


Introduction
There are a number of "small" algorithms and facts that come up again and again in problems. I feel like there I have had to explain them many times, partly because there are no blogs about them. On the other hand, writing a blog about them is also weird because there is not that much to be said. To settle these things "once and for all", I decided to write my own list about about common "small tricks" that don't really warrant a full tutorial because they can be adequately explained in a paragraph or two and there often isn't really anything to add except for padding.
This blog is partly inspired by adamant's blog from a few years ago. At first, I wanted to mimic adamant's blog structure exactly, but I found myself wanting to write longer paragraphs and using just bolded sentences as section headers got messy. Still, each section is short enough that it would not make much sense to write separate blogs about each of these things.
All of this is well-known to some people, I don't claim ownership or novelty of any idea here.
1. Memory optimization of bitset solutions
In particular, reachable nodes in a DAG. Consider the following problem. Given a DAG with $$$n$$$ vertices and $$$m$$$ edges, you are given $$$q$$$ queries of the form "is the vertex $$$v$$$ reachable from the vertex $$$u$$$". $$$n, m, q \le 10^5$$$. The memory limit does not allow $$$O(n^2)$$$ or similar space complexity. This includes making $$$n$$$ bitsets of length $$$n$$$.
A classical bitset solution is to let $$$\mathrm{dp}[v]$$$ be a bitset such that $$$\mathrm{dp}[v][u] = 1$$$ iff $$$v$$$ is reachable from $$$u$$$. Then $$$\mathrm{dp}[v]$$$ can be calculated simply by taking the bitwise or of all its immediate predecessors and then setting the $$$v$$$-th bit to 1. This solution almost works, but storing $$$10^5$$$ bitsets of size $$$10^5$$$ takes too much memory in most cases. To get around this, we use 64-bit integers instead of bitsets and repeat this procedure $$$\frac{n}{64}$$$ times. In the $$$k$$$-th phase of this algorithm, we let $$$\mathrm{dp}[v]$$$ be a 64-bit integer that stores whether $$$v$$$ is reachable from the vertices $$$64k, 64k + 1, \ldots, 64k + 63$$$.
In certain circles, this problem has achieved a strange meme status. Partly, I think it is due to how understanding of the problem develops. At first, you don't know how to solve the problem. Then, you solve it with bitsets. Then, you realize it doesn't work and finally you learn how to really solve it. Also, it is common to see someone asking how to solve this, then someone else will always reply something along the lines of "oh, you foolish person, don't you realize it is just bitsets?" and then you get to tell them that they're also wrong.
Besides the classical reachability problem, I also solved AGC 041 E this way.
2. Avoiding logs in Mo's algorithm
Consider the following problem. Given an array $$$A$$$ of length $$$n$$$ and $$$n$$$ queries of the form "given $$$l$$$ and $$$r$$$, find the MEX of $$$A[l], \ldots, A[r]$$$". Queries are offline, i.e. all queries are given in the input at the beginning, it is not necessary to answer a query before reading the next one. $$$n \le 10^5$$$.
The problem can also be solved with segment trees avoiding a square-root factor altogether. In this blog however, we consider Mo's algorithm. Don't worry, this idea can be applied in many situations and a segment tree solution might not always be possible.
A first attempt at solving might go like this. As always, we maintain an active segment. We keep a set<int> of all integers up to $$$n$$$ that are not represented in the active segment, and an auxiliary array to count how many times each number appears in the active segment. In $$$O(\log n)$$$ time we can move an endpoint of the active segment, and in $$$O(\log n)$$$ time we can find the MEX of the active segment. We move the endpoints one by one to go through all queries, and if the queries are sorted in a certain magical order, we get $$$O(n \sqrt n \log n)$$$ complexity. Unfortunately, this is too slow; also $$$O(n \sqrt n \log n)$$$ is an altogether evil complexity and should be avoided at all costs.
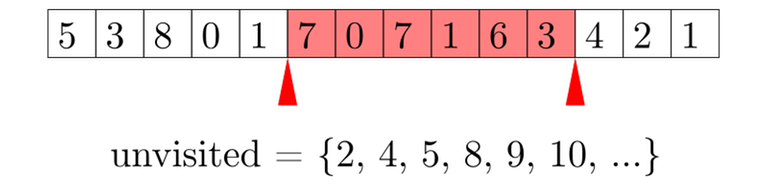
Clearly, set<int> is a bottleneck. Why do we use it? We need to support the following operations on a set:
- Insert an element. Currently $$$O(\log n)$$$. Called $$$O(n \sqrt n)$$$ times.
