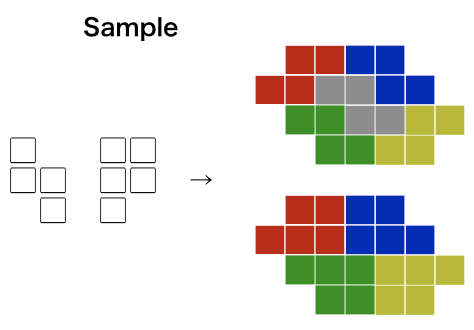
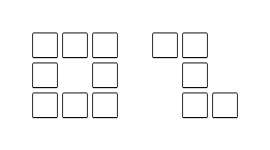
Div2 A Appleman and Easy Task (Author: EnumerativeCombinatorics)
This is a simple implementation problem. You can solve by searching adjacent cells of every cell.
Div2 B Appleman and Card Game (Author: EnumerativeCombinatorics)
This is simple greedy problem, but it seemed to be reading-hard. The statement says, "Choose K cards from N cards, the score of each card is (the number of cards which has the same character in K cards. (not in N cards)"
It is clear that this total score is (the number of 'A' in K cards)^2 + (the number of 'B' in K cards)^2 + ... + (the number of 'Z' in K cards)^2 This value will be maximized by the simple greedy algorithm, take K cards from most appearred character in N cards, the second most appearred character in N cards, and so on.
Div1 A / Div2 C Appleman and Toastman (Author: hogloid)
First I describe the algorithm, and explain why it works.
- Sort {ai} in non-decreasing order.
- Then, for i-th number, add (i + 1) * ai to the result.(i=1...n-1)
- For n-th number, add n * an to the result.
Actually, when you multiply all numbers by -1,the answer will be the minimal possible value, multiplied by -1.
It's Huffman coding problem to find minimal possible value. Solving Huffman coding also can be solved in O(nlogn)
In Huffman coding, push all the numbers to a priority queue. While the size of the queue is larger than 2, delete the minimal and second-minimal element, add the sum of these two to the cost, and push the sum to the queue. Here, since all the numbers are negative, the pushed sum will be remain in the first in the queue. Analyzing this movement will lead to the first algorithm.
Div1 B / Div2 D Appleman and Tree (Author: hogloid)
Fill a DP table such as the following bottom-up:
- DP[v][0] = the number of ways that the subtree rooted at vertex v has no black vertex.
- DP[v][1] = the number of ways that the subtree rooted at vertex v has one black vertex.
The recursion pseudo code is folloing:
DFS(v):
DP[v][0] = 1
DP[v][1] = 0
foreach u : the children of vertex v
DFS(u)
DP[v][1] *= DP[u][0]
DP[v][1] += DP[v][0]*DP[u][1]
DP[v][0] *= DP[u][0]
if x[v] == 1:
DP[v][1] = DP[v][0]
else:
DP[v][0] += DP[v][1]
The answer is DP[root][1].
UPD:
The above code calculate the DP table while regarding that the vertex v is white (x[v]==0) in the foreach loop.
After that the code thinks about the color of vertex v and whether we cut the edge connecting vertex v and its parent or not in "if x[v] == 1: DP[v][1] = DP[v][0] else: DP[v][0] += DP[v][1]".
Div1 C / Div2 E Appleman and a Sheet of Paper (Author: snuke)
For each first type queries that p_i > (the length of the paper) — p_i, you should express the operation in another way: not fold the left side of the paper but fold the right side of the paper. After such query you need to think as the paper is flipped.
Let's define count[i] as the number of papers piled up at the segment [i,i+1] (absolute position). For each query of first type you can update each changed count[i] naively.
Use BIT or segment tree for count[i] because you can answer each second type queries in O(log n). The complexity of a first type query is O((the decrement of the length of the paper) log n) so total complexity of a first type query is O(n log n).
