


This is the Editorial for MemSQL start[c]up Round 2 and MemSQL start[c]up Round 2 - онлайн-версия. Congratulations RAD for online round winner and Petr for onsite and overall score winner!
This editorial is written jointly by the contest's coordinators (i.e., MemSQL engineers).
Reference solution: Jimanbanashi's 4222182
Instead of calculating the smallest possible number of sheets given a fixed n, let us instead try to compute the smallest possible value of n given a fixed number of sheets. Let k denote the number of sheets. If a particular letter appears p times in s, then it must appear at least ceil(p / k) times in the sheet. Thus we can compute the smallest possible value of n by summing ceil(p / k) over all letters. Now the original problem can be solved using binary search on k (or brute force, since the constraints were small enough).
335B - Палиндром -- AlexSkidanov
There’s a well known O(n2) solution that allows one to find a longest subsequence of a string which is a palindrome: for every pair of positions l and r, such that l ≤ r, find the length d of the longest palindrome subsequence between those positions.
d[l][r] = max(d[l][r-1], d[l + 1][r], s[l] == s[r] ? d[l + 1][r - 1] + 1 : 0).
There are two ways to solve this problem faster than O(n2) with the constraints given in the problem:
- Use dynamic programming. For every position l and length k find the leftmost position r, such that there’s a palindrome of length k in the substring of s starting at l and ending at r. For position l and length k
r[l][k] = min(r[l + 1][k], next(r[l + 1][k - 1], s[l])),
where next(pos, s) is the next occurrence of character s after position pos. Next can be precomputed for all the positions and all the characters in advance. See DamianS's 4221965.
- If length is less than 2600, use the well-known O(n2) dynamic programming approach. Otherwise by pigeonhole principle there’s at least one character that appears in the string at least 100 times -- find it and print it 100 times. See SteamTurbine's 4224770.
335C - Графство и Королевство -- AlexSkidanov
The most straightforward way to solve this problem is to use Grundy numbers. Define a segment as a maximal range of rows in which no cells have been reclaimed. Since segments have no bearing on other segments, they can be assigned Grundy numbers. There are 4 types of segments:
- The entire river.
- A section of river containing one of the ends.
- A section of river blocked at both ends in the same column
- A section of river blocked at both ends in different columns
Each time a cell is reclaimed, it splits a segment into 2 segments (one of which may have size 0). We can compute the Grundy value for all possible segments in O(r2). Then after sorting the reclaimed cells by row number, we can find all segments and compute the Grundy number for the full state.
See Dmitry_Egorov's 4221888.
Alternatively, we can compute the result directly. Suppose the game is over. We can determine who won the game just by looking at the top row and the bottom row. Let us define “parity” as the modulo 2 remainder of (r + n + c0 + c1), where c0 is the column of the reclaimed cell with the lowest row, and c1 is the column of the reclaimed cell with the highest row. Claim: when the game is over, the parity is even. This can be seen by observing that the number of empty rows is equal to the number of times the column changes. In other words, if c0==c1, there are an even number of empty rows, otherwise an odd number of empty rows. Now, given r, c0, and c1, we can determine n, and therefore the winner.
Let us consider the case where there are no reclaimed cells. If r is even, then the second city can win with a mirroring strategy. When the first city reclaims cell (a,b), the second city follows with (r+1-a,b). Similarly, if r is odd then the first city wins by a mirroring strategy, playing first in ((r+1)/2, 0), and subsequently following the strategy for even r.
Now suppose there are reclaimed cells. Let us define r0 as the number of empty rows in the segment starting from one end, and r1 as the number of empty rows starting from the other end.
Case 1: if r0==r1 and the parity is even, the state is losing. All available moves will either decrease r0, decrease r1, or make the parity odd. The other player can respond to the first two types of moves with a mirroring strategy, and the third by making the parity even again (there will always be such a move that doesn’t affect r0 or r1, based on the fact that the argument above).
Case 2: if abs(r0-r1)>=2 then the state is winning. Suppose, without loss of generality, that r0-r1>=2. Then either of the cells (r1+1, 1) and (r1+1, 2) may be reclaimed, and one of them must lead to Case 1 (since they both result in r0==r1, and one will have even parity and the other odd).
Case 3: if abs(r0-r1)<2 and the parity is odd, the state is winning. If r0==r1, then we can change the parity without affecting r0 or r1, leaving our opponent in Case 1. Otherwise, there is a unique move that leaves our opponent in Case 1.