- Remove an element. Currently $$$O(\log n)$$$. Called $$$O(n \sqrt n)$$$ times.
- Find the minimum element. Currently $$$O(\log n)$$$. Called $$$O(n)$$$ times.
Note that operations 1 and 2 are more frequent than 3, but they take the same amount of time. To optimize, we should "balance" this: we need 1 and 2 to be faster, but it's fine if this comes at the expense of a slightly slower operation 3. What we need is a data structure that does the following:
- Insert an element in $$$O(1)$$$.
- Delete an element in $$$O(1)$$$.
- Find the minimum element in $$$O(\sqrt n)$$$.
This should be treated as the main part of the trick: to make sure endpoints can be moved in $$$O(1)$$$ time, potentially at the expense of query time. How the data structure actually works is actually even not that important; in a different problem, this data structure might be something different.
3. Square root optimization of knapsack/"$$$3k$$$ trick"
Assume you have $$$n$$$ rocks with nonnegative integer weights $$$a_1, a_2, \ldots, a_n$$$ such that $$$a_1+a_2+\cdots+a_n = m$$$. You want to find out if there is a way to choose some rocks such that their total weight is $$$w$$$.
Suppose there are three rocks with equal weights $$$a, a, a$$$. Notice that it doesn't make any difference if we replace these three rocks with two rocks with weights $$$a, 2a$$$. We can repeat this process of replacing until there are at most two rocks of each weight. The sum of weights is still $$$m$$$, so there can be only $$$O(\sqrt m)$$$ rocks (see next point). Now you can use a classical DP algorithm but with only $$$O(\sqrt m)$$$ elements, which can be lead to a better complexity in many cases.
This trick mostly comes up when the $$$a_1, a_2, \ldots, a_n$$$ form a partition of some kind. For example, maybe they represent connected components of a graph. See the example.
4. Number of unique elements in a partition
This is also adamant's number 13, but I decided to repeat it because it ties into the previous point. Assume there are $$$n$$$ nonnegative integers $$$a_1, a_2, \ldots, a_n$$$ such that $$$a_1 + a_2 + \cdots + a_n = m$$$. Then there are only $$$O(\sqrt m)$$$ distinct values among $$$a_1, a_2, \ldots, a_n$$$.
5. Removing elements from a knapsack
Suppose there are $$$n$$$ rocks, each with a weight $$$w_i$$$. You are maintaining an array $$$\mathrm{dp}[i]$$$, where $$$\mathrm{dp}[i]$$$ is the number of ways to pick a subset of rocks with total weight exactly $$$i$$$.
Adding a new item is classical:
1 # we go from large to small so that the already updated dp values won't affect any calculations
2 for (int i = dp.size() - 1; i >= weight; i--) {
3 dp[i] += dp[i - weight];
4 }
To undo what we just did, we can simply do everything backwards.
1 # this moves the array back to the state as it was before the item was added
2 for (int i = weight; i < dp.size(); i++) {
3 dp[i] -= dp[i - weight];
4 }
Notice however, that the array $$$\mathrm{dp}$$$ does not in any way depend on the order the items were added. So in fact, the code above will correctly delete any one element with weight weight from the array — we can just pretend that it was the last one added to prove the correctness.
If the objective is to check whether it is possible to make a certain total weight (instead of counting the number of ways), we can use a variation of this trick. We will still count the number of ways in $$$\mathrm{dp}$$$ and check whether it is nonzero. Since the numbers will become very large, we will take it modulo a large prime. This introduces the possibility of a false negative, but if we pick a large enough random mod (we can even use a 64-bit mod if necessary), this should not be a big issue; with high probability the answers will be correct.
