

Hi!
I'm glad to invite you to participate in Avito Cool Challenge 2018 which starts on Dec/16/2018 17:35 (Moscow time). The round will be rated to participants of both divisons.

The problem setters are TLE, sunset, fateice, yanQval and quailty.
We would like to thank:
- cdkrot and 300iq for coordinating and helping us with the round.
- Lewin, Ashishgup, winger, AlexFetisov, vintage_Vlad_Makeev and isaf27 for testing the round and giving advice.
- choutii for playing a crucial role in the contest. (you'll see.)
- MikeMirzayanov for awesome Codeforces and Polygon.
- Avito for generously sponsoring this round.
This round is conducted on the initiative and support of Avito. Avito.ru is a Russian classified advertisements website with sections devoted to general good for sale, jobs, real estate, personals, cars for sale, and services. Avito.ru is the most popular classifieds site in Russia and is the third biggest classifieds site in the world after Craigslist and the Chinese website 58.com.
Avito presents nice gifts for participants. Top 30 participants and also 10 random participants with places 31-130 will be awarded with a special T-shirt.
You will be given 8 problems and 2.5 hours to solve them. As usual, the score distribution will be revealed shortly before the contest.
This is the first contest on Codeforces for most of us. Hope to see you participating! Good luck!
There will be an interactive problem in the round. If you have never solved interactive problems before, please read this.
UPD: The scoring distribution is standard 500-1000-1500-2000-2500-3000-3500-4000.
UPD: Congratulations to winners!
Also, you can find the list of T-shirt receivers here.
UPD: Editorial







a round setted by 3 legends!
it is gonna be a legendary contest
Is it the first round set by so many high schoolers? Excited for this round :) tons to learn
Can't wait for this cool contest :D
Reminds me of "Aviato" from Silicon Valley Series XD
Chinese Round!
Chinese legends' round, but Chinese night owls' round as well.
I smell geometry and a lot of meth!
choutii for playing a crucial role in the contest. (you'll see.)
Both of you choutii and TLE studying in Fuzhou No.3 High School. And I am not blind
I think he will appear in problems just like Alice and Bob. :-)
guess again
Well, That was true :P
Not,I got no Alice
I need a lot of math in this contest.
There will be an i̶n̶t̶e̶r̶a̶c̶t̶i̶v̶e̶ binary search problem in the round.
Not all of them: 1088D - Ehab and another another xor problem
actually it is binsearch, every two iterations we discard a half of candidates for both numbers
Not all of them (2): 1075D — Intersecting Subtrees
Traditionally, we publish algorithm of selecting random winners before the round.
The seed will be the total number of points of three best participants of this contest, length is 100 (130 — 30) and nwinners is 10.
Total point value is 35931, so:
And winners:
And of course congratulations to top30:
tourist I think this contest will be the best revenge Radewoosh
rua!
I like Chinese rounds.
Chinese Round but a little bad time for Chinese high school students...
Sorry about that, but an opencup will end half an hour before the contest, so we can do nothing :(
when reading the Avito
Will problem setters get T-shirts too? :D
previous Avito code challenge is a good one for me(+100) hope this contest will also give a lot of increase in rating and for other also.
Will we get rating from this contest?
Read careful the round announcement, the second sentence specifies that it is rated for both divisions.
thanks you very much
IS it ICPC rules ? and are the 8 questions too much?
wow
Good Luck! :D
Is It Semi-Rated?
That silly registration process is annoying, fuck hacking, fuck rooms
zzq and fateice!the proud of fzsz!
%%%
In CP, You get T-shirts in winter XD
You can go to Australia to make the T-shirt useful.
tourist is now buying a ticket
How to solve D?
Think in terms of mst. Consider all the edges which directly or indirectly connects any 2 special nodes. Among all such edges find the one with maximum wight. This passed system test for me.
I did but what to do after that? How to find maximum distance for each special node after constructing the tree?
I have updated my comment. Try proving the solution yourself. It is interesting.
Find the MST, and then choose the relevant subtree that contains all the special nodes. The answer is going to be the maximum edge weight in this subtree repeated k times.
The MST has the property that it minimizes the maximum edge between in a path between nodes a to b.
I think it will not be maximum edge weight for ex: 4 3 2 3 4 1 2 10 2 3 1 2 4 1 Here the answer will be : 1 1 Correct me if am wrong.