(note that cases 2 and 3 together imply that all states with odd parity are winning)
Case 4: if abs(r0-r1)==1 and the parity is even, there is at most one move that doesn’t leave our opponent in Case 2 or Case 3. Suppose r0==r1+1. We must change either r0 or r1, since all other moves will change the parity to odd. Thus our only option is to decrease r0, since decreasing r1 would leave our opponent in Case 2. We could decrease r0 by 1, but doing so would change the parity. Thus we must decrease r0 by 2, and there is at most one move that does so and keeps the parity even. It follows that if floor(r0/2)+floor(r1/2) is even, then this is a losing position, otherwise a winning position.
See jill-jenn's extremely short 4225125.
335D - Прямоугольники и Квадрат -- AlexSkidanov
Even though constraints were allowing O(k^2) solutions, in this editorial we will describe an O(n log(n)) solution. This problem has a rather long solution, involving several very different ideas: On the first step, for every rectangle we want to determine, if we were to consider this rectangle as the top left corner of a square, how long could the top and left edge of the square be (see the picture).
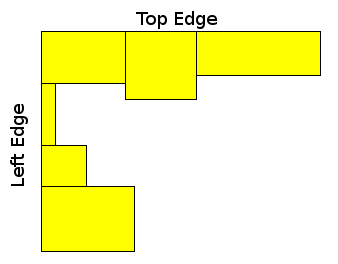
If there’s no rectangle that is adjacent to the current rectangle on the right, which has the same y1 coordinate, then the top edge length is just the width of the current rectangle. Otherwise it is the width of the current rectangle plus the max top edge computed for the rectangle adjacent on the right. Left edge length is computed likewise.
When top and left edge lengths are computed, we want to compute the max bottom and right edge length if this rectangle was the bottom right corner of the square.
On the second step, we want to find all possible square frames. Look at this picture to better understand what we mean by square frame:
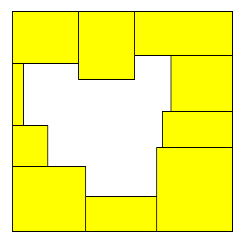
To find a frame, let’s sort all the points first by x - y, and then by x (or y -- both will yield the same result). This way all the points are sorted by the diagonal they belong to, and then by the position on that diagonal. Then we will maintain a stack of pairs (position, edge length), where edge length is min(top edge length, left edge length). Position could be either x or y (within a given diagonal relative differences in xs and ys are the same). Min edge length tells us what is the largest square that could start at that position.
When we process a new point on a diagonal, first pop from the stack all the pairs such that their position + edge length is less than our position. If stack after that is empty, then the current point cannot be a bottom right corner of any square. If stack is not empty, then there could be some frames with the current point being bottom right corner.
Here we need to make a very important observation. If a square frame is contained within some other square frame, we don’t need to consider the outer square frame, since if the outer square frame is then proves to be an actual square, then the inner frame also has to be an actual square, and it is enough to only check an inner frame.
With this observation made, we can only check if the last point on the stack forms a frame with the current point, there’s no need to check any other point on the stack. Since we already know that last element on the stack reaches to the right and to the bottom further than our current position (otherwise we would have popped it from the stack), to see if we form a frame with that point it is enough to check if we can reach that far to the top and to the left. To do so, check, if position of the current point minus min(bottom edge length, right edge length) for the current point is smaller or equal than the position of the point that is at the top of the stack. If it is, we have a square frame.
When we have a frame, we move to the third step, where we check if the frame is filled in. To do that we just want to check if area within that square that is filled in by rectangles is equal to the area of the square. For every corner of every rectangle we will compute the area covered by rectangles which are fully located to the left and top from that point. To do that we can sort all the corners by x, and then by y, and process them one by one. We will maintain an interval tree where value at every position y represents area covered by rectangles processed so far that are fully above y. Then when we process a corner, we first update the interval tree if the corner is a bottom right corner, and then query the interval tree to see the area covered by rectangles to the up and left from the current corner.
Then, when we have these number precomputed, for every square frame x1, y1, x2, y2 we can just get the area for (x2, y2), add area for (x1, y1) and subtract for (x2, y1) and for (x1, y2). See the author (AlexSkidanov)'s 4234601
A possible O(k2) solution is similar, but makes checking whether or not the frame is filled much and a bunch of other checks easier. See my 4234474.
