


A. The Power of the Dark Side
(difficulty: easy)
Let's sort the parameters of every Jedi: a ≥ b ≥ c. The "coverted" Jedi obviously wants to use his strongest 2 parameters (ak, bk) against the opponent's weakest 2 (bi, ci) to get 2 victories as assuredly as possible; besides, the optimal order is ak against bi and bk against ci, because if he can win when using them in the opposite order, then he'll win after swapping them, too. So we want to find all Jedis that have ak > bi and bk > ci for all i.
That's simple, because those are the same conditions as ak > B = max(bi) and bk > C = max(ci). When processing the input, we can count B, C and then we just check for every Jedi if he satisfies these 2 conditions, in linear time.
I decided during the contest to code a solution which is a bit slower, but more powerful — it allows us to answer stronger versions of this problem like "which Jedis can we choose, if we're satisfied with them only defeating K other Jedis". The trick I use here is that every Jedi creates 2 pairs: (bi, ci) and (ai, bi); then, for every pair of the 2nd type (and the corresponding Jedi), we want to count how many pairs of the 1st type smaller in both properties there are. For that, we sort the pairs by the first property, and process them in that order; now, we only need to count already processed pairs of 1st type smaller in the 2nd property, which can be done easily using a Fenwick tree, in  time.
time.
B. Similar Strings
(difficulty: easy-medium)
Let's call an "index list" of string s and character c a sequence A of all indices i such that s[i] = c (e.g. s[A[j]] = c for all j and if s[i] = c, then A[j] = i for some j).
The required mapping exists between strings s, t when the index lists of all characters of s form a permutation of those of t. That's because a bijection between characters is just a permutation of index lists. So we could generate all index lists (in an array B) for every string, sort them, and check if 2 strings are similar simply by checking if B[s] = B[t].
The lists can get nasty large, though — just inserting them into a map will TLE for sure. We could at least use the fact that there are not many distinct characters in a string, so B will have reasonably few index lists.
My approach was hashing the values in every index list polynomially. That is, let's denote 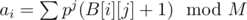 , where p is a prime (I use 999983; it's a good idea to have the prime larger than all possible A[i]) and M is really large prime (I use 10^9+9); then, we replace the index list B[i] by ai.
, where p is a prime (I use 999983; it's a good idea to have the prime larger than all possible A[i]) and M is really large prime (I use 10^9+9); then, we replace the index list B[i] by ai.
Chances are high that no two hashes for distinct index lists would be identical, so comparing two ai is the same as comparing their corresponding index lists. And since integer comparison works really fast compared to the vector one, it's enough to pass the tests when we note, in an STL map, how many strings have this B; for every B given by x strings, it means those x strings are similar, so the answer is a sum of 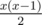 for all B.
for all B.
Time complexity: 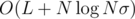 (σ is the alphabet size, at most 26 in this case, and the maximum size of any B, and L is the size of input), for reading the input, producing B for every string, and mapping them; inserting a vector of size S into a map takes
(σ is the alphabet size, at most 26 in this case, and the maximum size of any B, and L is the size of input), for reading the input, producing B for every string, and mapping them; inserting a vector of size S into a map takes 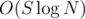 , because comparing vectors takes up to O(S) time.
, because comparing vectors takes up to O(S) time.
C. Victor's Research
(diff: easy-medium)
Let's denote the prefix sums 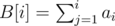 . Then, we're looking for all pairs (i, j) (0 < i ≤ j ≤ N) such that B[j] - B[i - 1] = S. In other words, for every B[j], we're looking for the number of indices i ≤ j such that B[i - 1] = B[j] - S. And since there are just N + 1 prefix sums (including B[0]), we can store them in an STL map.
. Then, we're looking for all pairs (i, j) (0 < i ≤ j ≤ N) such that B[j] - B[i - 1] = S. In other words, for every B[j], we're looking for the number of indices i ≤ j such that B[i - 1] = B[j] - S. And since there are just N + 1 prefix sums (including B[0]), we can store them in an STL map.
Just count the current sum (sa) as we process the input, then count how many times we mapped the prefix sums to sa - S, add it to the answer and add sa to the map. Time: .
Note: with an STL unordered_map (hashmap), we can achieve asymptotic O(1) complexity of map-operations, so we can solve it in optimal O(N) time.