We have to choose a SUBTREE of the MST that contains all the special nodes.
The 1-----2 edge will not be part of this MST subtree
Yes you are right, I did not read your comment properly, my bad.
I did using a binary search to find the maximun edge that is necessary to contains all special nodes. The answer will be this maximun edge for all nodes.
I wasted too much time on A-E and couldn't find time to code problem H :(
My approach would be something like this:
We may calculate number of distinct palindromes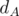 and
and 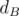 . First estimate would be
. First estimate would be  , but there will be some pairs which we counted twice. What are those strings which may be obtained in several ways? They always may be viewed as
, but there will be some pairs which we counted twice. What are those strings which may be obtained in several ways? They always may be viewed as 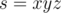 where
where  ,
,  ,
, 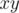 and
and 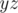 are palindromes. This immediately implies that
are palindromes. This immediately implies that 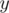 is the period of both
is the period of both 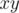 and
and 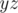 and this is one-to-one correspondence. Good news is that we may find all possible minimum periods of all palindromes in both strings
and this is one-to-one correspondence. Good news is that we may find all possible minimum periods of all palindromes in both strings 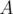 and
and 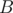 . Now we should calculate number of strings which may be glued with
. Now we should calculate number of strings which may be glued with 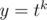 where
where  is one of minimum periods we found, seems like an easy task to do with eertree and some hashes, given that you have enough time to code it.
is one of minimum periods we found, seems like an easy task to do with eertree and some hashes, given that you have enough time to code it.
--
I tried something similar.
I made the pallindromic tree for both strings, now, to find the number of such y's, I calculated, for each reversed suffix links in A, the number of suffix links in B, so I made hashes of all these suffix links and inserted them in a multiset. But I had a bug in the code. Also, I cannot prove the suffix link idea is correct, so most probably it's wrong since it has 0 solves :p.
G is awesome. Could anyone share his/her solution?
As for the others. I found the contest quite nice overall. I failed on D and saw that only after locking. I'd say the biggest issue that I could see with the contest was the very weak pretests in D. Basically you'd pass them if you compute the maximum distance between any 2 points, not necessarily special. Then, regarding the same issue, this left plenty of space for hacks. And apparently rooms are very badly calibrated. In my entire room, there were only 5 (4 until 10 mins ago) people that even tried D (me included). So not only have I locked D and couldn't get a later AC, but my gain from hacks was only 100 points, whereas others had 4-5 hacks on D. I was close to having a good performance, but trying not to be biased, I think I'm not lying when saying that nobody likes having weak pretests. Basically you might misunderstand the problem, solve a wholly different problem and still pass the pretests.
Really? Why would you even do that? I saw people getting hacks on D but nothing happened in my room...
That's what I submitted too...
It's the answer if you read it as "for each special vertex, find the farthest (not necessarily special) vertex from it".
High five!
If there is a person to blame, i think it should be you. You should blame yourself for not reading statement carefully. Many people solved it, so you shouldn't blame the pretest.
Was I blaming anyone? I just said that it's shitty when this happens and nobody particularly enjoys it. I thought the purpose of the pretests is to help you get rid of silly/obviously unintended mistakes. If this is not true, then why do we have pretests at all? When there are some poor pretests, there are 2 categories of people: those that fail, definitely didn't enjoy failing on some easy problem because of a corner case, and those that don't, that still shit their pants when seeing so many hacks and WAs and double-triple check their sources, wasting time, instead of focusing on the beauty of the contest: thinking about the other problems. So I was just claiming that it's not a nice thing to do, and that nobody actually enjoys the fact that the pretests are weak (to be noted, that in this problem, the most random tests would've shown the bug, so the pretests were especially designed to hide this sort of wrong interpretation)
I don't care about the pretest. You just use the reason to satisfy yourself that you may still better than someone who solved the problem you failed, when the fact that you ruined your work yourself, while they were not. If i were you, i would accept the fact that i read the wrong statement and try hard next time, instead of leaving a complain.
Hmm so now I wasn't blaming anyone anymore, was I? Now I was complaining. Next, I'll be whining and so on. My point was: good contest, liked the problems, would've liked the overall experience more if the pretests were better and I'm sure I'm not the only one. This is not complaining, but stating a fact to remind the setters that nobody enjoys it.
