


651A - Джойстики
Автор идеи: fcspartakm, разработчик: fcspartakm.
Главной идеей решения является то, что в каждый момент времени нам нужно заряжать джойстик с самым низким уровнем заряда. По-этому мы можем просто проэмулировать процесс или вывести простую формулу за O(1).
651B - Красота картин
Автор идеи: fcspartakm, разработчик: fcspartakm.
Давайте посмотрим на ответ, в нем будет несколько подряд идущих отрезков возрастания красоты, а между ними красота будет падать. Будем решать задачу жадно: давайте отсортируем массив значений и будем набирать возрастающие куски по очереди. Чтобы набрать очередной кусок мы идем слева-направо и среди каждого множества картин с одинаковым значением мы выберем только одно. Так будем продолжать пока картины не закончатся.
Если аккуратно это реализовать, то получим решение за  .
.
Но такое решение дает нам всю последовательность, но в задаче от нас по-сути просили вычислить только число отрезков возрастания. Из прошлого решения следует, что мы наберем столько отрезков возрастания, сколько максимум раз повторяется в массиве одно из наших чисел. Очевидно, что мы не можем набрать меньше. Получаем решение за O(n).
651C - Хранители/650A - Хранители
Автор идеи: ipavlov, разработчик: ipavlov.
Когда манхетенское расстояние совпадает с евклидовым?
deu2 = (x1 - x2)2 + (y1 - y2)2
dmh2 = (|x1 - x2| + |y1 - y2|)2 = (x1 - x2)2 + 2|x1 - x2||y1 - y2| + (y1 - y2)2
Это означает, что они равны только когда x1 = x2 или y1 = y2. Что посчитать ответ нам нужно выяснить, сколько точек лежат на каждой горизонтальной и на каждой вертикальной прямой. Это легко сделать с помощью std::map/TreeMap/HashMap/Dictionary, или если просто отсортировать координаты.
Если у нас есть k точек на одной горизонтальной или вертикальной прямой, то они добавят в ответ k(k - 1) / 2 пар. Но таким образом мы дважды посчитаем пары совпадающих точек, то есть нужно будет вычесть из ответа посчитанные таким же способом числа пар одинаковых точек.
Если мы воспользовались TreeMap/sort, то мы получим решение за , а если unordered_map/HashMap, то O(n).
651D - Просмотр фотографий/650B - Просмотр фотографий
Автор идеи: fcspartakm, разработчик: fcspartakm.
Какие фотографии мы увидим в конце? Сколько-то от начала и возможно сколько-то с конца. Всего есть 4 случая:
- Мы всегда двигались только вправо.
- Мы всегда двигались только налево.
- Сначала мы двигались направо, потом сменили направление движения, прошли все просмотренные фото и продолжили движение налево.
- Сначала мы двигались налево, потом сменили направление движения, прошли все просмотренные фото и продолжили движение направо.
Первые два случая делаются банально, просто эмулируем. Третий и четвертый случай можно решить с помощью метода двух указателей. Заметим, что если мы пройдем в третем случае на одну картину больше справа, то мы потратим больше времени и число просмотренных фото слева уменьшится. Так двигаем эти два указателя и пересчитываем текущее время.
Это решение работает за O(n).
Альтернативным решением является зафиксировать сколько мы пройдем справа, а потом найти сколько мы пройдем слева с помощью бинарного поиска. Для этого нам нужно будет предподсчитать для каждой позиции слева и справа, сколько времени мы потратим, дойдя до нее.
Это работает за , что немного дольше, но возможно кому-то так проще было решать.
651E - Сжатие таблицы/650C - Сжатие таблицы
Автор идеи: LHiC, разработчик: iskhakovt.
Сначала решим задачу, когда все значения различны. Мы построим граф, где вершинами будут являться ячейки таблицы, а ребра будут вести из одной ячейки в другую, если у первой значение меньше, чем у второй и они лежат в одной строке или в одном столбце. В этом графе нет циклов, так что мы можем вычислить сжатые номера ответа с помощью динамического программирования:
for ( (u, v) : Edges) {
dp[v] = max(dp[v], dp[u] + 1);
}
Мы можем это сделать с помощью топологической сортировки или ленивых вычислений.
Если мы построим граф как описано, то в нем будет O(nm(n + m)) ребер. Чтобы уменьшить это число мы отсортируем каждую строку и каждый столбец и добавим ребра только между соседями в этом порядке. Тепеть у нас O(nm) ребер, которые мы вычисляем за время 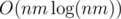 .
.
Теперь вспомним про одинаковые значения. Давайте построим точно так же второй граф, но теперь в нем ребра будут означать равенство. Теперь если мы найдем компоненты связности в этом графе, они и будут являться вершинами нашего нового первого графа.
