



There has been talk about this already, but in case anyone missed it:
The 2016 edition of Internet Problem Solving Contest is going to take place today (starting time).
It's a 5-hour contest for teams of up to 3 people, but there's also an individual division, so feel free to participate even if you can't find yourself a team at this point.
There's going to be an ACM-like number of problems (12+), ranging from classic algorithmic problems to quite unusual ones. Most problems have an easy subproblem worth 1 point and a hard one worth 2 points (think CodeJam); ties are broken using ACM rules (sum of times).
The practice session is over. The contest is over!
Read the rules or my previous blogposts about this for more info.
Belated, yet necessary warning!
Since this is a 5-hour contest where you can execute codes locally, some inputs will be YUGE (gigabytes). Accordingly, they will have fairly high system requirements. Get a good computer. While the official solutions quite comfortably run on my mediocre laptop, if you write something too inefficient, you can encounter a nasty surprise, e.g. frozen system. It happened to me last year.
If an input is big, you won't have to download it; instead, there will be a generator (typically a Python script, meaning they aren't very fast). It's usually a good idea to run all generators as early as possible — as long as it doesn't slow down your computer too much, you can avoid a situation where you can't submit a problem because the contest ended before your generator.
Actually, you should just try to read as many problems as possible and determine your strategy after you can guess your chances well enough.
Some quick stats
11145 submissions
5370 successful submissions (48% success rate)
797 active teams out of 1376 (58% did not give up before even trying)
773 teams with positive score (97% of active teams)
12/13 problems solved by someone
maximum number of fully solved problems: 10/13
lowest non-zero success rate: D (D2: 20%)
highest success rate: C,F (C2,F2: 85%)
highest success rate (easy subproblems): G1 (85%)
lowest success rate (easy subproblems): J1,M1 (25%)
hard problems (<50 teams solved) sorted by difficulty:
E: 0/13
M: 2/10
J: 4/17
H: 11/17
B: 11/18
L: 16/46
K: 40/107







Put on your headphone with high volume, go to https://ipsc.ksp.sk/2016/announcements, press " Show test notification" :D.
I am feeling a bit dizzy now!
Why couldn't you distribute password-protected archives via cloud drive services?
Excercise: try to list reasons pro and against.
Pros: noone depends on uniba.sk server.
Cons: Exception in thread "main" java.lang.NullPointerException ...
Exercise: try to answer exactly the question you are asked.
No. What will you do now?
Discuss it with ur mom next time I see her, son
Uh... what?
All i believe is you gotta have an iphone 6s
On problem D, I think there's log format mismatch (log created from javascript, and log received from checker/judge). Just remove second last line before "done" and finally OK verdict. The same thing happen on D2.
Look how many average attempt until accepted on problem D. Could the organizer fix it? many get junk penalties because of this (including me).
Based on Javascript code, you can see that it does not print the last "next", and only print "done" instead..
Uh sorry, that's clearly my mistake. After looking on scoreboard with many unsuccessful attempt make me think that it's not only me having the same problem/mistake. Still curious why problem D has high unsuccessful attempt rate (compared to other problem)?
What is wrong with my following solution for I1?
I ignored the "not-password-x" files and just printed the passwords and got I1.
could you explain a bit more?
From the beginning: I solved this problem on a Linux machine, not sure how to do it on Windows. If you try identifying the filetype of the input file using the
filecommand in bash, you will find that the input file is a filesystem. Mount it and you can access the folders. There are tons of nested folders in there. Ctrl:F reveals text files titled "password-x" and "not-password-x", with x ranging from 0 to I think about 12? Basically I ignored the not-password files, and copied the passwords from password-0 to password-9."BURN AFTER READING" was a big hint :D.
Any idea how to solve I2? After mounting, it contains a 0-byte file and an empty(?) hidden folder, where did they hide the password?
I'd say "lost+found" was a big hint :D
See Chortos-2's comment below. I figured the file was corrupted after I saw the lost+found folder, but I didn't know how to recover it.
what you needed to do is:
Find 10 files with names "password-x" where 0<=x<=9 , and output the 10 32-char passwords in separate lines in i1.out
The file is the image of an ext2 file system (as
file i1.inwill be glad to tell you), which you can mount on Linux (if you have root access) using a loopback interface (losetup /dev/loop0 i1.in && mount /dev/loop0 /mnt). This file system contains files named password-x, and their contents are the corresponding passwords. That’s it.In I2, the file system is damaged (but marked clean), so you have to force a check using
e2fsck -f. Then a file appears that contains the password split into lines of length 3. Join the lines, and you’re done.I guess I solved I2 in a non-intended way.