D. Hamming Distance
(diff: easy)
It's clear that characters at different indices don't affect the answer, so we can choose for every position in the resulting string the character that minimizes this position's contribution to Hamming distance.
When we choose a character that's entirely different that the 3 we have, the contribution is 3. If we choose one of those 3, it's at most 2, so that's better already. If there are 2 identical characters, we could choose that, and the distance is at most 1, and if we choose a different one, it's at least 2, so we want to choose that character. If all 3 chars are different, the contribution to Hamming distance is 2 regardless which one we choose.
Following those rules, we can choose the best char in O(1) time, so O(N) for the whole input.
E. Of Groups and Rights
(diff: medium)
Firstly, realize that the groups form a rooted tree, and we're given the ordered pairs (parent,son). Every node of the tree has a state, "allowed" or "denied" or "not set, e.g. state of its parent".
The first thing we should do is complete the list of states. If the root (0) is not set, the root has state "denied". Then, DFS the tree, and when moving into a son with state not set, set it to the parent's state (which is always set, because the root has it set and we only move into a son after its state is set).
Now, we know that if a group contains a user with access denied, the group can't have access allowed, because that'd allow access to that user. The groups a user is contained in correspond, in graph theory, to all vertices on the path from a leaf (representing the user) to the root. So do a BFS from all leafs with denied access; always move to the parent of the current vertex, and mark it as "can't have access allowed in the resulting structure".
The nodes that haven't been marked in the previous step can always have access allowed without violating the rules, because all users in their subtrees have access allowed. But we need to mark as few vertices as possible with "allowed". And it turns out that we need to mark exactly those vertices that haven't been marked with "can't have access allowed" and whose parents have been marked so (this 2nd condition is always true for the root — imagine it as the root being the son of a superroot that can't have access allowed).
That's because if we set "access allowed" to some node in the resulting structure for which we can do it, it's a better solution to set it to allowed for its parent instead — the number of nodes with "allowed" doesn't increase, and the sum of depths decreases by 1. We can see that this setting always makes a user with access allowed in the original structure to have it allowed in this one — if we trace the path to the root, we'll get to a vertex that can't have access allowed or to the root eventually; the vertex on the path before it has access allowed (there's at least one — the leaf we started in). And we can't have less vertices with access allowed, because then, we'd have to remove one of those chosen so far, and that'd cause the leaves under it (at least one) that want access allowed to not have it.
We only do some DFS and BFS (I did 2xBFS, though), so the time required is O(N).
F. Battle Fury
(diff: medium)
The ideal approach to this problem is binary search, because if some number of hits is sufficient, any larger number is also sufficient.
Let's say we need to check if h hits are sufficient. We can split each hit into 2: q to every monster and p - q to the monster we actually hit. So first of all, we can decrease the HP of every monster by hq. We need to hit the still living monsters with at most h hits to decrease all their HPs to zero or below. But we don't have much of a choice there; if a monster has x HP, then we need  hits. Watch out for the case p = q — here, we need all monsters to be already dead after the h "-q" hits. If the sum of hits we need to finish all mosters off is at most h, this value is sufficient; otherwise, it isn't.
hits. Watch out for the case p = q — here, we need all monsters to be already dead after the h "-q" hits. If the sum of hits we need to finish all mosters off is at most h, this value is sufficient; otherwise, it isn't.
We only need 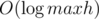 such checks, and one check can be done in linear time, so the total time is
such checks, and one check can be done in linear time, so the total time is 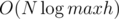 .
.
G. City Square
(diff: medium-hard)
It appears that the condition necessary and sufficient is for N to be a sum of squares: N = a2 + b2, with a, b ≥ 0. I don't know why that works, but it works. I'll write it if I find out, or you can write it in th comments if you know :D
How to check if it's a sum of squares? It's clear that 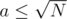 , so we can try all a-s and for each of them, check if N - a2 is a perfect square. Thanks to the sqrt() function, we can do that in O(1) time, so the total time complexity is
, so we can try all a-s and for each of them, check if N - a2 is a perfect square. Thanks to the sqrt() function, we can do that in O(1) time, so the total time complexity is  .
.
H. Secret Information
(diff: easy)
Let's make another string s, with s[i] = 0 if the i-th numbers in the input strings are equal (both 0 or both 1), and s[i] = 1 otherwise. XOR, basically.
