism city, then i think happiness will be c*(x+1).As depth of a node u means the number of nodes in the path [1,u).u is excluded. So if we include u as a tourism city then the number of tourism city in front of the c children becomes (x+1). So happiness becomes c*(x+1).
I am stuck here. Please Help.
Suppose Node A has depth x [1,x] x included A has c children and as its tree if we are going to select A we must have build industry in all of its children (remember A is still tourism we have not build anything) A as a tourism spot — c*x ( as all children will pas through x nodes) A as a industry — we have now (c+1) industry and (x-1) tourism spot so (c+1)*(x-1)
Remember its tree so we are just thinking about that particular branch and then comparing it with others
There are a few places where you have mixed tourism and industry and the total contribution by each node towards the total happiness will be (c-x).
I may have make it bit blurry . I took (x-1) as remaining tourism spot where taking it x will make it clear
Is there any specific reason for vector/set giving TLE in div1B ? I was trying to optimise my logic but couldn't come up with anything, so randomly changed vectors to arrays and it passed in around (1/15)th of the time limit. Got around 6-7 wrong submissions simply because of using vectors :/ I don't think I have ever gotten TLE before with n being 1e5 and the code running in O(n.logn) with vectors :(
Looking at the code i guess you simply forgot to put the "&" when passing vector to functions.
Oh damn. I completely ruined the contest because of this silly error. :( Thanks!
Is std::nth_element faster than std::sort?
Yes, it has Linear complexity since it doesn't sort the entire sequence. Rather, places in the nth position the number which should have been in that position if the sequence was sorted. The rest of the elements won't be in any particular order except for the fact that all elements before the nth element won't be greater than the nth element and all the elements after it won't be smaller.
I solved the Div2D 1337D - Xenia and Colorful Gems a bit differently. I created an array $$$v = r \cup g \cup b$$$ and sort it with keeping track of from which set they come. Whenever I have found $$$3$$$ numbers, I calculate an answer and keep the best one. First, notice some observations.
Once we read the first number (and know which set it's coming from), the $$$5$$$ cases are possible while iterating over $$$v$$$. Consider the array $$$v$$$ looks like this in the beginning.
$$$r_0 r_1 r_2 g_0 g_1 g_2 g_3 b_0 g_4 r_3 ...$$$
Cases:
This eventually goes over all possible triplets, and every time we find a triplet, we find the best middle ($$$2nd$$$) number using binary search. My submission: 76948887.
Why does finding 3 closest numbers using 3 pointers in the 3 sorted array(moving ahead the pointer with min value) fail in DIV2-D.Can someone please point out a case?
I'm not 100% sure how are you going to update the pointers, so try this case.
All 3 here are actually the same, but I have a feeling that your pointer update process might fail in 1 or 2 cases.
it will not fail, you just have to adjust according to requirement of min of the sum of squares. Check out my solution 76926016
For Div2(C), my logic was to sort nodes ascending according to their degree(no of other nodes they are connected to) and then descending according to their depth. Then choose first k nodes as industry. Why is this approach incorrect ? Can anyone suggest a test case please?
6 3 1-2 2-3 3-4 4-5 4-6
EternalAlexander could you please simplify the notations of the problem div1 C?
Can Anyone explain the Top-Down Approach for Div.1 (C) 1336C — Kaavi and Magic Spell ???
Everyone seems to be solving 2E/1C in $$$O$$$$$$($$$$$$n^2$$$$$$)$$$ memory while tourist did in $$$O(n)$$$ — 76845451. Can someone who understands his approach please explain how it is different from the one discussed in the editorial?
Optimizing Space Complexity
For Div2 D. I used a simple 3 pointer search similar to this gfg link. My submission - 76926016
My approach is same with you. I guessed this solution during the contest, but can't proof it until now:(
on what basis u are incrementing i,j,k in while() loop??? plz explain :( cant get this. thank u
I calculated 3 new sums(tmp1,tmp2,tmp3) by increasing each one of i, j and k. Then increased i, j or k whichever resulted in the smallest tmp value.
I dont understand the meaning of size(u) in problem C. Please explain me the reason why we subtracted it from the depth of every node??
to subtract the losses because of converting industry to tourism. This is because there will be no convey from this city.
Can anyone help me understand the approach div2 E Kaavi and magic spell? What is j represent here? Dp[i] [j] represents what?
