


I wrote problem 603E - Pastoral Oddities for the recent Codeforces round and was pleasantly surprised to see so many different solutions submitted in addition to my own (14611571). Even though I proposed the problem, I learned a lot by reading the submissions after the contest! Since I think these other approaches illustrate some beautiful techniques, I would like to share them with you guys. Below, I describe three different solution ideas by jqdai0815, winger, and malcolm, respectively. (If you haven't read the editorial yet, I suggest that you do so before continuing, since some of the observations and definitions carry over.)
Solution 1: jqdai0815
Like my original solution, this approach uses a link-cut tree to maintain an online MST. The main idea is the following observation: In a tree with an even number of vertices, an edge can be removed if and only if it separates the graph into two even-sized components. Thus we assign each edge a parity—even if removing it creates two even-sized components and odd if removing it creates two odd-sized components. Note that our answer is the maximum-weight odd edge in the minimum spanning tree. To apply this observation to our original problem, we can initialize our tree by linking all of its vertices together with infinite weight edges.
Now consider the operation of adding an edge connecting u and v to this minimum spanning tree. This consists of finding the maximum-weight edge on the path between u and v, and replacing it with our new edge if the new edge has a smaller weight. If we replace the edge, we have to update the parities of the edges in the new tree. Note that our new edge has the same parity as the old edge. In addition, all the edges not on path u-v in the old tree keep their parity. Now, consider the edges on path u-v. If we removed an even edge, then their parities also stay the same. Otherwise, the parities of all edges on this path get flipped. Thus we can store edges as vertices on the link-cut tree and support path updates with lazy propagation to maintain the parity of each edge.
To find the answer after adding each edge, observe that our answer never increases when we add a new edge. Thus we can use an STL set to store the current set of edges, and iterate down from our previous answer until we find an odd edge. Due to this step and the link-cut tree, this algorithm runs online in amortized 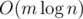 . jqdai0815 wrote a succinct implementation here: 14604705.
. jqdai0815 wrote a succinct implementation here: 14604705.
Solution 2: winger
During testing, winger found this solution which uses divide-and-conquer to solve the problem offline in 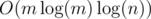 . We divide-and-conquer with respect to time by recursively solving subproblems of the form "Find all answers from time l to time r, given that these answers lie in the interval [lo, hi]." To do this, we first find the answer for m = (l + r) / 2, adding edges and maintaining connected components a la Kruskal's until there are no more odd-sized components. Once we have the answer ansm for m, we can call the same function to solve the problem in [l, m - 1], given that the answers lie in [ansm, hi], and the problem in [m + 1, r], given that the answers lie in [lo, ansm].
. We divide-and-conquer with respect to time by recursively solving subproblems of the form "Find all answers from time l to time r, given that these answers lie in the interval [lo, hi]." To do this, we first find the answer for m = (l + r) / 2, adding edges and maintaining connected components a la Kruskal's until there are no more odd-sized components. Once we have the answer ansm for m, we can call the same function to solve the problem in [l, m - 1], given that the answers lie in [ansm, hi], and the problem in [m + 1, r], given that the answers lie in [lo, ansm].
In order to make the complexity work out, we have to keep the edges that we added earlier between levels of recursion—that is, we enter the problem with our union-find data structure already containing the edges with time less than l and weight less than lo. Before calling the next levels of recursion, we insert edges into the union-find data structure to make this condition hold. To make returning to a previous state of the union-find possible, we keep track of all the changes that we make. Thus in a single level of recursion, we do one set of modifications on the union-find to compute ansm, then rollback, one set of modifications to satisfy the precondition for the interval [l, m - 1] × [ansm, hi], then rollback, and finally one set of modifications to satisfy the precondition for the interval [m + 1, r] × [lo, ansm].
The edges we use when computing our answer for m and for deeper levels of the recursion either have time in [l, r] or weight in [lo, hi], hence each edge appears in at most two separate instances of the recursion at each level. Since there are 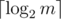 levels, edges appear a total of
levels, edges appear a total of 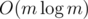 times. We process them in
times. We process them in  per edge, thus we have the desired complexity of . Below is a diagram illustrating this idea with edges represented as points (time, weight). (The big box represents the current level of recursion, while the red/blue highlights represent the next level.)
per edge, thus we have the desired complexity of . Below is a diagram illustrating this idea with edges represented as points (time, weight). (The big box represents the current level of recursion, while the red/blue highlights represent the next level.)
