


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | orzdevinwang | 3570 |
| 4 | Geothermal | 3569 |
| 4 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3531 |
| 8 | Radewoosh | 3521 |
| 9 | Um_nik | 3482 |
| 10 | jiangly | 3468 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 161 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 152 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |







Problem D was very interesting. Can't solve it during contest but spend all of my time on this problem. I can't understand the editoroal properly for this problem. Can anyone exolain this or give some info on how to become good at this kinds of problems.
During Contest I try to solve this using Binary Search and Two Pointer. But I can't figure it out.
If the number of days with negative temperature is larger than k then there is no solution. Otherwise there is a solution which is maximum 2*cnt ; (cnt number of negative segments) (because you need to change to Winter rubbers before the negative segment and change back to Summer rubbers after the negative segment is over). Now you have k — cnt days you can use Winter rubbers so if we can use them to merge 2 negative segments this will reduce the answer by 2. It's now obvious that we can greedily pick the shortest positive segments that lie in between 2 negative segments and delete them (as described in the tutorial). One special case is shown in the 3rd sample tests which is if you have enough days left for the last positive segment (that lies after the last negative segment), you can skip changing back to Summer rubbers at the end, thus we decrease the answer by 1.
Thanks for contest! Waiting for the next contest!(^_^)7
Easi tasks)0))0)
Unusual terrible bugs at unusual contest time...
Can someone please give proof of why the last segment of days with non-negative temperature has to be processed separately ? and not inserted in the heap. As far as i can think of that the other segments give us 2 changes per segment and the last will only give 1 change. But how is the length of days not the priority when we are considering last segment of non-negative temperature.??
Because the last segment will decrease the answer by only 1, so it's better to get rid of another segment that will guarantee decreasing the answer by 2. Observe this Test Case: 5 4 -1 1 1 -1 1 If you were to choose the last segment [5,5] because it's smaller than [2,3], then the answer would decrease by one (answer = 3) and then I can't get rid of the segment [2,3] because I can use the winter rubber only once more. But if you choose the segment [2,3] then the answer would decrease by 2 (answer = 2) which is a better solution.
I had the same approach but I am timing out on test case 12.Is O(nlogn) not appropriate>?
I will try to prove you why last segment is least important.Consider last segment gives you 1 point and other segments which are stored give you 2 points. Let initially k be some value which decreases as we move through the set till we reach a point we can’t gain any more 2 points.Now if leftover k is greater than the special segment we have no problem, we will gain one more point. But now you might think what if left over k is less than the special segment?.Well it turns out if you have to extract 1 point from this segment you will have to increase your k value!The only way to do this is to give up one segment that gave you 2 points. So will you a trade of 2 points for 1 point?:). I hope this clears your doubt.
One of my classmates provided a solution for F in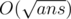 . Let us suppose that the ans is less than 162 * k. We devide the ans into 2 parts length of which is k. For the hinder part,suppose that if we have known how many letters we can use at most i times in the hinder part,we can get dp[s] interesting numbers while s is the state about it. Of course if i > k we can consider i = k.So the number of kinds of s is 16k + 1 at most. We can pretreat the dp array in O(16k + 1). Then we enumerate the front part in O(16k) and query the instereting number by dp array in O(1). So the solution is
. Let us suppose that the ans is less than 162 * k. We devide the ans into 2 parts length of which is k. For the hinder part,suppose that if we have known how many letters we can use at most i times in the hinder part,we can get dp[s] interesting numbers while s is the state about it. Of course if i > k we can consider i = k.So the number of kinds of s is 16k + 1 at most. We can pretreat the dp array in O(16k + 1). Then we enumerate the front part in O(16k) and query the instereting number by dp array in O(1). So the solution is 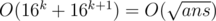 . Yeah,my English is really bad.QwQ
. Yeah,my English is really bad.QwQ
Can anyone help me the Problem C. I have wrong answer in test 9. Then I fix some in that, then it accept, but I can't regconize the difference between the old and new. Please help me.
Here the accepted code : http://ideone.com/wPPQrN
Here the "same" code wrong answer test 9 : http://ideone.com/z12T9u
You are getting WA because you tried to use the available servers but failed (because there isn't enough servers), but you already changed the values of the array Time. This means you skipped a task because not enough servers but you marked some of the servers as used for this task (but you shouldn't mark any servers if you skipped the task).
Thank you very much, sir. Finally I can see my big mistake
thanks Ibrahim.
In problem C for this case:
12 3
3 3 2
1 3 1
4 1 1
ACCPTED OUTPUT :
6
15
4
BUT why not:
6
6
4
my explanation :
for 1st task all server are not busy so i can use first 3 => 1,2,3 . They will free at 5th second (3,4 second will be busy) . So 6 . Look here before the 3th second in 1,2 seconds server 1,2,3,......,12 was unoccopied .
