


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | orzdevinwang | 3570 |
| 4 | Geothermal | 3569 |
| 4 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3531 |
| 8 | Radewoosh | 3521 |
| 9 | Um_nik | 3482 |
| 10 | jiangly | 3468 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 161 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 152 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
Hello, Codeforces!
I'd like to invite you to Codeforces Round #592 (Div. 2). It'll be held on Sunday, October 13 at 12:05 MSK. Note that round starts in the unusual time!
The round will be rated for the participants with rating lower than 2100. The statements will be available in Russian and English.
This round is held on the tasks of the regional stage All-Russian Team Olympiad of Informatics 2019/2020 year in city Saratov. The problems were prepared by Ivan BledDest Androsov, Vladimir vovuh Petrov and me.
Great thanks to Ivan isaf27 Safonov for helping in preparing the contest, to Mike MikeMirzayanov Mirzayanov for the great Codeforces and Polygon platform and to Ivan CaseRuten Khudoshin, Ivan Ivan19981305 Georgiev, Leonid Peinot Mironov, Anton anon20016 Lebedev, Ksenia Pavlova Pavlova and Dmitriy dmitrii.krasnihin Krasnihin for writing solutions.
You will be given seven problems and two hours to solve them. The scoring distribution will be published soon. Good luck everyone!
UPD The scoring distribution 500-1000-1500-1750-2500-2500-3000
UPD Editorial
Hello, Codeforces. Below you can see the improvements in the system Polygon.
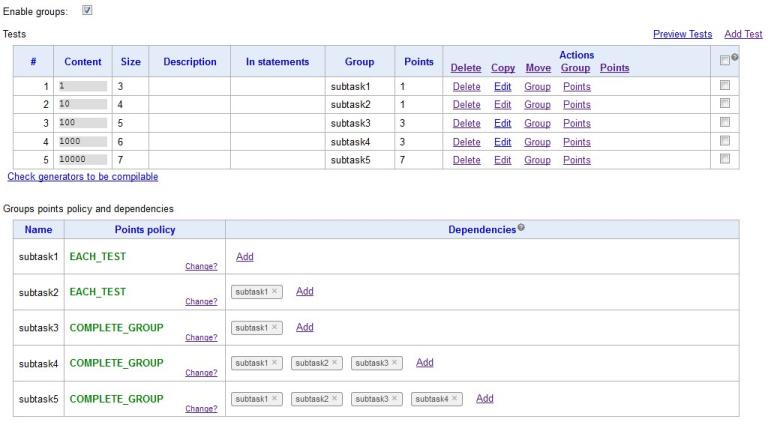
A lot of work has been done to simplify the preparation of school tasks, which use groups and points for tests. In the General Information tab, you can enable the points option for each test. This option is enabled points for the whole problem, that is, for tests from all testsets. Let me remind you that test groups can be enabled for each testset separately on the Tests tab.
Points for the test, as well as groups, can be entered in the table with the list of tests, and also specify them when creating a new test. If the group for the test appears for the first time, it will be automatically added to the list of available groups. This list is presented in the table.
Hello, Codeforces.
In this post we want to talk about the Codeforces and Polygon improvements, which were implemented recently.
Previously, Codeforces blog posts can either be published together with the translation, or both versions can be hidden in drafts. Now a blog post can be published or hidden in drafts separately from its translation. In case there is a published post, and its translation is hidden in drafts, or in the opposite case, you will see a corresponding warning about that. Also the logic of the Recent Actions was completely revised.
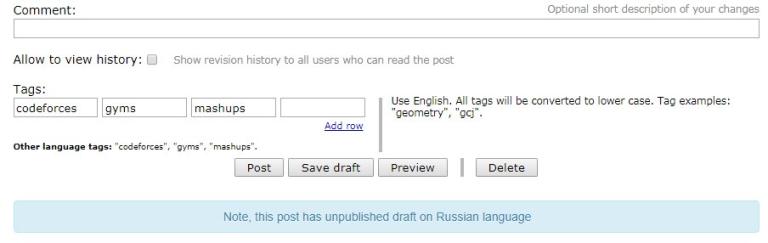
Also added a new functional in the Talks. For some users, it was inconvenient if a talk with one person contains a lot of messages. The page Dialogues has been implemented. It contains all the dialogs, sorted by the time of the last message. For each dialog, only one row with the last message is shown. When you click the message the talk with this person will open. When you open talk with the person, all messages sent to you by the corresponding person automatically become read. The old-style talks page is also fully preserved.
Hello!
In this post I will talk about recent innovation in Codeforces.
It is noticed that many coaches used the opportunity to change the start of the training/rename it for personal purposes (to host group trainings). This leads to confusion and inconvenience for other members of the community.

To keep everything in order, we changed the rules for editing gym contests. Now a coach can change the name/start time/description of a gym if it is not public or the last update was made not later than a week ago. A week after editing a gym, it becomes the history of Codeforces and coaches lose an opportunity to make edits in it.
You cat ask "how do you give a training in a group, specifying the start time?" Now there is such a way!
To allow more convenient re-use of past trainings, as well as regular contests, it was possible to copy past training and regular competitions into a mashup. This can be done by clicking on the corresponding button in the right sidebar or directly in the form of mashup creation.