The answer is the number of groups of consecutive 1-s in s (we always mean the largest we can make, e.g. bounded by 0-s or the borders of the string). Proof: if we swap the numbers in some interval that contains k such groups, it contains at least k - 1 groups of consecutive zeroes (between those groups of ones), which will turn into groups of ones, bounded by zeroes on their sides; therefore, any operation can decrease the number of groups of consecutive 1-s at most by one. So if there are K such groups in the whole string, we need at least K operations. That's also sufficient, just choose one group of consecutive ones in every operation.
Counting those groups is easy, for example by using the fact that every such group is determined uniquely by its first 1 — so K is the number of pairs s[i] = 0, s[i + 1] = 1, plus 1 if s[0] = 1 (there's no 0 before that one). Time: O(N).
I. Meteor Flow
(diff: medium)
The condition from the problem can be formulated as: for every i (with subset of not shot meteors with t ≤ ti denoted as S), 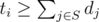 .
.
The trick here is that we don't have to decide immediately if we'll need to shoot down a meteor to prevent breaching the shield later, we can decide to do it only when facing that risk. And if it's happening, the best meteor to shoot down is the one we haven't shot yet (but have processed already, e.g. tj ≤ ti) and causes the largest damage.
So, we process the meteors by increasing time, and store ones we haven't shot (including the one currently being processed) in a heap; we also remember the damage they do. As long as the damage is too large, we just shoot the most damaging meteor, and update the total damage. Time: because we add/remove every meteor to/from the heap at most once.
This really gives the optimal solution, because shooting down meteors doesn't worsen the situation after processing any earlier meteor, and choosing to shoot the most damaging meteor doesn't worsen any later situation, wither (it gives us the minimum damages to the shield in all later situations). And as long as the shield is safe, we don't have to shoot any more yet, so we don't do it.
J. The Best Statement
(diff: easy-medium)
The statements that can be chosen form a subsequence strictly increasing in ai, because if k is given, all statements that have ai < k won't be chosen, and the first one with ai ≥ k will — so if ai ≤ aj and i > j, then if k is sufficient for i to be chosen, then it's also sufficient for j.
This sequence can be produced directly when reading the input: we remember the largest ai yet seen, and add the currently processed ai to the sequence if it's strictly larger. And it's possible to choose k matching the choice of any of those statements, by simply setting it equal to that ai.
We're not interested in as, though. We want to choose the largest b. We see that we can choose any statement in our sequence, so we choose the one with largest b. Done.
Time complexity is clearly O(N).
K. Three Contests
(diff: medium-hard)
A pair (i, j) isn't counted if ai < aj, bi < bj, ci < cj; otherwise, it is, because there are 2 contest (w.l.o.g. a, b) such that ai < aj and bi > bj, so team i considers itself stronger based on contest b, and so does j based on contest a. Let's say there are x such pairs; there are
Unable to parse markup [type=CF_TEX]
pairs in total, so the answer is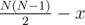 .
.Let's sort and process the teams in increasing order of ai. Then, we need to count the number of teams that have both bj and cj smaller than bi and ci, respectively. This reminds me a lot of problem Game from IOI 2013, just that it's an offline problem, the coordinates (if we imagine it is points in a coordinate plane) are already small, and we're only looking for a sum, which has an inverse operation, unlike GCD. We could still solve it with a compressed 2D interval tree in 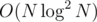 time, but that's way too ugly to implement.
time, but that's way too ugly to implement.
It's much simpler to just think about an sqrt{N} solution. Firstly, let's think about queries "count the number of points in rectagle with border points (0, 0) and (x, y)"; the update "add point (x, y)" is then quite easy. We can use the fact that all points have both coordinates different and small ( ≤ N), and note for every x the y corresponding to it (if there's no such y yet, just set it larger than N so it won't be counted) as A[x], and similarly for every y the x corresponding to it as B[y]. Let's also choose a constant K (over  , I chose 500 for this case) and make an 2D Fenwick tree F, in which we remember F[i][j] as the number of points with
, I chose 500 for this case) and make an 2D Fenwick tree F, in which we remember F[i][j] as the number of points with 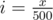 and
and 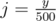 (integer division); its dimensions are then just 400x400.
(integer division); its dimensions are then just 400x400.