If you're so much willing to support an opposite point of view, then better try to add some arguments. If you don't care about pretests, then obviously something's wrong with you. I wonder why IOI and ICPC are full feedback. Ahh maybe, because they want to emphasize the idea, and not the code? Neah, can't be that
Okay, i think that blaming is similar to complaining. Anyway, i'd like to think that when we fail and other people aren't, then the failure should because of our mistakes. Pointing out the weak pretests is necessary for Codeforces community, as it helps improving the contest quality. i just don't like when you said that the weak pretests affected your perfomance. This is the fact, but there is also another fact that you ruined it before the pretests by reading wrong statement. What you said is like prefer the first fact than the second one, which is what i wouldn't like. So i tried to tell you this, but it became a bad argument.
Dude you blamed all your FIFA opponents for rekting you and you are here being hypocritical about what lmao???
Not only pretests were weak, but system tests too, which makes it more fair.
Here is O(m*k) accepted solution, which I did not manage to hack within contest.
Isn't that solution O(M * logM)? It looks like he baited you with bad indentation.
I guess that because of your comment I got downvotes, for bullshit and blaming strong tests :) Well this is O(m*k) as I wrote and here is the test exposing this:
You're calling bs but I copied the test and the solution and it runs in under 2 seconds in my (slow) computer... ? Did you care to try the test?
Edit: In fact, I ran that test on custom invocation with the input hardcoded and it got 30ms
You must have a very fast computer or use a different test. Here is the result on a fast computer:
It took me 3398 clicks (3.398000 seconds).
Edit. I also run it on cf and it runs in 15 ms. I don't understand that. I even added counter inside inner for loop
The value of that counter is 2,5*1e9, which proves that it runs in O(m*k). I don't understand how is it possible on cf to run so fast...
Edit. I even multipled constraints by 10 and on my machine it runs as expected — extremely long. On CF it runs in 93 ms and outputs very small number of total iterations. I completely do not understand this weird custom invocation behavior:
Expected number of iterations during local testing: 249999999999
CF custom invocation: 1666656
I found the issue. Please replace sort with stable_sort to get huge TLE or use different weights on edges. In case the values are the same the order can be arbitrary and it happened that first edge with 50000 appeared in the end instead of being in the middle.
Edit. I think that KNB. might be interested, as he also noticed that and tried to hack that solution.
I see, that's true. Nice catch.
Tests on E were also weak. Solutions which can set x_i = 0 like: 47142808 or 47119126 by mnbvmar were accepted. This fails for example on:
Added test for the upsolving
Have you added perf test to D too?
There was some discussion going about it, give me the last version and I will surely do :)
That was really interesting and close.
if V--o_o--V got just one successful hacking attempt, he would have become the first.
Edit: nvm :(
How to solve E?
for each number you have the sqrt of the sum of numbers before it
bf, and number next to itnxt. now you need to find anxsuch thatll(sqrt(a * a + nxt)) == sqrt(a * a + nxt)anda = bf + x. I don't think binary search would work, so I iteratedwhile ((a + 1) * (a + 1) - a * a <= nxt)which means that the difference between the next perfect square is already bigger thannxtand we have no answer if that happened, andnxt <= 1e5so that will fit in the time limit. Tho I don't have any proof whether the first number that fits will be the only one that does.We can prove that we want to always greedily take lowest possible square for any prefix. Lets consider 4 numbers, first and third of them we can choose. Consider the case when multiple prefix sums can fit the prefixes of sizes 1-2, but only one value fits prefixes of size 3-4.
In this case we can take any of lower values for 1-2 and adjust 3-4 up to needed numbers by adjusting value of number 3.
Formally:
And we have two different values for A and B: (A1, B1) and (A2, B2). So we can satisfy them with proper values a1 and a2. And then choose a3 = C - a1 - a2.
The only limitation is that a3 > 0. So choosing minimum B is not only valid, but also optimal.
Consider this geometrical interpretation. From up-left to right-bottom: green area is a1, yellow is a2, blue is a3 and pink is a4. On both pictures areas of yellow and pink are the same (up to my drawing skills quality), but we can freely choose green and blue areas to preserve total area of C and D unchanged.