Can anybody explain why my submission 76966044 for Div 2C is getting Runtime error on Testcase 9? My approach is the same, i.e calculate depth — (no. of nodes in it's subtree) for every node and then print the sum of the k largest elements.
I never used python. How does this work with local variables and recursion?
If you are asking about the variable count1, I have already initialized it outside the function, on line no. 29
So why do you return it, and copy to treecount?
What about example 5 of this tutorial? As I understand it says the local variable is local.
Why the ans is b,c,c in the first question instead of b,c,d in the first question?
let a=1,b=1,c=2,d=3 taking sides as b=1,c=2,d=3 . 1 + 2 == 3 . not Correct. the thing is b+c is always greater than c but if you choose third side as d , in some cases b+c will equal d ( because d > c )
Means we haveto follow the property x+y>z, x+z>y && y+z>x Right?
yes , sum of two sides greater than third
By choosing b, c, c, notice that b + c > c and c + c > b. These 2 inequalities works for all positvie b and c, hence it always work.
If you did b, c, d, b + c can potentially be less than d. For example, simply consider the input 1 1 1 10. You would print 1 1 10 instead, when you can just build an equilateral triangle with sides 1.
On 1337D i tried to sort all the three arrays, and for each fixed x, i would ternary search for y, but to make the decisions on this ternary search i would make another ternary search for z. Code . It did pass 22 test cases. It is not easy to find cases to make it fail.
Why once upper bound and lower bound is used? Why I can't use lower bound/upper bound twice? can squares return value zero? Can someone please explain?
First lower bound used because you want to have a value which is not less than x(i.e greater than or equal to x).Second,upper_bound (with z--) to have the greatest value which is smaller than x in c,now we can't use lower_bound here because lower_bound will give a value not less than x(the value may be equal to x we don't want that we need strictly greater) for eg. say we have c= 2,3,6,6,6,7 and x=6 now when we use z=lower_bound(....)(which is wrong) z will be equal to 6 and z-- =3 but what we need is z to be 7 and z-- =6 which will minimise the difference.
What if c = 2,3,7 and x = 6. We want z = 7 but z-- will make it 3 which is less than x?
Cant find Tutorial of 1337D Problem (Ps: I am new here can anyone help)
1337D is 1336B - Xenia and Colorful Gems because Div1 and Div2 both use the same problems, but use different names for some fancy reason.
For div.1 E2 Lemma 3
How to proof that the linear space B has exactly $$$m-k$$$ bases ?
First, it is clear that the length of $$$B$$$ is $$$m$$$ when $$$k=0$$$.
Every time we add a new base to $$$A$$$ (also, $$$k$$$ is increased by $$$1$$$). $$$B$$$ is impossible to be $$$B$$$ before, we must remove some bases in $$$B$$$. If we remove more than $$$2$$$ bases in $$$B$$$, the length of $$$B$$$ is minus when $$$k$$$ is increased to $$$m$$$!
So the length of $$$B$$$ has to be $$$m-k$$$.
UPD: I found a much easier way to prove it. See it in the new tutorial.
I am trying to implement div2C, my code clearly runs in O(nlogn) time, but I keep getting TLE.
one of my subbmissions. I have checked many times but couldn't find what is wrong.
still couldn't figure this out, can anyone help here please?
https://codeforces.com/blog/entry/75996?#comment-605586 this was the error
Another solution for 1336C:
Assume we have $$$n$$$ positions number from $$$0$$$ to $$$n-1$$$.We delete the letters in $$$S$$$ and put them in these positions.
We can simply see that the operations described in the statement can be changed to these:
Put the first letter arbitrarily in the positions.
Put other letters either at the front or at the back of the sequence of letters we put in the positions.
And the dp is quite obvious now:
Let $$$dp[i][j]$$$ be the answer when we delete the first $$$i$$$ letters in $$$S$$$ and the start of the sequence in the positions is $$$j$$$.We can choose to put the $$$i+1$$$ letter either at the front or at the back of the sequence.If the position we put this letter in is between $$$0$$$ and $$$m-1$$$,we need to make sure this letter equals to the corresponding letter in $$$T$$$.
That means:(if the dp is valid)
$$$dp[i+1][j-1]+=dp[i][j]$$$
$$$dp[i+1][j]+=dp[i][j]$$$
Of course,$$$dp[1][j]=2$$$ if $$$j>=m$$$ or $$$S[j]==T[j]$$$.The final answer is $$$\sum_{i=m}^{n}dp[i][0]$$$.