Div1 D Appleman and Complicated Task (Author: EnumerativeCombinatorics,snuke)
First, we ignore the already drawn cell and dependence of cells. If we decide the first row, then the entire board can decided uniquely. We call 'o' is 1, and 'x' is 0. Then,
a[i][j] = a[i-2][j] xor a[i-1][j-1] xor a[i-1][j+1]
For example, I'll explain n=5 case. Each column of first row is a, b, c, d, and e. "ac" means a xor c.
a b c d e
b ac bd ce d
c bd ace bd c
d ce bd ac b
e d c b a
Each character affects the following cells (denoted 'o').
o.... .o... ..o.. ...o. ....o
.o... o.o.. .o.o. ..o.o ...o.
..o.. .o.o. o.o.o .o.o. ..o..
...o. ..o.o .o.o. o.o.. .o...
....o ...o. ..o.. .o... o....
Generally we can prove the dependence that a[0][k] affects a[i][j] if k<=i+j<=2(n-1)-k and |i-j|<=k and k%2==(i+j)%2. ... (*)
We can separate the problems by (i+j) is odd or even.
Each (i,j), we can get the range of k that affects the cell (i,j) by using formula (*). So the essence of this problem is that "There is a sequence with n integers, each of them is 0 or 1. We know some (i,j,k) where a[i]^a[i+1]^...^a[j]=k. How many possible this sequences are there?" We can solve this problem by using union-find. At first, there is n*2 vertices. If k is 1, we'll connect (i*2,(j+1)*2+1) and (i*2+1,(j+1)*2), if k is 0, we'll connect (i*2,(j+1)*2) and (i*2+1,(j+1)*2+1) (note that i<=j). If both i*2 and i*2+1 are in the same set for any i, the answer is 0. Otherwise the answer is 2^((the number of sets-2)/2).
Also, it is possible to solve odd number version. (How many ways to fill all the empty cells with 'x' or 'o' (each cell must contain only one character in the end) are there, such that for each cell the number of adjacent cells with 'o' will be "odd"? ) I'll hope for your challenge for odd-number version!!
Div1 E Appleman and a Game (Author: hogloid,snuke)
Let C be the number of characters(here, C=4)
Given string S, the way to achieve minimum steps is as follows: Append one of the longest substring of T that fits current position of string S. Appending a not-longest substring can be replaced by appending longest substring and shortening the next substring appended.
Let dp[K][c1][c2] be defined as :
the minimum length of string that can be obtained by appending a string K times and that starts by character c1 and whose next character is c2. Note that next character is not counted in the length.
dp[1] can be calculated as follows:
For every string of length L expressed by C characters, if the string is not included in T, update the dp table as dp[1][the string's first character][its last character]=min(dp[1][its first character][its last character],L-1)
For any (c1,c2), dp[1][c1][c2] is smaller than or equal to log_C(T+1)+2 (since the kind of strings of length log_C(T+1)+2 that start by c1 and end by c2 is equals to T+1). Therefore for L=1...log(T+1)+2, try all the strings as described above.
Also we can use trie that contains all substrings of T of length log_C(T+1)+2, and find what can't be described as a substring of T by one step.
Since dp[k+1][c1][c2]=min(dp[k][c1][c3]+dp[1][c3][c2] | c3=1...C), we can use matrix multiplication to get dp[K].
For a integer K, if there is (c1,c2) such that dp[K][c1][c2]<|S|, the answer is greater than K. Otherwise,the answer is smaller than or equal to K.
Since answer is bigger or equal to 1 and smaller or equal to |S|, we can use binary search to find the ansewr.
O(T*((log T)^2+C^2)+C^3(log |S|)^2)
BONUS: Is there any algorithm that solves in O(1) or O(C^foo)(that is, not depended on |S|) for each |S| with pre-calc?
Some hints: Maximal value of dp[1][*][*] — Minimal value of dp[1][*][*] <= 2
(let's call the maximal value dp[1][i][j]=L. Here, any C^(L-2) strings are contained in T as substring, so for any (c1,c2), dp[1][c1][c2]>=L-2)
Maximal value of dp[1][k][*] — minimal value of dp[1][k][*] <=1 ( k=1...C)
Maximal value of dp[1][*][k] — minimal value of dp[1][*][k] <=1 ( k=1...C)
Even if we use these hints and make C=3, the implementation would be not easy.
If you come up with smart way, please comment here :)