And this idea can be easily generalized for higher number of prefixes.
wewark I think you meant
a*a = bf + xand nota = bf + x.sorry,
bfis the sqrt of the sum of the numbers before, not the number itself. Fixed.I did it with a greedy algorithm. For every odd i find such an a[i], so sum (a[1..i-1]) + a[i] + a[i+1] is a correct square, using the fact, that we can make any correct square from sum (a[1..i]), that is less than sum (a[1..i-1]). So every time i seek for the minimal square. We can stop seeking, when a[i+1] is less than 2 * sqrt (sum (a[1..i])) + 1.
I did it with a greedy algorithm. For every odd i find such an a[i], so sum (a[1..i-1]) + a[i] + a[i+1] is a correct square, using the fact, that we can make any correct square from sum (a[1..i]), that is less than sum (a[1..i-1]). So every time I seek for the minimal one. We can stop seeking, when a[i+1] is less than 2 * sqrt (sum (a[1..i])) + 1.
Can we do F deterministically? If yes then what is the approach?
In general, we can't. For example, see array with size 2. 01 and 10 are indistinguishable.
Is pC C(m,n/(n-k))
It is
I managed to find the formula during contest and submitted exactly the same. But it gave WA on pretest 5. I guess I messed up ordering of modular arithmetic. :(
Can you please explain?
So there are k + 1 blocks. Choosing the sizes of the blocks and the colours are independent of each other, and the answer is the product of the two.
colour arrangements: For the first block, we have m options, but for the other k blocks, it must have a different colour than the previous one, so there are m - 1 options for those. This gives m(m - 1)k.
Block sizes: Every block must be of size ≥ 1, so let s1, ..., sk denote the starting positions of the second, third, etc. block. Then we have 1 < s1 < ... < sk ≤ n, so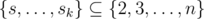 . Thus we are picking k 'balls' out of n - 1 'items'. This is
. Thus we are picking k 'balls' out of n - 1 'items'. This is 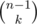 .
.
Is it the correct one ? I submitted the same but got WA on pretest 4 !! and then applied DP seeing the constraints :(
Edit — I made a modular arithmetic mistake :3
Completely misunderstood the problem. I thought there are k different bricks in total with color different from each brick except the last one.
What are the hacks in D? I see a lot of hacks.
Basically, anything
i couldnt solve b. Can anyone please telll the solution?
please?
Here is my solution, but I feel like there's a simpler one out there. I recommend waiting for the editorial.
cant see your solution . can you explain your approach?
I'll tell you how I approached it. First, Observe that all people who are wearing the same type of hat will have the same value of a[i] i.e. people differing will be the same. Although vice versa is not true.
Maintain a hat ID variable starting from 1.
FOR ith person who is not assigned any hat number:
count the number of people having the same values in a as a[i]. let's call them SAME and count the people having different values in a, other than a[i].let's call them DIFF.
if DIFF is greater than a[i] that means sequence b is not possible.
if DIFF is equal to a[i] then all the people counted in SAME will get the same hat number. Assign the same hat ID to all people counted in SAME.
if DIFF is less than a[i] then (a[i]-DIFF) people counted in SAME will not get the same hat number. Hence assign same hat ID to ( SAME-(a[i]-DIFF) ) people counted in SAME. Don't assign any Hat ID to the rest.
increment hat ID variable.
END FOR loop.
Here's my code.
For each people we can say the number of hats of his kind — it's
n - a[i]. Then we can count the number of people, the number of hat's of whose ifn - a[i].Xpeople forZhats. If for each number from 1 to nX % Z == 0— we can answer. Otherwise, it's impossible. We can choose the types from 1 to n in this order:Please stop using
l(lowercase L) as a variable name in problem statements.On problem 1081F - Tricky Interactor, I thought "the interactor will either flip [1, r] or [l, n]" was "[l, r] or [l, n]" and spent over half an hour solving the wrong problem.
I think
lis similar to1, but l is not similar to 1.Looking similar doesn't justify the use of wrong characters. Don't you think?
holy terrible implementation on F
+1, I spent like 40 minutes trying to figure out when to invert the value of s[i]...
PS: I still think the problem was awesome
what was test 15 in E?
It was great being purple for a day. :(
Will probably fall about 30 rating points.
EDIT: WTF Got hacked and failed two problems. RIP pretests.
really nice problems !! it was fun to think about :D even so C made me confused with probabilities and couldn't solve it
See problem setters we don't get mad because we didn't make good result it's because the problems aren't fun to think about
My solution of C failed on pretest 4. But i didn't find the right case. Can somebody, who failed at pretest 4 first, please, explain, where is mistake?
