


Разбор задач Codeforces Round #215
368A - Сережа и вешалка
Будем каждый раз циклом проходить по массиву и искать минимальный элемент, который еще не помечен. Если мы найдем элемент, добавим в ответ и пометим, иначе отнимем от ответа штраф.
368B - Сережа и суффиксы
Предпосчитаем значение ansi — количество различных элементов на суффиксе с i. Для подсчета пройдемся с конца массива, и будем считать ansi = ansi + 1 + newai, newai равно 1, если элемент ai еще не встречался и 0 в противном случае.
367A - Сережа и алгоритм
Если разобраться в том, что написано в условии, то станет понятно что алгоритм закончит свою работу, если мы можем получить строку вида: xx, yy, zz, zyxzyxzyx... и все ее циклические сдвиги. Для проверки нужно просто знать количество букв x, y и z по отдельности. Количества можно считать с помощью частичных сумм.
367B - Сережа и анаграммы
Разобьем последовательность на min(n, p) последовательностей. 1-й, (1 + p)-й, (1 + 2·p)-й, ... символ идет в первую последовательность, 2-й, (2 + p)-й, (2 + 2·p)-й... идут во вторую последовательность и так далее. Теперь ответ нужно найти для каждой из них, считая что p = 1. Это можно решить простым методом. Можно пройтись по последовательности слева на право и посчитать количество вхождений каждого числа. Если количества вхождений каждого числа будет совпадать с количеством вхождения того же числа во вторую последовательность, то все ОК.
367C - Сережа и расстановка чисел
Понятно, что нужно набрать как можно больше самых дорогих чисел, что бы из них можно было построить массив. Замечу, что имея n чисел, мы будем иметь m = n·(n - 1) / 2 обязательных связей. Видим, что это граф, в котором нужно сделать Эйлеров путь, добавив как можно меньше ребер. Для n%2 = 1 — все ясно, а для n%2 = 0 нужно добавить n / 2 - 1 дополнительное ребро. Почему? Это Ваше домашнее задание :)
Так же подробное объяснение Вы можете найти здесь.
367D - Сережа и множества
Заменим все множества одним массивом, где элемент — номер множества, которому принадлежит индекс. Теперь возьмем все последовательные отрезки длиной d и найдем множество элементов, которое там не встречается. Понятно, что если в качестве ответа мы выберем подмножество такого множества, то оно нам не подойдет. Запомним все такие "плохие надмножества". Когда мы всех их знаем, найдем все "плохие" множества. Выберем самое большое по количеству элементов не плохое множество. Лучше всего здесь работать с битовыми масками.
367E - Сережа и отрезки
Будем считать, что отрезки отсортированы, а в конце ответ домножим на n!, мы можем так сделать, так как все отрезки будут различные.
Рассмотрим два случая n > m и n ≤ m. Казалось бы нужно для обеих писать динамику за разную сложность, но не сложно показать, что в первом случае ответ 0. Второй случай делается следующей динамикой: dpi, l, r, i — сколько чисел мы рассмотрели, l, r — только на этом интервале отрезков будет присутствовать i. Так же нам будет нужна вспомогательная динамика si, l, i — сколько чисел рассмотрели, l — сколько отрезков уже закрыто, и i ничему не принадлежит. Переходов будет 4, так как на каждом числе у нас может начинаться и заканчиваться не более одного отрезка.
Осталось прилепить число x, это делается достаточно просто: просто добавим еще один параметр 0 / 1 в динамику, было ли у нас такое начало интервала или нет. Учитывая нашу динамику, это не составит труда.







Серёжа, а ты правда пишешь разборы после контеста?
да, временами)
Я не могу понять людей, тратящих не меньше 20 часов реального времени (навскидку) на подготовку контеста, и не находящих полчаса, чтобы написать до него разбор.
Сегодня мне было не до разбора, честно :)
Я один раз таки написал до раунда и случайно удалил. В итоге долго понимал, как восстановить, и все равно с задержкой получилось =(
Sometimes I prefer to read the Russian tutorial, instead of the "Google Translated" one.
