


Writer: Atef
In this problem it was required to find next palindrome on a digital clock. Since the lowest unit of time used 1 minute, and there are only 24 * 60 minutes in a day, one could simply go through each minute starting from the time given in the input plus 1 minute, until finding a palindrome. If no palindrome is found till the end of the day 23: 59, the output should then be 00: 00.
Datatypes
Writer: Atef
Let us call a pair of datatypes (a, b), where a < b, BAD if and only if there exists a number x where x fits in a bits but x * x does not fit in b bits. The following observation helps in finding a solution to the problem. The best candidate for the number x is the largest number fitting in a bits, which is x = 2a - 1. So for each ai it is enough to check that the smallest aj > ai has enough bits to contain x * x = (2a - 1) * (2a - 1), which has at most 2 * a bits. Sorting the numbers first was needed to traverse the list of datatypes once and ensuring the condition above.
Dorm Water Supply
Writer: Atef
The problem describes a graph of houses as nodes and one-way pipes as edges. The problem states that the graph will contain 1 or more chains of nodes. The required is to find the start and end of every chain (consisting of more than 1 node, which caused many hacks). The other requirement was to find the weakest edge in each of the chains. This can be done by traversing (using Depth-First Search (DFS) for example) the graph from each un-visited node with no incoming edges. These nodes are the start of a chain. By keeping track of the minimum diameter so far, whenever the DFS reaches a node with no outgoing edges, it means that this node is the end of the current chain. After storing, in a list or vector, the tuples (start, end, minimum diameter), we sort these tuples by start index and print.
Writer: Atef
This problem is asking for the probability. Consider two sets of teams: the set of teams where Herr Wafa is the only student from his major and the set where at least one other student from Herr Wafa's major is present. These two sets don't intersect, so once we can compute the number of teams in the first set, A, and the number of teams in the second set, B, the answer would be B / (A + B).
The number of teams in the first set is A = 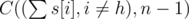 . We subtract one as Herr Wafa is guaranteed the spot, and the other (n - 1) spots are to be taken by the remaining
. We subtract one as Herr Wafa is guaranteed the spot, and the other (n - 1) spots are to be taken by the remaining 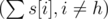 students.
students.
. We subtract one as Herr Wafa is guaranteed the spot, and the other (n - 1) spots are to be taken by the remaining students.Now let's count the number of teams having exactly k students from Herr Wafa's major apart from him. This number would be 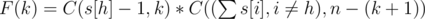 . Much like for the first set, (n - (k + 1)) students from the other majors should he selected, and none of them should be from Herr Wafa's major. The total number of teams where at least one other student is from Herr Wafa's major is therefore
. Much like for the first set, (n - (k + 1)) students from the other majors should he selected, and none of them should be from Herr Wafa's major. The total number of teams where at least one other student is from Herr Wafa's major is therefore 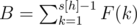 .
.
. Much like for the first set, (n - (k + 1)) students from the other majors should he selected, and none of them should be from Herr Wafa's major. The total number of teams where at least one other student is from Herr Wafa's major is therefore .The statements above describe the mathematical solution. It can be implemented in various ways.
Writer: Atef
At the first glance the upper limit for n being 1018 looks huge. But in fact, combined with the fact, that the answer should be output modulo 12345, it's should not scare you but rather hint that the problem has a DP approach.
Like all DP problems the way to approach it is to split the problem into sub-problems and figure out what extra information should be carried between the sub-problems in order to combine them into the solution to the whole problem.
Say, n is 11 and we solved the problem for the first 10 crimes. Clearly, just the number of ways to commit the first 10 crimes is not enough to solve the full problem with n = 11. The extra information to be carried along with the number of ways to commit n crimes and be innocent is the following: the number of ways to commit the first n crimes and have remaining multiplicities d1, d2, ...d26 respectively. The fact that the product of the multiplicities does not exceed 123 makes this a solvable task, as the set of all possible remainders contains not more elements than the product of multiplicities.
To illustrate the idea from the first paragraph consider the first example case. It has two constraints, A with multiplicity 1 and B with multiplicity 2. The remainder of the number of crimes of type A is always zero, and committing crimes of type A may not yield any punishment. The remainder of the number of crimes of type B is zero or one. Therefore, while solving the sub-problems for the first n2 < = n crimes, it's enough to keep track of only two numbers: "number of ways to commit n2 crimes and be completely innocent" and "number of ways to commit n2 crimes and have committed one 'extra' crime of type B".
The key step to solve the problem now is to notice that each transition from the solution for the first k crimes to the solution for the first (k + 1) crimes can be seen as multiplying the vector of the current state by the transition matrix. Once all possible transitions are converted to the matrix form, the problem can be solved by raising the matrix into n-th power. Raising the matrix into large power can be done efficiently using matrix exponentiation: on some steps instead of computing Ai + 1 = Ai· A0 one can compute A2i = Ai· Ai.