This solution is easier to think,understand and implement than the editorial.
Thanks! Much easier to understand and implement.
In case anyone needs the code — 77121142
Can anyone re-explain E1 to me ? :'(
My observations and solution for Div2 C / Div1 A and Div2 D / Div1 B in the Announcement thread:
Div2 C
Div2 D
There is another straightforward to think greedy solution using hld for Div1A:
Let, $$$t(u) = \text{number of chosen vertices in subtree of }u$$$, $$$l(u) = \text{level of }u\text{ if we root the tree at }1\text{ (in particular }l(1)=0)$$$.
Maintain $$$f(u) = l(u) - t(u)$$$ for all free (not chosen) vertices.
Initially, $$$\text{ans}=0$$$. Then, do this $$$k$$$ times:
Complexity: $$$\mathcal{O}(n + k \log^2 n)$$$
how is that straightforward
$$$f(u)$$$ means how much I can gain from choosing $$$u$$$... this is the first thought that crosses mind.
Trying to put tourism spots at nodes with maximum size subtrees first comes to mind first (which is incorrect, but can be fixed).
Since we would choose all nodes in a subtree of node u before u itself, we would better use number of all nodes in that subtree in the first place. Instead of adding them one by one.
A question regarding 1336A - Linova and Kingdom tutorial: why are you saying that
std::nth_elementin STL implies an $$$O(n)$$$ solution? As far as I understand,std::nth_elementworks in $$$O(nlogn)$$$ timeRef: https://en.cppreference.com/w/cpp/algorithm/nth_element
In the page you mentioned, are you reading the correct footnote? Overloads 2 and 4 take an execution policy as an additional parameter, while overloads 1 and 3 are "Linear in std::distance(first, last) on average" according to your page.
For more details, see https://en.wikipedia.org/wiki/Quickselect.
Thank you, indeed, I misread the footnotes :)
Then it's $$$O(n)$$$ on average and $$$O(nlogn)$$$ in the worst case, right?
I reacted to the claim that the solution is $$$O(n)$$$, which is not the case, since big-O notation marks the upper bound of the function (time complexity), and not the average.
With $$$1 <= k < n$$$ the solution complexity is still bound by $$$O(nlogn)$$$
Similarly, you can't say that quicksort is bound by $$$O(n)$$$ — that's its average performance, but in the worst case it's bound by $$$O(nlogn)$$$
Sorry for being pedantic, just wanted to point it out.
You correctly state the average and worst-case complexities, and I agree with you that when someone says "a solution runs in O(something)", the implicit assumption is that they're talking about worst-case complexity. So the post should have said "O(n) average time" to avoid this confusion. Your concern is perfectly justified, in my opinion.
I also want to point out your previous comment is absolutely correct too. Big-Oh notation can be used to denote an asymptotic upper bound to any function, and in particular you can use it to bound the average-case complexity as well as the worst-case complexity, and so "O(n) on average" is a technically correct use of big-Oh notation.
Either way, nth_element could have been implemented with the Median of medians algorithm to guarantee worst-case O(n) complexity. In practice, the STL implementations we use rely on a variant of Introselect that combines Quickselect and Heapselect. Wikipedia seems to claim that the original Introselect combined Quickselect and the Median of medians algorithm for optimal worst-case complexity, but I can't confirm that.
i did not understood the editorial for problem C, it is not written well,to clarify my doubts sizu is the size of the subtree of u and depu is its depth ,consider for the last node of the tree with 5 nodes its sizu will be 1 and depu will be greater than 1 , now the author is saying the total happiness will be increased by sizu−depu: here sizu−depu=1-x ,x>1 (sizu−depu) will be a negative value,now how can negative value increase the happiness ???
In div1B my code is giving correct answer for test case 1. but on submitting it is sowing some different answer(instead of 1999999996000000002 some other answer is printing)77017823. please help.
The problem is:
const long MAX = 9e18->const long long MAX = 9e18.The solution to E2 is very interesting, but the tutorial is a little bit hard to understand for me at the beginning. Here are some suggestions:
(1) It would be better to use "Walsh-Hadamard transform" instead of "FWT" here, because fast or not does not matter here. (It's not affordable to explicitly compute it anyway.)
(2) Similar to (1), I feel that "XOR convolution" is a little bit distracting here, because we only care about one term anyway. It made me feel that "we do Fast Walsh-Hadamard transform because we want to do XOR convolution fast", but this is not true.