335E - Инвентаризация Небоскребов -- pieguy
The skyscrapers in this problem depict a data structure called Skip List. Skip list is similar to AVL and red black trees in a sense that it allows O(log N) insertions, deletions and searches (including searching for lower and upper bounds), as well as moving to the next element in sorted order in constant time. Skiplist is different from any tree structures because it has a practical thread safe implementation without locks (so-called lock-free). Lock free skiplists are used as a main data structure to store data in MemSQL, and the algorithm that Bob uses to traverse the skyscrapers is an O(log N) approach, that allows one to estimate the size of the skiplist. Thus, if Bob ended up with an estimation of n, the actual skiplist size is expected to be n (so if the first line of the input file is Bob, one just needs to print the number from the second line to the output). Formal proof is rather simple, and is left to the reader. Curiously, the converse does not hold. If the skiplist size is n, the expected return value of the estimation algorithm could be bigger than n. For an n that is significantly bigger than 2h the estimate converges to n - 1 + 2h, but this problem included cases with smaller n as well.
Let us build up the solution one level at a time. When H is 0, the expected sum is N. Now for each additional level, we can add the expected cost of the zip lines on that level, and subtract the expected cost of the zip lines immediately below them. In the end we’ll have the total expected cost.
For some floor number H, let’s consider some left and right tower, and determine the probability that a zip line exists between them. Let L be the distance between the two towers. A potential zip line of length L and height H exists if the towers at both ends are tall enough (probability 1 / 2H for each one), and the L - 1 towers between them are all shorter (probability 1 - 1 / 2H for each). Thus the probability that such a zip line exists is 1 / 22 * H × (1 - 1 / 2H)L - 1.
Now, assuming that such a zip line exists, what’s the expected number of zip lines immediately below it? This is simply one more than the number of towers of height H - 1. Each of the L - 1 towers has probability 1 / (2H - 1) of having height H-1 (given that it has height at most H-1) -- use conditional probability (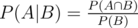 ) to calculate this. Thus the expected number of zip lines immediately below a zip line of length L and height H is 1 + (L - 1) / (2H - 1).
) to calculate this. Thus the expected number of zip lines immediately below a zip line of length L and height H is 1 + (L - 1) / (2H - 1).
For each length L, there are N - L possible zip lines with this length on each level. We multiply probability by cost for all possible zip lines to attain the expected value.
The final answer is therefore
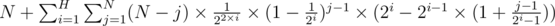
It turns out the inner loop can be computed using matrix multiplication, for a running time of O(H log N). -- although the constraints is low enough that using matrix multiplication is an overkill -- O(H * N) will do.
See the author (pieguy)'s 4234465. ...apparently this solution is much shorter than the "easier" problem's :)
Congratulations Petr and tourist for the only persons solving this problem in-contest both on-site and off-site!
335F - Купи пирог, получи второй в подарок! -- pieguy
This problem is equivalent to maximizing the total value of items that we can get for free.
First, process the items into <#value, #number_of_items_with_that_value> tuples, which means we have #number_of_items_with_that_value items of value #value. Then, sort the tuples in descending order of #value.
Iterate over those tuples and let #pieguy be an empty multi set()
For each tuple <#val, #num>, we can calculate #max_free, the maximum number of items (not value) that we can get for free up to this point easily.
So, we want to populate #pieguy so that it contains exactly #max_free “things”. #pieguy is special, in that we can compute the maximum price that we can get for free for n items by summing up the n most expensive items in #pieguy. How could #pieguy do that?
For now, you may assume that each element of #pieguy contains the value of a single item that can be gotten for free. Thus, summing n items = value of n items that can be gotten for free. This is not correct, of course, since not all n arbitrary items can be simultaneously gotten for free in tandem, but we’ll come back to it later.
We’re now at <#val, #num>, and we have #pieguy from previous iteration. #pieguy contains the previous #max_free elements. Assume that #num <= number of items more expensive than this value, for otherwise the remainder are ‘dead’ and useless for our current purpose. In particular, for the first tuple we process, we assume that #num is 0, since all of them cannot be gotten for free.
Suppose we want to obtain exactly #max_free items. How many of the #num must we use?
Let’s arrange the current members of #pieguy in descending order. For example, if #pieguy has 5 members:
A B C D E
Let’s arrange #num #val under #pieguy so that the rightmost one is located on position #max_free. For example, if #num is 6 and #max_free is 8 and #val is V....
A B C D E
V V V V V V
These 6 Vs will be competing for a spot in #pieguy.