The last trick of this problem is to deal with multiple allowed multiplicities. If they were not allowed, the remainders per each crime type could have been kept with the modulo being equal to the multiplicity for this crime type. Moreover, if no crime type is listed more than once, the only valid final state is the state where the remainders are zero across all the crime types.
With multiple allowed multiplicities, for each crime type the remainder modulo the product of the multiplicities of crimes for this type should be kept. (Strictly speaking, LCM is enough, but the constraints allow to use the plain product instead). Then, at the stage of printing the output, instead of treating the counter for the state with zero remainders as the only contributor to the output, one would have to iterate through all possible states and verify if each set of remainders conducts a valid final state.
Arrangement
Writer: Atef
The problem asks for finding the lexicographically n-th permutation satisfying the input constraints.
The trick which confused many contestants, as well as a few authors and testers, is that instead of having the restrictions formulated in a way position[a[i]] < position[b[i]] the restrictions were element at position[a[i]] < element at position[b[i]].
As in most problems where one has to output lexicographically n-th answer, the idea which can result in the solution which is passing the systests is to learn how to compute the number of solutions satisfying certain constraints.
We will speak about how to compute the number of solutions in a bit, but first let's understand how having such function would lead to a solution. The very first observation is: if the total number of possible solutions is less than y - 2000, then the answer is "The times have changed". Once we have ensured that the solution exists it can be found using some of search.
A simple approach would be the following: fix the first element of the resulting permutation to be 1 and count the number of possible solutions. If we do have enough to reach year y, then the first element must be 1, because there exists enough permutations with the first element being 1 to cover the years up to y, and any permutation where the first element is not 1 comes after any permutation where the first element is 1 in lexicographical order.
And if fixing the first element to be 1 is not giving enough permutations, then we should decrease the "desired" year by the number of solutions with 1 being fixed as the first element and start looking for the solutions with 2 as the first element. The intuition is that there are not enough solutions with 1 being the first element, but once we acknowledge that and start looking for the other solutions --- with 2 as the first element, we are speaking not about arrangements for years 2001 and onwards but about the years 2001 + number of solutions with first element being one and onwards. Therefore instead of looking for the permutation with index y - 2001 with the first element being 1 we are looking for the permutation with the lower index, y - 2001 - number of solutions with first element being one, with the first element being 2 or higher.
This process should be continued until all the elements are identified. Once the first index is fixed the known prefix would become a two-numbers prefix, and it will grow until all the permutation is constructed.
Now to complete the solution we need to be able to compute the number of permutations which satisfy two restrictions: the input constraints and the added "permutation has prefix P" constraint. This problem can be solved using DP.
For a given prefix P of length m, (n-m) other elements should be placed.
Assume first that we are going to be iterating over all possible permutations with the given prefix using the brute force, but, instead of trying each possible value for the element at the next empty position i, we would be trying each possible position for the next not-yet-placed element i. This approach would work, but in O((n - m)!) time, which is obviously unfeasible. We need to find some way to reduce the state space and make it run faster.
The key observation is the following: the state of the partially solved problem can be completely described by the bitmask of the currently occupied positions. This statement is nontrivial, as, from the first glance, it seems that apart from the unused positions mask, the information about the order, in which the already-placed elements are placed, is important. However it's not. Recall that all the constraints have the form of "element at position ai is less than the element at position bi". Provided the elements are placed in increasing order, in order to satisfy each constraint it's enough to confirm that, if the element to be placed is being put into position i, there is no such constraint in the input, that the element at position i should be less than the element at position j, while the element at position j has already been placed.
This approach results in the DP with 2n - m states. Note that the next element to be placed can always be determined by the number of bits set in the mask and the prefix elements.
The implementation of the above algorithm requires nontrivial coding, as the elements, belonging to the prefix, have to be treated differently compared to the elements which were placed by the DP. This is because the DP is enforcing that the elements are always added in the increasing order, which does not have to be the case for the elements conducting the prefix.
Darts
Writer: Dima
Before doing the coding let's do some math. The answer to this problem can be computed as the total area of all input rectangles / the area of the union of all input rectangles.
One of the easy ways to understand it is the following. First notice that if all the rectangles are the same, the answer is always the number of rectangles. Now forget that the input figures are rectangles, assume any shape is allowed, and then try to construct the example case given the union area s and the resulting expected score e. Notice that you can start with any shape constructed of non-intersecting figures with the total area s, and then add more figures on top of these, such that the contour of the union is the same as the contour of the first original figure of area s. Specifically, you'd need to add some figures of the total sum of t = s· (e - 1), but the number doesn't matter here. The key is that the placement of these added figures doesn't change the result, and therefore the answer will always depend only on the total area of the input figures and the area of their union.