P.S.: I don't know Russian.
Next time change codeforces.ru to codeforces.com ayer than translate. It was hardliners to the Russian site in the initial blog.
Someone should write notes with Chinese
Только у меня такая сказочная конструкция вместо разбора одной из задач?
Guys, change the URL to codeforces.com/... instead of codeforces.ru/... for the tutorial in English, it is available there..
hope it helps !
Could anyone please give a detailed explanation of problem B Div 1? I do not undestand why we can consider p = 1?
Split the sequence a into subsequences (vectors): subsequence ci is composed of numbers ai, ap + i, ..., akp + i (i < p). Then, we only need m consecutive elements of ci.
why does it work fast? It will be O(p * m)?
It's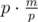
Upd. Oh, yep, it's a crap.
Upd2. Oh, no, it's really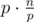 . Show why it's wrong, if it is.
. Show why it's wrong, if it is.
It's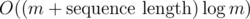 per every sequence ci which contains at least m elements; if a sequence contains less, we can just ignore it and not run any algorithm on it at all. There are at most
per every sequence ci which contains at least m elements; if a sequence contains less, we can just ignore it and not run any algorithm on it at all. There are at most 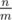 such sequences, and the sum of their lengths is at most n, so it's
such sequences, and the sum of their lengths is at most n, so it's 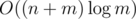 amortized.
amortized.
I have been working on "Sereja and Algorithm" for a few days, but I cannot see why we just need to count the number of x, y and z and compare them.
I understand that it's necessary, but I don't see why it's sufficient. Could someone explain that?
What you're asking about is whether it's always possible to rearrange the string to one of the form "zyxzyxz..". The algorithm doesn't specify any rules for which triples to rearrange (just that it can't be 'zyx' or its cyclic equivalents), so we can choose what's best for us.
Imagine that there's a resulting string R, which is a permutation of letters of the input string S, and on which the algorithm terminates (the necessary condition).
In every step, find the first position i in which S and R differ. It's obvious that the suffixes S[i..] and R[i..] will also be permutations of each other. Letter R[i] must appear in S somewhere later, let's say that S[j] = R[i]. Take the triple S[j - 1..j + 1] and rearrange (permute) it so that S[j] becomes S[j - 1]. This way, the wrong letter always moves one position left, without changing the prefix S[0..i - 1], so it eventually moves to S[i].
Even if we can't choose the triple S[j - 1..j + 1] if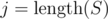 , we can just either choose S[j - 2..j] for i < j - 1, or for
, we can just either choose S[j - 2..j] for i < j - 1, or for 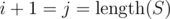 permute the whole incorrect part of S (which is just 2 last letters plus the one between them) to become identical to the last triple in R.
permute the whole incorrect part of S (which is just 2 last letters plus the one between them) to become identical to the last triple in R.
We see that a finite number of steps increases the longest common prefix of R and S by 1, so the 2 strings can be made equal.
Thanks for your reply.
What if S[j-1 .. j+1] is one of "zyx", "xzy", "yxz"?
There are more border cases to consider (and I'm sleepy), but the main idea is that you can keep taking triples which only contain the first 2 or last 2 letters of any substring that you can't choose, and shuffle those to turn it into a substring from which you can choose any triple.
Problem E has another nice solution, but I have absolutely no idea how to prove it, I found it through trail and error. Time complexity is $$$O(nm)$$$ — code
Basically it comes down to proving this: The number of sorted sequences of $$$n > 1$$$ segments such that the last segment is $$$[x,y]$$$ is $$$\frac{1}{n(n-1)}\binom{x-1}{n-1}\binom{y-1}{n-2}(ny-(n-1)x)$$$. Next, try all values of $$$y$$$ between $$$x$$$ and $$$m$$$ and all values of $$$k$$$ from 1 to $$$n$$$ — the index of the segment which has $$$x$$$ as its endpoint in the sorted sequence and apply the formula above.
How does one come up with this formula?