


Hello everyone!
I'm writing this entry to invite you all to take part in the first edition of Info (1) Cup contest. It is an individual contest with algorithmic tasks and we will accept only C++ sources. The contest itself has 2 parts, both of which held online.
You can still take part in the online mirror in any frame of 5 hours before time. We invite you all to participate. The tasks should be challenging for everyone The live scoreboard of the online mirror is on.
PS: As in all the other contests that have online mirrors, I kindly ask you not to discuss the tasks until all the rounds and their online mirrors end. After that, on the official site, you'll find the editorials of the problems.
The first one consists of a national contest in which only invited Romanians can take part and which should be easier. We haven't decided yet whether we'll host an online mirror of it or not and I'll update the post later with this kind of information. We will host an online mirror of round 1 too. We invite you all to take part. We assess the difficulty to be similar to that of a div2 round or even a little lower, so if you are div1 we strongly advise you not to take part in this round, but rather in the second contest described below
The second one is the international contest that I can assure you anyone can take part in. However, as we want the contest to be as similar as possible to international OIs (such as BOI, or CEOI), we want just participants from the official teams of different countries to sign up at the official version. We'll also have an unofficial second contest, similar to an online mirror which you can take in any 5-hours frame for a couple of days after the contest (usaco system). The official round will have a fixed frame . If you consider the time frame good for your country and the country is not listed below yet, I kindly ask you to PM me with information about how to contact any person that may be considered to be in charge with the selection of your country's teams for international competitions to give them the link to the official registration form. Ohh and about the unofficial registration, you'll be able to make an account soon using the official site (LE: Now you can register for the online mirror). The contest will be full-feedback and will use CMS, 5-hours long with 4 problems with all kinds of difficulty level.
Also, about the prizes, we'll award medals and certificates to the winners of the official round,
Ohh and forgot to mention the scientific committee: I'm one of the members together with Alex Niculae and Costin Tudor
The official round 2 is now over. Congratulations to all the participants and special congratulations for those who got a maximum score: Mahmoudian Bidgoli Arash (who finished after just 3 hours and 48 minutes), Alex Tatomir and Mishinev Encho . I hope you enjoyed the contest. Also, we're sorry that, at the 4th problem, we had a limit a little too large which let solutions intended to get 78 points to get a full score. We'd like to address special congratulations to the only contestant that solved the problem in the intended way (that we find pretty tricky and nice and will be explained in the editorial after the ending of the online mirror), Hossein Mohammad Nematollahi.
We kindly ask you not to discuss the solutions until the end of the online mirror. However, we'd be happy to receive any kind of feedback regarding the competition so that we can improve it the next year, doesnt't matter whether it's positive feedback or not.







Auto comment: topic has been updated by geniucos (previous revision, new revision, compare).
Auto comment: topic has been updated by geniucos (previous revision, new revision, compare).
Auto comment: topic has been updated by geniucos (previous revision, new revision, compare).
Auto comment: topic has been updated by geniucos (previous revision, new revision, compare).
Auto comment: topic has been updated by geniucos (previous revision, new revision, compare).
Unable to register .....anybody help !!
The script is still in progress. You should be able to register by the end of the weekend.
The script is working, you can all register
Auto comment: topic has been updated by geniucos (previous revision, new revision, compare).
Does O(n*log(n)*T) pass for the last problem ?
It shouldn't. Unfortunately, we set the limits too large in the official round, and there is only one participant that implemented the wanted solution, all others having the complexity mentioned by you.
However, you can try the problem with the changed limits in the online mirror, and we will also post the editorial after the online mirror.
Hope you enjoyed the tasks :)
Ok, thanks.
When will you publish the scoreboard?
click
Can please someone explain how to solve problems Comeback and Walk from day 1?
