


Hello, Codeforces!
Actually, I didn't understand how, but I've prepated a round for the second division. I think it is subconscious wanted to soften the hard memories of the round of 276.
I hope that very much that the round will be held without any technical issues, as was the 277th.
I express my sincere gratitude to all involved in the preparation — Maxim Zlobober Akhmedov, Maria Delinur Belova, Polygon System, servers and James Gosling for Java. Also I am immensely grateful to the driver, who did not knock down me by car, although I, thinking about the problems, was crossing road on red.
It will be rated round, 6 problems and non-typical progressive scores: min(500 + i*500, 2500).
Wish you to see many Accepteds.
UPD. The Round moved 5 minutes forward. I want very much so that no one be late! Sorry.
UPD 2. Rating has been updated. But if we will find any cheaters, they will be punished and we will recalculate ratings. Thank you for participation!







6 Problems means that we will enjoy more :) . This announcement made my day :D
Thank You sir :D may Allah keep you in the best of health & happiness always :)
So the scores distribution will be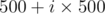 with
with 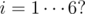
We are programmers. Everything is zero-indexed.
ghar!?!
except segment trees and fenwick trees
Umm, what about
2*i + 1and2*i + 2?Not fenwick mate! Can't zero index a fenwick tree!
Oh rly? http://e-maxx.ru/algo/fenwick_tree
My bad!
For me (and for many people also, as I think) it's more comfortable to use 1-indexed segment tree :)
I use 0-indexed segment tree, can you tell me what does it make more confortable to you use 1-indexed ones ??
i<<1 and (i<<1)|1 (in 1-indexed) is faster than (i<<1)|1 and (i<<1)+2 (in 0-indexed)
didn't know it, but I guess is not TOO FASTER... or is it ??
Maybe he wants to save 1 milliseconds just like uc-nuts wants to save 4 bytes here
I always use it and save 1 extra memory B|
And if it's not zero-indexed (with a few exceptions!), you really shouldn't call yourself a programmer :)
It's maybe me but I'm confused why for people ask for clarification got downvotes... pretty weird you know.
Because in 99,9% cases it may be 0-based indexation, or 1-based indexation (it's well-known fact for most of us). The space of possible solutions is 2, so this question should be considered stupid.
I see. Though I almost believe the 1-based indexation. Unusual round's name and unusual scoring, both sounds interesting. Still, it only makes sense for 0-based indexation.
Another sleepless night!
6 problems, more chance to enjoy!!!
start more and more contests if you can...we need them
I believe that codeforces will become more and more perfect. Great thanks to MikeMirzayanov for creating a fine platform,We appreciate everything you do.
i think next contests will be 277.75 ... :D
i think next contests will be 277.6 ... too!!:D
277.5--277.6--277.7--277.8--277.9--277.95-- .... :D
We can use binary search...277.5 277.75 277.875 277.9375.... 278-pow(2,-i)
:D
This time, no thanks to Mike?
Unable to parse markup [type=CF_TEX]
I thought Mike involved in the preparation, no?
Do you even sarcasm, bro?
Mr. MikeMirzayanov I like the way you have made people's handles as their middle names :) that would be quite a nice way to introduce some people in real life :)
Or did you mean Mr. Mike MikeMirzayanov Mirzayanov
Mike Mirzayanov needs no introduction.
darn this is infinitely recursive
totally agree with you...... meanwhile my friends made a cake having the text "Happy Birthday RED_BACK" in my last birthday..... :P
Mike as the problem setter? I want to take this round now.
It 's very interesting !
I was laughing something about 10 minutes to this :
"Also I am immensely grateful to the driver, who did not knock down me by car" :D
6 problems, wow!!!!!!!!!!
That also mean we have more chance to choose.
MikeMirzayanov facts:
277.5) Once upon a time MikeMirzayanov fell asleep on the keyboard and accidentally prepared Div2 contest
xdd, the same as "tourist wiped the dust from keyboard and got Accepted on A,B,C div 1"
Can't see the register option for this contest. somebody please help fast :(
are you sure that registration is open ?
The comment is hidden because of too negative feedback, click here to view it
Vote -1 to make this comment more interesting)
Your idea is too old :P See here
wow...+185
It was red commentator, feel the difference
:|
no, it was first time :)
6 Problems are welcome :D but will it last for 2 hours or more ??
Meanwhile in Russia
Cold frost and sunshine: day of wonder!
But I'm on CF. My choice is done)
It's wery good that he added the contest, I cant understand why are you joking about this? Everythiing is done for us
updated scores will be min(500 + i*500, 2500).
I need help for this problem. Please. Link is given below.
(https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=1719)
hope for some good dp!!!
Hoping for a +ve color change.. :) good luck everyone
thanks MikeMirzayanov
Unsuccessful hacking attempt always killing me! :/
It was best contest in my life...i saw paging errors just one time...
tnks a lot from all of friends who took this contestHow was problem F supposed to be solved?
