Легко видеть, что в задаче возможно всего три случая. Если король находится углу доски, то у него 3 возможных хода. Если он стоит на краю доски, то у него 5 возможных хода (если конечно он не в углу). Наконец, если король не стоит на краю доски, то у него всего 8 возожных хода.
Решение на С++char c, d;
bool read() {
return !!(cin >> c >> d);
}
void solve() {
int cnt = 0;
if (c == 'a' || c == 'h') cnt++;
if (d == '1' || d == '8') cnt++;
if (cnt == 0) puts("8");
else if (cnt == 1) puts("5");
else if (cnt == 2) puts("3");
else throw;
}
Сложность: O(1).
Легко видеть, что ответ всегд находится в одной из заданных точек (функция суммарного рассояния между парой заданных точек монотонна). Далее можно либо для каждой точки посчитать суммарное расстояние и выбрать оптимальную точку, либо заметить, что ответом является точка находящяяся посередине в отсортированном списке заданных точек (если точек чётное количетсво то слева посередине). Последний факт легко доказыватся, но можно это и не делать и сдать задачу первым способом.
Решение на C++const int N = 300300;
int n, a[N];
bool read() {
if (!(cin >> n)) return false;
forn(i, n) assert(scanf("%d", &a[i]) == 1);
return true;
}
void solve() {
sort(a, a + n);
li suml = 0, sumr = accumulate(a, a + n, 0ll);
li ansv = LLONG_MAX, ansp = LLONG_MIN;
forn(i, n) {
li curv = li(i) * a[i] - suml;
curv += sumr - li(n - i) * a[i];
if (ansv > curv) {
ansv = curv;
ansp = a[i];
}
suml += a[i];
sumr -= a[i];
}
assert(sumr == 0);
assert(ansv != LLONG_MAX);
cerr << "ansv: " << ansv << endl;
cout << ansp << endl;
}
Сложность: O(nlogn).
Задачу предложил Resul Hangeldiyev Resul.
Решение задачи легко получить из второго примера. Легко видеть, что если расставить все нечётные числа в виде ромба посередине квадрата, то мы получим магический квадрат.
Решение на C++int n;
bool read() {
return !!(cin >> n);
}
const int N = 101;
int a[N][N];
void solve() {
memset(a, 0, sizeof(a));
forn(i, n / 2) {
int len = n / 2 - i;
forn(j, len) {
int x1 = i, x2 = n - 1 - i;
int y1 = j, y2 = n - 1 - j;
a[x1][y1] = 1;
a[x1][y2] = 1;
a[x2][y1] = 1;
a[x2][y2] = 1;
}
}
int odd = 1, even = 2;
forn(i, n)
forn(j, n)
if (a[i][j]) a[i][j] = even, even += 2;
else a[i][j] = odd, odd += 2;
forn(i, n) {
forn(j, n) {
if (j) putchar(' ');
printf("%d", a[i][j]);
}
puts("");
}
}
Сложность: O(n2).
Эту задачу я уже давно хотел дать на раунд, она мне казалась очень стандартной, но я недооценил её сложность.
Запишем уравнение, которое описывает все решения задачи: a1k + b1 = a2l + b2 → a1k - a2l = b2 - b1. Имеем линейное диофантово уравнение с двумя неизвестными: Ax + By = C, A = a1, B = - a2, C = b2 - b1. Его решение имеет вид: 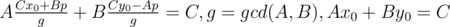 , где последнее уравнение решается с помощью расширенного алгоритма Евклида, а p произвольное целое число. Далее нам нужно удовлетворить двум условиям:
, где последнее уравнение решается с помощью расширенного алгоритма Евклида, а p произвольное целое число. Далее нам нужно удовлетворить двум условиям: 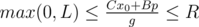 и
и 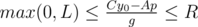 . Поскольку мы знаем знаки чисел A и B, последние уравнения задают отрезок возможных значений для переменной p, длина этого отрезка и является ответом на задачу.
. Поскольку мы знаем знаки чисел A и B, последние уравнения задают отрезок возможных значений для переменной p, длина этого отрезка и является ответом на задачу.