ComeBack:
At first, we will compute for every i from 1 to N, the right end, j, such that sum[i,j] <= X && sum[i,j+1] > X. Because the numbers are non-negative, for every k (i <= k <= j), sum[i;k] <= X. We will keep track of the number of these sequences (Cnt) and their sum (Sum).
Afterwards, we will “move” the i-th element at the end of the array. We should update Cnt and Sum: we will substract the sequences that had the left end equal to i, and will add the sequences that will have the right end equal to n + i.
This can be done in O(n) with some precomputed sums and sums of the partial sums. You can check our source for more details: http://info1cup.com/files/Revenire.cpp
Walk:
We have dp[x] — the number of ways to have the walk in the x’s subtree as it said in the statement. v[x] — all the restricted nodes from the x’s subtree.
dp[x] = 0, if v[x] doesn’t contain consecutive positions, or, if x is restricted, the position of the x node (from the restricted order) is bigger than at least a restricted node from its subtree.
dp[x] = dp[son1] * dp[son2] * … dp[son_cnt] * arrangements(cnt, cnt — sons_restricted), where cnt is the number of x’s sons, and sons_restricted are the number of x’s sons that are restricted
Thank you
My solution for the last problem:
The solution for T ≤ 18 builds P - 1 = R by placing numbers from 1 to N into it one by one; when R contains the first j - 1 numbers and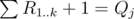 , we insert j to the position Rk + 1. The structure that supports insert / subarray sum is treap; the right positions can be binsearched, which gives
, we insert j to the position Rk + 1. The structure that supports insert / subarray sum is treap; the right positions can be binsearched, which gives 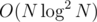 complexity, maybe
complexity, maybe  if implemented well.
if implemented well.
How to avoid bignums: instead of Qi take only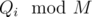 where 15M fits into long long; this way, we lose the ability to binsearch, but the main principle is similar. We still need to find positions where prefix sums equal Qj and be able to insert numbers.
where 15M fits into long long; this way, we lose the ability to binsearch, but the main principle is similar. We still need to find positions where prefix sums equal Qj and be able to insert numbers.
We can use sqrt decomposition — store R as a linked list, recalculate prefix sums after adding each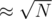 numbers, store them in a hashmap and when searching for the next position to insert, try all possibilities for how many of the numbers added since the last recalculation are contained in the prefix whose sum should equal Qi. Time complexity:
numbers, store them in a hashmap and when searching for the next position to insert, try all possibilities for how many of the numbers added since the last recalculation are contained in the prefix whose sum should equal Qi. Time complexity: 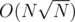 .
.
This problem is an excellent example of why input processing isn't part of IOI problems. Just reading the largest inputs takes 400 ms for me (fast cin, scanf, getchar_unlocked...) and the more straightforward methods of computing all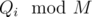 add another second. IOI format with input reading dealt with by the organisers and a provided get_number() method for contestants to decide on how much of the input to store would have been much better. It hurt what could have been a really good problem — I wasn't looking for a solution to the algorithmic part as much as for a way to get a reasonable input without shooting myself in the foot.
add another second. IOI format with input reading dealt with by the organisers and a provided get_number() method for contestants to decide on how much of the input to store would have been much better. It hurt what could have been a really good problem — I wasn't looking for a solution to the algorithmic part as much as for a way to get a reasonable input without shooting myself in the foot.
Also, too few tests. I was able to gain a 40% speedup (and easily pass the version with original limits) by copypasting a few lines to take care of my most obvious worstcase.
What you've explained is almost the official solution. We had the same complexity, but we transformed the task in some operations supporting problem (adding on interval and interrogating where is the last appearance of a 1).
I'm sorry for the inconveniences. We should have implemented a function get_number (). I thought about giving input as a parameter and quickly gave up as the official source was not storing the all input, but a function to return the numbers one by one would've been a great idea...About computing Qi mod M, it was time consuming in our sources too and the strict time limit was to avoid big number treaps or segment trees getting accepted, which unfortunately was not enough either:(. That's the reason for the last specification which was really weird: that of testing the reading part independently from the rest of the code. I have a lot of regrets regarding this problem and how it could have been better.
