


| # | User | Rating |
|---|---|---|
| 1 | tourist | 3880 |
| 2 | jiangly | 3669 |
| 3 | ecnerwala | 3654 |
| 4 | Benq | 3627 |
| 5 | orzdevinwang | 3612 |
| 6 | Geothermal | 3569 |
| 6 | cnnfls_csy | 3569 |
| 8 | jqdai0815 | 3532 |
| 9 | Radewoosh | 3522 |
| 10 | gyh20 | 3447 |
| # | User | Contrib. |
|---|---|---|
| 1 | awoo | 161 |
| 1 | maomao90 | 161 |
| 3 | adamant | 156 |
| 4 | maroonrk | 153 |
| 5 | -is-this-fft- | 148 |
| 5 | SecondThread | 148 |
| 5 | atcoder_official | 148 |
| 8 | Petr | 147 |
| 9 | nor | 144 |
| 9 | TheScrasse | 144 |
|
+266
I can confirm that I had a lot of issues with wuhudsm during my time as CodeChef Head Admin. One of those issues, which was not the focus here although you can see it in screenshots regarding problem proposals and errorgorn's first comments to them: wuhudsm seem to think that vague idea of what the problem might be about, without limitations or intended solution is already a good enough thing to propose. I guess the idea is that the coordinators will figure out what to do next with this half-baked idea, maybe they will come up with an interesting solution or mend the idea into actually being a problem one can solve and therefore wuhudsm can use in a contest as author. I understand that coming up with problems is not an exact science and one of the valid methods is to throw shit against the wall and see what sticks, then mend and form it to make a problem. The issue is that the person doing the mending should be yourself, or maybe your collaborators. Not the coordinator. It is not the coordinator's job to actually come up with a problem for you. Yes, sometimes they do this and you should be grateful, but you shouldn't make it the norm. There was (or maybe still is, I'm too old to remember) a trend when authors posted how many problems were rejected to make their round. And it was supposed to be "the higher that number is — the better". I don't understand the logic here. The only thing a high number proves is that your internal bar for "the problem I'm not ashamed to show the coordinator" is waaaay too low. wuhudsm decided to go even further and send "not a problem"s to coordinators (plural). I guess it kinda makes sense to send it to several coordinators at the same time because it increases the probability that one of them will come up with an actual problem while looking at the shit you sent. I was very surprised when I saw that wuhudsm is setting CF rounds, while also maintaining "The Forces" community whatever the fuck that is and people seem to like his problems and be thankful for his contribution. I thought "maybe he got better" but I guess he just doubled down on his shitty behaviour and found targets that are kinder than me (not a dig at current CF/CC coordinators, nothing wrong with being nice to potential problemsetters). I'm really glad that errorgorn was brave enough to publicly talk about this situation. I think we would all benefit from having better insight into coordinators' work. It is not an easy side gig, and a good coordinator is the thing that separates good rounds from bad. |

|
+260
We are carefully looking into the situation and will inform you when we make a decision. |

|
+129
Psychotic_D was taking a session on problem-setting day before yesterday. While he was entering Polygon, one could see several CF alt accounts auto saved. Fortunately, I took a note of that and found EndlessDreams's account was also saved by him. Here is the image supporting my claim.
|

|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 8 hours ago
+117
That's racist. If someone from a country is a cheater it doesn't give you any information about other citizens of that country. |
|
+98
Ok, he gave 4 bad examples which hid the actual example. That definitely looks like cheating. Thanks for providing the evidence. MikeMirzayanov please look into it (the 4th submission pair) |

|
+84
After went through the post and the comments(including the explanation wuhudsm wrote). My summary is that wuhudsm had a wrong understanding about that coordinator has the authority to compose the problems into a contest instead of the writer himself. I think errorgorn was right to point this out and now making wuhudsm on the same page. This reduces the chaos in the future. Actually I'd also like to point out that wuhudsm did a great job on creating interesting problems on many platforms. I've partipated Codeforces, Codechef, TheForces rounds authored by him. I've also been a tester of his round like 960. I want to say that a productive writer like him is making the community better and better. As long as they are on the page, I would suggest we give wuhudsm more chance to grow and improve instead of criticize on the mistakes. |