(3) The proof of lemma 4 doesn't really make sense. "The $$$i$$$-th number of $$$F^c$$$ only depends on $$$popcount(i)$$$, it certainly still holds after Fast Walsh-Hadamard Transform." is true because the the property here is "popcount". If you replace "popcount" with something else it will be false. The formula you listed below should be the actual proof for this lemma.
If I'm going to explain this solution I will try to rephrase it as follows. The main purpose of doing Hadamard transform is to move the analysis from linear subspace $$$A$$$, which has high dimension ($$$k$$$), to another linear subspace $$$B=\{y:\forall x\in A, \langle x,y \rangle=0 \pmod 2\},$$$ which has low dimension ($$$m-k$$$). Hadamard transform provides a linear transformation between $$$[x\in A]$$$ and $$$[y\in B]$$$: $$$[x\in A]=\frac{1}{|B|}\sum_y (-1)^{\langle x,y\rangle}[y\in B]$$$. Therefore if we want to count how many vectors in $$$A$$$ satisfy some properties, we can enumerate every $$$y\in B$$$ and calculate its "contribution" instead. Formally, let $$$F_c$$$ be the set of all vectors which have $$$c$$$ 1s. Then we have $$$\sum_{x\in F_c} [x\in A]=\frac{1}{|B|}\sum_{y} (\sum_{x\in F_c}(-1)^{\langle x,y\rangle })[y\in B]$$$. If we simply enumerate every $$$c\in[m],y\in B$$$ and calculate the contribution of $$$y$$$ in $$$F_c$$$ by some combinatorial methods, we have a $$$O(m^2\cdot 2^{m-k})$$$ algorithm already. By observing that the coefficient only depends on the number of $$$1$$$s in $$$y$$$, this can be squeezed to $$$O(2^{m-k}+m^3)$$$ as in the tutorial.
Elegant problems and short, concise statements. Thank you for this fine contest!
Video tutorial Div1C/Div2E 1336C - Kaavi and Magic Spell here
Someone please explain Div 2 C briefly.
since the capital city is at node 1 we have to place industries in such a manner that total sum of tourism cities is maximum for each of the industry
you should place all the industries as far as possible from the root.
suppose you have some node u with distance d which is tourist city but you are placing an industry on some node with distance d-1 or smaller on the path from 1 to u then you can always achieve better answer for placing the industry at node u so that the answer can be increased. hence you will place all the industries as far as possible from the root node
suppose there are two cities u, v which are at same distance d and no other city is more distant from node 1 other than these two cities and both these are non leaf
you will prefer to make industry on node which has lesser number of children. since u, v are non leaf nodes that means their children should already have been made industry and making node u or v an industry will decrease the solution by number of children of that node as all the nodes which are in subtree of node u or node v will have one less tourist node each in their path to root.
hope it's clear now
It is not the node as far as possible from root. Given node u 2 away from root and having 3 children. And node v 3 away from root but with one child only. Then you have to choose v before u, because it contributes more.
that is what i have said in third and fourth spoiler correct me if I am wrong
solution for div 2 d is very elegant
I am trying to write an easier explanation for Div2E/Div1C.
Our target is to build a string of length $$$n$$$, which is initially empty.
$$$dp_{i,j}$$$ is a state where we have already filled up all the positions in the range $$$[i+1,j-1]$$$.
Now we will either add the next character at the beginning (at index $$$i$$$) if it is equal to $$$T[i]$$$ or we will add the next character at the end (at index $$$j$$$) if it is equal to $$$T[j]$$$. The first option will take us to the state $$$dp_{i-1,j}$$$ and the second option will take us to the state $$$dp_{i,j+1}$$$.
Our answer is $$$dp_{1,1}+dp_{2,2}+dp_{3,3}+.....+dp_{n,n}$$$.
Here is my submission.
what if it's not equal to both T[i] and T[j].
Then, you can't go to any of the two possible new states.
So answer for the current state $$$dp_{i,j}$$$ will be $$$0$$$.
I think it should rather be
Our target is to build a string of length m, which is initially empty.or did i miss something?It's $$$n$$$. Because we will use all the characters from the string $$$S$$$.
Thank's i Got it
For div2 C. When I submitted this solution. I got the Wrong answer at test case 7.
But when I submitted this solution it got accepted.