6. Estimate of the harmonic numbers
This refers to the fact that
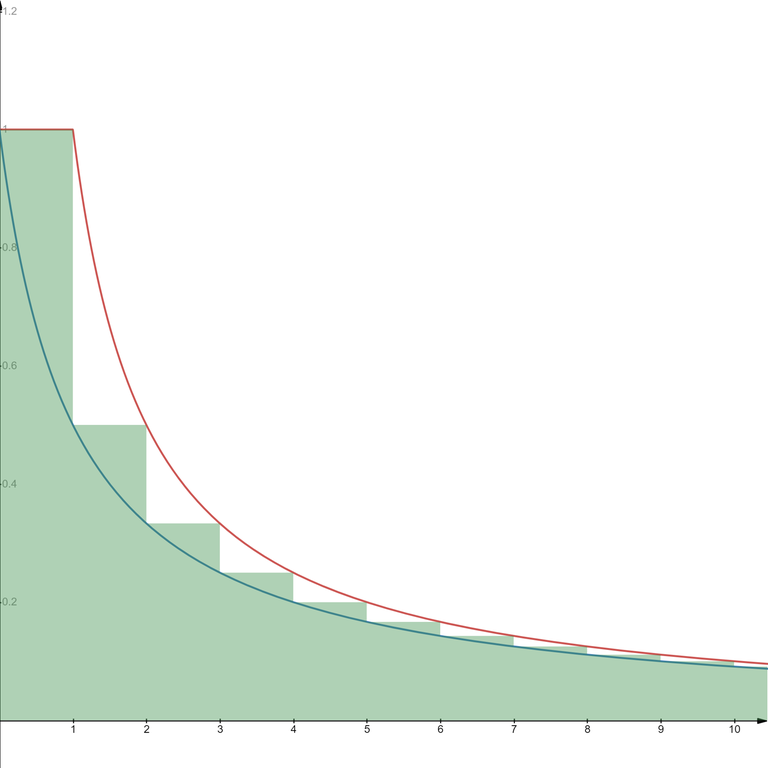
This fact is useful in calculating complexities of certain algorithms. In particular, this is common in algorithms that look like this:
1 for i in 1..n:
2 for (int k = i; k <= n; k += i):
3 # whatever
For a fixed $$$i$$$, no more than $$$\frac{n}{i}$$$ values of $$$k$$$ will be visited, so the total number of hits to line 3 will be no more than
so the complexity of this part of the algorithm is $$$O(n \log n)$$$.
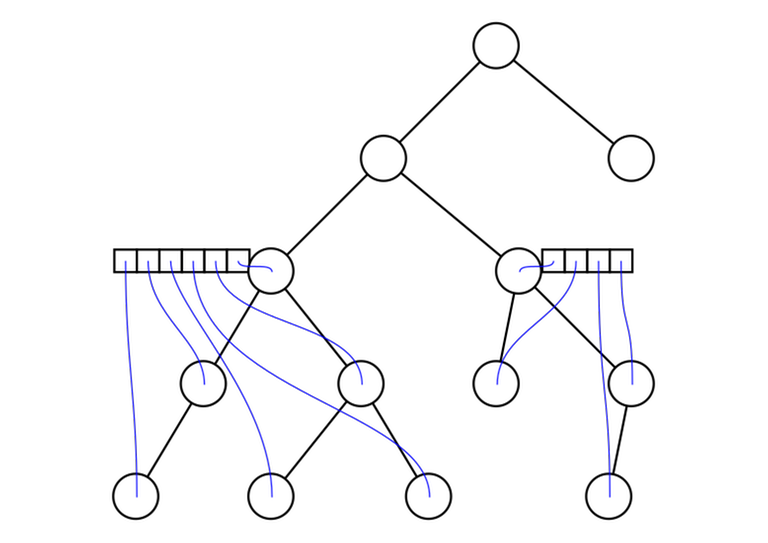
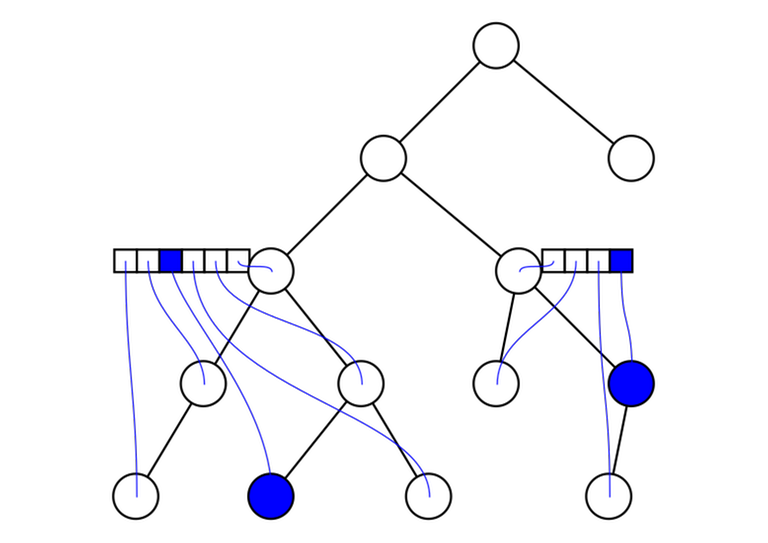
7. $$$O(n^2)$$$ complexity of certain tree DPs
Suppose you are solving a tree problem with dynamic programming. Your DP states look like this: for every vertex $$$u$$$ you have a vector $$$dp[u]$$$ and the length of this vector is at most the number of descendants of $$$u$$$. The DP is calculated like this:
1 function calc_dp (u):
2 for each child v of u:
3 calc_dp(v)
4 for each child v of u:
5 for each child w of u other than v:
6 for i in 0..length(dp[v])-1:
7 for j in in 0..length(dp[w])-1:
8 # calculate something
9 # typically based on dp[v][i] and dp[w][j]
10 # commonly assign to dp[u][i + j]
11
12 calc_dp(root)
The complexity of this is $$$O(n^2)$$$ (this is not obvious: when I first saw it I didn't realize it was better than cubic).
8. Probabilistic treatment of number theoretic objects
This trick is not mathematically rigorous. Still, it is useful and somewhat reliable for use in heuristic/"proof by AC” algorithms. The idea is to pretend that things in number theory are just random. Examples:
- Pretend the prime numbers are a random subset of the natural numbers, where a number $$$n \ge 2$$$ is prime with probability $$$\frac1{\log n}$$$.
- Let $$$p > 2$$$ be prime. Pretend that the quadratic residues modulo $$$p$$$ are a random subset of $$$1, \ldots, p-1$$$, where a number is a quadratic residue with probability $$$\frac12$$$.
A quadratic residue modulo $$$p$$$ is any number $$$a$$$ that can be represented as a square modulo $$$p$$$; that is, there exists some $$$b$$$ such that $$$a \equiv b^2 \pmod{p}$$$.
The actual, mathematically true facts:
- There are $$$\Theta \left( \frac{n}{\log n} \right)$$$ primes up to $$$n$$$.
- Given a prime $$$p > 2$$$, there are exactly $$$\frac{p - 1}{2}$$$ quadratic residues.
Many actual, practical number theoretic algorithms use these ideas. For example, Pollard's rho algorithm works by pretending that a certain sequence $$$x_i \equiv x^2_{i - 1} + 1 \pmod{n}$$$ is a sequence of random numbers. Even the famous Goldbach's conjecture can be seen as a variation of this trick. On a lighter note, this is also why it is possible to find prime numbers like this:
Prime numbers are plentiful, so it's easy to create such pictures by taking a base picture and changing positions randomly.
9. LCAs induced by a subset of vertices
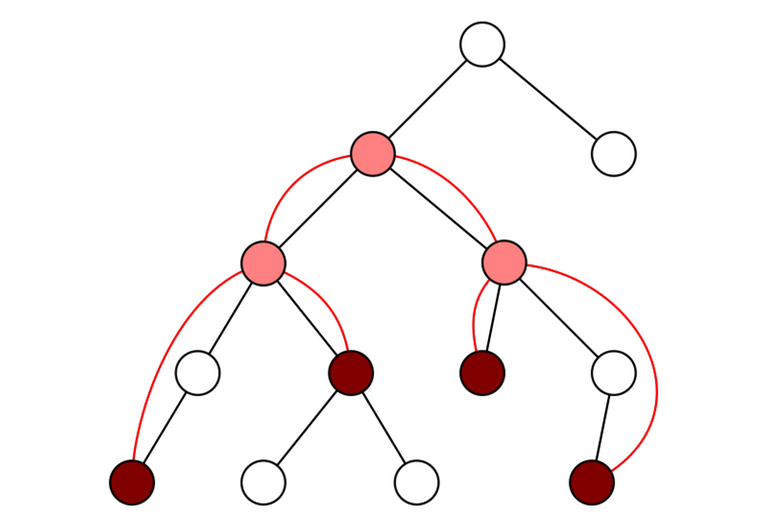
Given a tree and a subset of vertices $$$v_1, v_2, \ldots, v_m$$$. Let's reorder them in the (preorder) DFS order. For any $$$i$$$ and $$$j$$$ with $$$v_i \ne v_j$$$, $$$\mathrm{lca}(v_i, v_j) = \mathrm{lca}(v_k, v_{k + 1})$$$ for some $$$k$$$. In other words: the lowest common ancestor of any two vertices in the array can be represented as the lowest common ancestor of two adjacent vertices.
