


Hello, Codeforces!
Yesterday slappy advised me to stop writing problems. I will not listen to his advice and will not stop coming up with new problems. Moreover, the idea of problem 1118C - Palindromic Matrix is mine, and I do not consider it bad or unsuccessful.
IMHO, this is a good example of a problem, where an sloppy (almost slappy) implementation leads to a casework, duplication of code and a lot of formulas. On the other hand, a well-turned implementation is devoid of all these drawbacks and easy to write. It seems to me that such feedback about the problem is something of a Dunning-Kruger effect.
In general, this is an important skill of the developer to write such code, which solves the problem reliably, concisely and is not dirty. And if your code smells bad, then instead of the shaming the authors, I urge you to think "can I write a solution to this problem better?". Good way is to read solutions of other participants. You can choose short implementations from experienced participants. If you focus on learning, rather than just participating for fun, this should be the rule: read solutions of other participants (better experienced, choosing short codes or extremely efficient) and learn. The fact that you got “Accepted” does not mean that you have nothing to learn with this problem.
Here is the explanation of my solution which was written in ~10 minutes. Please, read the problem 1118C - Palindromic Matrix if you don’t know the statement. This problem is just a generalization of string palindrome constructing problem on 2D.
In general case there are 3 types of elements of a matrix (I didn’t spend to much time on drawing, the image is not perfect):
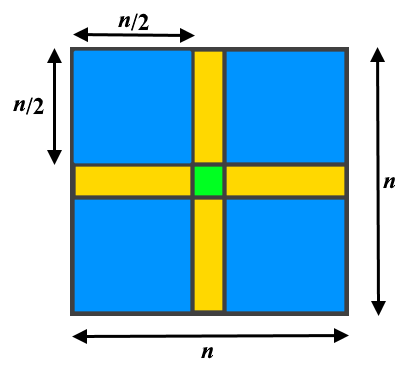
Each element in the blue area has 4 equal copies (itself and 3 additional symmetric cells). Each element in the yellow area has 2 equal copies (itself and 1 additional symmetric cell). And the single central cell (the green area) has only the single copy (itself). The yellow and green areas are absent in case of even n.
It means that you can fill the matrix with a greedy approach. At first process the blue area: for each cell take any value with number of occurrences at least 4 and fill the cell and its copies. After it process the yellow area (if any): for each cell take any value with number of occurrences at least 2 and fill the cell and its copy. Finally, process the green area (if any): take any value with number of occurrences at least 1 and fill the cell and its copy.
Easy to see that each time you can take a value with the greatest number of occurrences, so I used priority_queue<pair<int,int>> to maintain values ordered by number of occurrences. The first item in a pair is a number of occurrences, the second item in a pair is value itself. To construct such priority_queue q just use simple code like this:
map<int,int> cnts;
forn(i, n * n) {
int val;
cin >> val;
cnts[val]++;
}
for (auto [key, value]: cnts)
q.push({value, key});
To implement the rest of code, use simple function to reflect a position to the symmetric (in 1D):
int rev(int i) {
return n - i - 1;
}
Now the main part of the code is: iterate over blue, yellow, green areas and put values in the matrix (consider all symmetric copies in together):
int m = n / 2;
forn(i, m) // blue area
forn(j, m)
put({{i, j}, {i, rev(j)}, {rev(i), j}, {rev(i), rev(j)}});
if (n % 2 != 0) {
forn(i, m) { // yellow area
put({{i, m}, {rev(i), m}});
put({{m, i}, {m, rev(i)}});
}
put({{m, m}}); // green area
}
The function put takes a sequence of symmetric positions and put same values on them:
void put(vector<pair<int,int>> pos) {
auto t(q.top());
q.pop();
if (t.first < pos.size()) // can’t do it?
no();
for (auto [i, j]: pos)
a[i][j] = t.second;
t.first -= pos.size();
q.push(t);
}
So the complete code is very simple and contains only two if statements (almost no casework!).