I solved using a dp.
The states where dp[amount of columns that needs 2 '1'][amount of columns that need 1 '1'].
The transitions would be picking 2 of these columns (out of all the possible ones) for each row.
I hope it gets accepted.
very nice problem in your contest. thanks MikeMirzayanov
strong pretest 0.0
Can anyone give me a hint for F ?
I did it in O(N^3) with DP[row][col1][col2], where col1 and col2 is number of columns with 1/2 remaining cells to choose. When you are adding new row, you may either choose 2 columns with 1 cell left and move to DP[row+1][col1-2][col2], choose 2 columns with 2 cells left and move to DP[row+1][col1+2][col2-2], or choose 1 column with 1 and 1 with 2, moving to DP[row+1][col1][col2-1].
My first implementation was a bit messy and it was challenged, but after adding some prunings it looks fast enough.
Wow !!! Thanks, hope you will get it Accepted. It seems not so hard. In the contest I think about DP[row1][row2][col1][col2], it works fast with std::map but I could not find the correct formula.
You can extract the 3rd parameter from the first two to get O(N ^ 2) solution.
formula: col2 = ((remainingRows * 2) — col1) / 2;
Unfortunately, the website went down in the last 10 minutes of the contest which is the most crucial time! :(
How I can solve problem D?
Also wondering
I tried to enumerate every pair of vertices (B, D) and calculate the number of diamonds (assuming these two are the middle vertices of a diamond). Intersecting their parents and their children, I obtained the number of possible vertices (A, C) that could form a diamond. Also intersecting these two sets, I obtained the number of "repeated" vertices that are both parents and children of A and B, and thus can't form a diamond with itself. And add to the answer the value (parents * children — their intersection).
But this approach gave TLE
For each possible (end of diamond v; source of diamond u) we can count the number of paths of length 2 from u to v.
Let us define cnt[v][u] as the number of different paths of length 2 from u to v. We run the following loop:
Now we can easily obtain the answer:
Actually now I am not sure why does this solution pass in time.
Won't this work in O(m) ? Provided you store the parents and children of every node before counting. Not sure about this though.
I'm thinking about the test case where we have m / 2 edges incoming to some x and m / 2 edges outgoing from x. Then lines 2-3 are m2, like gen wrote below.
It's O(n·m) because degv < n
I think that in worst case it will be (m / 2)2, which is fine, 225M.
There's a simple O(N^2) solution (N^2 is an upper bound, actually it is faster I think):
For every node i, do a dfs (max depth 2) using i as root
During dfs, for every node j that you reach using 2 edges, update cnt[j] (where cnt[j] is the number of ways to reach j using 2 edges) PS: clearly you stop dfs when you use 2 edges
At the end of the dfs, iterate from node 1 to N and for every node j update result in this way:
At the end of the whole process you'll obtain the answer :)
How to solve D ? And what is hacking testcase of B ?
I solved D using pascal triangle and a dfs of depth 2 for each node.
The hacking case on B for me was: 2 2 3 2 2 1
Some people did not sort the arrays, and the solution like this was enough to pass the pretests.
About D,you can try to use Brute Force. :)
Did anyone else experience heavy lag during the contest ?
no...it was so good for me
I had some problems at the end of the contest, but other than that it went smoothly.
yep. My hack, which I did about 1 min before the end, wasn't sent to server =((((
How to solve E?
Let's use binary search to find best possible ratio. When you fixed ratio R, then you know that for total picturesqueness of X you can take no more than R*X total frustration. So for every point you can calculate dist[i] which is equal to best possible difference between F(frustration that you have taken) and R*X. If dist[n] is not positive — it means that you can make ratio no more than R, because you found path with F<=R*X. Otherwise smallest possible ratio is larger than R.
But how to deal with a lot of different picturesquenesses?
When you stay at point X and have dist[X]=D, then you actually don't care about real values of picturesqueness and frustration. Only dist[X] matters — your "frustration reserve". When you move from X to Y — total frustration increases by some value F (cost of this move), and total picturesqueness increases by b[Y], which increases your "frustration limit" by b[Y]*R — it is the same as decrease frustration by b[Y]*R while not changing picturesqueness.
Part of solution which explains this idea:
Wonderful, thank you!
I liked F , but I think my solution won't pass. Also very nice E , I don't know how to solve it yet. Congrats Mike for the round !
6 unsuccessful submissions to C because I printed "0" instead of "0 0"
Epic Fail(((
I probably never going to become candidate master((
I thought same 2 years ago about myself :D
How did you overcome it?
Problem D reminded me of this Google Code Jam problem !
Thanks for the nice problemset! Unfortunately I got overslept for the entire contest. When I woke up, the contest has ended.
Could anyone explain me why this algorithm got me WA in pretest 5 (problem D)?
