


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | orzdevinwang | 3570 |
| 4 | Geothermal | 3569 |
| 4 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3531 |
| 8 | Radewoosh | 3521 |
| 9 | Um_nik | 3482 |
| 10 | jiangly | 3468 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 161 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |






Btw, O(N^2) solution (even without bitmasks) for problem G.
I couldn't understand your solution by reading the code :/ Would you please explain your solution?
It's just like:
for (int i = l; i <= r; ++i) if (a[i] == x) a[i] = y;, but is written a bit trickier.Well if you thought that that solution got accepted is a bad thing... look at this: http://codeforces.com/contest/911/submission/33820899
the most naive solution can get accepted with some tricks..
Hi, can you tell us what does this "unroll-loops" pragma mean and what does it do?
Yes. Please throw some light on the 3 pragmas mentioned.
the first just tells the compiler to optimize the code for speed to make is as fast as possible (and not look for space)
the second tells the compiler to unroll loops. normally if we have a loop there is a ++i instruction somewhere. We normally dont care because code inside the loop requires much more time but in this case there is only one instruction inside the loop so we want the compiler to optimize this.
and last but not least we want to tell the compiler that our cpu has simd instructions and allow him to vectorize our code
Interesting! Did you tried experimenting their combinations and see how each pragma affects the time? Just curious.
they are all required to pass the tests
Can you suggest where I can learn about using pragmas?
i am sorry i have no source for this... but in generel i would recomend not to use them anyway! This solution was definitely not wanted and should never have passed... and normaly it doesn't help to use any pragma to get accepted. You just need to find a good algorithm. (some of this pragmas make normal code slower!)
Haha, manual loop-unrolling ftw.
Anyway, your solution uses segment tree idea under the hood, right?
Can you give some suggestions on how to make the program run faster if there is something more than just simple loops(for example,dfs and so on)?
You know, if we talk about the general case, then there is an acceleration operator in c++. For example:
Now use acceleration operator:
Bingo! Now you code runs very fast.
But seriously, I have some ideas for optimizing solutions with graphs, but so far there has not been a problem where I could test them =) Well, the general suggestions are simple: do as few operations as possible and access to memory as fast as possible.
Here's a nice implementation for E that I wrote after the contest: 33746048.
Problem G can be solved in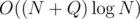 independent of max ai.
independent of max ai.
For each value, we store the positions it occurs in. This can be encoded into a segment tree-like data structure, where we have a node for each range (that would be in a regular segment tree) that contains the value at least once. There will be nodes total.
nodes total.
To change x to y in a range, first divide it into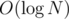 intervals that are represented by single nodes (like in a regular segment tree). Then, merge each node for x into the corresponding node for y. If either is empty, we at most do a swap, which is O(1). Otherwise, we recursively merge the children and delete the original x node. We may also add
intervals that are represented by single nodes (like in a regular segment tree). Then, merge each node for x into the corresponding node for y. If either is empty, we at most do a swap, which is O(1). Otherwise, we recursively merge the children and delete the original x node. We may also add 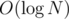 new nodes on the paths back to the root.
new nodes on the paths back to the root.
The answer can be recovered by recursively traversing the data structure for each number.
The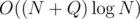 time bound can be shown using amortized analysis with the potential function as the number of nodes.
time bound can be shown using amortized analysis with the potential function as the number of nodes.
Here is my (after contest) implementation of this approach.
Can you elaborate more on the proof of complexity?
To make it easier to explain, I'll be referring to my implementation.
Building the data structure and recovering the answer are clearly .
.
If a > L or b < R, "transfer" divides the interval the same way a top-down segment tree does. This takes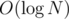 per query.
per query.
If a ≤ L and b ≥ R, "transfer" will always delete a node. Since only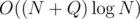 nodes are created, this can only happen
nodes are created, this can only happen 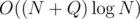 times. The body of the function excluding recursive calls (which are counted separately) takes O(1), so its total runtime is
times. The body of the function excluding recursive calls (which are counted separately) takes O(1), so its total runtime is 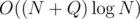 .
.
911D - Подсчет инверсий can be solved with help of Cycle Decomposition in O(n+m). We can find the parity of the initial permutation in O(n) in this way, reducing the overall complexity to O(n+m). Link to My Submission
but this while increase the complexity of the algorithm """while(!vis[now]) {vis[now]=1; now=P[now];}""" i wrote a code using BIT wich take O(nlog(n)) to find the initial permutaion, and it take the same time as you '109ms'
The time complexity of finding initial no of inversions is still O(n). There are two nested loops, but they are not executed for all values.
Let's say, for loops begins with 1, and then while loops runs till n, so it will mark all elements from index[1,n] as visited and hence while loop will not be executed for those values again.
One can visualize it as; for loop is executing while loop for element at given index i, if it is not marked, whereas while loop marks element which is present at index of given element.