10. Erdős–Szekeres theorem
Consider a permutation $$$p$$$ with length $$$n$$$. At least one of the following is true:
- There exists an increasing subsequence with length $$$\sqrt{n}$$$.
- There exists a decreasing subsequence with length $$$\sqrt{n}$$$.
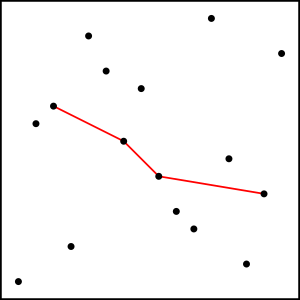
On this image we can see one possible decreasing subsequence of length 4 in a permutation of length 16. There are many options, some longer than 4.
Alternatively, we may phrase this as a fact about the longest increasing and decreasing sequences.
Thank you for reading! 10 is a good number, I think I've reached a good length of a blog post for now.






also this problem for the first trick
Thanks for the blog. Here are more random tricks that I was reminding off while reading the blog that maybe isnt too well known. (Again, I don't claim ownership or novelty of any idea here.)
O(n) complexity for some tree DPs
Let's say we have some tree DP where we can merge $$$2$$$ DP states of size $$$a$$$ and $$$b$$$ in complexity $$$O(\min(a,b) \cdot f(n))$$$ to get a DP state of size $$$a+b$$$.
Everyone knows by small to large trick that we can do this DP can be done in $$$O(n \log n \cdot f(n))$$$.
But some DPs, we can do it in $$$O(n)$$$ if the DP states of size $$$a$$$ and $$$b$$$ form a DP state of size $$$\max(a,b)$$$. This is because every node is merged exactly once! We can imagine that when states in $$$a$$$ are merged into $$$b$$$, they just disappear.
So we can actually solve the problem of finding all pairs that are exactly distance $$$K$$$ from each other on a tree in $$$O(n)$$$ using this trick since the size of our state is the depth of the subtree, and merging 2 subtrees, you get a state that is the maximum over the depth of both subtrees.
O(nk) complexity for some tree DPs
There is a generalization of the $$$O(n^2)$$$ complexity of certain tree DPs. Suppose instead of the vector being the length of the subtree of $$$u$$$, it is the minimum of $$$k$$$ and the length of the subtree of $$$u$$$.
It may seem that this DP is $$$O(nk^2)$$$, but it is actually $$$O(nk)$$$.
Let's think about why this is true. It has the same idea as the visual proof presented here, except lets label all vertices by their preorder, then I claim this is same as iterating over all pairs $$$a$$$ and $$$b$$$ such that $$$|pre[a]-pre[b]| \leq 2K$$$.
Instead of a list in each node, let's make a queue with at most $$$2K$$$ people (where we insert based on their preorder). For $$$a$$$ and $$$b$$$ to exists at their lca queue at the same time, so it must hold that $$$|pre[a]-pre[b]| \leq 2K$$$. We need $$$2K$$$ and not $$$K$$$ because if we are merging $$$2$$$ states both of size $$$K$$$, the "gap" between the furthest 2 elements is around $$$2K$$$. Therefore, it is clear why the complexity is bounded by $$$O(nk)$$$.
If you merge two subtrees in $$$O(min(depth_1, depth_2))$$$, you get exactly $$$n-treeDepth$$$ operations in total. This exact formula is easier to understand and prove.
Speaking of seeing Errichto here, he and I made a video about the problem mentioned in Trick #10, which you can check out here if you're interested.
Can you post proof then?
1) Visual proof: put one token in every node. When merging two subtrees, pay the cost by removing tokens from the more shallow subtree. The remaining tokens form a path to the deepest leaf.