So for second task since starting is from 1st second so it can be perform 1,2,3 servers since , "before the 3th second in 1,2 seconds server 1,2,3,......,12 was unoccopied ". so 6 .
For the task 3rd . In the 4th second there will be unoccopied server : 4,5,6,......,12 i will pick the smallest so 4 .
"The tasks are given in a chronological order"
sir, i am struggling with today C, Server here is my code https://paste.ubuntu.com/23652768/ here i upadate my FREE[] while checking each server and getting WA. But some people got AC since they update it at the end,(comment in my code) my question is why this happening?? thanks in advance
This is because it is not guaranteed there will be enough servers to handle the request, in this case, none of the servers should be occupied by the task. If you update the status of the servers before determining if there is enough servers, it could result in occupying servers which are not supposed to be happening.
Can someone explain F in more detail . Is it similar to digit DP ?
Sir, please help me with 747E - Comments. My approach is similar to the editorial : Firstly, I separate all the number and string and store it in a vector. After that, I find the depth of each word by DFS and print it. I think it will work in O(n), but as you see, it nearly TLE in test 9 and TLE in test 29.
Here is my code: 23167334
Thank you very much.
True, but you have an implementation problem in the separate function, you use
s = s + str[i]which has a complexity of O(|s|), where you can uses += str[i]which has a complexity of O(1). 23169430 here I got AC just by changing this line of code.Oh thank you very much, I think that they have the same complexity. Lost E just because this :(.
Now you know better, good luck next time.
What is the reason behind this?
Because
s += str[i]will simply add the character to the string in O(1) (similar topush_backin Vectors), but withs = s + str[i], the compiler will make a copy ofsand addstr[i]to this copy and then assign the result toswhich will takes a lot of time O(|s|).Can someone, please, explain problem F in more details?
Thanks for the help!
I can describe my solution
Binary search on what is the answer(mi). So, the problem reduces to counting number of numbers <= mi such that each digit occurs <= t times.
In fact, we solve a more general problem — find number of numbers of length i such that each digit j occurs <= b[j] times. 0 complicates the matter somewhat but for the time assume that 0 can be placed anywhere and obeys constraint like the normal digits. Then formulate dp[i][j] = number of numbers with i digits and place only digits <= j. Iterate k = how many j digits will be there — 0 to min(i,b[j]) then dp[i][j] = sum((i choose k)*dp[i-k][j-1]). Base cases are simple to write.
Overall count can be calculated by fixing highest digit(depends on mi) and then a dp call, then next digits etc.. similar to what we do in offline digits dp solution. The prefix digits that are fixed decide what array b is(t — number of times digit has occurred till now).
Finally for 0, simply calculate for lesser lengths using a similar logic. Checkout my solution for more details.
Time complexity = O(p^3*d^3) where p=max digits in answer=9 and d=16 and = runs in 15 ms :)
Can you explain a bit more on how do we handle dp when the prefix digits are fixed?
If you have done any question in which we need to count numbers <= x such that some property holds then we calculate d[i] = number of numbers with length i having that property and run this loop:
for(int k=MAX_DIGIT; k>=0; k--) {//digits from MAX_DIGIT to k+1 are equal to digits in x implicitly.
for(int i=0; i<x[k]; i++) {
ans += d[k-1];
}
}
The idea is exactly similar we call. The digits are fixed automatically as they need to be equal to be mi's digits and we call dp for remaining length.(those i and j loops in my solution).
Thanks, got it now. I mistakenly interpreted that there is a way to fix the prefix and not recalculate the dp array.
Thanks a lot for your help! Got accepted!
I guess I'm misunderstanding problem F statement, because I coded a simple brute force to check the correctness of the second example and the result seems wrong.
Input: 1000000 2
Output: fca2c
My function:
It returns 931720, which is less than 1000000.
I'd be thankful if someone could explain me the problem statement.
UPD: Nevermind, my
fromhexfunction had a bug...For D, i think it is not necessary to use set to do that
first of all, we ignore the first consecutive and the last consecutive segments.
then we gain all the segments which are only consist of non-negative numbers
we sort the segments by their length (the same as the solution)
so we just keep picking from smaller one to large one
finally, for the first consecutive part, it doesn't impact the answer, so we ignore it.
for the last consecutive part, if it is consist of non-negative number, we should ensure whether we can use the left k tires to pass it, if we can, the answer should minus 1.
if it is consist of negative number, we should let answer minus 1 (because u don't need to change at the end of the sequence)
for more infor, here is my code : http://codeforces.com/contest/747/submission/23391692
Hey, can anyone tell how to solve D using DP? It has a DP tag, and I am practicing DP questions, so I would be more than grateful to know about that! :D
This is not linked with problems, can you please look into it fcspartakm