I saw "must go deeper" after mounting, but then I just look at the i2.in as a text file. There were bunch of 38-chars (split by 3 chars) texts, I just took the latest one (because of "go deeper") — success from the first attempt, no fsck involved.
Is it possible to upsolve problems?
If it isn't yet, it will be soon.
Update: Tomi seems to have fallen asleep. Training area update is postponed until he wakes up. Tomorrow, probably :)
Upsolving is now available, the contest has been added to the training area.
Test data and sample solutions are coming soon, they will be available in the archive.
Can anyone share method they used to solve c.
I was calculating number of ways in which each permutation cycle can be broken into smaller cycles but got WA.
In C , I decomposed the array into cycles and then calculated independently for each cycle. The number of ways to sort a single cycle of length n in minimum number of swaps came out to be n^(n-2).How do we prove that it is n^(n-2)?[I wrote a brute force and then figured out the sequence.]
bruteforce, search oeis --> http://oeis.org/A000272 Easy win ;)
First you have to proof that this problem (#of optimal ways to sort a cycle length n with swap) can be reduced to number of rooted labelled tree size n.
After that, This document do the rest of the proof.
But I still have doubt about how to proof that this problem (#of optimal ways to sort a cycle length n with swap) can be reduced to number of rooted labelled tree size n.Can you explain it more specific?
Why does sorting each cycle independently optimally produces optimal minimum swaps overall? I am getting strong intuition that it should be so but not quite able to prove it
By swapping two numbers in the same cycle, number of cycles in permutation increases by one, and swapping numbers from different cycles decreases number of cycles by one.
You want to make n cycles (sorted permutation is the only one with n cycles), so the optimal thing to do is to always swap inside the same cycle.
Is it possible to solve H in something less than O(log2N) per query? I wrote O(logN) per query for H1 but it took 6 minutes to run so HLD would probably take O(6logN) minutes to run which is too slow.
We had a neural network for L, achieving 85.9% accuracy on L2. Knowing IPSC, I fully expect that this was an overkill and I'm just waiting for the booklet to laugh at the simplicity of the solution.
Thanks for yet another amazing contest!
Neural net is not an overkill, but you need a better neural net (e.g. convnet from here http://keras.io/getting-started/sequential-model-guide/)
Sample MNIST convolutional network with AdaGrad was getting to 99.7 after just five epochs.
For me L1 was way harder than L2 because you actually need to do something reasonable there. I decided to just run naive brute force on ec2 for 50 minutes.
Yeah, the neural network turned out to be an expected solution, but we missed "The golden middle way", which is a sort of a nice trick I expected from IPSC.
For example, linear SVM on raw image data after applying pca easily passed in L2.
Our issue ended up being network size — doubled the amount of convolutional kernels and it magically worked.
For the record, the architecture used was:
Conv -> ReLU -> Conv -> ReLU -> MaxPool -> FC (+ dropout) -> ReLU -> FC -> Softmax
Of course, the "golden middle way" would've been the way to go, had we taken up this problem earlier on during the contest.
The first draft of this year's solutions booklet is now available: click here
I did the following kind of ML in L.
First, for L1 I removed noise from images. This is done by removing all pixels that have less than two neighbors, repeating twice. After that only a few pixels of noise remain on each image.
Than I generated a vector of features: compute the number of ones in each row, sort these values, do the same for columns (170 features in total). After that a simple 1-NN gives perfect result immediately.
To check the classifier I made 26 folders and put each classified image into respective folder. Afterwards I had just to check if all images in each folder are the same.
I tried to use the same approach for L2, but the quality was dissatisfying. I added several more features, such as sizes of black and white connected components, but it still couldn't distinguish between several types. Finally, I made it to the golden middle and finished the work by hand. Sadly, it took more than an hour.
We also had a really simple solution to K2. I hadn't even open the code (well, I did, but scared by the number 512 closed it immediately). The simple bash script which generated several random sequences of each length have made the thing in a few minutes (however, after two unsuccessful tries with N=52 and N=51).
Surprised so few people solved J -- it's just convex hull trick, and it's quite a popular topic recently (I know at least 3 problems in recent div 2 rounds that used it).