|
+80
As a lot of comments above me have already said, the fourth submission pair you provided in this blog is a good evidence for the claim you are making. I hope that someone with appropriate power will take action soon. I am writing this comment in response to this:
I believe the elephant in the room that we need to address in these "exposing cheaters" blogs is the fact that the blog doesn't immediately go to its main points, which takes more of HQ's time to process and take action. To me, the important pieces of information in this blog are:
The other parts aren't necessary for HQ or other relevant people to take action, are they? The more irrelevant information you include, the less credible your blog becomes, and the less people want to believe your evidence. I would really appreciate it if "exposing cheater" blogs were straight to the point, presenting the objective facts on why the person is cheating, not filled with other unnecessary information merely to attract attention. |

|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 13 hours ago
+72
Codeforces lore going wild. Can't wait for season 2. |

|
+69
Poor kitty got photobombed... |

 ♡♡♡
♡♡♡ |
+62
It seems that it's your alt account. |

|
+60
As a tester, I wish good luck to participants! |

|
+59
Mike doesn't look into anything until it gets hundreds of upvotes lol. That's why cheaters set rounds and only get punished 8 months later. |

|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 13 hours ago
+57
This is how you properly investigate. Not the random personal garbage in the previous threads. |

|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 12 hours ago
+52
This is the real "Catching the mole"! |

|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 12 hours ago
+51
thinking that cheaters are the reason you aren't high rated is a cope to avoid confronting the fact that you need to improve at cp |
|
+50
I'm afraid your financial future looks bleak my man. Of course, one can disagree on the definition of "very useful topic". But I agree that all the listed topics are useful, especially the Lucas Theorem which I used dozens of times which is unheard of for such a seemingly niche thing. |
|
+48
Is he a tester?
|


|
+46
Since i was hosting this session, i can confirm this Screenshot is true. Sad to read this. But from his skills i am not really sure is he cheating or not... cause not everyone can explain problem setting etc if they are not decently pro. |

|
+46
bad B2! |

|
+44
The live scoreboard is finally up! https://scoreboard.egoi23.se/scoreboard_2024.html |

|
+43
dxqwq almost certainly is innocent, you should not throw accusations of cheating around as it lowers the credibility for the rest of your claims. The only good evidence in this thread is the fourth submission pair. |
|
+43
"Errmmm, actually" |

|
+40
As a tester again, I tested today. |

|
+40
It only proves he is not totally incompetent His true skill might be of CM, Master or even IM as he is currently. However, it is true that he used false means to get here regardless of whether its his true skill or not. |
|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 12 hours ago
+40
|


|
+38
Ok i didnt inspect this one that carefully. It does look like cheating. It's like the fourth in the list and the other ones didn't convince me so i just skimmed through it |

|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 12 hours ago
+38
You have a nice storytelling style. Can’t wait for part 3! |
|
+37
Bro does NOT have a sense of humour/friends |
|
+37
nice cat |

|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 13 hours ago
+37
That is a damn good investigation bro. |
|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 10 hours ago
+37
ICPC |
|
+37
B2 with 500 pts is just not worthy doing... To many cases make it not beautiful.(in my algo) And C is mostly a Elementary mathematics prob. |

|
+37
I don't like math :( |
|
+36
The link is broken. My friend saved it before it vanished so I reuploaded it.
|

|
+35
|


|
+35
Bro really tried to play 4d chess but ended up getting mated himself. |
|
+35
|

|
+34
Problem D is just a copycat of this problem: https://acmp.ru/index.asp?main=task&id_task=884 Simply copy pasted my old code and got AC in 10 mins, dislike for testers. |
|
+33
Heyo, for those who are reading this, I highly recommend you to participate in Codechef Starters 144. Even though I was never a big fan of CodeChef contests, I watched satyam343 pour his heart, sweat, soul and tears into the contest. Even if you don't usually do CodeChef, you should totally make an exception just this once! |

|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 13 hours ago
+33
i said the evidence was bad, not that he didnt cheat (in fact if you take a look at my messages, you will see that i wrote I myself find it suspicious) I also tagged mike in the previous to previous blog where there was actual evidence. I care only about the truth and I repeat i am not a friend of his. https://codeforces.com/blog/entry/131781#comment-1173618 |
|
+33
In C if $$$a_i$$$ is turned into $$$\text{log}$$$ $$$a_i$$$, it's the same problem as 1883E - Look Back. |