For any i, we have three case P[i]=i, P[i]<i and P[i]>i.
if P[i]=i, while loop runs only once i.e. marks that element
if P[i]<i, since for loop has already been executed till i, P[i] is already marked, so no execution of while loop
if P[i]>i, while loop marks element P[i], and hence will not be executed when i=P[i]
In G i have used sqrt decomposition and in each block i maintained the fact that the current element refer to which element now (As doing this brutely takes O(100^2) I have used two long long integers and then with normal bitwise operations i maintained this. Thanks for such a nice problemset :)
If possible can anyone please give the question links similar to F!
Can someone give me an example of author's solutuion of problem G, please?
just look at 33740346 by pannibal
very beautiful~
I don't get how to update parent's node using children. Can you please explain what does that mean :
seg[x][i] = seg[rs][seg[ls][i]];upd: got it. just remember that segment tree is built on queries, not elements. we want to merge 2 sons. we consider that left son and right son both influence value of current scanline index. answer for value firstly changes in left son, then the result is changing in right son, that is why we have
seg[x][i] = seg[rs][seg[ls][i]];We can also prove D like this: If we reverse segment [l, r], then all inversions (i,j) which i < l or j > r will not be affected, so we just consider the number of inversions (i, j) which l <= i < j <= r. Let a is the number of inversions (i, j) which l <= i < j <= r, and b is number of all pair (i, j) which l <= i < j <= r, so b = (r — l + 1) * (r — l) / 2. Then if you reverse segment [l, r], a will change to b — a (all pairs which are not inversions will change to inversions, and vise versa). And because we just consider the parity of the result, we can change b — a to b + a. So that mean you just need to consider about the parity of b.
nice explaination!
In problem C, why answer for 4 3 2 is NO ? x1=1,x2=4,x3=2 will not lead to "YES" ?
there are many counter cases. One of them is 303 (as 4 and 3 only lead to odd places in this case but neither 302 is divisible by 4 nor 299 by 3).
inp: 4 3 2
x[] = 1 4 2
1 5 9 13 ...
4 7 10 13 ...
2 4 6 8 10 12 14 ...
from 4, there is no 11.
can somebody elaborately explain problem D ?
As the editorial says: “permutation with one swap is called transposition”. So, intuitively, you can think of a transposition as being a single swap. For example, one could say '[2, 1, 4, 3] is one transposition 'away' from [1, 2, 4, 3]', as only one swap (transposition) has been carried out.
Think of the identity permutation as a permutation in ascending order (so no inversions). For example, [1, 2, 3, 4, 5, 6] is the identity permutation of length 6 and [1, 2, 3, 4, 5, 6, 7, 8] is the identity permutation of length 8.
The parity of the permutation equals the parity of the number of transpositions needed to get it from the identity permutation. Parity is whether something is even or odd. For example, [4, 1, 2, 3, 6, 5] has even parity as there are four transpositions needed to get it from the identity permutation ([1, 2, 3, 4, 5, 6]). Swap elements with indices 1 and 4, then with indices 4 and 3, then indices 3 and 2, then indices 5 and 6.
The parity of the number of inversions = parity of the permutation.
So, the algorithm proposed by the editorial involves first calculating the number of inversions in the initial permutation. This can be done “naively (check all pairs of indices)”. For example, if we have [3, 2, 4, 1], first compare 2 and 3 (INVERSION!), then compare 4 and 3, then 4 and 2, then 1 and 3 (INVERSION!), then 1 and 2 (INVERSION!) and finally 1 and 4 (INVERSION!). So we have four inversions, so parity of inversions before any reverses is even.
Then, for each reverse you carry out, count the number of swaps in whatever way you want (the editorial suggests one way). Let's say the permutation before the reverse has x transpositions from the identity permutation and we know the parity of x (not necessary to know x itself). Let's call the number of swaps carried out in a single reverse y. The parity after the reverse = parity of x+y, as x+y is the total number of transpositions that have been carried out on the identity permutation to get to the current reversed permutation. If y is even, then parity after reverse = parity before reverse. If y is odd, the parity switches after reversing. (consider all the different possible parities of x and y). Thus, we can work out the parity of the permutation after ever reverse query.
You can also do this problem using cycle decomposition, which is what was suggested earlier (http://codeforces.com/blog/entry/56771?#comment-404553). If you're interested, you can read online about parity of permutations, cycles, transpositions, etc.
Hope that helped!
B can be done in O(log n).
kudos to the author of problem D !!!!
Alternate solution for G : We can use DSU with blocks division to solve the problem. Using DSU, we can find the final color of each initial color. We can maintain a groups array for the group of the current color and the parent array to find the current set of groups merged with the original color in DSU. Update is pretty straightforward with block updates of size sqrt(N). Time complexity will be O(Q*(100 + sqrt(N))).