Let $$$S[v]$$$ denote the subtree size of $$$v$$$, and let $$$D[v]$$$ denote the subtree depth. It takes $$$min(D[c_1], D[c_2])$$$ operations to merge two children $$$c_1$$$, $$$c_2$$$.
Lemma: we need exactly $$$S[v] - D[v]$$$ operations in the subtree of $$$v$$$.
Proof: Consider a node $$$v$$$ with two children $$$c_1$$$ and $$$c_2$$$. By induction, we already used $$$S[c_1] - D[c_1] + S[c_2] - D[C_2]$$$ operations. Add merging to get the total: $$$S[c_1] - D[c_1] + S[c_2] - D[C_2] + min(D[c_1], D[c_2]) = S[c_1] + S[c_2] - max(D[c_1], D[c_2])$$$. New dp size is $$$max(D[c_1], D[c_2])$$$. If you merge with a third child, you will get the sum $$$S[c_1] + S[c_2] + S[c_3] - max(D[c_1], D[c_2], D[c_3])$$$, and so on. Finally, let's notice that $$$((\sum{S[c_i]}) + 1) - (max(D[c_i]) + 1) = S[v] - D[v]$$$.
Thank you! Here is a problem (CF 816.E) relate to the second technique.
I've been trying to grasp the $$$O(nk)$$$ generalization of trick 7, but have been struggling for a while now. I think I understand the $$$O(n^2)$$$ from the main blog though.
Mainly, I don't see why $$$|pre[a] - pre[b] \leq 2K$$$. Would anyone be able to elaborate on the proof?
More intuitive explanation for the harmonic series’s sum by galen_colin
I just want to note that although the proof you provided is more intuitive, it is in fact a proof of a slightly different fact. That post proves that $$$H_n = \Theta(\log n)$$$, while the proof by integration implies that $$$H_n \sim \ln n$$$, providing the exact relation constant.
The codechef/galen explanation shows that the answer is between $$$log_2 n$$$ and $$$\frac{1}{2} \cdot log_2 n$$$, which is good enough.
(the second part comes from the fact that we at most doubled every number to get $$$log_2 n$$$)
Define 'good enough'. Not even for asymptotic complexity analysis in the general case: $$$\Theta(2^{\ln n})$$$ and $$$\Theta(2^{\log_2 n})$$$ are somehow rather different complexities.
Cool blog! Bonus problem: write a checker for the Parade task from the last example.
I'll also share a couple of tricks then.
How to precompute all factorials, inverse factorials and inverses up to $$$N$$$ modulo prime $$$p$$$
Option 0. Inverse each number in $$$O(\log{p})$$$. Compute factorials and inverse factorials trivially in one for-loop. Though it is usually not a bottleneck, you can still do this in $$$O(N)$$$ instead of $$$O(N\log{p})$$$.
Option 1. You can compute inverses one by one:
So in code:
After this it is trivial to compute factorials and inverse factorials.
Option 1.5. There probably were some fancy one-liners, I do not remember them. Feel free anyone to share.
Option 2 (no-thinker). If you do not want to memorize the equation above or even its right hand side, but you know how to compute inverse in $O(\log{p})$ (man, I hope this will render properly here in codeforces), you can do the following:
Kinda bitsets of variable length
Suppose you have the following problem:
Given $$$T$$$ test cases, in each of them given something of size $$$n$$$ which can be solved via bitsets in $$$O(n^2)$$$ or something. It is guaranteed that $$$\sum n^2 \leq \text{smth}$$$. For example, $$$\sum{n}\leq 10^6$$$ to read input fast, and $$$\sum n^2\leq 10^{10}$$$.
If you use a bitset of some fixed size $$$N$$$, it will be $$$O(N\sum{n})$$$ which may be too big: if you are given $$$T = 100$$$ and in each test $$$n = 10^4$$$ or $$$T = 1$$$ and $$$n = 10^5$$$, then you have to choose $$$N \geq 10^5$$$ to pass the single big test and $$$N\sum{n} \geq 10^{11}$$$ in the bunch of small ones. If you think it will pass, substitute some bigger numbers.
If you do not want to implement your custom bitset, you may do the following: introduce 20 bitsets of different power-of-two length and do something like:
You get the idea. Now you never use a bitset of length twice or more greater than you need. You can make your life easier by introducing some macros or metaprogramming instead of copy-pasting these ifs twenty times.