About the number of tests, we were afraid of too many submissions (which was not the case) and tried to make as few and strong tests as possible. I still don't understand how you could improve your most obvious worst case though.
LE: After a little thinking, I realize that implementing a function get_number was not very useful either. Most of the time was being spent on computing the value of number modulo something (In my source too), but the reading takes about 400 ms irrespective of the reading method and when we fixed the time limit we took care at considering those 400 ms. However, I agree that the task had a lot of problems but I still don't know how to solve most of them. We should've made more tests and fix better limits (decrease the memory limit even more and let the time limit as it was as we had 1 solution with big integer segment tree that passed even the new limits). But about the reading I don't think there's much we could do. Anyway, fixing better limits should've been enough (for example you should easily fit in 3 seconds without caring that much that half of the time is spent on reading)
A fixed reading method would help since nobody could waste time trying to optimise it and the time limit would be more informative — like this, it carries a hope that maybe I'll be able to shave off some 100-200 ms or that maybe someone else did.
I dealt with possible locations of the next number to add this way: check if it's before all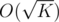 newly added numbers, if not then check if it's after the 1st, 2nd, 3rd etc. and finally if it's behind all of them. It ran 2.2+ seconds on the last test after a lot of tiny optimisations. Then I changed it to checking if it's before all of them, then after all of them, then after the 1st, 2nd etc., and the running time dropped to 1.4 seconds (on the last test, 1.6 overall). That's a lot, considering it's such a small change — surely tests where numbers are added to R in specific patterns that slow it down exist.
newly added numbers, if not then check if it's after the 1st, 2nd, 3rd etc. and finally if it's behind all of them. It ran 2.2+ seconds on the last test after a lot of tiny optimisations. Then I changed it to checking if it's before all of them, then after all of them, then after the 1st, 2nd etc., and the running time dropped to 1.4 seconds (on the last test, 1.6 overall). That's a lot, considering it's such a small change — surely tests where numbers are added to R in specific patterns that slow it down exist.
Ohh now I see. However, I'm not really sure that such tests exist. Few permutations have a decent size of the input file (and by that I mean less than 1GB:)) ) and we didn't have exactly full control over the tests. I'll think at a way to build a test so that this optimization won't make such a difference and add id to the test data together with some other tests when I'll publish it on an online judge. Right now, I'm thinking just at some romanian online judge. BTW, do you have any suggestions about where can I add it so that it'll still have subtasks and it'll be more open to all? I'd add it on CF, but there are no subtasks in gym:(
Just make a separate problem for each subtask; merge some subtasks if you don't want too many. People don't worry much about subtasks on CF level.
Could you please open the solutions for the tasks from the international round, as the online mirror is over now?
We're writing them right now. Sometime this evening, they'll be published on the official site. Sorry for the delay: we're very few in the committee and we've been very busy lately. However, you shouldn't wait much longer:)
Thank you for your reply and the editorials. Well, I was actually talking about the "View solution" button, which at the moment seems to link to "info1cup.com/notAvailable". Could you handle that too please?
I am wondering, how every prefix of DFS preorder traversal is beautiful (connected)? For example if we have bridges: 1-2, 2-3, 2-4, 1-5, 5-6, 5-7. DFS preorder traversal is 1-2-3-4-5-6-7. At first we take for query set {1, 2, 3}, which is connected. But at the second query set {4, 5} isn't connected anymore (they are in different subtrees). Please, explain which part of my thinking is wrong.
{4, 5} is not a prefix. {1, 2, 3, 4, 5} would be enough to find out what you're interested in and it's a prefix (thus, connected). Each query asks for a prefix ending at a fixed binary searched position.
Aha, I understand. We do binary search, but always query from 1 to mid. Thank you very much.
Yep, you got it right. You're welcome
So here's my review: I think the problems were all nice. There weren't too many people with the same score, wich is nice.