|
+32
B was pretty bad imho. Why did B2 have so less points? It was much harder than B1 |

|
+31
I am not sure Mike saw it. But some of the evidences in this post are 100% bullet-proof, unlike the ones from the previous post. Please see the discussion above. Don't ask people to stop attracting attention to cheaters. Instead thank them for doing such work. |

|
+31
Is cat an official problem setter? |

|
+31
thank you for giving me such a special experience of eating s**t. |

|
+31
|
|
+30
|



|
+30
In conventional math typesetting,
|
|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 11 hours ago
+30
I hope defnotmee will be joining the FBI shortly. |

|
+28
You going to ICPC proves nothing. And btw different colleges have different criteria so, many tier-1 colleges like IITs, BITS, NITs have multiple team participating so they tend to select their top teams even though they are above the cutoff and many tier-3 colleges like yours have very few teams participating so to diversify different colleges participating they select many colleges that are way below the rankings of many tier-1 bottom teams. Dont boast just because you are selected for regionals. for all we care you could have cheated your way like him. It was an online contest after all. If you cant support then please keep your opinion to yourself if you cant understand the proofs given. |

|
+28
Please give some easy and good questions :)
|


|
+28
No, because these trees grow upside down! |
|
+27
I've always wanted to know why most people who catch cheaters seem to write blogs that are barely coherent, disorganized messes. |
|
+26
Big fan btw :) |
|
+25
Firstly, ICPC rankings are given to teams, not to individuals.(The fourth highest rated person from the same college as him has gotten plagiarized on Codechef and has multiple skipped submissions on codeforces but still his team did extremely well at ICPC Regionals, for instance). Secondly, This is just way too much evidence for someone to be innocent imo. |
|
+25
I guess that depends on the definition of cheating. I wouldn't say I cheated, but I definitely (accidentally) helped other people cheat. |
|
+24
we will never know who has the best cheating practices |

|
+24
Now Dhurvil is caught red-handed. I urge the ban of these cheaters from CF and ban their IP address so that they may not form new accounts. MikeMirzayanov KAN Dominater069 acraider Priyansh31dec lookcook pkhaustov |
|
+24
Lmao he just changed pair to 2d dp .How tf did it survive plag check |

|
+24
worst contest last time |

|
+23
As a tester Hint |

|
+22
An insignificant addition but I always write algorithmic complexity as Note that to view the difference properly you might want to change your math renderer into "Common HTML" or "SVG" (you can do it by right-clicking a LaTeX formula):
|

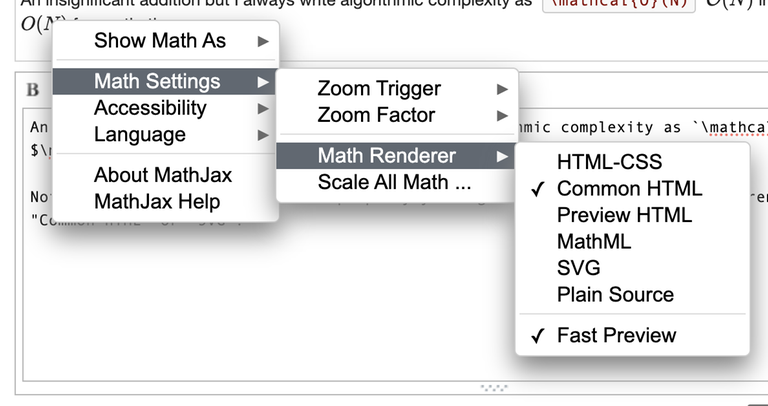
|
+22
As a tester, I wish good luck to every participant! |

|
+22
MathForces |
|
+22
Thanks, you just made me rich. |

|
+21
satyam343 Orz |

|
+21
I agree with you that these behaviors are not professional and need to be fixed. But we had to see that these behaviors are not initiated from evil purposes (IMO evil purposes here are something like cheat to get high rated or screw up a contest). I believe that he wants the community to be better. Just give him some time to grow up and to be more professional. |
|
+21
I have not been contacted about the cash prize. Should I just wait, or? |