The only difference between these two starts from line number 34 in the wrong answer I declared the array res as vector int and for the right one, I declared it using pair of vector int.
So Why one is got accepted and the other one got rejected ?
the extra 0th element added to your vector res has created problems I have initalized res vector without space and I have replaced res[i] = with res.push_back() your edited and accepted solution
someone please tell me that why we have added z==c.begin() condition in solve method in Div2. D in editorial I mean upper_bound is returning the smallest index which has greater value than the key searched so suppose if the min value of vector c is greater than the key the result will be c.begin() why would we do continue in this case (can't we form a triplet with value from vector c as c.begin() ) what's wrong with doing that
Why is this solution in Python giving Runtime Error on Case 9
76970117
Can anyone please explain { DIV2 : E. Kaavi and Magic Spell }. I am not getting it from the editorial. Not even the intuition.
I tried to explain it briefly here
Nice round :) Thank you ^^
btw, you don't have to actually hold the dp matrix in div1C, as the update only use the next location for each update, you can update it from left to right.
Here is a very short solution:
It's really short. I didn't fully understand the solution from the editorial though.
I was able to solve it using O(n) space too. But I had to store two rows since my current state calculates answer using the values from the previous row.
How to solve the bonus part of E2? :(
+1, is it somehow related to this? rabfill's comment claiming $$$O(2^{2m/5}m)$$$ complexity though I didn't get his approach.
In Div1 E in this part "build linear basis A with given numbers", what do you mean exactly? Build a set with minimum number of elements of the input such that all the elements are linear combination of those?
consider each number as a zero-one vector in $$$\mathbb{F}_2^m$$$, then find a basis of this vector space. Then, each given number can be written as the xor of a subset of this basis.
In that case a base could be { (1,0,...,0,0) , (0,1,...,0,0) , ... , (0,0,...,0,1) }, right?
I don't understand why $$$ ans_i = p_i \cdot 2^{n-k} $$$.
Do you know a post where i can learn this?
"In that case a base could be { (1,0,...,0,0) , (0,1,...,0,0) , ... , (0,0,...,0,1) }, right?"
No, that's a basis of $$$F_2^m$$$, but we want a basis of the subspaced spanned by the given vectors.
As for why $$$ans_i=p_i\cdot2^{n-k}$$$: let $$$V$$$ be the set of input vectors, and let $$$A\subset V$$$ be a basis of the subspace spanned by $$$V$$$. First we look at linear combinations of $$$V\setminus A$$$, then we consider linear combinations of $$$A$$$ to get a desired popcount. Choose any linear combination of $$$V\setminus A$$$, there are $$$2^{n-k}$$$ of these, and suppose the xor sum is $$$x\in span(V)$$$. Each $$$x$$$ that we get this way can be expressed uniquely as a linear combination of vectors in the basis $$$A$$$. Now consider one of the $$$p_i$$$ linear combinations of vectors in $$$A$$$ such that the resulting popcount is $$$i$$$, and suppose the xor sum of this linear combination is $$$y$$$. There is a unique way to use the basis vectors to go from $$$x$$$ to $$$y$$$, ie. writing $$$y-x$$$ as a linear combination of the basis. This gives a bijection that shows $$$ans_i=p_i\cdot2^{n-k}$$$.
"Do you know a post where i can learn this?"
This is linear algebra with a bit of combinatorics.
I don't get one moment.. Suppose we get any linear combination from $$$V \setminus A$$$ which have xor sum $$$y$$$. Then we get any subset $$$X$$$ from $$$A$$$ that have popcount equal to $$$i$$$ and xor sum -- to $$$x$$$. How come that we're always able to express $$$y - x$$$ as linear combination of vectors from $$$A \setminus X$$$?
Oh, seems that otherwise we've couldn't express $$$y$$$ as linear combination of vectors from $$$A$$$. Cause linear combination of $$$x$$$ is also unique
Can you elaborate more on the part where you say "This gives a bijection that shows ans_i = p_i * 2^(n-k)."?
Every linear combination of $$$V$$$ is the sum of a linear combination of $$$A$$$ and a linear combination of $$$V\setminus A$$$. One way to get a linear combination of $$$V$$$ with popcount $$$i$$$ is to choose a linear combination $$$x$$$ of $$$V\setminus A$$$ and a linear combination $$$y$$$ of $$$A$$$ with popcount $$$i$$$. Once we fix $$$x$$$ and $$$y$$$, we can put $$$x$$$ as the linear combination of $$$V\setminus A$$$, and $$$y-x$$$ as the linear combination of $$$A$$$. The number of ways to choose $$$x$$$ and $$$y$$$ are $$$2^{n-k}$$$ and $$$p_i$$$ respectively.