I is a very nice problem, but it seems a bit inconsistent -- you have a download archive for people with slow internet connections and a note explaining that we'll need to download Python 2, and then there is a problem recommending we download and install a whole Linux distribution during the contest?
There are really small Linux LiveCDs. Like 50 MB distributions or less.
Which is still more than the archive for slower download speeds (34 MB) they made available, and a download of about half an hour at something like 35 KB/s.
This is only the download of the Live CD itself, because you'll also need to get it to run somehow, which will need extra installation steps and hardware or more software downloads / installs.
I'm not saying it made the problem bad, but it's a hassle that could have been avoided.
Why not just install Linux when told to get Python? :D
As I had tested my code on J extensively during the last couple of nights, I found out what the most serious problem could be for anyone who wrote it in-contest: precision errors which lead your code to discard the wrong function — or keep a function which should be discarded. I needed approx.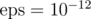 in the end.
in the end.
Besides, it's not so obvious if you're not given lines, but an equation with strange 'd's and when it's not about lines, but some uglier functions (even though they're sqrt(lines)).
Because Python is already the first thing I install on any of my computers anyway, I just ignored the message :D
Good point about precision on J -- I just copy-pasted some code that uses eps = 0 and it worked, so I assumed it wouldn't be an issue.
When I got WA on this problem I really thought that there is some precision problems or I have bug in convex hull trick. So I tried to change eps a few times, and even rewrote all code to BigRationals. It took half an hour, but I just got a few more "Wrong answer"s.
Eventually it turned out I just forgot to set sum to 0 after each 5000 queries :( Fortunately I need only 20 more minutes to get hard version accepted (it was 3 minutes before the end of contest).
You could've written a bruteforce and compared the outputs on a random case.
Actually I copied my solution, removed all convex-hull part, and tried all functions each time. But it had the same bug (with not cleaning sum), so I got same results for first small testcases.
So after that I still thought that there is a precision problems on big testcases...
We spent our time trying to solve I1 without linux lol Choosing the right problem to solve is not easy :P
I wonder where people learn skills of solving such problems as I. More than 100 teams solved it, but for me it is ridiculously hard and reading each line from solution just makes me think this is even more ridculously hard than I thought before reading that line ._. I am not able to imagine myself solving this problem in finite time even given the solution from booklet xd
I didn't know about "file" command, but just from looking through file in binary I noticed "/mnt" string. And for me this was a clue that it might be a mountable thing, maybe some file system. So I tried mounting and it worked.
P.S. And this is exactly the way ISO images are mounted here in Linux :)
I tried it in-contest and while I thought it'd be extremely hard, it surprisingly wasn't. My current brand of Linux (Kali) was quite helpful there, since
can be omitted there (it seems to create a loop device automatically...). For the easy part, it's just
file,mntandlsin the mounted filesystem. In the hard one, googling what lost+found is for quickly pointed me to a recovery command, I ran it and voila.As is often true with Linux autismo, the ability to search the Internet for tips, try many commands and hope one of them works (and none crash your system) is more important than knowing what you're doing :D
Congrats, you don't have autism
The booklet described solution in more complex way than necessary. Here is how it went for me with (almost) no command line required:
Guess that file might be an archive. I tried chaning the file extension to some common archive names -> no luck. Maybe it is a disk image, added .iso extension. After that file browser suggested to open it with disk image writer. I don't want write it, right click open with, disk image mounter sounds good. After mounting it I opened the first folder, it contained password-1 in correct format, ok lets' search for password-* and copy the content to text editor.
Let's try the same on i2.in. Observe YOU_NEED_TO_LOOK_DEEPER and lost+found, maybe the file system is damaged or files were erased. Google "linux file recovery". First result — SystemRescueCD, why would I need a rescure image I am already on Linux. Second result ddrescue, looks complicated. Third result Testdisk, lets try that.
testdisk --help->testdisk file.dd|device->testdisk i2.in. It has curses based interface, great I don't need to read the manual. enter ->enter ->analyze ->quick search->list files. PW sounds interesting, copy file, open it in text editor, remove newline, submit.Btw, I guess that problem H can be classified as "Big Data" :P. Processing tens of millions queries of complexity O(log2n) is not something very fast ._. Moreover building needed structures for trees on 10^7 vertices took 4GB of memory on my computer which along with usual memory usage of system fit within my RAM by a really small margin ._. (yeah, my HLD implementation is pretty memory-reckless, never meant it to be working well on 10^7 vertices :P).
