


td,dr: A 1100, B1 1300, B2 1800, C1 2000, C2 2300, D1 2200, D2 2700. You needed a 2300 rating to have more than 50% prob of winning a t-shirt and advancing to round 3.
GCJ round 2 took place last weekend. Congratulation to everyone who won the t-shirt and advanced to round 3.
I provide below my estimate of the difficulty of the problems. This is a bit late, and I skipped round 1B and 1C, but I will do a summary of round 1 to catch up.
The data and methods are the same I described in my previous posts, see qualification round and round 1A.
Your feedback is very valuable to increase the quality of the estimates and is very appreciated.
Method 1: The 50% Bucket
Approach and Data
Please see my previous post for an explanation.
Out of around 4'500 participants of GCJ 2, about 2'900 had a CF namesake.
I decided to exclude from the estimate roughly 30 participants with rating below 1000. If you made it this far, your rating doesn't really reflect your ability, so your performance is not a good indicator of the difficulty of the problems.
I also grouped the other participants below 1300 in a single bucket, since there aren't many left.
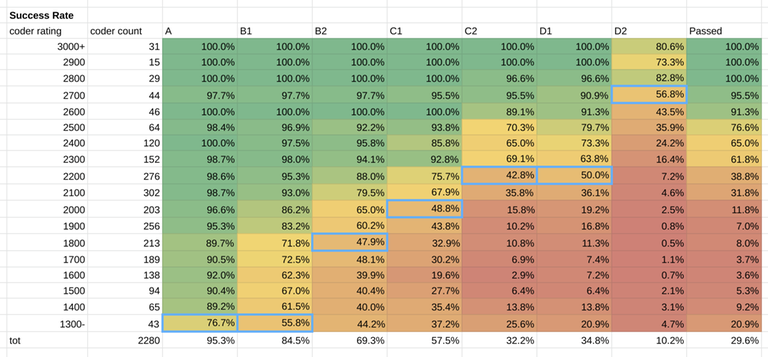
Results
This is the estimate: A 1300, B1 1300, B2 1800, C1 2000, C2 2200, D1 2200, D2 2700.
I think this approach gives reasonable results for most problems, with the exceptions of A and B1. Those two were easy for the majority of the contestants, so this method just places them at the lowest bucket available.
Method 2: Inverse Prob Function
Approach and Data
Again, please see my previous post for more details.
In this round, the average contestant rating was 2020. I tried to imply the difficulty of the problem given the success rate of the contestants close to the average ability ($$$2000 \pm 100$$$ rating), and the results... well, did not improve the estimate by much.
Results based on average contestant's performance
A 1397, B1 1655, B2 1860, C1 1967, C2 2222, D1 2190, D2 2619.
As observed for previous rounds, the approach of inverting the prob function doesn't work well for problems very easy or very difficult for the contestant. For example, the difficulty of B1 is clearly inflated with this approach, and we weren't able to place A at a reasonable level below the 1300 bucket.
Given that the previous buckets method already gives decent results for most problems, can we really learn anything more about the difficulty of the problem using this approach?
I think so. For the easiest and hardest problems, the buckets don't work well. There are not enough contestants around 1000-rating to make enough buckets to estimate the difficulty of problem A. But we can estimate the difficulty of A and B1 based on the performance of the lowest-rated participants. For the hardest problems the buckets seem to work fine so far, but maybe in the coming rounds there will be a similar issue for them.
Adjustments to easy problems based on low rated contestant performance
There are roughly 200 contestants with rating <= 1500. Based on their performance:
A 1,068, B1 1,309.
Much more reasonable.
My Estimate
I put together the two estimates above, and I get this:
A 1100, B1 1300, B2 1800, C1 2000, C2 2300, D1 2200, D2 2700.
What rating did you need to be to pass the round and win a t-shirt? 39% of coders rated 2200 qualified for Round 3. The percentage increases to 62% for 2300 rated participants. You needed to be a Master/close to International Master to have a significant chance to pass. In the table above, right-most column, you can see more details.
What do you think?