Thanks ♥
If you have four numbers 2 in the list, it means there are 4 ways to get to vertex 2 right?
If that is so, you should pair only these ways (every pair of ways to a vertex will generate a diamond). So you should count how many times each number repeats and calculate the how many pairs you can form with 'count' elements (c*(c-1)/2).
Ups.. I think I misunderstood the problem >__< Ty for the reply! :)
I totally overkilled B by using flow =p
OMG!! I was kinda lazy to solve it but I never imagined there will be someone who would do THIS!! XD
Solved C using regex'es (8726629).
can anyone explain me why code:
in my compiler makes error "Segmentation fault". (ubuntu x64), but in test system there is no error;
You shouldn't allocate such large arrays on stack. Place it outside the function to make it statically allocated.
thanks for answer, array was in function main, is it true for main()?
Even if it is called
main(), it is still a function like any other.no, it's true for any array you are allocating on stack. see this: Memory: Stack vs. Healp
In Ubuntu x64 the typical stack limit is 8192KB. You can query and modify it with
ulimit -s. However, in Codeforces, stack limit is even larger than memory limit of most problems so stack overflow can't happen at all.In problem E, we have to work with non-integer numbers, so I think we should consider output to be correct if the difference between output and answer is small enough (E.g, lower than 10 - 6)
very nice problem in this round,very thanks MikeMirzayanov :)
what a shame that you accepted B and C but your code was wrong for A... :(
Problem A:
define INF 1000000000 — WA 21
define INF 1000000001 — AC
It's about me. But it was very interesting contest for me.
I know that you feel...
))
What a pity! :(
tnx mike it's good conteset but PLZ unlike me :) plz
Thanks to the ISP , we were cut off the internet country wide for over 9 hours and I missed the contest........in addition, living without internet connection was a wild experience.
How to solve D if for the same problem, we modify the constraints as follows:
1<=N<=2000 (Number of intersections)
1<=M<=(N*(N-1))/2 (Number of edges).
You may try N^3/32 solution. Generate bitsets of ingoing and outgoing edges for every vertex. Fix 2 vertices B and D (this gives us N^2), and count number of rhombi for this pair. To count this number, you should count number of valid A's for it (using bitsets of ingoing edges for B and D, you can make it in N/32 by taking blocks of 32 vertices from both bitsets and counting 1's in bitwise AND of these blocks) and number of valid C's for it (same idea, but with outgoing edges). Add the product of received results to the answer, and don't forget to substract invalid rhombi with A==C (to count them you should make same AND trick with all 4 bitsets at the same time).
http://codeforces.com/contest/489/submission/8723815
2000 0takes 3.76 seconds (ideone.com).Of course, when i said "bitsets" — it was not literally about C++ "bitsets":) You implemented solution from editorial, which is even better than my previous idea (it does 4*10^6 bitset intersectings instead of 6*10^6 in my first solution). But it is slow because of bitsets.
First of all, try your solution in custom invocation here at CF instead of ideone. It shows ~1.2 seconds. That already sounds much better for me:) Implemented a bit more carefully, it works ~0.4 seconds (source code), therefore you should have no problems with using it to solve such problem at CF.
Yes, I've just tried it in custom invocation and I think it would get AC even with C++ bitsets if n<=2000 (MS C++ runtime: 561 ms).
This was my first solution during the contest, but for n = 3000 it takes 1622 ms :/
Thanks
for problem A why o(n^2) did not give me TLE 8739673 ?
Why do you think it would TLE? n is small (<= 3000), so n^2 is good enough.
i thought n^2 = 3000^2 = 9*10^6 so it require more than one second i think my approach is wrong , so could u simplify it , please ?
9*10^6 operations doesn't take that much time actually, recent processors do around 10^8 in a second, or even more..
thank you very much :)
You can solve it faster with some data structures (obvious solution with segment tree gives N*logN), but it is an overkill for div2 A.
Nowadays computers are fast enough to use N^2 for 10000:) And in your solution all operations are very simple, so it will work well even for larger constants.
Also you can always check speed of your solution in CUSTOM INVOCATION, if you are not sure.
i got got TLE, for i forgot to break in the second loop.. 8727730 But i think in most cases, 3000^2 won`t cause TLE.
I think the complexity of your program is O(n*n*log(n)).
Actually I believe you got TLE because you're printing a lot of data, not because of the time complexity of your algorithm, look at the test case where you get TLE:
the number of answers you're going to print is "1121253" which is pretty much a lot of data to be printed!
If you print a very large amount of data, then you will get output limit exceeded (OLE) error instead of getting TLE in most of the cases.
I don't know if there is(OLE) here in codeforces, but I tried to submit a code where I just print 1121253 * 2 values, and I still get TLE.
The Code
Can Codeforces start the round at 7.00 pm (UTC+4) ? It's too late for me :v
Country Wise Rankings have been updated.