650D - Канатная дорога
Автор идеи: LHiC, разработчик: LHiC.
Нам нужно вычислять длину наибольшей возрастающей подпоследовательности (НВП) после каждого из независимых изменений к массиву.
Для начала вычислим длину НВП в нашем исходном массиве и обозначим её за k. Пока мы это вычисляем, нам понадобится хранить дополнительную информацию lenl[i] — максимальную длину НВП, заканчивающуюся на данном элементе. Аналогично нам понадобится lenr[i] — максимальная длина НВП, начинающейся с данного элемента (мы можем это вычислить аналогично, только нужно будет идти по массиву в обратную сторону).
Давайте решим тот случай, когда наш новый элемент будет лежать в новой НВП. Длина максимальной НВП, проходящей через эту точку будет равна maxi < a, h[i] < b(lenl[i]) + 1 + maxj > a, h[j] > b(lenr[j]). Это можно вычислить онлайн с помощью персистентного дерева отрезков или оффлайн с помощью обычного дерева отрезков и метода сканирующей прямой, что будет работать за  на запрос. Это единственный случай, когда ответ будет больше k, точнее он может быть только k + 1.
на запрос. Это единственный случай, когда ответ будет больше k, точнее он может быть только k + 1.
Во втором случае, когда наш элемент не входит в ответ, но то что мы его поменяли привело к порче всех исходных НВП, то ответ будет k - 1. Иначе у нас останется хотя бы одна НВП длины k, она и будет ответом.
Как это понять? Давайте посчитаем число НВП в исходном массиве по какому-нибудь модулю. Мы можем это сделать с помощью динамического программирования также, как мы искали саму НВП, например с помощью дерева отрезков. Тогда мы можем проверить, если liscount = liscountleft[a] * liscountright[a], то это как раз означает, что все НВП проходят через наш элемент.
Если вам не нравится решение с таким "хешированием", то есть алтернативный честный подход. Для каждого элемента давайте поймем, может ли он входить в какую-нибудь исходную НВП, а если может, то на какой позиции(эта позиция будет как раз равна lenl[i]). Тогда для каждой позиции мы посчитаем, сколько различных элементов претендуют на нее. Если только один элемент, то это как раз и означает, что все НВП проходят через него.
Получаем решение за .
P.S. Мы можем решить эту задачу без использования структур данных с помощью альтернативного метода вычисления НВП с помощью динамического программирования и бинарного поиска.
650E - Часовой механизм
Автор идеи: Zlobober, разработчик: Zlobober.
Первое соображение: ответ всегда равен числу ребер, которые есть в первом дереве, но которых нет во втором. Это означает, что если у нас есть ребро, которое лежит в обоих деревьях, то это ребро можно удалить, а те две вершины, которые оно соединяло, объединить в одну, ничего не изменится.
Второе соображение: если мы возьмем любое ребро из первого дерева и удалим его, то всегда найдется корректное ребро из второго дерева, которое можно вставить обратно (если такого нету, то это означает, что второй граф не связен, а он дерево, противоречие). Таким образом порядок замены ребер из первого дерева может быть произвольный.
Третье соображение: если мы взяли лист в первом дереве, выкинули соответствующее ему ребро, то мы можем добавить любое ребро из второго дерева, которое ведет из данной вершины.
В итоге получаем алгоритм: храним списки ребер в вершинах, когда ребро общее, то объединяем вершины с помощью системы непересекающихся множеств, а их списки склеиваем вместе. Чтобы получить порядок ребер в первом дереве мы сделаем его обход в глубину и получим такой список, что если мы уже убрали все прошлые ребра, то следующее всегда будет листом.
Получаем асимптотику O(nα), что на практике является линейным алгоритмом.





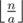 . Иначе выгоднее в начале покупать стеклянные бутылки, пока можно. В этом случае, если у нас есть хотя бы
. Иначе выгоднее в начале покупать стеклянные бутылки, пока можно. В этом случае, если у нас есть хотя бы 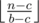 стеклянных бутылок, а на остаток докупим пластиковых. Получаем решение формулами за
стеклянных бутылок, а на остаток докупим пластиковых. Получаем решение формулами за 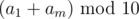 . Попробуем понять чему равно
. Попробуем понять чему равно 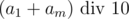 . Если остаток равен 9, то так как максимальная сумма двух цифр равна 18, значит
. Если остаток равен 9, то так как максимальная сумма двух цифр равна 18, значит 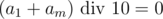 . В противном случае результат однозначно определяется тем, был ли перенос в самом левом разряде при сложении или нет. Получается, что мы выяснили чему равно
. В противном случае результат однозначно определяется тем, был ли перенос в самом левом разряде при сложении или нет. Получается, что мы выяснили чему равно 