Now...
1) what happens if C < V? This means, instead of making C free, we can make V free instead! (if you’re wondering why this is possible, remember that #pieguy definition I gave you was not entirely honest yet). So, we replace C, D and E with all Vs, and we get our new #pieguy! A B V V V V V V (this should be sorted again, but C++’s multiset does that automagically).
2) otherwise, C > V. So, V cannot contend for the 3-th place in #pieguy, it has to contend for a place larger than or equal to the 4-th.
Now the fun begins! If you want to contend for the 4-th place, any solution MUST HAVE AT LEAST 2 V s (remember that the 4-th place is used in a solution consisting of at least 4 free items). In general, if you want to contend for the #max_free — i -th place, you MUST HAVE AT LEAST #num — i Vs. #proof? is easy, exercise (i’m honest!)
Okay, so back to contending for the 4-th place. If D is still > V, we proceed. Otherwise, we know that D < V. This means, E and any element after E is also < V! Thus, we can replace all elements after or equal to E with V! The problem would be the final element of #pieguy.
When the final element of #pieguy is included in the sum, it is only included in the sum of all n elements of #pieguy. You do this when you want to calculate the maximum sum of values of free items you can get when getting exactly #max_free items. Any such solution must include all #num elements with value #val. We have included #num-2 Vs in #pieguy. Thus, the final element of #pieguy must somehow contains 2 Vs! So, elements of #pieguy actually can do this. Instead of containing a single elmeent, each element of #pieguy is more of an “operation” that adds several value and removes several value. In our case, we want to add 2 Vs and remove something. The something? The smallest element that we can remove (the ones that we haven't removed)! C! (if you're wondering why not D or E, it's because (again) #pieguy is special -- it only forms a solution if the most expensive t are summed, not if some are skipped. -- we cannot skip C if we want to use D).
So, Insert 2V — C into #pieguy, and the rest, insert V into #pieguy. 2V — C is < V, so summing all elements of #pieguy correctly found out the max value when we receive #max_free free items!
Right! Cool! ...except that 2V — C can be negative. Why would we want to insert negative stuffs into #pieguy? We don’t! Actually, we check if 2V — C is negative. If it is, we continue instead, and check 3V — C — D and so on, under the same reason.
That’s it folks! I skipped some details of why this works (for example, that the number of V selected is always sufficient to guarantee solution in #pieguy), but they're easier to see once you get this large idea. The result is then #pieguy.last_element







The problems are nice! Problem E can be solved just by an O(N*H^2) dp.
Yes, the very first solution we had was O(N*H^2). Constraints were kept low enough to allow it. There is a lot of very different O(N*H) solutions also, the one in the editorial is the easiest one we know.
The solution to Problem F...too hard to understand for me..
Here's the way I see the solution for problem F, may be my perspective will help people to understand the problem better.
Consider this solution: we have a dynamic programming table, that for position i and number j tells us how much money we will save if we get j items for free. Then i - 2 * j is the number of items we paid for but did not take anything for free with them. Such an item we will call an "available item". If we process items one by one, we will need to handle a case, when an available item has the same price as the current one, so we would need to extend the DP table in some way (like adding another dimension, denoting how many items we have available with the current price). Instead of that we will process items with the same price all at once. So now i is not a position in the array, it is the position in the array after removing duplicates. If we have an array
Then i = 0 is the row after processing 10s, i = 1 is the row after processing 9s, i = 2 is the row after processing 6s etc (row here means a row of dynamic programming table for a fixed i).