In the copied mashup all the submissions of participants of parent contest, the statements of the problems and other information are inherited. Thus, it is a convenient way to start a training in a group at a specific time (now participants will participate in an ordinary way, and not make a synchronous virtual start), giving it its own name.
Wish you successful trainings!
Hello again, Codeforces!
I'd like to invite you to Codeforces Round #452 (Div. 2). It'll be held on Sunday, December 17 at 09:35 MSK and as usual Div. 1 participants can join out of competition. Note that round starts in the unusual time!
The round is rated.
This round is held on the tasks of the second day of the municipal stage All-Russian Olympiad of Informatics 2017/2018 year in city Saratov. They were prepared by Olympiad center of programmers of Saratov SU. A convincing request to the participants of the municipal stage in Saratov to do not participate in this contest.
Great thanks to Nikolay Kalinin (KAN) and Grigory Reznikov (vintage_Vlad_Makeev) for helping me preparing the contest, to Mike Mirzayanov (MikeMirzayanov) for the great Codeforces and Polygon platform and to Alexey Ripinen (Perforator) for writing solutions.
You will be given six problems and two hours to solve them. The scoring distribution will be published soon. Good luck everyone!
UPD The scoring distribution 500-1000-1500-1750-2250-2500
UPD: The system testing is starting now, but upsolving, virtual participation and viewing solutions and tests will be disabled till the end of the olympiad in Saratov (around 2-3 hours from now). Hope for your understanding. Editorial will be posted after the olympiad as well.
UPD Congratulations to the winners!
UPD Editorial
Hello, Codeforces!
I'd like to invite you to Codeforces Round #451 (Div. 2). It'll be held on Saturday, December 16 at 14:35 MSK and as usual Div. 1 participants can join out of competition. Note that round starts in the unusual time!
The round is rated.
This round is held on the tasks of the municipal stage All-Russian Olympiad of Informatics 2017/2018 year in city Saratov. They were prepared by Olympiad center of programmers of Saratov SU. A convincing request to the participants of the municipal stage in Saratov to do not participate in this contest.
Great thanks to Grigory Reznikov (vintage_Vlad_Makeev) and Nikolay Kalinin (KAN) for helping me preparing the contest, to Mike Mirzayanov (MikeMirzayanov) for the great Codeforces and Polygon platform and to Alexey Ripinen (Perforator) and Roman Glazov (Roms) for writing solutions.
You will be given six problems and two hours to solve them. The scoring distribution 500-750-1500-1750-2000-2500. Good luck everyone!
UPD Editorial
UPD2 Congratulations to the winners!
Hello, Codeforces!
The latest innovation in Codeforces is introduction Google calendar with information about the upcoming contests. To view calendar you can visit tab "Calendar" in the top menu.

The Codeforces contests are adding in calendar automatically. Also you can add contests from the other programming platforms. Each red user has this option. In addition, we will grant the rights to edit the calendar to employees/enthusiasts of other popular platforms.
In the tab "Add" you can add information about upcoming contest. The form shown below will help you for this.
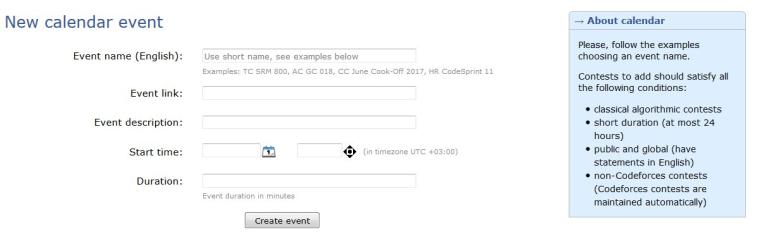
Please, add to the calendar classic algorithmic contests which duration does not exceed a day. Also the contest must be publicly available, i. e. had English statements and open for a wide range of participants. We ask you to use short names for competitions, as it is presented in the examples, for convenience and uniformity.
Also you can edit or remove information about upcoming events in corresponding tabs.
We hope that the calendar will be useful for you and will help to planning your time and learn about all upcoming programming events.
In our plans to expand the functionality of the calendar. Write about your ideas for improving it in the comments.
Hello, Codeforces!
It is time to tell about the improvements in Polygon. It is a system for the preparation of programming problems. All Codeforces rounds and many other olympiads prepared in Polygon. Everyone at any time can use this system.
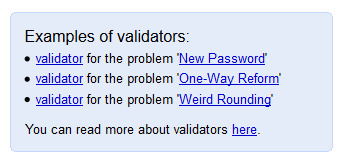
A special fields with examples now displayed on a page with a list of files which used in problem and on checker, interactor and validator pages. It will be very useful for the new users and will help them faster understand the system.
Hello, Codeforces! It's me again=)
I'd like to invite you to Codeforces Round #387 (Div. 2). It'll be held on Monday, December 19 at 05:05 MSK and Div. 1 participants can join out of competition.
This round is held on the tasks of the second day of the municipal stage All-Russian Olympiad of Informatics 2016/2017 year in city Saratov. They were prepared by Olympiad center of programmers of Saratov SU.
Great thanks to Nikolay Kalinin (KAN) for helping me preparing the contest, to Tatiana Semenova (Tatiana_S) for translating the statements into English, to Mike Mirzayanov (MikeMirzayanov) for the great Codeforces and Polygon platform and to Vladimir Petrov (vovuh), Alexey Ripinen (Perforator), Mikhail Levshunov (Levshunovma), Mikhail Piklyaev (awoo), Aleksey Slutskiy (pyloolex), Ivan Androsov (BledDest), Oleg Smirnov (Oleg_Smirnov) and Roman Kireev (RoKi) for writing solutions and editorials.
You will be given six problems and two hours to solve them. The scoring distribution will be announced later. Good luck everyone!
UPD The scoring distribution 500-1000-1500-2000-2000-2500
UPD2 Editorial
UPD3 Congratulations to the winners!