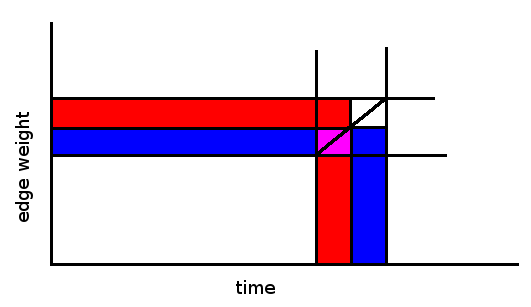
subscriber implemented the same idea here: 14601511.
Solution 3: malcolm
Finally, malcolm had another offline divide-and-conquer solution that ran in using a segment tree. In this solution, we first sort the edges by weight and then find the answers for the queries from last to first. We build a segment tree over all of the queries and do a DFS on it, visiting the right child before visiting the left. Simultaneously, we maintain a union-find data structure that supports rollback. Before we look at the details of this algorithm, we make the observation that if an edge i is used in the optimal solution at time j, then edge i should be present in the union-find in the time interval [i, j].
The DFS works as follows: At each internal node of the segment tree, we add all edges assigned to that node to the union-find before visiting its children. When we leave that node, we rollback the union-find to its initial state. At each leaf, we find the answer for the time value represented by the leaf. We process edges in order of increasing weight, starting from where we left off in the previous leaf. Suppose we are at the leaf representing time j. We compute the answer for j by adding edges as we do in Kruskal's algorithm until we have no more odd-sized components, making sure to only add the ones that appear before time j. When we add edge i to the union-find, we also update the segment tree over the interval [i, j - 1], adding edge i to the set of  nodes covering this range. Thus we know when to add edge i to the union-find later in our DFS. Again, before leaving this leaf, we rollback our union-find to its initial state.
nodes covering this range. Thus we know when to add edge i to the union-find later in our DFS. Again, before leaving this leaf, we rollback our union-find to its initial state.
Each edge appears in the segtree times, so the overall complexity of this algorithm is . You can look at malcolm's code here: 14600443.
EDIT: Thanks to mmaxio for pointing out that due to rollbacks, we can only have instead of amortized O(α(n)) as the time complexity for our union-find operations. To get , we can use union by size (merging smaller into larger) or by rank (merging shorter into taller) to achieve a non-amortized bound on the maximum height of the tree.
By the way, if anyone has questions about these solutions, feel free to ask!






How do you achieve O(α(n)) per modification in union-find with rollbacks?
If I understand correctly, we can simply store modifications (whose parent was changed and what it was changed from), and revert as many as we need. Complexity amortizes out. (We can't revert more changes than there have been). For example, a snippet from malcolm's code:
Well, if we add rollbacks, complexity shouldn't be amortized anymore. In this case we should use Union-find with ranks and achieve guaranteed O(logn) per join/unjoin/find, no?
mmaxio, you're right. Rollbacks do break amortized complexity. We can, however, still achieve per operation by writing union with rank or size heuristics, since these guarantee the height of each tree to be
per operation by writing union with rank or size heuristics, since these guarantee the height of each tree to be  . I'll go update my post—thanks for pointing this out!
. I'll go update my post—thanks for pointing this out!
rnsiehemt, consider a costly operation (i.e. path compressing a long chain) that takes k changes. If we repeatedly undo/redo this operation, we have to make k changes each time, which breaks the bound. Amortization only says that the sum of the costs of the first m operations is bounded.
EDIT: ikatanic, looks like I agree with everything you wrote. :)
I just thought there might be some cool idea which I'm not aware of.
Oops, you're right of course. I saw that the implementation had the same complexity without rollbacks, and since I always ignore the difference between O(a(n)) and O(logn) union-find in practice I carelessly assumed that it achieved the desired complexity.
Is there any 2D dp solution(using 2 states) for Problem 1 (Alternative Thinking)?
thanks for solution 2 very much