I know this shall get too many downvotes, but honestly I enjoyed solving yesterday's C problem. Just finished silly bugs after 2 minutes contest ends, so couldn't submit within contest.
Well, first thank you for mentioning.
Second, I advised "such problem" not "problem". I mean most of the participants would have used same logic as described above, even I used same. But as u mentioned, you wrote this code in 10 minutes, well not everyone is MikeMirzayanov. It took me more than 1 hour and 15 minutes. I mean what's the purpose of printing the matrix, you could have just asked about printing "yes" or "no". If a participant knows the answer than surely he/she can print the matrix but it will take time for different people according to their speed. So basically it is speed that will matter?
Btw I know creating new problems is a hard work, So keep making problems and thanks for the platform.
So you said the problem is bad because it took you 1 hour to solve? WTF is this logic?
Looking at scoreboard, tons of people were able to solve it in 10-20 mins. The problem is super easy, only need some idea and does not require much difficult implementation or casework. Please stop complaining and solve more problems.
You need to go to the announcement blog and then read the comments.
Also It was a round for Div.3 (not Div. 1) participants and see how many solved problem C.
Yes I know it's a div 3 contest and 685 official contestants solved it. And several official contestants solved it within 10-20 mins.
See also how many solved B, I am not saying that only time should be taken into consideration, the place of problem(A, B, ..), and many things.
Also if some people solved in 10-20 minutes, then why are not looking for the number of people who solved it in more than 30 minutes.
You never talked about mis-ordering of problems in your comment "should stop setting problem C" and your 1st comment here. So:
It's not slow in typing. It's that they weren't good / experienced enough to figure out algo with simple implementation. Please do not confuse these things. Smart ideas like these are required in both competitive programming and real world software engineering. Are you trying to get better at programming or are you just going to make excuses and never become good?
You could check other problems. For example D1, D2, E, F1 were much more easily than C.
Exactly, that's my point if a participant is slow in typing or implementing whatever, then he/she will not even get time to read problem D1, D2, E, F1, or if he/she can read then he/she will not have enough time to solve it.
In fact many people would have felt this yesterday.
Also, you agree that C is harder in implementation than D1, D2, E...
Why do people usually think that problems with higher alphabetic order are harder than the others? When you are doing contests where all problems have equal scores, I think that you should spend some time to read all problems before actually starting to code since there is nobody (problemsetters) saying that the problems are sorted with ascending difficulties. Plus :
if a participant is slow in typing or implementing whatever, then he/she will not even get time to read problem D1, D2, E, F1, or if he/she can read then he/she will not have enough time to solve it
Read D1, D2, E, F1, at the first place and then decide which problem is faster for implementation/solving
Ah, this explains why problem A is always the easiest.
yeah, I saw even D2 was easier than C. So, why C should be that hard? such that we miss the easy problems? and in case of D2, why D1 needs? everyone who knows greedy knows binary search. and D2 was just like that https://www.spoj.com/problems/AGGRCOW/
Reading comments and blogs these days:
-I'm a newbie
+solve more problems!!
-I'm a LGM
+solve more problems!!
-I hate implementation
+solve more problems!!
-I hate math
+solve more problems!!
-I think I solve enough problems:
+solve more problems
-I just don't want to solve problems
+solve more problems!!
What’s wrong with it?
It would be an easier problem. Also, in general, yes/no problems are bad because the chance that someone can break through the tests is higher — IMO they should be avoided unless finding a solution or at least some unique information about it is serious overkill, which wasn't the case in this problem.
Thats why you cant even get over blue bro.
You're taking your bad performance as an excuse. It's no different than butthurt people failing a random problem in which they use rand() for a million-element array.
So solve more and get good.
I will not listen to his advice and will not stop coming up with new problems.Imo, It is your second best decision. :P
So what's his best decison?
Codeforces?
Yep.
Thanks to MikeMirzayanov for the platform.