By the way, have anyone compared their bitset of variable length with the
std::bitset? Does anyone have some benchmarks like "yeah my custom is about the same speed as std one" or "no I tried really hard, but mine is still 2x slower"?Here's a cleaner implementation for your bitset idea.
How does this work? Shouldn't the value of
nbe known at compile time? This looks like magic to me.The template parameter
lenneeds to be known at compile time;nis just an ordinary function parameter that can be anything at runtime. And in the template-recursive call inside ofsolve, its template parameterstd::min(len*2, MAXLEN)can be calculated at compile time sincelenwas a template parameter (and hence is known to the compiler),MAXLENshould be a compile-time constant, andstd::minisconstexprsince C++14*. Of course, whether the template-recursive call will actually be executed does depend onn, but that's perfectly allowed!*You can use the ternary operator to work around this with older language standards. But bounding the template-recursion at some
MAXLENis important: The compiler can't generate infinitely many versions of a function, and also may not be happy when compile-time signed integer arithmetic overflows.Thanks for the reply!
This is what initially confuses me because the value of
nis not known and therefore we can't know if the recursion will actually stop. But after playing around with the code, I suppose the compiler more or less only cares about the number of possible calls, whether it is finite and within the allowed depth.So that is why it doesn't work on C++11 (the ternary operator method works well though).
Great blog. You should add numbering 1-10 to make it easier to refer to something.
The visual proof can be summarized as: every pair of nodes contributes +1 merging operation at their LCA.
Polish statement and OJ: https://szkopul.edu.pl/problemset/problem/85OxKFDUUUJKw1egESKVJovL/site/?key=statement
An English statement also exists because this problem was used in an Opencup.
Thanks for the nice blog!
The $$$3k$$$ trick was somewhat new for me, and I used to do it in $$$O(m \sqrt m \log n / W)$$$ before this blog, rather than in $$$O(m \sqrt m / W)$$$ (where $$$W$$$ is the word size).
To do that, it is sufficient to compute the frequency of each distinct weight (say $$$k_w$$$), and note that after updating the knapsack bitset (say $$$b$$$) $$$k_w$$$ times, it becomes $$$b | (b « w) | \dots | (b « (k_w w))$$$, which can be computed via binary exponentiation (and optionally noting idempotence of $$$|$$$) in $$$O(\log k_w)$$$ time.
Edit: as pointed out by errorgorn, this blog shows that we can in fact get rid of the log factor in the complexity analysis of this algorithm.
You can achieve the same worse complexity in a manner that may be more useful. If we have frequency pairs of the form $$$(w, f_w)$$$, where $$$f_w = 2^n + k$$$, we can create an equivalent set of $$$O(\log f_w)$$$ elements $$$2^0 \cdot w, 2^1 \cdot w, \cdots, 2^{n-1} \cdot w, (k+1)w$$$. If you do this for every frequency pair, you have a set of $$$O(\sqrt{m} \log n)$$$ elements that you can do a naive knapsack on. This is kinda more useful because it applies to any associative operation, not just addition. You can use it in a non-knapsack context to solve 922 E. The comments under the editorial calls it "method of nominals".
Thanks for the note. This was precisely what I meant by noting the idempotence of $$$|$$$.
(3) is contained in very old problem 95E - Lucky Country
Knapsack variant with many possible solutions, which may use (3), (4) and/or (5): sushi
Me reading trick 8: -is-this-fft-?
For reachable nodes in DAG, why can't you do:
Find strongly connected components, using tarjan or whatever algorithm you want. Then we can compress all nodes within the same strongly connected component to get a line graph (i.e. $$$a_1 \to a_2 \to a_3, \dots , \to a_n$$$.) Now, it is easy to query.
But this seems too simple.
Oops, I see my mistake, thanks :)
Compressing SCCs doesn't have to result in line graph. Consider a graph 1->2, 2->3 and 1->3 (there are no SCCs and graph isn't a line).
:facepalm:, thanks for the correction
This is wrong, but it can be used in specific examples (for graphs that are not necessarily DAGs), such as in the case when the underlying graph is a tournament graph.
ok thanks
The trick mentioned in Point 3 can be used to solve School Excursions on CSES.
