


Hey, CF community!
I have a newbie question about the square-root decomposition method on arrays. You probably know the trick — assume we have to do a sequence of queries on the array of size n. We divide it into pieces of size 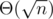 . Then when any query (do something on interval) comes up, there are
. Then when any query (do something on interval) comes up, there are  pieces covered by the interval (which we can somehow process quickly) and elements outside these pieces (which we can brute-force). Thus we arrive into something like or
pieces covered by the interval (which we can somehow process quickly) and elements outside these pieces (which we can brute-force). Thus we arrive into something like or 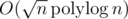 per query.
per query.
Now my question comes — many people here name such a technique; its name is Mo's algorithm. However, my searches in Google and arXiv gave no information on the origins of the name. However, it seems to be widely used on Codeforces and we-love-algorithms-blogs. I'm quite interested in:
- Who was the first to use this name for the technique? When was it?
- Which Mo (I guess many of them contribute to computer science, at least arXiv says so) does the name refer to?
Thanks in advance for your answers.
A funny sidenote: I had also another question in my mind before — it was about BITs (binary indexed trees). I thought that it must be connected with bit manipulations. It got really weird when people kept discussing about Fenwick trees there. I was explaining to myself that we use bit operations to move in the tree more efficiently. It took me like a year to realize how stupid I had been... :D







I expect this to be some weird local meme. Possibly, someone called "Mo" once used the trick in a local contest, and the name stuck and later got popular. I have never encountered the name "Mo's algorithm" outside of competitive programming.
I also think it's misleading because people tend to use that name for anything where the sqrt decomposition is used. Personally, I wouldn't use the name for anything (except, maybe, for the one specific algorithm published by some Mo, if it even exists). Calling the technique "square root decomposition" or something similar makes way more sense.
I think calling it "square root decomposition on queries" is a better choice, since not specifying it implies that decomposition happens on the array itself. (Of course, we store queries on another array but I mean the main array.)
What you describe sounds nothing like Mo's algorithm to me. It's a very clever application of square root decomposition that uses some sort of structure capable of adding/removing values quickly to process offline queries.
To people like misof it may not hold much value to name it separately, but for the rest of us mortals I think it's very useful to learn it separately as this application of sqrt decomp is not obvious (at least to me).
To me, this square root decomposition is essentially a "poor man's version" of a static binary tree (interval tree / tournament tree / pick the name you prefer), it's just that instead of vertex degree 2 and depth O(log n) you have vertex degree sqrt(n) and depth 2. The part about depth being specifically 2 makes the implementation easier because the propagation of information up and down the tree is trivial.
I do agree that this is a useful technique worth knowing. I'm not saying it doesn't deserve a separate name, I'm only saying I would not call it "Mo's algorithm" -- which is because currently I would not call anything Mo's algorithm.
Also, your post actually kind of makes my other point: different people use the name "Mo's algorithm" for different things / different levels of abstraction, which makes it even more confusing at times. What is the other thing you know under the name "Mo's algorithm"?
It's pretty simple to keep median of an array online using sets. Now suppose you have an array and I ask you to give median of every interval (L, R) of this array in a set of queries.
If you reorder the queries by (L/sqrt, R), you can use the online set approach to move the borders of the current interval you're considering to answer each query in amortized sqrt n log n time.
This query reordering trick is what people refer to as Mo's algorithm, though I have no idea why.
Oh, so it turned out that I really didn't know much about this method (I'm still avoiding the word algorithm, because the trick seems to be applicable to many other problems; isn't Mo's trick a more suitable phrase?). Now I understand a bit why people wanted to assign it a separate name.
Besides — a great technique! (I have seen it used maybe once in my life before, of course without being told its name, and I instantly fell in love with it!)
Exactly. What I've seen called Mo's algorithm is a technique to, given q = O(n) queries on an interval of length n, sort them and process them offline so that the total number of insertions/removals of an element in some data structure (say the previous query was about the interval [1, 4] and the next one is about [3, 5]; then we need to remove elements 1 and 2 and add 5) is O(n3 / 2). Also no idea about a citation — maybe the Chinese coders can come up with one :)
I think this is exactly what I'm referring to.
Yes, this is the real Mo's algorithm. And Mo's algorithm is a very good compact name for the technique.
The technique, or the term "Mo's Algorithm" ("莫隊算法" in Chinese) was originally thought of and popularized by 莫涛 (Mo Tao) and his teammates.
It was first used to tackle a problem from 2009 China IOI Camp: 小Z的袜子(hose) — authored by 莫涛 himself.
The problem was: given a sequence of integers, for any given interval, calculate the probability of choosing any 2 numbers and the 2 numbers are equal.
The technique itself certainly wasn't new. A Chinese PhD student studying in NYU surveyed this technique a while back. "Rectilinear Steiner Minimal Arborescence technique" mentioned in this paper — Carmel Kent, Gad M. Landau, Michal Ziv-Ukelson, On the Complexity of Sparse Exon Assembly (2005) seems to be identical to Mo's Algorithm. There could be earlier sources.
In case you're curious,
Here is an interesting discussion (in Chinese sadly) on what algorithms/data structures was truly invented by Chinese sport programmers.
Of course myself I do not know any of these :P
Is that Myth5?
I prefer "Mo's technique" to some "rectilinear arborescence". It probably should be named after the first inventor, but it might be extremely time-consuming to search the literature for the very first instance of this idea, given that it can be reinvented independently in a matter of a few days of thought. (But so can Prim's algorithm, no? Still, it's named after Prim, rather than e.g. Jarník.) It's no good to keep renaming an algorithm every time we discover an earlier publication about it. A good compromise might be to give the colloquial name and cite the earliest publication known so far.
thanks for you helping