There is a couple of things about sparse tables that a lot of people I think are doing slightly wrong (including the popular reference implementation by e-maxx).
First, you don't need to precalculate and store logarithms in an array. In fact, whichever procedure compiler will pick to calculate the logarithm is probably going to be much faster than looking it up somewhere in random access memory. The optimal way would be to use __builtin_clz ("count leading zeroes") which uses a separate instruction available on most modern x86's. This way you need just 2 memory reads instead of 3, so on large arrays this should be ~1.5x faster.
Second, memory layout and the order you iterate it matters when you're building the sparse table. There is a total of $$$2 \times 2 = 4$$$ ways to do it, and only one of them results in beautiful linear passes that work 1.5-2x faster.
It's easier to implement too:
int a[maxn], mn[logn][maxn];
int rmq(int l, int r) { // [l; r)
int t = __lg(r - l);
return min(mn[t][l], mn[t][r - (1 << t)]);
}
// somewhere in main:
memcpy(mn[0], a, sizeof a);
for (int l = 0; l < logn - 1; l++)
for (int i = 0; i + (2 << l) <= n; i++)
mn[l+1][i] = min(mn[l][i], mn[l][i + (1 << l)]);
Implementation was updated (tnx jef and plainstop):
original query implementationint lg(int x) {
return 31 - __builtin_clz(x);
}
int rmq(int l, int r) { // [l; r)
int t = lg(r - l);
return min(mn[l][t], mn[r - (1 << t)][t]);
Also, it's interesting that the last loop is not getting auto-vectorized by the compiler (because std::min is probably something overly complex), and replacing it with simple (x < y ? x : y) gets total speed up to ~3x if you include avx2, but I personally wouldn't do this because it looks cumbersome:
int x = mn[l][i];
int y = mn[l][i + (1 << l)];
mn[l+1][i] = (x < y ? x : y);
(Testing performed on my laptop; didn't run it on CF or other online judges.)
Full text and comments »










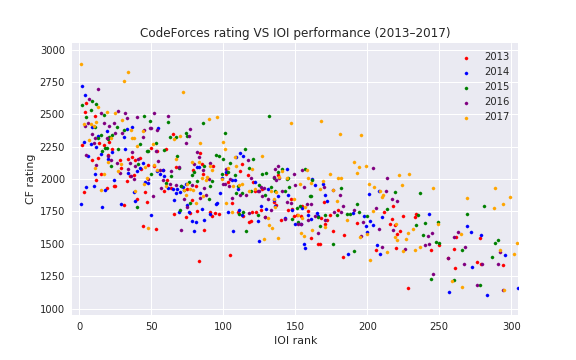
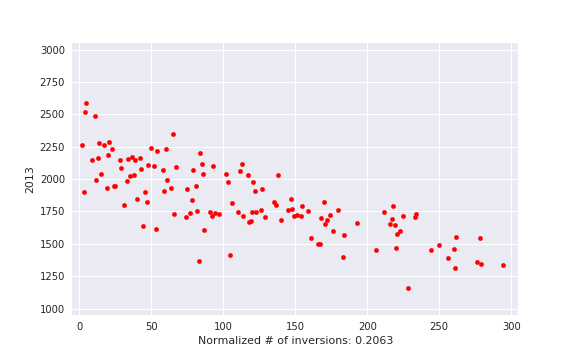
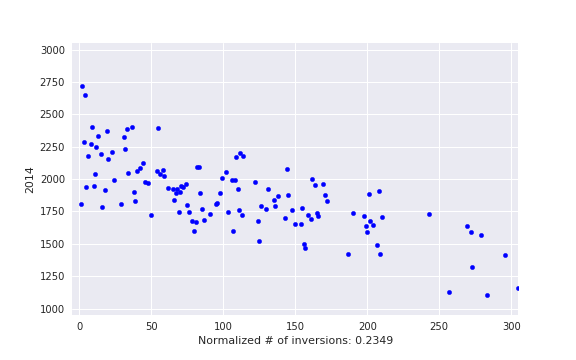
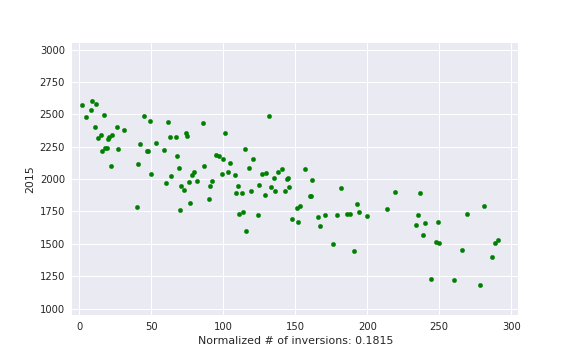
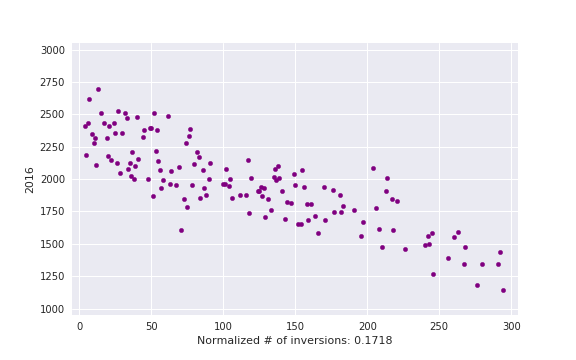
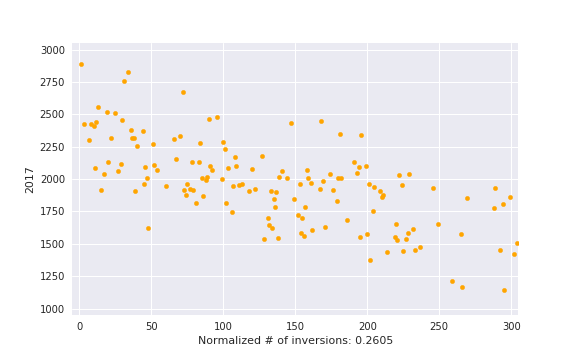
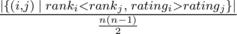 , i. e. actual number of inversions divided by maximum possible. This is some kind of measure of a contest being close to a standard CF round.
, i. e. actual number of inversions divided by maximum possible. This is some kind of measure of a contest being close to a standard CF round.