Note that it is not necessary to apply the trick and using a bitset only will also work.
Can you please add these tricks in a spoiler? It would be easier to navigate
Can't we use inbuilt bitset in c++ directly for the first trick, I got accepted AGC 041 E code --> here.
It was quite easy to implement, instead of taking 64 bit int, please tell if I'm wrong in some case or this method is slow.
Btw thanks for the blog !!!
The issue is memory usage. To make $$$N$$$ bitsets of length $$$N$$$ you use $$$N^2$$$ bits of memory. If $$$N = 5 \cdot 10^4$$$, this is 298 MB, if $$$N = 10^5$$$, then this is 1192 MB. It is common to have memory limit 256 MB and very rare to have memory limit over 1024 MB. So, in most problems it won't work. Apparently the Atcoder problem has memory limit 1024 MB, I didn't notice that. But for example, in the problem shared by box earlier in this thread, the memory limit is only 256 MB, so it doesn't work.
Why it isn't 25⋅(10^8) bits which will be approx 3⋅(10^8) bytes ,which will be around 0.3 MB.
Ooo sorry It will be 0.3 GB , So 300 MB , Thanks for the explanation.
Can anyone explain how to solve section 2 with segment tree? Thanks!
Construct a persistent value-range segment tree, where $$$Tree_i(l, r)$$$ stores the number of value that has occurred between $$$[l, r]$$$ and index $$$\le i$$$. For each query $$$[l, r]$$$, do a binary search on both $$$Tree_{l-1}$$$ and $$$Tree_r$$$ simultaneously to get the mex. Time complexity $$$O(n \log n + q \log ^ 2 n)$$$ or $$$O((n + q) \log n)$$$ depending on how binary search is implemented.
Hope this helps.
Thank you. I have understood.
Doesn't this only work if the integers in the array are distinct?
Wooooooops I made a mistake. The segment tree should maintain a counter of occurrence of each value.
Apologies, I should've been more specific. As I understand it your algorithm constructs a range sum segment tree over values for each prefix, or in other words $$$Tree_i(l,r)$$$ stores the sum of occurrences of integers between $$$[l,r]$$$ with index $$$\leq i$$$. To find the mex you descend down the tree to find the smallest value range $$$[0,x]$$$ that contains exactly $$$x$$$ occurrences of integers. While descending down the tree, you go to the left subtree if the sum of occurrences of integers within its range is less than its size (Indicating that the mex exists within the range of the left subtree), and the right subtree otherwise and so on until you reach a leaf node.
But doesn't this break if an integer occurs multiple times in the given array? e.g; for the array A = [0,0,0,0,0,0] and query(1,6), how do you correctly decide whether to descend to the left/right subtree?
5. Removing elements from a knapsackA nice problem for the 5th trick --> I. Segment with the Required Subset
we can optimise the 2nd trick find minimum complexity to $$$ O( sqrt(n) / 64) $$$ which is nearly constant, by implementing our own bitset ,and maintaining pointers to next and prev sqrt block.
hectic implementation but more faster as we are dealing in bits.
10 seems to be related to the problem 1097E - Egor and an RPG game. Problem essentially asks you to split a permutation in a "small enough" number of subsequences such that each subsequence is either increasing or decreasing. Size of the answer for the problem is always $$$O(\sqrt n)$$$.
I believe a similar idea to #9 is used here
1000F - One Occurrence can be solved with second trick.
Here's another good example for #7:
https://open.kattis.com/problems/kthsubtree
Hey, I have been trying using knapsack like approach in this problem but getting TLE verdict. Can you elaborate the approach you used to optimize this. Here is the Code .
The code looks asymptotically correct, the main issue is probably recursion (it is very tight for a 1s limit and I am not surprised by TLE).
One other thing you could improve is when going through each child node and updating
dp[u][num], don't updatenumfor allchild[u], rather keep a running sum of the total size of subtrees you have processed so far and only updatenumwithin that bound. This should cut the constant factor by half (intuitively, this is because you will now operate on all ordered pairs instead of unordered pairs of nodes).In the 3k trick, what should we do if there're more than 3 rooks that have equal weights?
Replace $$$3$$$ of them by $$$a$$$ and $$$2a$$$. Repeat until there are no $$$3$$$ rocks with equal weights.