Решение на C++li a1, b1, a2, b2, l, r;
bool read() {
return !!(cin >> a1 >> b1 >> a2 >> b2 >> l >> r);
}
li _ceil(li, li);
li _floor(li a, li b) { return b < 0 ? _floor(-a, -b) : a < 0 ? -_ceil(-a, b) : a / b; }
li _ceil(li a, li b) { return b < 0 ? _ceil(-a, -b) : a < 0 ? -_floor(-a, b) : (a + b - 1) / b; }
li gcd(li a, li b, li& x, li& y) {
if (!a) {
x = 0, y = 1;
return b;
}
li xx, yy, g = gcd(b % a, a, xx, yy);
x = yy - b / a * xx;
y = xx;
return g;
}
void solve() {
l = max(0ll, _ceil(l - b1, a1));
r = _floor(r - b1, a1);
if (l > r) {
puts("0");
return;
}
li A = a1, B = -a2, C = b2 - b1;
li x0, y0;
li g = gcd(A, B, x0, y0);
if (C % g) {
puts("0");
return;
}
if (g < 0) {
g = -g;
x0 = -x0;
y0 = -y0;
}
li L = _ceil(r * g - x0 * C, B);
li R = _floor(l * g - x0 * C, B);
R = min(R, _floor(y0 * C, A));
li ans = max(0ll, R - L + 1);
cout << ans << endl;
}
Сложность: O(log(max(a1, a2))).
Задачу предложил Zi Song Yeoh zscoder.
У этой задачи есть простое решение, которое участники описали в комментариях. Моё решение несколько сложнее. Будем решать задачу с помощью динамического программирования. zn — наименьшее время, необходимое для получения n букв 'a'. Теперь рассмотрим переходы: переходы на дописывание одной буквы 'a' будем обрабатывать как обычно. Переходы на умножения на два и вычитание единицы будем обрабатыват одновременно: будем считать, что сразу после умножения числа i на двойку мы сразу сделаем i вычитаний и далее будем проталкивать от нашего числа вперёд такие обновления. Легко видеть, что такие обновления никогда не никогда не вкладываются, поэтому их можно хранить в очереди, дописывая очередное обновление в конец очереди, и, забирая лучшее обновление с начала очереди. Решение достаточно сложное на объяснение, но очень короткое, поэтому лучше посмотреть код :-)
Решение на C++int n;
li x, y;
bool read() {
return !!(cin >> n >> x >> y);
}
const int N = 20 * 1000 * 1000 + 13;
li z[N];
void solve() {
forn(i, N) z[i] = LLONG_MAX;
list<pair<li, int>> q;
z[0] = 0;
forn(i, n + 1) {
while (!q.empty() && q.front().y < i) q.pop_front();
if (!q.empty()) z[i] = min(z[i], q.front().x - i * x);
assert(z[i] != LLONG_MAX);
pair<li, int> cur(z[i] + y + 2 * i * x, 2 * i);
while (!q.empty() && q.back().x > cur.x) q.pop_back();
q.pb(cur);
z[i + 1] = min(z[i + 1], z[i] + x);
}
cout << z[n] << endl;
}
Сложность: O(n).
Задачу предложил Александр Кульков adamant.
Сначала научимся избавляться от запросов на удаление. В силу условия, что никакая строка не добавляется дважды (и, соответственно, не удаляется) нам достаточно посчитать ответ для всех добавленных строк (как будто они не удалялись) и вычесть из него ответ для уже удалённых. Таким образом, можно считать, что строки только добавляются.
Далее воспользуемся алгоритмом Ахо-Корасик. Единственная проблема, заключается в том, что алгоритм строит правильные суффиксные ссылки только после того как все строки добавлены. Чтобы решить эту проблему заметим, что ответ для набора строк равен ответу для некоторой части этого набора плюс ответ для оставшейся части. Далее воспользуемся стандартным приёмом превращения статической структуры данных (Ахо-Корасик в данном случае) в динамическую.
Пусть в данный момент в набор добавлено n строк, тогда мы будем хранить не более logn наборов строк размера разных степеней двойки. Добавим строку в набор размера нулевой степени двойки и далее перебрасывать наборы к большим степеням двойки, пока не получим инвариантный набор множеств.