Can anyone please help?
Problem Div2 D : I have coded solution as per editorial, verified the data types of ans, vector. I am getting correct answer for the sample test on my machine, but on submitting I'm getting a different output.
wrong answer 2nd numbers differ - expected: '1999999996000000002', found: '2147483647'submission 77118100
Ok found the mistake. Was setting LONG_MAX to a
long long.Still confused why I got correct output locally(on my machine),
LONG_MAX could be defined differently. You could define your own infinities to avoid this.
Can someone please tell me why am I getting WA on test case 6 on div2 C . My logic is to find the depth and the no. of children of each and every node. Find depth[i]-children[i] for all nodes and return the sum of the top k values Here's the code https://codeforces.com/contest/1337/submission/77153692
Can anyone suggest more good problems like DIV2 'C'(1336A)
I don't Understand Div 2 problem D can someone explain to me what's wrong in my idea Idea: First, assume the solution is of the form x<=y<=z fix x and found y by lower_bound(b.begin(),b.end(),x) then found z by lower_bound(c.begin(),c.end(),*y)
Try this:
I've also used the same approach.My code passes your test case. But fails System Case. For all possible 6 combinations of arrays r,g,b I've used finding x<=y<=z Approach. Please Help!
Code
How to approach problem C. sizu−depu, how do we get to know about this? observation & intuition?
Hey Guys, If you want a solution for Div.2 B — Kana and Dragon Quest Game
Please check out this video!
https://youtu.be/DGo4IU143nQ
Can someone please explain Magic Spells ? Ashishgup I liked your code on this. Can you just tell, what is dp[i][j] in your solution ?
Thanks
For 1337C- Linova and Kingdom,
I did same but I was getting Runtime Error which must be due to recursion limit as it will be exceeded if we have all 10^6 nodes connected in a sequence.. So I tried to increase the limit to 10^6 but for that, I got memory limit exceeded error.
Then I tried to set it to 10^5, but for this one also I got Runtime error.
Can anyone suggest what should I have done?
I think I am missing something for Division 2 Problem C: Linova and Kingdom. I have the following problem with the author's solution:
When calculating increase in happiness, when we choose a certain node $$$u$$$ to develop into a tourism city, then the loss is $$$dep_u$$$, this is correct: since all the parent nodes are already taken by the lemma that the author proved at the beginning. But when we calculate the gain, it is, at that moment, equal to $$$size_u$$$. But when we color some predecessor of $$$u$$$ in subsequent (later) steps, then this gain value changes, because some nodes in the sub-tree of $$$u$$$ no longer remain as an industry city.
EternalAlexander, or anyone, please point out where am I wrong. Thanks!
You can see that, when you colour node $$$u$$$ all its predecessors are already coloured in previous steps. Because for all predecessors of $$$u$$$ the $$$size-dep$$$ is greater than $$$u$$$.
OK, sorting takes the predecessors first in a branch. But out of all the possibilities over all branches, how does sorting ensure that it takes the best possible node? Because the number $$$size_u - depth_u$$$ doesn't really make sense to me, because it loses its significance when we take a child of $$$u$$$, it's value completely changes. So why do we store these numbers in an array and sort them. I think this needs some kind of proof??
We have proved that, in the optimal way, when you take node $$$u$$$, all its predecessors are already taken, otherwise you should take the predecessor first.
So before we take node $$$u$$$, all the nodes in its subtree are definately not taken. So in the optimal way, when you take node $$$u$$$ the change to the answer is $$$size_u - depth_u$$$.
Yes you have proven that, but how do you prove that out of all possible nodes in a given depth (all the nodes in previous depths are already taken), the optimal node is the node with the maximum value of $$$size_u - depth_u$$$? Because this number doesn't mean anything after a few steps. So why do we store it? And sort them?
Ok, I'll try another way to explain.
Here $$$k$$$ denotes to $$$n-k$$$, i.e. the number of tourism cities.
Let $$$f_u$$$ be $$$size_u - depth_u$$$.
First, the optimal answer is no less than the greatest $$$k$$$ of $$$f_u$$$. Because that's the answer when you take the first $$$k$$$ nodes.
