


Hello!
As a part of preparation for ACM-ICPC 2014 World Finals our team NU 1 prepared (and continues preparing) Algos — collection of some useful algorithms. Today we decided to share it with Codeforces community.
For the ease of use of Algos, all algorithms (with very rare exceptions) can be compiled and executed as is. Moreover, in order to verify the correctness of code and to help understanding the purpose of algorithm, the source code of every algorithm is based on some reference problem (on which the link is provided). Short description and time complexity are also available for every algorithm.
Algos is originally based on the repository on Github. You are very welcome to fork and contribute!
Requests, bug-reports and just feedback are welcome in the comments :)
Which other algorithms you would like to see there?







I wonder if it wouldn't be more useful in paper form. After all, since you can't use it during a competition as is, you'd still need to rewrite it, and what you want is being able to write it quickly.
By "paper form" do you mean pure algorithm functions/structures, without main function, includes, etc? You are right, it would also be useful, and it is widely done elsewhere, for example on e-maxx.ru and other sites with algorithms.
But the initial idea of this collection was that one can easily run any code, see what it does, what output produces, and be able to test/submit it on reference problem.
And to find the best compromise between these two extremes I always tried to find reference problem which just states "use this algorithm", so there wouldn't be much code on input/output/things specific to the problem, and you would be able to find and copy needed parts quickly.
By paper form, I mean a printed paper with the algorithm :D
Just because you mention it being as part of preparations for ACM, where being used to online tools can be an inconvenience.
Then I don't see any problem at all :)
You can always print these codes. This is how we have done our ACM World Finals team reference — document with algorithms, which you can take with you on the contest. And during trainings we honestly retyped code from this collection when we needed it, so we didn't get used to copy-paste.
Good for you, then.
Thank you for sharing this.
In Aho-Corasick code, function
trieInsert:for (int i = 0; i < strlen(s) ; i++)With
i < strlen(s), insertion takesO(|s|^2), right?Yeah, it is. One of the best reasons why C-strings shouldn't be used beyond reading the input.
What?! Is there a problem to store a variable which value is the length of the string?
No, but strlen() tends to lead people not to do that. And it's kind of annoying, having to manually modify that variable everytime the string's length changes, and maybe fail a problem because of that. With C++ strings, you already have
.length(), which works in O(1), so it requires no additional work.Unfortunately,
std::stringprovokes you to use concatenation and other slow operations. And even if you don't use it, it's still very slow in its basic usage comparing to pure C, would you mind taking a look? What's very strange, if you passstringas constant, it works much better, do you have an idea why? Anyway, writing consts everywhere in competitive programming is rather annoying.http://ideone.com/hYKu4J
Now
calc1<const char*>andcalc2<const string&>have the same runtime.for(int i=0; s[i] ; ++i)is slower thani < lenandi < s.length()Maybe because s[i] can't be predicted?
I don't :D
These subtle differences are beyond me. I tried small variations of this, but all it actually gave me is slightly varying runtimes (in around 0.2 s' range for classic std::string, so it's roughly 2x slower than with const).
It's true that C++ strings have a worse constant, but that hasn't ever been a very big deal for me — whenever using member functions caused me TLE, it was always due to a horrible factor to the complexity brought about for example by comparing the whole substring instead of what I actually needed to compare, not the constant factor (as far as I remember, at least). And when I write a solution that doesn't completely obviously pass if the complexity's good, then I try to pay attention to what could possibly make it TLE — like avoiding reallocations, modulos or functions that could be too slow. And sometimes, even that fails (damn, deque reallocates as well :D), but I don't remember a case where the problem would be caused by using a C++ variant instead of the C one.
On the other hand, there's someone asking why his code got TLE with the answer being strlen() making it quadratic or something similar.
Just to give example when C strings are much faster than std::string and allow to fit solution into TLE. These two submissions differ only in string type, and have different verdicts (TLE and Accepted): 6913322 6910557. Actually this is why I used C strings in Aho-Corasick.
Sorry, the problem on which these submissions are based has statement in Russian. It gives you several (<= 1000, with lengths <= 80) strings, and then gives you string queries (lengths <= 250) , for each of which you have to say if it contains any of original strings. Max input size is 1 MB.
Thanks for pointing this out. I usually don't use C strings, so didn't pay enough attention to this line. Fixed now.
This year we were also lucky to qualify for the Wold Finals, so the work is going on :)
The number of algorithms in Algos reached 50.
Any ideas what to add next?
It would be very nice if this algos would be wrapped up in classes, so that you can simply use them without caring about variable shadowing or collisions. Like, for example:
Yes, I though of it myself. It would be pretty nice in some cases.
The question is how to deal with large arrays in classes in C++. Having them global will make class useless, using vectors will cause some time overhead and mallocs are just not so convinient (also vectors and mallocs mess up the code, in my opinion).
Usually when you solve a problem, you know what algo you know in advance, and you rarely use more than one at a time, so I decided to leave it in this form (and it is pretty useful now for me).
Maybe any ideas how to add some object-orientedness without pain?
+classes, -vectors, -mallocs
I don't think dynamically allocated arrays will be faster then vector which you don't actually resize (just create from n).
probably yes, because of heap allocation. If I understood correctly ADJA don't like typing
sort(v.begin(),v.end());instead ofsort(v,v+n);— and that's the pointOK, if that was the point then I agree.
I have a question about dinic algorithm from your collection. There is a comment: "MaxFlow Dinic algorithm with scaling. ~ O(NMlogN)" This code looks very similar to the one described here : http://e-maxx.ru/algo/dinic where there is a complexity O(n^2 m). It's written next to the first algorithm, but the second one is almost the same. Unfortunately, I don't understand russian at all to be completely sure. Could you write what improvement you've made to reduce complexity ?
Thanks for the question. The algorithm here is basically really the same as in e-maxx.ru, and works in O(n^2 * m) in general.
The improvement over it used in the collection is scaling. You can see it in the line #107 in the code. What it does: it not simply tries to push any flow from the source to the sink, but tries to push some big flow from the start (1 << 30) then decreasing the flow only when it fails (divides flow by 2). In practice, this improves the speed of an algorithm quite well.
Though, I don't know any strict complexity of this improvement (or maybe complexity stays the same?) I wrote ~ O(NMlogN) as it what it seems to work like, but I maybe very wrong in this.
Does anybody knows more? This would be really helpful.
It is actually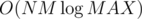 . To prove it you should combine proof for scailing flow(
. To prove it you should combine proof for scailing flow(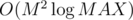 ) with Dinic. There is
) with Dinic. There is 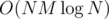 version of Dinic, but it requires link-cut trees)
version of Dinic, but it requires link-cut trees)
Thanks.
Actually it turns out that in the algorithm list I already correctly wrote O(NMlog|F|) and there was a mistake in the repository.
O(NMlog|F|) really seems decent, in analogy to any other scaling flow.
Actually MAX is not |F|, it is maximum edge capacity)
Oh, well..
Thanks, I didn't know that.
For interested like me: this article on topcoder nicely describes this (and there is a reference list at the end).
Nice...
But it was better to put some text with the codes too ,for better learning
Can you add a sqrt-decomposition theme to github?