Легко видеть, что каждая строка перебросится не более logm раз и на каждый запрос мы умеем отвечать за O(logm).
Решение на C++const int N = 4 * 300300, A = 26, LOGN = 20;
struct node {
char c;
int parent, link, output;
int next[A], automata[A];
int cnt;
node(char c = -1, int parent = -1, int link = -1, int output = -1, int cnt = -1):
c(c), parent(parent), link(link), output(output), cnt(cnt) {
memset(next, -1, sizeof(next));
memset(automata, -1, sizeof(automata));
}
};
node t[N];
vector<int> ids;
inline int get_idx() {
assert(!ids.empty());
int ans = ids.back();
ids.pop_back();
t[ans] = node();
return ans;
}
inline void return_idx(int idx) {
ids.pb(idx);
}
inline int add(const string& s, int root) {
int v = root;
forn(i, sz(s)) {
if (t[v].next[s[i] - 'a'] == -1) {
int idx = get_idx();
t[v].next[s[i] - 'a'] = idx;
t[idx] = node(s[i], v, -1, -1);
}
v = t[v].next[s[i] - 'a'];
}
t[v].output = v;
return v;
}
int link(int v, int root) {
int& ans = t[v].link;
if (ans != -1) return ans;
if (v == root || t[v].parent == root) return ans = root;
char c = t[v].c;
int vv = link(t[v].parent, root);
while (vv != root && t[vv].next[c - 'a'] == -1)
vv = link(vv, root);
return ans = (t[vv].next[c - 'a'] == -1? root: t[vv].next[c - 'a']);
}
int output(int v, int root) {
int& ans = t[v].output;
if (ans != -1) return ans;
return ans = (v == root? root: output(link(v, root), root));
}
int cnt(int v, int root) {
int& ans = t[v].cnt;
if (ans != -1) return ans;
v = output(v, root);
if (v == root) return ans = 0;
return ans = 1 + cnt(link(v, root), root);
}
int next(int v, char c, int root) {
int& ans = t[v].automata[c - 'a'];
if (ans != -1) return ans;
if (t[v].next[c - 'a'] != -1)
return ans = t[v].next[c - 'a'];
return ans = (v == root? root: next(link(v, root), c, root));
}
void dfs_clear(int v) {
forn(i, A) if (t[v].next[i] != -1) dfs_clear(t[v].next[i]);
return_idx(v);
}
string a[N];
int build(int root, const vector<int>& ids) {
dfs_clear(root);
root = get_idx();
forn(i, sz(ids)) add(a[ids[i]], root);
return root;
}
int calc(int root, int idx) {
int ans = 0;
const string& s = a[idx];
int v = root;
forn(i, sz(s)) {
v = next(v, s[i], root);
ans += cnt(v, root);
}
return ans;
}
int m;
bool read() {
return !!(cin >> m);
}
struct blocks {
int root[LOGN];
vector<int> block[LOGN];
void clear() {
forn(i, LOGN) {
block[i].clear();
root[i] = get_idx();
}
}
void insert(int i) {
vector<int> cur(1, i);
forn(i, LOGN)
if (sz(block[i]) == sz(cur)) {
cur.insert(cur.end(), all(block[i]));
block[i].clear();
root[i] = build(root[i], block[i]);
} else {
block[i] = cur;
root[i] = build(root[i], block[i]);
break;
}
}
li calc2(int idx) {
li ans = 0;
forn(i, LOGN) {
ans += calc(root[i], idx);
}
return ans;
}
};
char buf[N];
blocks z1, z2;
void solve() {
ids.clear();
nfor(i, N) ids.pb(i);
z1.clear();
z2.clear();
forn(i, m) {
int type;
assert(scanf("%d%s", &type, buf) == 2);
a[i] = buf;
if (type == 1) {
z1.insert(i);
} else if (type == 2) {
z2.insert(i);
} else if (type == 3) {
li ans = z1.calc2(i) - z2.calc2(i);
printf("%lld\n", ans);
fflush(stdout);
} else throw;
}
}
Сложность: O((slen + m)logm), где slen — суммарная длина всех строк во входном файле.