I had ifs:
if (k==0)return cout<<m,0;
if (k>m)return cout<<0,0;
I removed them and got ac, formula is: d[i][j]=d[i-1][j-1]*(m-1)+d[i-1][j];
Before processing this formula i put every d[i][0] to m (1<=i<=n)
Thank you! I did't think about dp. But I haven't got the problems with this cases...
tourist is going to take back the first spot!
How to solve B?
Here a[i] is the number of persons who wear different hat from him.
Hence, n-a[i] is the number of persons who wear similar hat to him.
Now, group the indices whose n-a[i] is equal. Insert i in the group[n-a[i]].
If for any group[i], size of the group is not divisible by i, then print Impossible
Otherwise, maintain a id starting from 1. For each group[i], iterate through all the indices in
it and for every i indices, set their value of b[] to the counter value and increment the counter by 1. Then print Possible and the array b[].
Update: Here is my code: https://pastebin.com/QWf0gbsB
Sorry for my poor English. Feel free to comment, if you don't understand the solution.
why are other's submission still not public ? :(
Probably to do the system testing fast.
If we say in C that k is not just for left bricks, but to all bricks (every brick can be painted with m colors, but all bricks in the end need to have k different colors), what is formula for dp[n][k] then?
DP[0][0] = 1;
DP[i][j] = m*DP[0][j] + Sigma(x from 0 -> i-1) (m-1) *DP[x][j-1] (if j > 0)
Best chineese contest i've ever seen
As a general rule, no one solved H. But I still think the problems are perfect.
How can pretests be so weak that for problem D a solution which outputs the biggest distance between the furthest vertex, not the furthest special vertex pass pretests?
I was hacked by khokho with this same idea. Luckily for me, he gave me the opportunity to correct my code.
EDIT: my corrected code didn't pass system tests. Damn it, I spent twice the time for less than worse results.
EDIT: Why the downvotes?
nice 9th test on B just kills me.
i think it's will be something like 2 1 1 or 4 2 2 2 2 or 7 5 5 5 5 5 5 6
How come tourist was able to hack on A...
Btw, I see only one FST among all 63 submissions in our room. What a smart room!
You should try to be bad-at-luck like me, constantly jumping into rooms that nobody makes mistakes even other rooms are full of such people :D
Also, nicely done hacking one D :D
What is FST?
Failed System Test
aactually I have seen the code of problem A which tourist hacked . that fellow's code gives output 2 for input 6. here's the code https://codeforces.com/contest/1081/submission/47132351 and hacking that code is too easy for someone like Tourist!
Why I'm unable to see other's solutions?
Why can't I submit problems though systest is over? Submit button still redirects to same page with notification 'contest is over' .
How can I upsolve the problems of this contest?
The problems should be able to submit by now. However, they're not at the top of the problemset, so be careful to find them.
Why am I not able to submit solutions even though the systests are over?
coz they havent put the problems for practice!!
I hope they add it soon. My frustration level is rising exponentially.
why I faced problem while submitting ans of problem after contest ?
Anyone got an idea what was pretests 6 in E? Can't wait anymore
back to div2 it is
When the Editorial will be published ?
In problem C, can anyone explain meaning of this line "he found there are k bricks with a color different from the color of the brick on its left (the first brick is not counted, for sure)".
If
color[i]is the color of the i-th brick, then it's talking about the number of bricks such thatcolor[i] != color[i-1].I agree that it could have been worded better.
https://codeforces.com/contest/1081/submission/47141835
My submission is O(n) but you can easily achive O(1) with factorial preprocessing for calculating nCr.
O(1) sol for C. 1). How many ways to divide n into k+1 segements. (x)
2). How mnay ways we can color k+1 segements such that no adjacent color is same. (y)
ans = x*y
But thats O(n) solution.
Mine is O(n) but with factorial preprocessing you can do nCr part in O(1).
many have crached task D on test 18, does anyone understand why?
Taken such test for example:
The answer should be 3, but since many solutions output the maximum weight of the MST of the entire graph (not just the subgraph including all special vertices), they outputted 4 and failed system tests.
I just want a T-shirt~QAQ
Problem D is so close to this one: The Child and Zoo
Guys ! for problem D you also can use simple Dijkstra algorithm starting from any special vertex. The answer is the maximum of cost of all special vertex. check my solution. Using wrong comparator function was the reason i had to try submitting so often.