Here's how the first several rows of the table look like:
First row says, that after buying two 10s we cannot save anything (it is impossible get 1 item for free). After purchasing 9s we can save 9 if we get one item for free, or we can save 18 if we get two items for free. That makes a lot of sence -- we had two available numbers, we added two nines to the picture, we got them both for free -- thus we can save 9 if we get one for free, or 18 if we get two for free. When we look at the third row, which we obtain after adding 6s to the picture, we see that if we get one item for free, we can still save 9. We could have gotten 6 for free instead, but obviously we want to save as much as possible. Then for two items we still can save 18 by getting two 9s for free. It gets interesting at the third column -- now we can save 21. 21 - 18 is neither 6 nor 9, where does it come from? Well, to get the third item for free after we already got two 9s for free we need to return one 9 back and pay for it, and then use 10 which became available, and 9 we've just returned to get two sixes. That results in a difference of 6 + 6 - 9 = 3. Now this is an O(n2) solution, and it is rather simple (I let you deduce the DP transitions as an exercise). We are looking for O(nlogn) solution. To achieve it, we will modify the array. Instead of storing the actual value we save, we store how much more we save compared to the value on the left (in other words, if we already got j items for free, how much more we can save by getting j + 1 items for free). Now first three rows look like that:
In the last row, first item we get for free saves us its price 9, second item we get for free saves us its price 9, and the last item we get for free saves us only 3, because we need to return one of the 9s we got for free. Now I will describe how we compute these rows. We begin with a row with a single 0
0 Now when we add two nines, we have 4
items total, of which we can get for free at most 2. We put all the nines we have in the current batch to the rightmost of those 2 positions. In this case rightmost positions happen to be the only positions:Then we add two sixes. We have a total of 6 numbers, of which we can get at most 3 for free (we clearly cannot get more than half of total number of items for free). Let's put two sixes to the rightmost of the three available positions:
Now ideally we would just replace smaller numbers in the first row with bigger numbers in the second:
But it's not quite how it works, and here comes the most confusing part of the solution. For every position in which number in the old row is bigger than the number in the new row we have a problem, because if you look again at the rows:
you will notice that the last six in the second row says "you can save 6 with the third item if you saved 6 on the second item". We cannot just merge it with the previous row, because in the previous row we saved 9 on the second item, not 6. To adjust for it, for every column in which the old row has a number bigger than the new row, we will adjust one of the last numbers in the second row to account for the difference. In this case in the second column 9 > 6, we will adjust the very last column to account for it by subtracting 9 - 6 from it, resulting in 6 - (9 - 6) = 3.
Now we replace numbers in the first row with bigger numbers in the second row:
When we add third row, we now have 14 items, of which for free we can get only 6 (because we have only 6 numbers that are bigger than 4). We again place 4s into the rightmost positions of the array:
Now this is the first time when from the get go we have numbers in the first row smaller than numbers in the second row. We can replace them immediately:
Then again we have two columns where first row has number bigger than the second row. To account for it we subtract 9 - 4 from the last two columns (for the final value of 4 - (9 - 4) = - 1):
Then we merge and discard negative numbers, resulting in the final row:
We will take two nines and two fours for free, and will pay for all the remaining fours. The answer to the problem is the sum of all the values in the last row, so the answer for the case we've just considered is 9 + 9 + 4 + 4 = 26
Now, what if had this array?
It is easy to show that one but last row would be
Then we add two 4s. We can get at most 5 items for free, place two fours into the two rightmost of those 5 columns:
We immediately replace 3 with 4, since it is bigger:
Now we replace items on top:
This case is different from all we considered above, because after this step the array is not sorted. We want to sort the row in this case:
We can check if the result is correct by simulating how much we can save. Clearly with the first two purchases we can save 9 and 9. Then with the third purchase we have two options: pay for 6, get 4 for free (save 4 extra), or pay for one of the 9-s we got for free and get two sixes for free (save 3 extra). In the first case we save more, thus we pay for 6, get 4 for free, then we do it again. Finally, with the last purchase we now pay for 9 and get two 6-s for free, which gives us savings of (9, 9, 4, 4, 3), the same as what we ended up having in the DP table row.
So the final shape of a single iteration is:
Now if you use multisets instead of arrays to represent the row, all these operations can be done in logarithmic time, which makes the entire solution O(nlogn).
Thank you very much, I have solved the problem with your help lol.
Problem B: In fact, if length < 2575 (26*99+1), we can use O(n^2) DP. :)
there's no point of what you say, We can use O(N^2) whenever the length allow us to use it even if this condition is not satisfied (length < 2575) for example length=5000.
but I think you meant: if length>=2575 (26*99+1),we can use the idea of finding a character that is repeated at least 100 times and print it 100 times
Should it be d[l][r] = max(d[l][r-1], d[l + 1][r], s[l] == s[r] ? d[l + 1][r — 1] + 2: 0) instead of 1:0 in problem B?
Yes, but you still have to check case, when l = r, because than, you want add only 1.
So completely correct formula is in my opinion this:
d[l][r] = l == r ? 1 : max(d[l][r - 1], d[l + 1][r], s[l]==s[r] ? d[l + 1][r - 1] + 2 : 0)
The problems were interesting enough! I haven't gueesed the solutions :(
cut ---
404 Not Found