As I've commented in opposition to slappy that it is a very interesting problem, because you need to optimize your implementation efforts, you need to find symmetries and so on... I liked this approach of Mike, very illustrative. My solution implementation was kind of similar (tbh, took more than an hour) and was as following:
7.1. If N is odd then compose middle YELLOW-GREEN-YELLOW row.
7.2. Until BLUE and YELLOW are empty: compose BLUE-YELLOW-BLUE row, and put it onto and under the existing matrix.
Perl code: 50241592
UPD. One more variant with similar idea:
1! Count a hash of occurences.
2! Depending on occurences push numbers to appropriate array (BLUE, YELLOW or GREEN).
3. If BLUE contains surplus of numbers, then transfuse them to YELLOW (with doubling them).
4. Output "NO" if N is odd and size of GREEN is more than 1 OR BLUE has deficit of values (i.e. less than (n/2)^2).
5. Generate final matrix by accretion:
5.1! Make n/2 x n/2 matrix of numbers from BLUE array.
5.2! To the end of each row push an extracted number from YELLOW array and reversed initial row.
5.3! If GREEN array is not empty, add a row consisting of an element of GREEN array, surrounded by YELLOW array and its reverse.
5.4! Add new rows to the matrix by reversing first n/2 rows.
6. Output "YES" and the final matrix.
Perl code: 50400979
Mike, even you started writing posts for contribution? :P
Don't know why many of them saying this not a good problem but I personally enjoyed this problem and was able to submit the code just before 5 min of the contest
no complain, but a lot of people missed D1 and D2 for this C. D1 and D2 was easier.
So it's a good lesson learned — read other problems if you're stuck with implementation of one of them.
This is a problem with simple idea but tricky implementation. If you screw it up, it will take you an hour. If you make it smart, it may take you 10 minutes. This is one of the skills you need to gain to advance to next level(s).
I'm not an expert here (yet), but I'm sure you will face a lot of problems like this, going forward.
And yes, problem C sometimes takes more time to implement than problem D and may have less successful solutions than problem D. Even if its score is less than of problem D. That's life :)
I was half-conscious while solving this, taking an hour with 7 WAs before finally AC (even not doing any caseworks). Still, I enjoy this problem. It was easy in terms of ideas, yet painful if your implementation skills are bad.
Still, actually solving it with a neat solution is a prize worth claiming for anyone.
IMHO, this is a good example of a problem, where an sloppy (almost slappy) implementation leads to a casework, duplication of code and a lot of formulas. On the other hand, a well-turned implementation is devoid of all these drawbacks and easy to write. It seems to me that such feedback about the problem is something of a Dunning-Kruger effect.
Fully agreed with this part.
I have a complain on that, sequence sould be C1, C2, D(C1, C2 should be D1 and D2 as they were easier).
Not quite.
can't you relate this with that after a little greedy. https://www.spoj.com/problems/AGGRCOW/
honestly, round looked like div2 than div3. just see the problem rating. C = 1700, D1 = 1800, D2 = 1900, E = 2000, F2 = 2700(IGM level)
Don't trust the high-level problem ratings in div2/3 rounds. It is illusionary because the problem is considered to have "beaten" a lot of weak-ranked players. It is sort of like how some chess players beat up a bunch of low ranks to artificially inflate their ratings.
oh! i see. that's the reason i am finding D1, D2, E, F1 so easy.
Thanks a lot.Although I didn't solve this problem in the contest,I learn a lot from your code about modern c++ programing:)
There's actually a very easy way to implement this without having to think about indexes, symmetry, sections, halves and quarters.
You are always looking at (at most) 4 squares. Let's keep 4 variables to keep track of the squares we are currently analyzing:
i_left, i_right(for the line indexes) andj_left, j_right(for the column indexes). Then you can iterate through them like this:This way, you get rid of all the "index arithmetic", case analysis and symmetry tracking. In my opinion, this relieves a lot of the headache and reduces the chance to get things wrong.
Full code 50188880
The provided code is not compiling in GNU G++14 but works absolutely fine in GNU G++17. Can someone explain why?
Because of the structured binding
auto [key, value]. That syntax only is valid since C++17.