Second, the answer can not be greater than that:
If there exists a way to make the answer greater, assume that the nodes you've taken are $$$u_1, u_2 \cdots u_k$$$, the sum in this way will be $$$f_{u_1} + f_{u_2} + \cdots + f_{u_k}$$$, because for any node taken, all its predecessors are taken, and you can calculate the answer in this way. And you can see this is no greater than the sum of the $$$k$$$ greatest $$$f_u$$$.
The main idea is:
In the optimal way, when you take node $$$u$$$, all its predecessors are already taken.
If the nodes you take satisfy the condition above, assume the nodes you take are $$$u_1,u_2 \cdots u_k$$$, the answer is $$$size_{u_1} - depth_{u_1} + \cdots + size_{u_k} - depth_{u_k}$$$.
If you take the greatest $$$k$$$ of $$$size_u - depth_u$$$, the nodes you take satisfy the condition above.
OK I got it, thanks a lot!!!
When you sum those values, the change in $$$f_u$$$ of parent due to child node gets added to the answer, and sorting ensures that the conditions $$$1$$$ and $$$2$$$ are always fulfilled, so it is optimal to take the best $$$k$$$.
Thanks a lot, really!
Yes that's exactly what I meant :D
can someone please give solution for 1336C - Kaavi and Magic Spell with proper explaination. I can't understand the editorial.
Does anyone know more problems like 1336C — Kaavi and Magic Spell ?
For Div2D/Div1B My Approach is very similar to Editorial's. Its failing System Tests.
We assume the solution is of the form x<=y<=z. Then Fix x and find y by lower_bound(b.begin(),b.end(),x). Then find z by lower_bound(c.begin(),c.end(),*y)
We do this for all 6 Possible Combinations of Arrays r,g,b.
Code
Please Help!
1336B — Xenia and Colorful Gems auto y = lower_bound(b.begin(), b.end(), x); auto z = upper_bound(c.begin(), c.end(), x);
why is z-- but not z = lower_bound(c.begin(), c.end(), x)?
There was a huge mistake in the tutorial of 1336F - Journey. I have fixed it now. Thanks sys. for pointing out!
:)
In problem e1 the soluution has this written on it Build linear basis A what does this mean ?
Can anyone help me finding the error as my code is getting wrong ans on test case 6 problem A
My Code
nice problem div1A problem
I want to take some time to explain the Div2C/Div1A's solution (Linova and Kingdom).
So the tutorial already mentions that we need to get the $$$val_u = size_{u} - depth_{u}$$$ for each node, and then sort the values, such that the bigger ones are first, and select the first $$$n-k$$$ values, and those are the ones that are selected as the tourist spots. Also, the summation of the $$$val_u$$$ for these $$$n-k$$$ values would give us the answer, But why?
So why are we taking $$$size_u$$$?
This is taken, while assuming that all the nodes under the current node will be industries. Now, if our current node is a tourist node, then in that case, each of the industry in the subtree will count this tourist node as one. Therefore we take the $$$size_u-1$$$ value. (The -1 is cancelled out later)
Why are we decreasing $$$depth_u$$$?
All the parent nodes of the current node would have taken the current node as an industry (as per the $$$size_u$$$ calculation). Now, since we are considering the current node as a tourist spot, we need to remove the "industry assumption" values from the total. This can simply be done by counting the number of nodes from 1 to the current node. That will be $$$depth_u-1$$$
The -1s cancel out, so we get $$$size_u - depth_u$$$.
Now this works because the sorted order forces us to go from parents to children. I hope this helps.
can you please explain why this assumption is correct?
This is taken, while assuming that all the nodes under the current node will be industries.Because it may happen that we assumed that all the subtree will be industries but we did not take all the subtrees
Yes it can be false definitely. That's what the $$$-depth_u$$$ part is for. So you add $$$size_u$$$ assuming that all the nodes under the current node will be industries. Let's say this node as N, whose children we have assumed to be industries.
Now let's say, when you reach some node A, in the subtree of N, which is to be taken as a tourist spot. In that case, the assumption for N becomes wrong, and you remove need to remove A's contribution from all it's parents. That's just $$$depth_u - 1$$$.
So this handles the scenario when the node in the subtree is not an industry.
oh! Yes. I got it. Thanks a lot.
Why not a,b,c can be a answer in Problem A? Why b,c,c?