Distributed CodeJam... on one node.
I did mention here to get a good computer. And I did expect RAM troubles (as I wrote, I memnuked my computer last year with a memory-expensive bug).
It's really necessary to do this. Consider the following solution:
split the queries into blocks of K, process each block together
there are at most 2K interesting vertices, the rest of the tree can be compressed into weighted paths
semi-bruteforce each query, only remembering for each road the last time it was cleared + direction and how much snow it had initially
go back to the original tree, recalculate the new amount of snow on each road
It's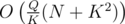 , so
, so 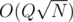 . Without any optimisation, it solves reasonable inputs for a CF round in... tens of seconds, I think. When the vertices are first renumbered in preorder, the compression/regeneration gets a lot faster. I got it to finish within ~6 hours on the official input — while testing J with its own huge inputs.
. Without any optimisation, it solves reasonable inputs for a CF round in... tens of seconds, I think. When the vertices are first renumbered in preorder, the compression/regeneration gets a lot faster. I got it to finish within ~6 hours on the official input — while testing J with its own huge inputs.
OK, your reply generally makes sense, but I just wanted to point that "I did mention here to get a good computer." sounds really funny to me :P.
As do most of my posts. See yummy's comment below for a textbook example of not heeding a warning.
Alternate solution to M: mincost flow (cost = life loss). The details should be fairly easy to work out, and we can solve the problem with only one network instead of brute forcing combinations of shocklands to fetch.
It turns out I didn't implement this properly during the contest for 2 reasons:
I forgot that shocklands in play are untapped and you don't need to pay 2 life (haven't played MTG for so long). I also didn't realize there were 3 different samples, since I just hit pagedown to the bottom of the page when testing on samples >_>
I accidentally replaced Frontier Bivouac with Crumbling Necropolis... so now both of them failed to work. In hindsight I probably should've just parsed the input file instead of hardcoding all 70 lands.
Problem H: Heavy Snowfall can also be solved with a link-cut tree in O(log n) time per query. You can see my code here. (I'm not sure why heavy-light solutions are so popular; link-cut trees have always felt much cleaner and easier to code.)
My solution also comes with a sad story: After finishing debugging with 15 minutes left, I realized that I had forgotten to generate the test data for the hard batch (which was the one that required the link-cut tree in the first place). So I could only watch sadly as my solution ran only on the small batch, 1.5 hours of debugging and three processor cores gone to waste.
But there is a silver lining--my 4:58 submission on H1 was enough to snag us first place in the secondary school division (with teammates FatalEagle and ksun48). :)
And thank you misof, Xellos, and all the other organizers for writing another amazing IPSC! This is solidly the contest I look forward to most each year.
A new, updated version of the solutions booklet: https://ipsc.ksp.sk/2016/real/solutions/booklet.pdf
Additionally, all problems now have outputs and solutions in the archive: https://ipsc.ksp.sk/archive
Sorry I didn’t have the chance to comment sooner, but the solution to T (Turning Gears) sounds overcomplicated. The final paragraph describes the whole solution, whereas the paragraphs preceding it just add more and more distraction. I understand everything written there, but it wasn’t an easy read—and the many various observations weren’t used in the solution. Moreover, you can simplify the solution even further: just compute the speed for each gear (along with its direction) during the graph search. Got a contradiction? There’s no rotation. Walked the whole graph without any contradiction? Output the computed speed for gear n. This immediately solves both T1 and T2.
The solution goes for a deeper understanding of what's going on. For example, it tries to explain that if there are no odd cycles, you will never encounter the situation where the gears get stuck because, for example, different wheels would try to push one particular wheel in the same direction but at different speeds.
Sure, you don't need that, it's enough to implement what you described. But skipping the deeper understanding of a problem is not a good long-term strategy for you.
(And by the way, what you simplified is not the actual implementation. Our implementation does not need to keep track of fractional speeds of the wheels between 1 and n. And if you use floats instead of fractions, there's one more point where your solution might fail, although I admit that in this particular case this is pretty unlikely.)
As for D (Dumb Clicking), I took the original JavaScript, unminified it on http://www.jsnice.org/ and modified it to generate the desired log for me. I didn’t have to query the canvas like the solution seems to say; I just had the reordering function fill in a
{"color type": [center_x, center_y]}map.