There were too many announcements. It was annoying and distracting. Different input/output formats were confusing. I submitted a code that was reading from standard input, when it should've read from input file. I received wrong answer instead of something like "output file not found". I'm not sure how CMS works, but I think usaco had a different verdict for this issue.
By the way, are we going to receive actual medals or just a certificate?
You'll receive actual medals. About the missing output file, yes, we should've tried to give such an verdict when needed. I'm not sure yet how to do it, but I'll do some research. All those issues will be gone next year, I promise. It was our first edition and I think we're able to learn from our mistakes. Thanks a lot for the feedback!
The task were really interesting and the difficulty curve was great. It was a lot of fun to solve them.
The testdata was a little weak:
My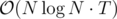 with bigintegers in base 1018 got all points in 'permutation recovery 2'. I liked the idea of the problem, but the balance between time spent parsing the input and killing off bigint solutions seems rather difficult.
with bigintegers in base 1018 got all points in 'permutation recovery 2'. I liked the idea of the problem, but the balance between time spent parsing the input and killing off bigint solutions seems rather difficult.
In 'binary subsequences' I got the last 18 points by cutting off the smallest of the comprimes pairs (i, N + 2 - i), 2·i < N + 2 when N > 105, which seems wrong.
of the comprimes pairs (i, N + 2 - i), 2·i < N + 2 when N > 105, which seems wrong.
In 'binary subsequences', a larger subtasks where you can get some points by answering only queries of the first type would have been nice, as computing φ(N + 2) is quite a bit easier than computing the shortest binary string in almost linear time.
We know about the weak tests. Actually, they are not that weak, we should have decreased the memory limit even more (maybe 32 MB?), as this way we could let the time limit even looser and stop big integers solutions pass...It was just a bad choice that we made:( . Yes, in binary subsequences, answering first question for N~1e9 would be nice, but we've focused on finding some method to find the strings and then we stopped instead of analyzing the task even more. About the smallest 1/2, do you mean you checked for i <= N / 4? Because using i <= N / 2 is correct as an string obtained for (i, N + 2 — i) is the exact opposite of a string obtained for (N + 2 — i, i), and so, it has the same length.
Decreasing the memory limit would have been a great idea.
The cutoff I used was only considering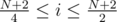 if n > 105. I have no idea if I just got lucky or whether this works most of the time.
if n > 105. I have no idea if I just got lucky or whether this works most of the time.
There were some other optimizations such as iterating from highest to lowest i or breaking when the current string gets longer than the previous best one.
In the editorial you mention that the shortest length is at most 16 when K ≤ 2000. It seems like the shortest length is at most 30 when K ≤ 106. This could be used to construct another fast solution.
I thought it was quite amusing that the statement asked to print the answer mod 109 + 7. I think it was a good idea to include this in the task statement, as one might otherwise sooner realize that the answer is small.
Actually, there were some people tricked by the modulo:)) it was exactly this reason for which we decided to pretend the value could be large. Yes, I made all kinds of experiments and saw that all values of K have at least one string of length at most 30. I thought for a while whether there is some interesting way of doing a meet in the middle. I've got only one partial idea: pretending that we go from a state (x, y), fixing a string of length at most 15 and finding out the sum of the 2 numbers in the state that we reach as something like ax + by + c. Now, we can do one more backtracking to fix the first half of the string, compute where we end up after following the route, let's say we end up in (x, y). Now we should somehow see whether it can be matched with some triplet (a, b, c) in order to get K, but that's where I stumbled...Soo, if you already have a complete idea of how to do it based on the fact that the length will be rather small (30 in our case), could you share it with us? This way, we could compute phi (N + 2) to solve the first kind of query and some strange complexity for the second one (which who knows? maybe it'd work for N<=1e9)
It might be quite late, but it is possible to upsolve ALL problems from the International Round here: https://oj.uz/problems/source/325