Now back to the rectangles. Computing the sum of the ares of the rectangles is easy. The hard part is to compute the area of their union in better than O(n3). Note that the union may have multiple disjoins components, it does not have to be convex, it may have holes and, in short, does not have to be easy to describe.
One of the relatively-easy-to-implement solutions is the following. We will be computing the are of the union of the rectangles using the trapezoid method. Note that for the trapezoid method the order, in which the segments of the figure are provided, doesn't matter. Therefore, in order to use the trapezoid method, we "only" need to find all non-vertical directed segments which are the part of the contour of the union.
Let me elaborate a bit more on the previous paragraph. We don't need vertical segments, because their contribution to the resulting area is zero in the trapezoid method of computing the area. The direction of the segment is the important part though. It's not enough to know that the segment (x1, x2) - (y1, y2) belongs to the contour of the union. It's important to know whether the area of the union if the part of the plane above it or below it.
Imagine the test case where the union of all the rectangles is a big rectangle with a hole inside it. In this case we need to know that the segments, describing the outer part of the union, should contribute to the area with the "plus" sign, while the segments describing the inner hole should be considered with the "minus" sign.
Specifically, for the trapezoid method, the sign of x2 - x1 would be describing the direction of this segment: for example, if x1 < x2 than the segment is "positive" and if x1 < x2 it's "negative".
To find all such segments let's consider all distinct non-vertical lines. There are at most 4n such lines in the input. Each segment of the final contour of the union should lay on one of those lines, so it's enough to focus on the lines only, consider them independently from each other (but make sure to process each distinct line only once!) and for each line construct a set of the positive and negative segments.
Let's formulate the rules under which a part of the line would be a positive or negative segment. They turn out to be very simple:
1) If some segment (x1, y1) - (x2, y2) is part of the border of one of the input rectangles, then it's a "positive" segment if this input rectangle lays below this segment and a "negative" segment if this rectangle lays above this segment.
2) If some segment (x1, y1) - (x2, y2) belongs to the intersection of the borders of two different input rectangles, with one being a "positive" one and one being a "negative" one, then this segment does not belong to the contour.
3) If some segment (x1, y1) - (x2, y2) is being covered by another rectangle, then it does not belong to the contour. "Covered" means laying completely inside some other rectangle, the border cases are covered above.
The easy way of constructing all the segments could look as the following pseudo-code:
for each distinct non-vertical line
create the array of markers. the marker holds the x coordinate and one of four events: { start union area below, end union area below, start union area above, end union area above }.
iterate through all the input rectangles
if this rectangle has one segment laying on the line under consideration
add two markers: one for start and one for end. whether the markers are above or below is determined by the position of this rectangle with respect to this line
else if this rectangle intersects this line
find the intersection points and add four markers: { start area below } and { start area above } for the left intersection point and { end area below } and { end area above } for the right intersection point
sort the array of markers by the x coordinate of the events
traverse the array of markers. if some segment (x1..x2) is being reported as having the union area only above it or only below it, it becomes the negative or positive segment of the union respectively.
At this point one could run some sort of DFS to merge the segments into the connected loops, but this is actually unnecessary to compute the area using the trapezoid method. Just summing up (x2 - x1)· (y1 + y2) / 2 for all the segments does the trick, and it would automatically ensure that the outer contours are taken with the positive sign and the inner contours are taken with the negative sign.
The solution described above runs in O(n2· logn) : for each of O(n) lines we have at most O(n) intersections, which should be sorted in O(n· logn) inside the loop over all the lines.







We can just check (MN - minutes in input, HR - hours in input):
This is a statement of your problem B. Here you use a word some which change the meaning of the statement what you want to mean. This statement mean if there are any aj which fullfil the condition ai < aj, tutuf will continue using Gava. The word some totally change the statement here and I got wrong over and over only for that reason. Is not it a mistake?
then plz help me the 4th test case at which my code failed
I used the following idea: let x=all possible teams=
Is anything wrong in the reasoning? I got stuck on test 21. submission[635824]. Code is here.
A = C ( sum(s[i] i!=h) - 1, n - 1), I think it should be A = C ( sum[i] i!= h), n - 1). Why we must subtract 1 ?
And F(k) = ... sum(s[i] i!=h) - (k + 1), why we must subtract (k + 1) ?
F(k) = C( s[h] - 1, k) * C( sum(s[i] i!=h), n - (k + 1) )
Can someone explain how to calculate the transition matrix for Div1 D(Crime Management),and also what should the dp state be?
Thanks. good editorial