How do we count points now? Firstly, we can just check the already added points with x-coordinates from x - x%500 to x, and count how many of them have the other coordinate < y. Then, we can say that x = x - x%500, and do the same with y-coordinate. We're left with a rectangle made entirely of smaller 500x500 rectangles, which is a rectangle with border points (0, 0) and 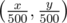 in our BIT (Fenwick tree). And that's just 1 query. The updates are even simpler: set A[x] (the original x) to y, B[y] to x, and add 1 to
in our BIT (Fenwick tree). And that's just 1 query. The updates are even simpler: set A[x] (the original x) to y, B[y] to x, and add 1 to 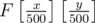 .
.
This approach has time complexity
Unable to parse markup [type=CF_TEX]
(the first term is for checking all coordinates modulo K, the second one for operations on a 2D BIT), which passes comfortably.L. For the Honest Election
(diff: easy-medium)
What's the minimum number of people in the first option? If we have a group of size N, and K out of them are P's followers, the worst case is if the remaining N - K are his opponents; in that case, all K vote for one of them, and all N - K for one of them. For P to certainly win, his supporter must get strictly more votes, so K > N - K, e.g. 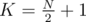 (division is classical integer division here) must be the supporters.
(division is classical integer division here) must be the supporters.
Let's now denote the answer (considering both options) for N as A[N].
In option 2, we have M groups of size 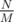 ; M is a divisor of N. Those form one group of size . We need the supporter of P to win that group, and for that, we need
; M is a divisor of N. Those form one group of size . We need the supporter of P to win that group, and for that, we need  groups to be won. There's no point in sending any supporters of P into the other groups, so the answer for this M is
groups to be won. There's no point in sending any supporters of P into the other groups, so the answer for this M is 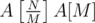 .
.
However, P's friend can choose the option and M (in case of option 2) that minimize the number of people. So if we want to find A[N], we find A[M] for all divisors, in the same way using dynamic programming, and choose the minimum of and 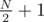 for A[N].
for A[N].
DP on all numbers smaller than N is obviously too slow, but we can use the fact that all numbers i for which we'd need to compute A[i] this way are also divisors of N, so we can just do DP on divisors, and remember the values for example in an STL map or the previously mentioned hashmap (so the complexity of inserting/finding A[i] for some i is O(1)).
N has at most around 1500 divisors (http://www.javascripter.net/math/calculators/ramanujanhighlycompositenumberslist2.jpg), so even if we try divisibility by all numbers up to to generate all divisors of every one of those divisors, it's fast enough to pass the tests. Asymptotically, if we assumed N to have d divisors, if we had to try divisibility by numbers up to for all of them, it'd be O(N) time, but in reality, it has a small constant because 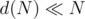 — it's something like O(0.001N) for the largest inputs.
— it's something like O(0.001N) for the largest inputs.







{kind=link}
Thank you, Xellos!
sqrt(n) works in O(1) or O(logn)?
I heard it's O(1) because it looks up the value in a table or something.
is it possible to submit somewhere solutions?
Sure. Just go to the contest (click Enter), and click Register for practice. Then, you'll be able to submit normally (but you won't see the test data until you get Accepted).
sure, but where is the link on context though? :)
go to Gym, and on top of the page, there's the contest on the left, there's the contest's name, and below the name is a hypertext link "Enter" (and another one, "Virtual participation")
If you attach the blog to the contest, the link to this contest will appear just above the blog's tags.
By the way, smth about L. You can solve the next problem: given N (1 <= N <= 1018), calculate the worst case time for your algo:
Also,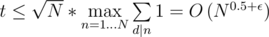
Actually, I thought the bound was tighter than and tried googling stuff that'd show it, but it didn't work, so I just threw the obvious
and tried googling stuff that'd show it, but it didn't work, so I just threw the obvious  there. It's good to see it was a good idea :D
there. It's good to see it was a good idea :D
I have an easier solution for problem B.
For each string, map each character according to the order of how appears, for example (if characters were numbers)
abacaba -> 1213121
because "a" appears first, then "b" and finally "c".
Then map each resulting string with his frecuency ( for all N strings it cost NlogN) and those are strings which are similiar. The total quantity of pairs would be, for each string, map[s]*(map[s]-1)/2
Here is my code for more clarity http://pastebin.com/KmDWtTD2