


Round statistics sample
Values meaning

Sent — participants count, who made at least one problem submission
Pretest — participants count, who's solution stuck on pretests
Hacked — participants count, who's solution was hacked, and didn't pass hack sample
Systest — participants count, who's solution stuck on system tests
Accepted — participants count, who solved the problem
Attempts — attempts count for the problem
Success % — Accepted count / Attempts count
Severity — average attempts count among participants, who solved the problem
Median Score — median score value for solved problem
Hacks — successful(+) and unsuccessful(-) hacking attempts count (invalid tests and compilation errors are ignored)
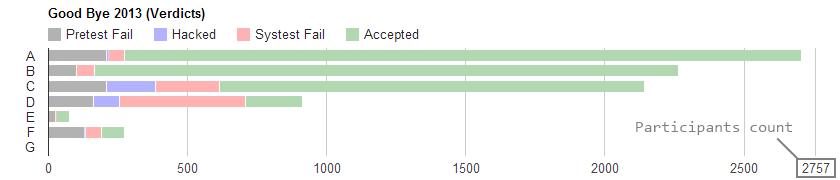
Graphic representation of Pretest / Hacked / Systest / Accepted columns.
Right-most value — participants count.
Used stuff
Standing pages parsing: Google Chrome + javascript.
Tables and graphs drawing: Google Charts.
Manual actions: Paint.NET + Notepad++ :)







I think i have a good statistics to add yours.
Let N be the number of participants that took part in a contest in question. Let Ri be the rating of ith-placed user before the change of rating. And let WRi be the world rating of the i-th contestant (numbered according to world rating). So WR1 is 3141 :D (tourist's current rating).
The idea is to estimate how well (in some sense, i'll explain) do contestants (that took part in the recent contest) represent all the contestants on codeforces. A selection is good representative of users on website if concentration of the levels of users is uniform, that is to say, for example there isn't excessive number of red users nor purple users are too many.
The formula would be something like this (for div1):
fraction = (number_of_div1_users) / N;
sum = 0;
for i = 1 to N:
sum += Ri — WR(i * fraction)
print sum :D
Well, for sure, some kind of deviation would be more accurate : ]