|
+21
Spreading awareness about shitty behaviour is not bullying. |
|
On
peltorator →
"never submit" strategy: state-of-the-art competitive programming approach by tourist, 2 days ago
+20
tourist failed his strategy 10 mins after he came to confession : ) just like I fail my strategy to solve problems. |

|
+20
Disagree with this opinion: This problem('s statement) is much more beautiful than that (even if i am a Chinese, i still think the problem you mentioned is too complex for me to appreciate). And most of all, this is an atcoder BEGINNER contest (I do agree with that on a ARC or AGC original-idea-problem is important), reusing some beautiful ideas should be encouraged: If evan ABC could not introduce this one, how people around the world could know it. |

|
+20
Bravo. I think I think we shouldn't use program language in math formula: $$$a=a+1$$$ or $$$a\gets a+1$$$ I think we should use GCD has it's |

|
+19
Yousef_Salama 2nd grade, registered 13 years ago! lol, thats crazy |
|
+19
As a multiple time contributor of TheForces, I notice that I also faced the same situation with 1936E. I like his problem and want to help the community, but according to current things around the community, I shouldn't too trust random people. Shame on me... |

|
On
peltorator →
"never submit" strategy: state-of-the-art competitive programming approach by tourist, 41 hour(s) ago
+18
after a contest, about half of the participants wish they had employed this strategy |
|
+18
A pedantic $$$TeX$$$ nician here... For math operators like lcm, I suggest using In the case of mod, using For $$$\times$$$, I would avoid using it except for the matrix dimension (like "an $$$n \times m$$$ matrix"), because avoiding $$$\times$$$ and $$$\div$$$ is mostly a convention in math typesetting (except for elementary school textbooks), but I admit this is largely a matter of taste. |
|
+18
I have provided some evidence and clues to the CF administrator this afternoon(it is UTC+8 here). I sincerely hope that everyone will not hastily draw conclusions and wait for the official results. |

|
+18
blud tried to cook the contest, but at the end he got cooked himself |
|
+18
searching up tourist is crazy |

|
+18
what in the facebook is this bruh |
|
+18
Rare occurrence when I lost any remaining will to solve problems in a contest See you again never |

|
+17
What are the score distributions? |
|
+16
finally satyam343 round |

|
+16
OMG ORZ satyam343 I AM YOUR BIGGEST FAN |
|
+16
Have you provided for or against? |
|
On
Vladithur →
EPIC Institute of Technology Round Summer 2024 (Div. 1 + Div. 2) Editorial, 27 hours ago
+16
I thought this idea was really neat, so I decided to write my own implementation of it with some comments to make it accessible. Thanks for sharing! 271969422 O(n) per test case |

|
+16
As a tester, the problems were really nice 👍 |
|
+16
why even make problem like C? slowing down use of double for TL really make problem little bit fancy? |
|
On
defnotmee →
Catching the Mole II(Hard Version) (Psychotic_D cheating case aftermath), 2 hours ago
+16
To make a few things clear: As the founder of TheForces I swear that we've not shared any solutions during any official contests from any platform, to make sure that we're not a big cheating group, you can ask the trusted testers of codeforces who have been TheForces members for a long time. I'm also shocked now because I didn't know this amount of cheating between some of our moderators, I'll make everything clear asap. |

|
+15
Psychotic_D do you remember something? "It's easy to bypass MOSS, I think. Someday (today) cheaters will know they don't have to share codes, sharing ideas is enough." |
|
+15
The submissions look awfully suspicious. I urge codeforces to look into it. MikeMirzayanov |
|
+15
guess what dhruvil has done now which shows he did cheat?? |

|
+15
As not a tester, I hope I get +3 delta |

|
+15
First of all, having alternate accounts is against the rules. Second, my claim is that Psychotic_D and EndlessDreams are two different people sharing codes. That is even more agains the rules. |
|
+15
Interesting scoring distributuion |
|
+14
i suppose this is sarcastic right? |
|
+14
Wrong question. Geothermal how much did you pay? |

|
+14
As a tester, this is my first contest as a tester, I wish luck for participants! |

|
+14
Scoring distribution when?? |

